
sckit-learn 특징
- 다양한 머신러닝 파이썬 라이브러리
- 머신러닝 개발을 위한 프레임워크와 API 제공
scikit-learn 주요 모듈

API 사용방법
- Scikit-Learn으로부터 적절한 estimator class import하여 모델의 class 선택
- class를 원하는 값으로 인스턴스화해서 모델의 하이퍼파라미터 선택
- 데이터를 특징 배열과 대상 벡터로 배치
- 모델 인스턴스의 fit() 메서드를 호출해 모델을 데이터에 적합
- 모델을 새 데이터에 대해서 적용
-
지도 학습 : 대체로
predict()메서드 사용해 예측 -
비지도 학습 : 대체로
transform()이나predict()메서드 사용해 데이터 속성 변환, 추론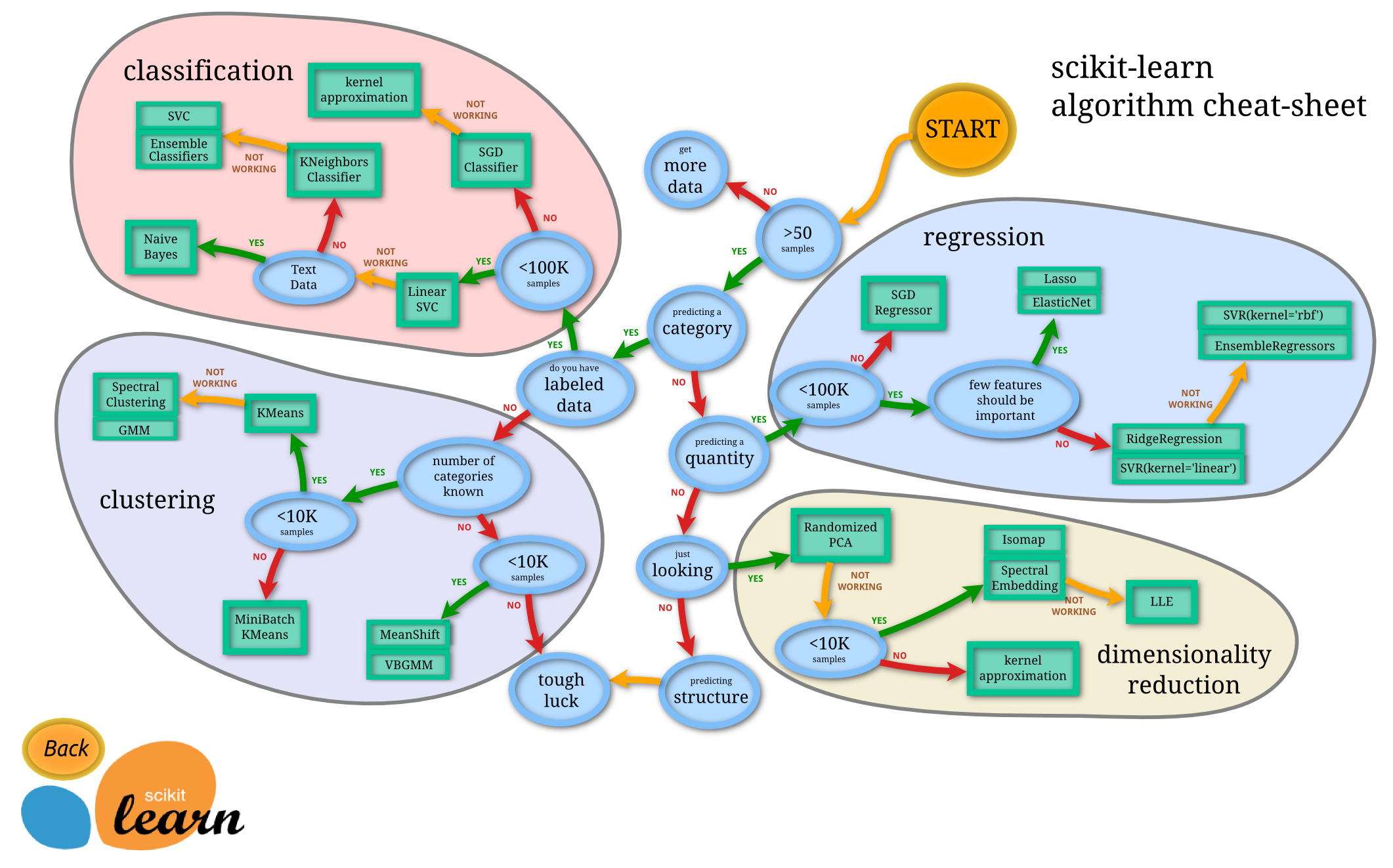
API 사용 예제
# 1. 적절한 estimator 클래스를 임포트해서 모델의 클래스 선택
from sklearn.linear_model import LinearRegression# 2. 클래스를 원하는 값으로 인스턴스화해서 모델의 하이퍼파라미터 선택
model = LinearRegression(fit_intercept=True)
# 3. 데이터를 특징 배열과 대상 벡터로 배치
X = x[:, np.newaxis]
# 4. 모델 인스턴스의 fit() 메서드를 호출해 모델을 데이터에 적합
model.fit(X, y)# 5. 모델을 새 데이터에 대해서 적용
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)model_selection모듈
-
학습용 데이터와 테스트 데이터로 분리
-
교차 검증 분할 및 평가
-
train_test_split(): 학습/테스트 데이터 세트로 분리from sklearn.model_selection import train_test_split # test_size = 분리 비율 X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.3) -
cross_val_score(): 교차 검증from sklearn.model_selection import cross_val_score, cross_validate # cv= 데이터 분할 방법 scores = cross_val_score(model, data, target, cv=5) -
GridSearchCV(): 교차 검증과 최적 하이퍼 파라미터 찾기- 잠재적 파라미터 후보군들의 조합 중에서 가장 best조합을 찾아줌
from sklearn.model_selection import GridSearchCV
alpha = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
param_grid = dict(alpha=alpha)
# estimator = 모델 객체
# param_grid = 탐색하려는 하이퍼 파라미터 그리드
# scoring = 모델 성능 평가 지표
# cv = 데이터 분할 방법
gs = GridSearchCV(estimator=Ridge(), param_grid=param_grid, scoring ='accuracy', cv=10)
result = gs.fit(data, target)데이터 전처리 모듈
StandardScaler : 표준화 클래스
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
iris_scaled = scaler.fit_transform(iris_df)MinMaxScaler : 정규화 클래스
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
iris_scaled = scaler.fit_transform(iris_df)성능 평가 지표
오차 행렬
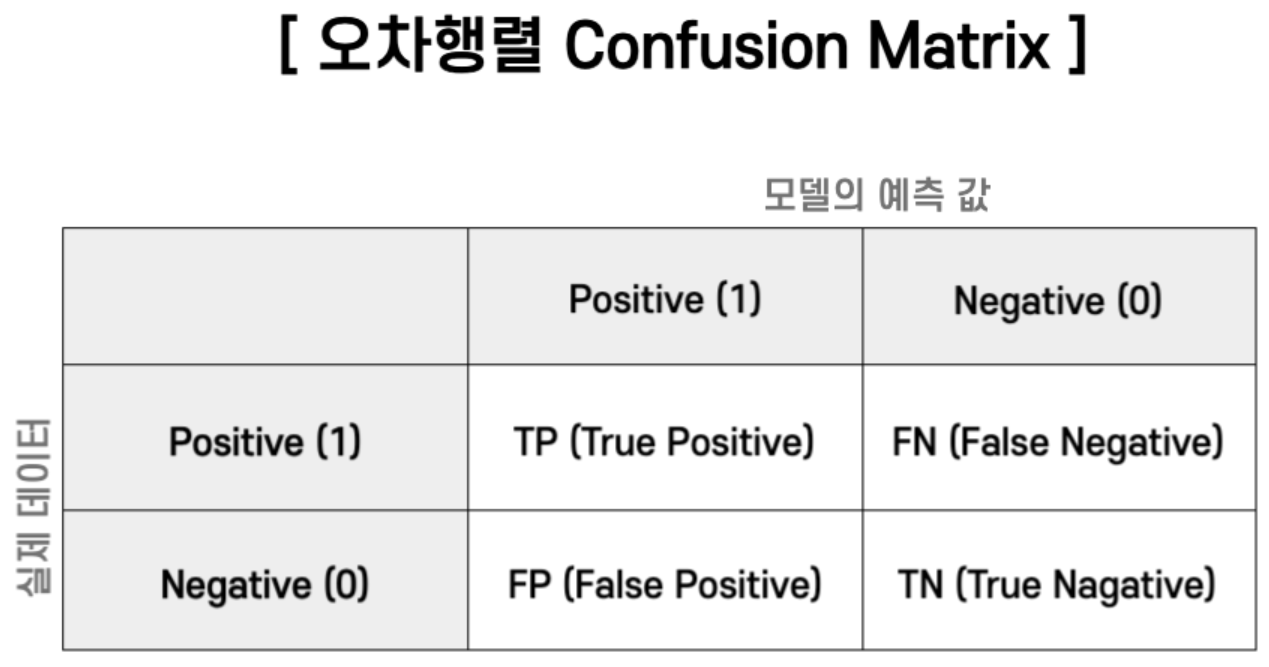
from sklearn.metrics import confusion_matrix
confmat = confusion_matrix(y_true =y_test, y_pred=predict)정확도(Accuracy)
전체 예측 데이터 건수 중 예측 결과가 동일 데이터 건수
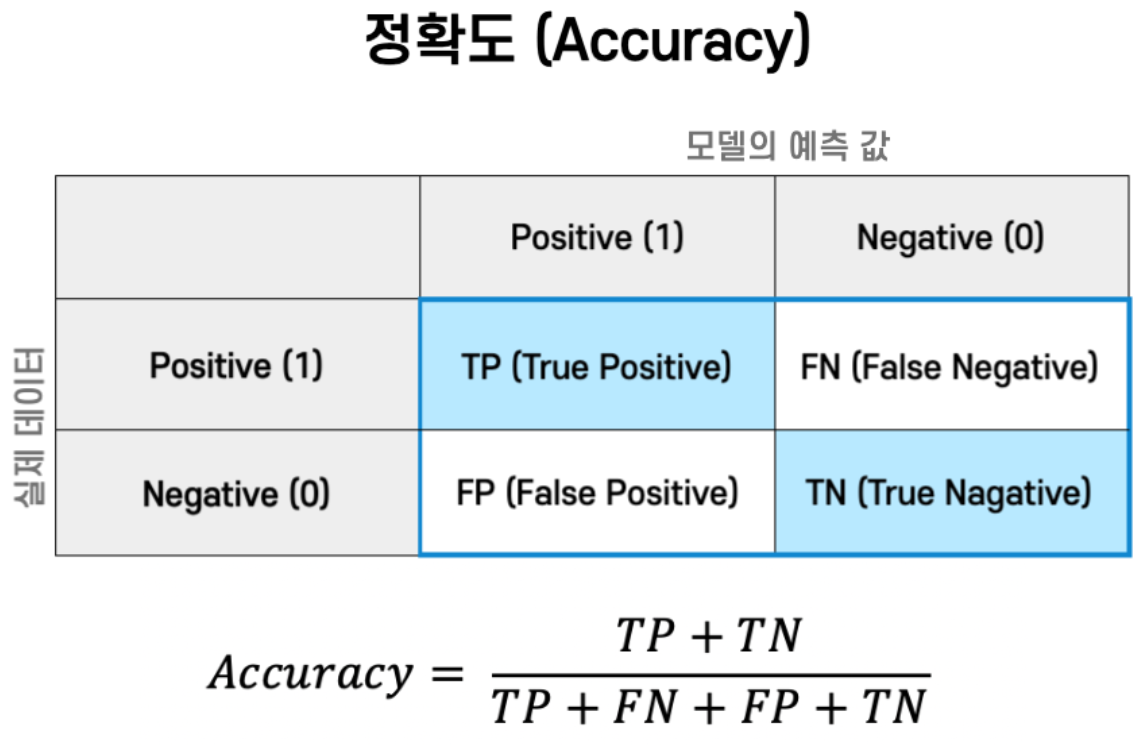
from sklearn.metrics import accuracy_score
score = accuracy_score(y_test,predict)정밀도와 재현율
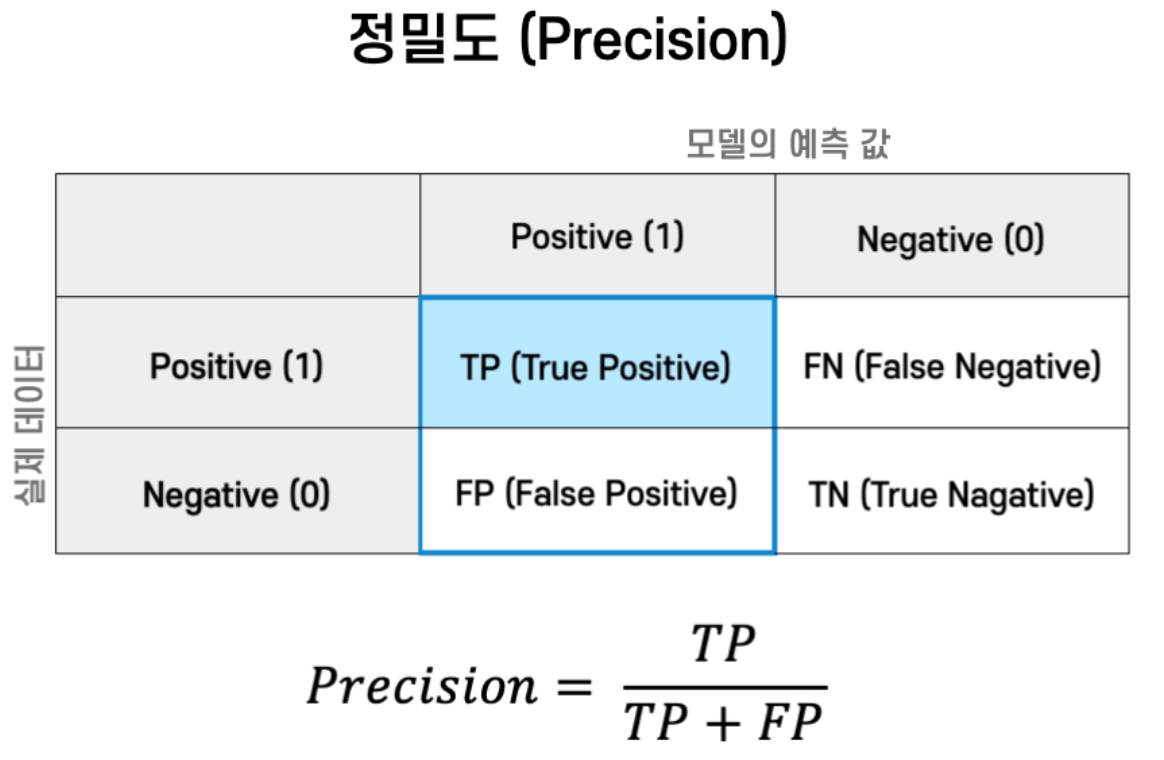
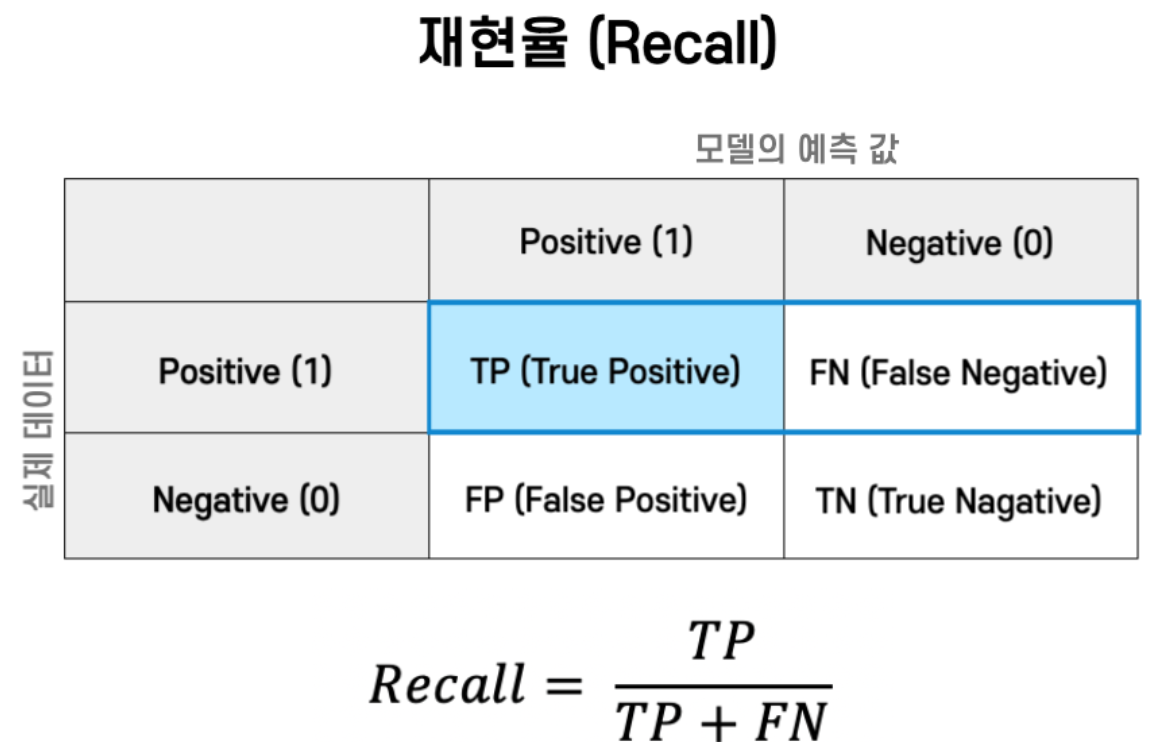
from sklearn.metrics import precision_score, recall_score
precision = precision_score(y_test, predict)
recall = recall_score(y_test, predict)F1 Score(F-measure)
- 정밀도와 재현율의 조화평균
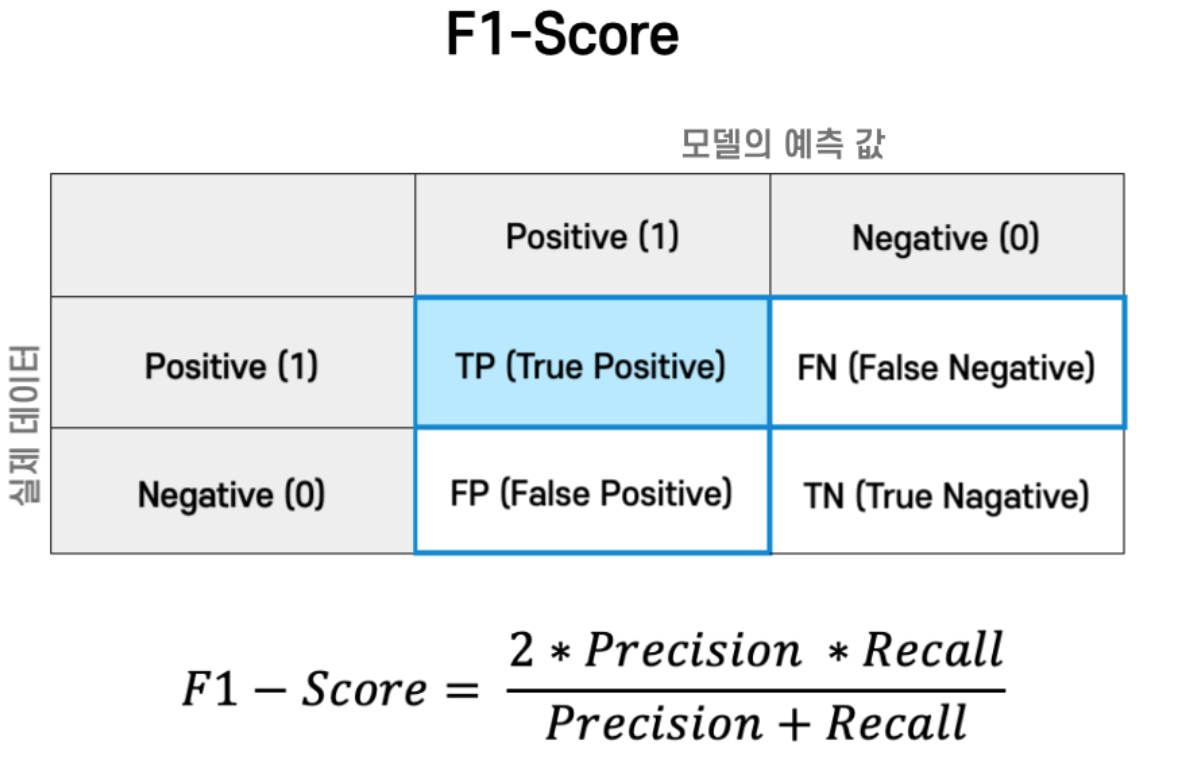
from sklearn.metrics import f1_score
f1 = f1_score(y_test, predict)
ComputerVision 누구냐 넌