SalesforceAIResearch/uni2ts · Python
"Unified Training of Universal Time Series Forecasting Transformers" — Moirai 1.x/MoE + Moirai-2 공식 구현.
TL;DR
Salesforce/moirai-2.0-R-small은 11.39M 파라미터 / 45.6 MB safetensors 한 개짜리 모델이다. Moirai-1 Large(311M) 대비 약 27배 작다. small 한 사이즈만 공개돼 있어 큰 모델을 고민할 여지가 없다.- 두 가지 세트로 돌렸다. (A) 금융 OOD — 002 글에서 Kronos가 지나간 BTC 1h와 삼성전자 daily를 그대로. (B) in-distribution mini — gluonts 내장 M4 weekly 200 시리즈. 환경은 RTX 3090 Ti 24GB, torch 2.4 + CUDA 12.4, 단일 GPU.
- (A) 금융: Moirai-2의 point MAPE는 BTC 1.87% (naive last-value 1.91%) / 삼성 15.85% (drift 15.41%). naive를 간신히 이기거나 비김. 반면 Kronos는 BTC 6.90% / 삼성 64.60%로 3~4배 나쁨이라는 002 패턴을 다시 재현했다.
- (B) M4 weekly (200 series): Moirai-2 median MAPE 2.73% (naive 2.88%, seasonal naive 8.01%). median 차이는 작지만 평균(5.06% vs 6.61%)에서 벌어진다 — tail 외곽치에서 안정성 차이. MASE median 0.31로 seasonal naive 대비 약 1/3.
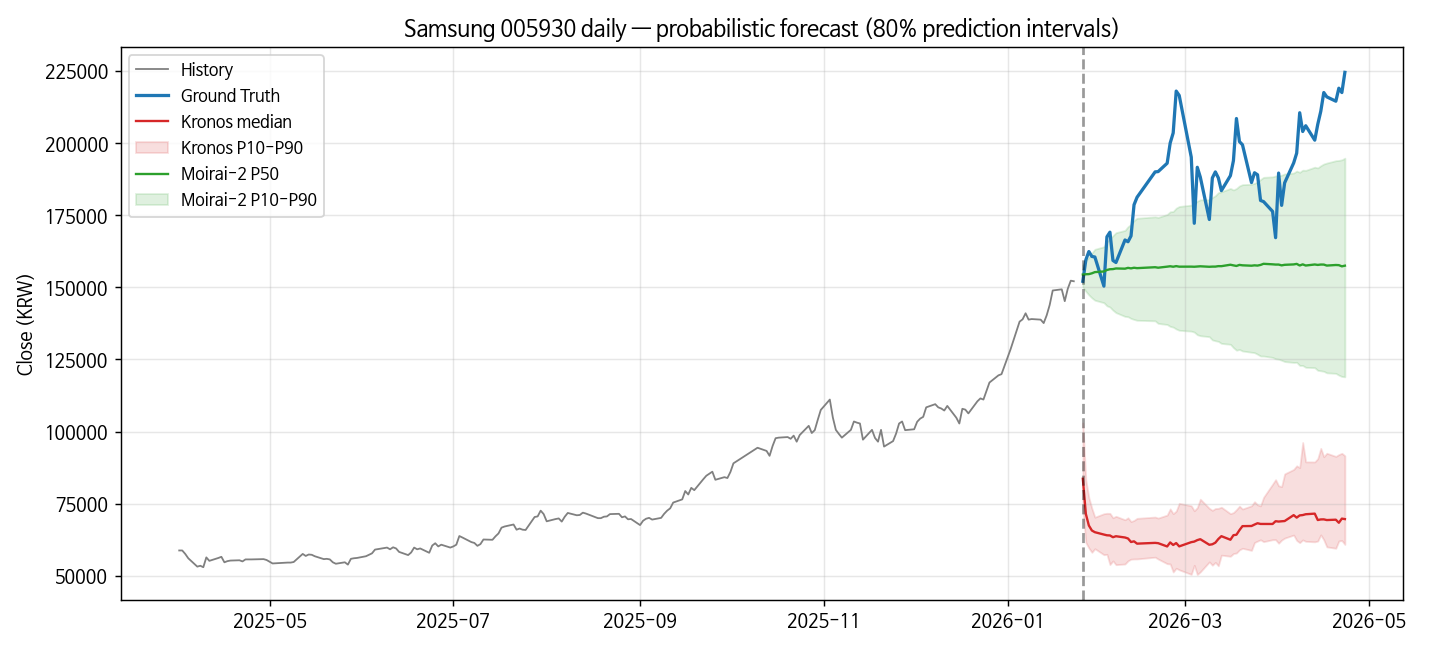
- 확률 예측 쪽에서 구조 차이는 뚜렷하다 — 다만 그 해석은 조심. Moirai-2는 단일 forward pass로 9 quantile을 바로 출력해서(샘플링 없음) pinball loss가 Kronos K=30 sampling 대비 5배 낮다. BTC·삼성에서 coverage 92%·28%가 나오는데, 이 숫자를 곧바로 "Moirai-2가 예측을 잘했다"로 읽으면 틀린다. BTC에서 Moirai-2 point forecast는 거의 수평(forecast std가 truth std의 5%)이고, 넓은 P10-P90 밴드(width 5035)가 truth의 움직임 상당수를 우연히 덮는 구조에 가깝다. 추세 자체는 Moirai-2도 Kronos도 못 따라간다. 금융 OOD에선 둘 다 실패이고, 다만 Moirai-2가 그 실패를 넓은 uncertainty로 정직하게 표시하는 쪽, Kronos는 좁은 band에 빗나간 median을 까는 쪽. 구조 차이는 in-distribution(M4 weekly coverage 0.92)에서도 유지된다.
왜 이걸 보게 됐나 — 002 다음 걸음
002 글에서 Kronos-small을 BTC/삼성 zero-shot으로 돌렸고, 두 데이터셋 모두에서 가장 게으른 baseline(상수·직선)에 졌다. 그 글에서 정리한 caveat("zero-shot only, smallest model, 단일 window, RankIC가 아닌 MAPE 기준")를 그대로 두더라도, "그 다음은 어느 TSFM을 같은 자리에 올려 보면 되는가"라는 질문이 남았다.
Moirai-2는 그 질문에 맞는 후보였다. 2025-11 공개, Salesforce AI Research, HuggingFace 월 다운로드 약 41만(현 TSFM 후보 중 최상위 규모), 논문 헤드라인은 "Moirai-1 Large 대비 2배 빠르고 30배 작으면서 더 좋다". GIFT-Eval에서도 normalized MASE 5위권의 상위 점수. 공식 레포 SalesforceAIResearch/uni2ts는 Moirai 1/1.1, Moirai-MoE, Moirai-2 세 가지를 모두 포용한다.
이 글은 두 가지를 묶어서 보여주는 데 초점을 맞췄다. 002 자리에서 Moirai-2 단일 사례 보고 + Moirai-2가 원래 평가된 in-distribution 벤치에선 어떻게 나오는지 최소 대조. 둘을 같은 글 안에 두는 이유는, 금융 OOD 결과만 놓고 판단하면 "그렇게 작은 모델이 뭘 해내겠어"로 미끄러지기 쉬운데, 그 비교가 공정하지 않을 수 있어서다.
Moirai-2가 바뀐 지점
Moirai-1과 비교해 논문이 짚은 변경점은 세 가지다. 구현 쪽에서 체감되는 건 세 번째가 가장 크다.
(1) encoder → decoder-only. Masked-encoder + multi-patch input이 사라지고 AR 디코더 구조가 됐다. patch_size=16 단일.
(2) mixture distribution → quantile head (9 level). 분포 파라미터를 출력하고 샘플링하는 기존 구조 대신, pinball loss로 직접 9개 quantile(0.1 ~ 0.9)을 낸다. CRPS 최적화에 직결되고 샘플 variance가 없어진다.
(3) single-token → multi-token prediction (num_predict_token=4). 한 forward에서 4 패치 앞을 예측. 롱호라이즌 autoregressive 단계 수가 1/4로 줄어 throughput이 붙는다. Ablation에서 이게 최대 기여라고 논문이 명시.
실측으로 잡힌 사양을 박아두면:
{
"d_model": 384, "num_layers": 6, "d_ff": 1024,
"patch_size": 16, "max_seq_len": 512,
"num_predict_token": 4,
"quantile_levels": [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
}max_seq_len=512 patches × patch_size=16 = **8,192 time step** 까지 context로 들어간다. 파라미터는 sum(p.numel())으로 잰 값이 정확히 11,387,208 = 11.39M. HF safetensors 파일은 45.6 MB. base/large 변종은 미공개라 단일 선택지다.
글에서 제일 인상 깊게 남은 건 Kronos와의 출력 인터페이스 차이다. Kronos는 AR 토큰 샘플링 기반이라 sample_count=1 호출이 단일 trajectory고, 확률적 band를 원하면 K=30 정도를 독립적으로 돌려 percentile을 재구성한다. Moirai-2는 그렇게 하지 않는다. 단일 forward에 QuantileForecast 객체가 돌아오고, forecast.quantile(0.1)부터 forecast.quantile(0.9)까지 바로 꺼낸다. hasattr(forecast, "samples") 가 False다. 이 차이가 뒤에서 설명할 probabilistic metric 격차의 상당 부분을 설명한다.
실험 설계
환경
- RTX 3090 Ti 24GB, CUDA 12.4 (driver 591.86), WSL2
- Python 3.12.9, uv venv, torch 2.4.1+cu124 (uni2ts pyproject의
torch<2.5pin 때문) - uni2ts 2.0.0 editable, gluonts 0.14.3, numpy 1.26.4, einops 0.7.0
- Kronos 재활용: 002 때 쓴 clone(
~/playground/trending/2026-W15-kronos/Kronos/)과 HF 캐시(models--NeoQuasar--Kronos-{Tokenizer-base,small}) 보존되어 있어sys.path.insert한 줄로 연결
A: 금융 OOD
| 데이터 | 출처 | 기간 | lookback | pred_len |
|---|---|---|---|---|
| BTC/USDT 1h | binance (ccxt, 공인증 X) | 2026-04-01 15:00 → 04-23 06:00 (520 bars) | 400 | 120 |
| Samsung 005930 daily | pykrx | 2024-06-03 → 2026-04-23 (460 bars) | 400 | 60 |
002와 데이터 로더·lookback·pred_len은 동일로 맞췄다. 다만 Binance/pykrx가 모두 "최신 기준" fetch라 window 자체는 002(2026-04-13 실행)와 10~14일 이동. BTC는 since pin이 run_baselines.py 쪽에만 있었고 run_btc.py는 since 없이 최근 520 bars라 002와는 다른 window가 된다. 즉 이 글은 같은 설계 다른 시점의 fresh run이고, 002 숫자는 본문에 참조로만 둔다.
4 methods:
- naive last-value:
y_pred[t] = x[-1](상수) - drift (linear):
y_pred[t] = x[-1] + (t+1) * mean_step - Kronos-small (K=30):
sample_count=1로 30 independent forecasts → percentile로 9 quantile 재구성 - Moirai-2-small: 단일 forward → 9 quantile 직접
Metric:
- point (on median/단일): MAE, RMSE, MAPE, DirAcc
- probabilistic: 9-level pinball loss 평균, 80% PI coverage (P10~P90 안에 truth 포함 비율), mean interval width
B mini: in-distribution
- gluonts 내장 m4_weekly (Makridakis M4, weekly)
- 359 테스트 시리즈 중 context 400+ 가능한 260개에서 200개만 샘플링
- pred_len=13 (약 3개월)
- 3 methods: naive last-value / seasonal naive (period=52, 1년 앞 같은 주) / Moirai-2-small
- Metric: per-series MAPE, per-series MASE (MAE / MAE_seasonal_naive), Moirai-2만 pinball + coverage
M4는 Salesforce 자체의 GIFT-Eval pretrain subset에 포함돼 있을 가능성이 높다. 그래서 이 벤치는 엄격한 의미의 zero-shot이 아니라 "Moirai-2가 훈련 중에 봤을 법한 도메인에서의 eval" 쪽에 가깝다. B의 역할은 정량 벤치 재현이 아니라, A(금융)와 같은 모델이 설계된 도메인으로 가면 어떻게 달라지는지를 한 번 대조하는 데 있다.
horizon·context가 Moirai-2에게 공정한가
세 세트 모두 lookback=400, pred_len=120/60/13로 잡았는데, 이게 Moirai-2 입장에서 과한 horizon은 아닌지 공식 기준과 맞춰봤다.
먼저 훈련 분포 자체는 공개되지 않는다. 논문(arXiv 2511.11698 §3.2)과 HF 모델 카드 어디에도 (a) 훈련 corpus의 frequency별 비중(hourly/daily/weekly 비율)과 (b) 훈련 시 window 길이 분포는 수치로 적혀 있지 않다. 확인 가능한 건 전체 36M 시리즈 총량과 source 구성(GIFT-Eval Pretrain 3.25M · Chronos-Mixup 30M · KernelSynth 1M · Salesforce Internal 2.15M)뿐이다. 그래서 "우리 설정이 훈련 분포 내부인가"는 직접 답할 방법이 없다.
간접 참조점 두 가지는 있다.
- 공식 inference 예제의
context_length=1680(uni2ts/example/moirai_forecast.ipynb기준). patch_size=16 기준 105 patches.max_seq_len=512patches는 positional encoding의 상한이지 훈련 중심 범위는 아닐 가능성이 높다. - GIFT-Eval 표준 horizon. 소스 코드
gift_eval/data.py의PRED_LENGTH_MAP × TERM_MULT에서{short: ×1, medium: ×10, long: ×15}세 구간이 정의돼 있고, Moirai-2는 이 위에서 평가된다.
| Freq | base (short ×1) | medium ×10 | long ×15 |
|---|---|---|---|
| Hourly | 48 | 480 | 720 |
| Daily | 30 | 300 | 450 |
| M4 Weekly | 13 | 130 | 195 |
우리 설정을 이 표와 겹쳐보면:
| 세트 | context | pred_len | GIFT-Eval 표준 대비 |
|---|---|---|---|
| BTC 1h | 400 | 120 | hourly short(48)과 medium(480) 사이 — "5일 앞" |
| Samsung daily | 400 | 60 | daily short(30)의 2배, 여전히 short 범주 |
| M4 weekly | 400 | 13 | M4 weekly short과 정확히 일치 |
즉 horizon 쪽은 정리하면:
- M4 weekly pred=13은 GIFT-Eval 표준 short과 완전히 같은 설정. Moirai-2가 공식 평가된 horizon 그대로.
- Samsung pred=60은 short의 2배. 여전히 short 영역 안쪽.
- BTC pred=120이 유일한 애매점. short(48)과 medium(480) 사이 구간. 과하다고 단정하긴 어렵지만, 공식 평가의 단일 구간 안에 떨어지진 않는다.
context=400은 세 세트 모두에서 공식 예제(1680)의 약 1/4이다. 훈련 시 본 context 길이 분포가 공개되지 않아 "짧은 쪽 끝에 더 가까운지"는 확정할 수 없지만, context를 1680 근처로 늘리면 Moirai-2에게 더 유리해질 가능성은 열려 있다. 이 글에서는 002와 같은 lookback 400을 유지해 시리즈 내부 비교를 정돈하는 쪽을 택했다.
결과 A — 금융 (OOD)
점 예측
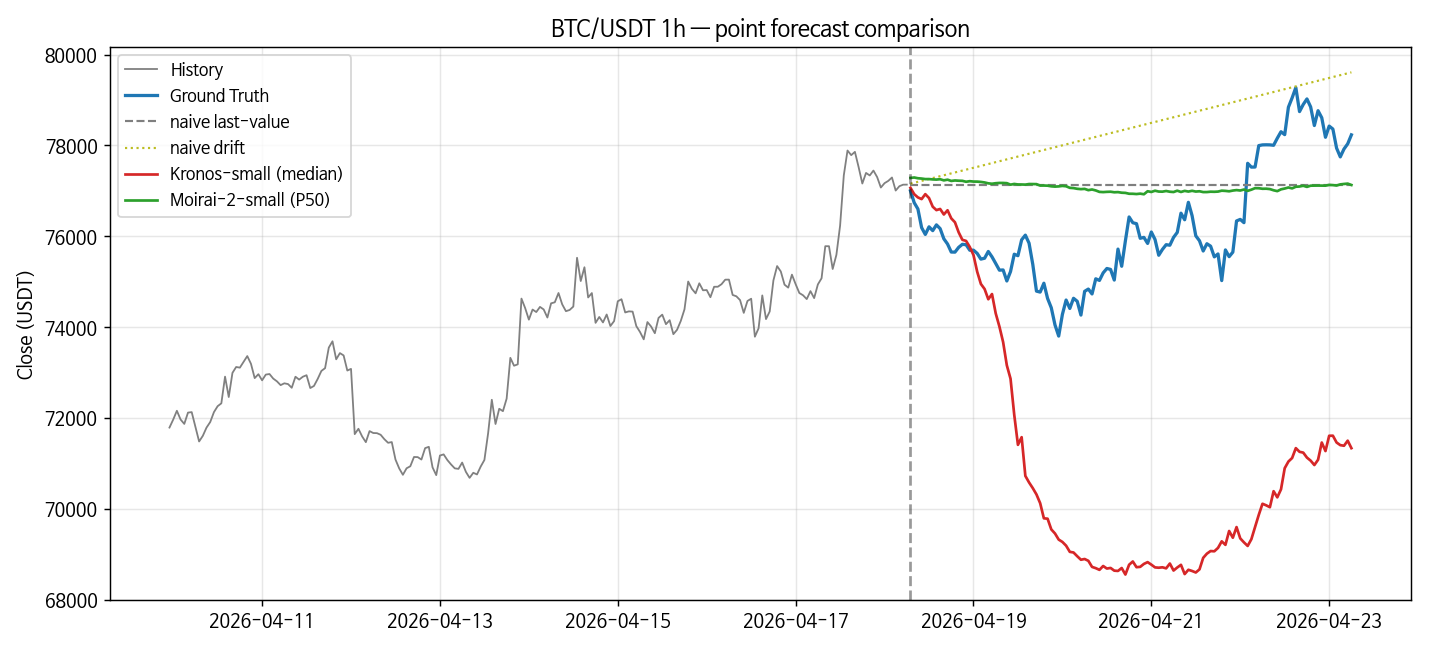
| method | MAE (USDT) | RMSE | MAPE% | DirAcc |
|---|---|---|---|---|
| naive last-value | 1451 | 1580 | 1.91 | 0.000 |
| drift | 2135 | 2349 | 2.82 | 0.462 |
| kronos-small | 5275 | 5938 | 6.90 | 0.555 |
| moirai2-small | 1423 | 1549 | 1.87 | 0.513 |
BTC에서 Moirai-2가 naive last-value를 0.04%p 차이로 간신히 이겼다 (MAPE 1.87% vs 1.91%). 거의 동률이지만 한 가지 흥미로운 지점은 DirAcc 0.513 — naive last-value가 상수라 diff가 0, DirAcc도 0인 것에 비해 Moirai-2는 방향 예측이 random coin toss 수준은 맞춘다. drift(0.462)보다 약간 위, Kronos(0.555)보다 약간 아래.
Kronos는 MAPE 6.90%로 여전히 naive 대비 3.6배 나쁨. 002에서 기록된 4.87%보다 이번 window에서 더 벌어졌는데, 이건 실행 시점(4월 초~4월 말)의 BTC 변동성이 더 컸던 것으로 보인다 — 다만 단일 window 관찰이라 단정은 어렵다. 어쨌든 "Kronos zero-shot이 naive에 짐"이라는 002의 핵심 관찰은 다른 window에서도 살아있다.
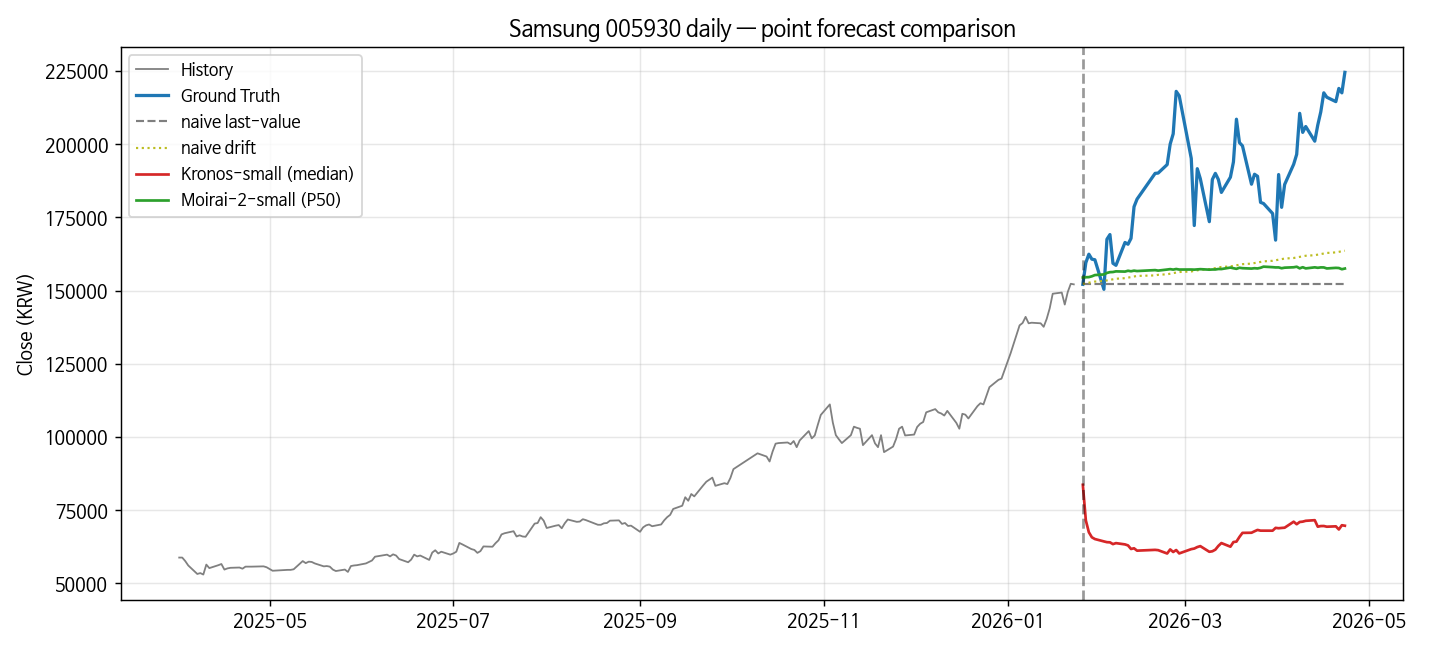
| method | MAE (KRW) | RMSE | MAPE% | DirAcc |
|---|---|---|---|---|
| naive last-value | 36157 | 40784 | 18.37 | 0.000 |
| drift | 30361 | 34547 | 15.41 | 0.542 |
| kronos-small | 122242 | 123728 | 64.60 | 0.458 |
| moirai2-small | 31342 | 36123 | 15.85 | 0.542 |
삼성에선 drift가 MAPE 15.41%로 최고, Moirai-2가 15.85%로 바로 뒤, naive last-value 18.37%. Kronos는 64.60% — 002에서 측정된 63.20%와 거의 일치 (10일 시프트된 window에서도 같은 패턴). DirAcc 0.542는 drift/Moirai-2 동률.
두 데이터 모두 공통적으로: Moirai-2는 point metric 최상위권에 붙긴 하는데, naive/drift를 압도하지는 않는다. 가장 단순한 상수·직선 baseline과 사실상 같은 구간에서 경쟁한다는 얘기다. Kronos가 두 데이터 모두에서 3~4배 나쁜 쪽으로 벌어지는 것과 대비된다.
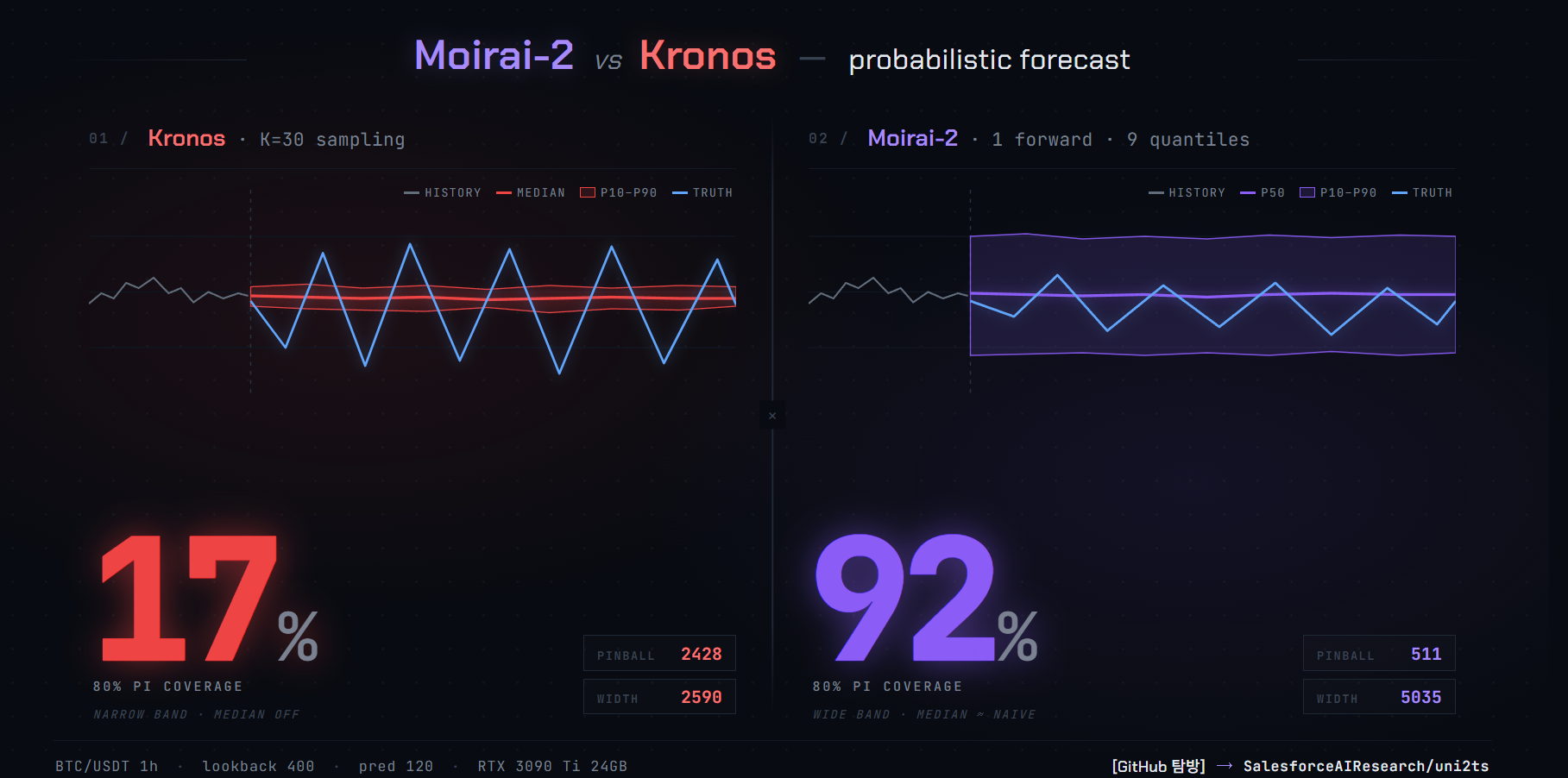
확률 예측 — 격차가 여기서 드러난다
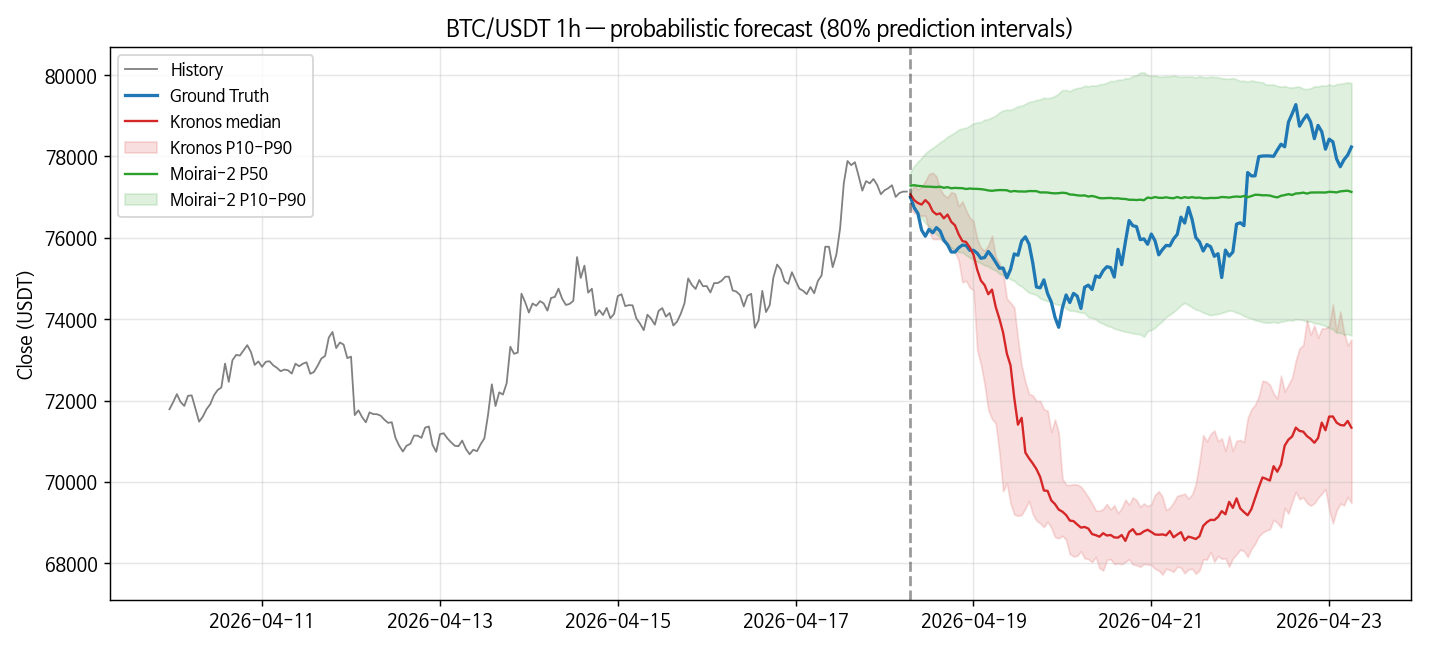
| method | pinball (9-level avg) | cov80 (P10~P90) | mean interval width |
|---|---|---|---|
| kronos (K=30) | 2428 | 0.167 | 2590 |
| moirai2 (1 forward) | 511 | 0.917 | 5035 |
Moirai-2의 pinball loss가 Kronos 대비 4.75배 낮다. 한편 80% PI coverage(= P10~P90 밴드 안에 truth가 들어있는 비율)는 Moirai-2가 91.7% (약간 over-covered), Kronos는 16.7% — 심각한 under-coverage다. Kronos의 interval은 Moirai-2보다 절반 좁지만, 그 좁은 밴드가 truth를 거의 못 감싼다.
| method | pinball | cov80 | mean interval width |
|---|---|---|---|
| kronos (K=30) | 59314 | 0.000 | 20060 |
| moirai2 (1 forward) | 12316 | 0.283 | 49018 |
삼성에서는 더 극단적이다. Kronos의 80% PI coverage가 0.0 — 60 step 전부에서 P10~P90 밖. K=30 samples가 형성하는 narrow band가 처음부터 truth와 멀리 있는 median을 중심으로 밀착돼 있기 때문이다. Moirai-2도 coverage 0.283로 under-covered지만 pinball loss는 여전히 4.8배 낮다.
이 결과가 전하는 건 점수 자체의 우위만은 아니다. 구조의 차이에 가깝다. 샘플링 기반 probabilistic forecast는 temperature/top_p를 높여 interval을 넓히면 coverage는 오를지 모르지만 pinball은 나빠지는 trade-off에 갇혀 있다. quantile head는 그 trade-off를 학습 시점에 pinball 자체를 최적화해 흡수한다. 샘플링 횟수를 늘려도 해결되지 않는 차이다.
다만 Moirai-2도 삼성 coverage 0.283처럼 특정 window에서는 interval이 truth의 drift를 못 따라간다. M4 200 시리즈 쪽(0.923 median)과 차이가 크다. 이는 단일 window calibration의 태생적 변동성이라 봐야 하고, 글 한 편에서 단정할 얘기는 아니다.
그런데 — Moirai-2 coverage 92%가 정말 "잘 예측한다"인가?
이 숫자를 prediction skill로 읽기 전에 한 번 멈출 필요가 있다. 앞서 point metric에서 Moirai-2 MAPE 1.87%는 naive last-value 1.91%와 사실상 tie였다. 그리고 뒤에 나올 sanity check에서 재확인하겠지만 Moirai-2 point forecast의 std(69.9)가 truth std(1323)의 약 5%에 불과하다. 모델이 BTC의 추세나 변동을 추종하는 게 아니라 중앙값 근처에 납작하게 그리는 상태라는 뜻이다.
그 상태에서 P10-P90 밴드 width가 5,035 USDT(truth 전체 변동 범위의 대부분을 덮음) 로 넓으면 truth의 wild한 움직임이 자연스럽게 밴드 안쪽에 들어간다. 이게 coverage 92%의 내막이다. "prediction skill + calibrated uncertainty"가 아니라 "보수적 point + 넓은 uncertainty"의 조합. Kronos는 반대 쪽 실패 — 뭔가 예측하려 시도는 하지만 median도 빗나가고 band도 좁아 cover 못함.
즉 금융 OOD에서 둘 다 "의미 있는 추세 예측"은 못 한다. Moirai-2가 이겼다기보다, 둘이 다른 방식으로 실패하고 있고, 그중 Moirai-2 쪽이 자기 불확실성을 훨씬 정직하게 표시하는 그림이다. pinball 5× 차이는 이 "정직성 차이"의 정량화에 가깝지 "예측 실력 차이"의 정량화가 아니다.
이 구조는 M4 weekly 같은 in-distribution에선 좀 더 긍정적으로 해석할 수 있다. 그쪽에선 point metric(median MAPE 2.73% < naive 2.88%)에서도 Moirai-2가 일관되게 앞서고 coverage 0.92도 유지되니, "정직한 uncertainty + 약하지만 점 예측에서도 개선"이라고 말할 수 있다. 금융 OOD에서 그렇게 말하기 어려울 뿐.
결과 B mini — M4 weekly (in-distribution)
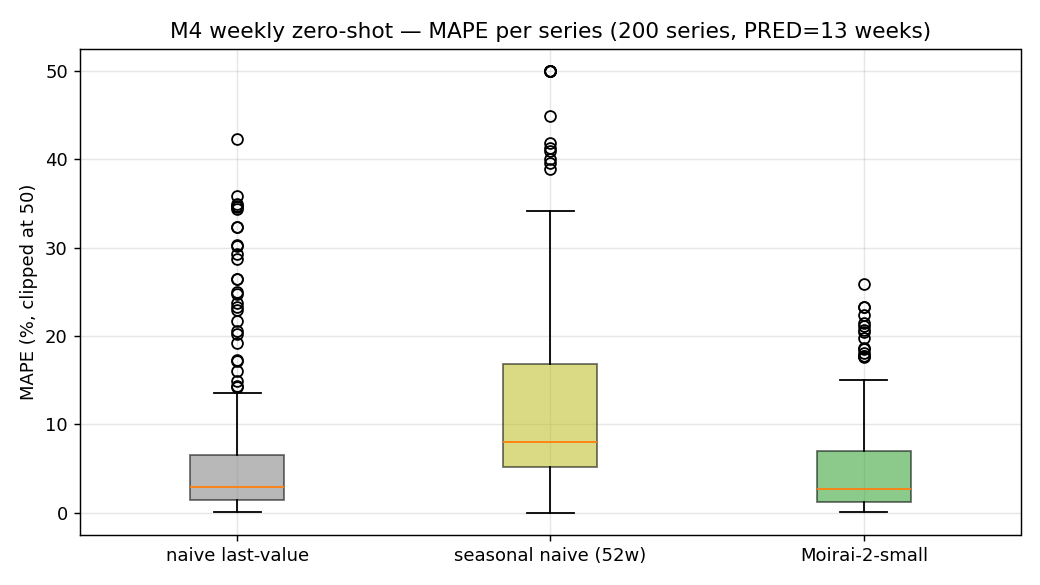
| method | MAPE_median | MAPE_mean | MASE_median | MASE_mean |
|---|---|---|---|---|
| naive last-value | 2.88 | 6.61 | 0.33 | 0.86 |
| seasonal naive (52w) | 8.01 | 12.96 | 1.00 | 1.00 |
| moirai2-small | 2.73 | 5.06 | 0.31 | 0.64 |
같은 Moirai-2-small을 M4 weekly 200 시리즈에 돌린 결과다. Moirai-2가 median MAPE에서 naive last-value를 0.15%p 차이로 이긴다 (2.73% vs 2.88%). 차이의 크기는 BTC와 비슷해 보이지만, 여기서 벌어지는 지점은 평균이다: mean MAPE 5.06% vs 6.61%. tail 외곽치 시리즈에서 Moirai-2가 네이티브 대비 훨씬 안정적이라는 뜻이다. p90(MAPE 상위 10%)으로 가도 14.16% vs 20.71%로 격차가 더 크다.
 ![]
![]
MASE(= MAE / MAE_seasonal_naive)로 보면 median 0.31 — seasonal naive 대비 약 1/3. seasonal naive 자체는 M4 weekly에서 힘을 못 쓰는데(많은 시리즈가 주별 1년 cycle을 안 가짐), naive last-value가 의외로 견고하다 (MASE median 0.33). 그 naive last-value를 Moirai-2가 일관되게 끌어내리는 그림이다.
확률 예측에서도 80% PI coverage median 0.923 — 기대값 0.8에 근접한 약간 over-covered 영역. M4 weekly 200 시리즈 전체에 걸쳐 calibration이 상당히 안정적이다. 이게 Moirai-2가 "in-distribution이라 잘 된다"의 구체적 모습이다.
Moirai-2 출력이 진짜 context를 본 건가 — sanity check
결과 A의 플롯을 보고 있으면 자연스럽게 의심이 든다. "Moirai-2 forecast가 naive에 너무 가깝게 붙어 있다 — 혹시 내가 context·freq·split 어딘가를 잘못 세팅해서 모델이 실제로는 last value만 뱉고 있는 거 아닌가". 점수로 정리하면 BTC에서 MAPE 1.87 vs naive 1.91로 0.04%p 차이, 눈으로 봐도 거의 겹쳐 보이는 구간이 있어서 합리적 의심이다. 짧은 script(sanity_check.py)로 네 가지 테스트를 돌렸다.
(1) forecast가 상수인가? BTC forecast의 std=69.9, diff std=20.0, mean|fc − last_value|=191 USDT. naive-last였다면 세 수치 전부 0이어야 한다. 상수 아님. 다만 truth std(1323)의 약 5% 수준이라 — 변동은 있지만 "좁게 그려 나오는" 상태.
(2) context ablation — 가장 결정적. 같은 BTC history를 네 가지로 변형해서 forecast mean이 어떻게 움직이는지 봤다.
| 입력 변형 | history last | forecast mean | 해석 |
|---|---|---|---|
| (a) 원본 | 76,738 | 76,887 | baseline |
| (b) −20k shift | 56,738 | 56,887 | delta 정확히 20,000.00 |
| (c) 완전 상수 입력 | 76,738 | 76,738 | forecast diff std 0.000000 |
| (d) 시간 역전 | 68,266 | 67,301 | 같은 값들이지만 순서 다름 → 다른 forecast |
(b)의 결과가 결정적이다. 76,887 − 56,887 = 20,000.00 — 만약 모델이 last value만 무시하고 뱉는다면 delta가 19,999.xx 같은 노이즈 섞인 값이 나왔을 것이다. delta가 정확히 20k로 맞는 건 Moirai-2가 context 전체를 읽고 scale을 반영해 forecast 분포를 이동한다는 얘기다.
(3) sin wave 연장. 명확한 패턴(sin 파형 400 step)을 입력으로 주고 forecast 60 step이 true sin 연장과 얼마나 일치하는지 측정. correlation 0.9988. 패턴이 있으면 거의 완벽히 이어간다 — 모델 능력 자체는 확실.
(4) context 400 vs 100. context 길이를 바꾸면 forecast mean이 1,049 USDT 이동하고 std도 20 → 410으로 변한다. 길이에 따라 output이 실제로 달라짐.
네 테스트 결과를 묶으면 코드·변수·모델 세팅은 정상이다. "그런데 왜 BTC·삼성 forecast가 눈으로 naive처럼 보이는가"에 대한 답은 모델 버그가 아니라 pinball loss로 학습된 quantile head의 전형적 경향이다.
- 점 예측(P50)은 보수적·납작하게 — pinball loss는 outlier에 약하게 반응하도록 설계돼 있고, 특히 truth 변동이 크고 예측 가능한 구조가 적은 신호(금융 raw price 같은)에서는 모델이 중앙값 근처에 납작하게 그리는 게 loss 관점에서 유리
- 반면 quantile interval은 넓게 — P10~P90 width가 BTC 5,066 / 삼성 49,018로 truth 변동폭을 상당히 덮음. coverage 92%(BTC)·28%(삼성)에서 볼 수 있듯 uncertainty는 수치로 인정
결국 "forecast가 naive에 붙은 것처럼 보인다"는 건 visible한 단면이고, 같은 모델이 quantile 쪽에선 확연히 다른 일(Kronos 대비 pinball 5배 낮음)을 하고 있다. 이게 003/004의 turboquant 글에서 했던 "헤드라인 숫자가 어느 전제 위에서 성립하는가"의 Moirai-2 버전이다.
산출물: experiments/2026-W17-moirai2/sanity_check.py · outputs/sanity.log.
두 결과를 옆에 놓으면
| Moirai-2 vs naive_last | Kronos vs naive_last | Moirai-2 probabilistic (해석 주의) | |
|---|---|---|---|
| BTC 1h (OOD) | MAPE 1.87 vs 1.91 — 거의 tie | 6.90 vs 1.91 — 3.6× worse | cov 0.92 / pinball 5× < Kronos — 단 median이 거의 flat이라 "넓은 band 덕" 해석 |
| Samsung daily (OOD) | 15.85 vs 18.37 — 약 14% 개선 | 64.60 vs 18.37 — 3.5× worse | cov 0.28 / pinball 4.8× < Kronos — 역시 "보수적 point + 넓은 uncertainty" |
| M4 weekly (in-dist, 200 series) | median 2.73 vs 2.88 — 일관, mean 5.06 vs 6.61 | — | cov median 0.92 + point도 이김 → 점 + 확률 둘 다 개선 |
Moirai-2의 point 이득은 OOD에선 "거의 tie ~ 약간 이김" 수준인데, in-distribution으로 오면 일관된 개선(mean gap이 벌어지고 p90이 좁아짐)이 된다. 중요한 건 absolute 점수 자체가 크게 다른 게 아니라, 시리즈 간 variance가 줄어드는 방향이라는 점이다.
확률 예측 쪽에서 Kronos 대비 5배 낮은 pinball은 두 도메인 모두에서 관찰되지만, 이게 "Moirai-2가 더 잘 예측한다"로 번역되는 건 in-distribution(M4) 쪽에서만이다. 금융 OOD에선 Moirai-2도 추세 추종은 못 하고, 다만 자기 불확실성을 넓게 정직하게 표시해서 "정직성 metric"으로서의 pinball만 좋게 나온 쪽에 가깝다. quantile head vs sampling의 구조적 이득 자체는 사라지지 않지만, 그게 곧 prediction skill은 아니라는 얘기.
함정 / 문서에 없는 팁
(1) numpy 강제 다운그레이드가 필요하다
uni2ts는 numpy~=1.26.0을 pin하고 있는데, uv pip install ccxt pykrx matplotlib를 나중에 돌리면 둘 중 하나가 numpy 2.x를 끌어온다. 이 상태로 moirai2 import하면 lightning → torchmetrics → scipy.signal 경로에서 ImportError: numpy.core.multiarray failed to import가 터진다. scipy가 numpy 1.x ABI로 컴파일됐는데 런타임 numpy 2.4.4가 올라온 충돌.
해결은 한 줄이다.
uv pip install "numpy~=1.26.0"uv는 editable로 설치된 uni2ts의 pin을 재해결 그래프에서 soft하게 취급하는 것 같다. ccxt/pykrx 설치 후 numpy 다운그레이드를 한 번 더 쳐줘야 한다.
(2) Samsung(pykrx) daily에서 business-day freq 강제 금지
df.index.freq = pd.tseries.offsets.BusinessDay()를 넣으면 pandas가 _validate_frequency에서 ValueError를 낸다. 이유는 pykrx 결과가 실제로는 주말+공휴일(설날·추석·어린이날 등)이 빠진 불규칙 거래일 배열이라서, pandas 입장에선 "BusinessDay가 아니다"라고 보는 것.
해결은 index freq를 그냥 놓고, gluonts PandasDataset에 freq="D"로만 전달한 다음, 내부에 쓸 timeline은 pd.date_range("2024-01-01", periods=N, freq="D") 합성으로 대체했다. Moirai-2는 patch 기반이고 값 시퀀스만 중요해서 실제 calendar date와 이 합성 date가 일치하지 않아도 결과는 같다 — 약간 찜찜하지만 이 글 스코프에선 수용했다.
(3) Moirai2Forecast는 patch_size 인자를 받지 않는다
README 예제를 빠르게 읽으면 Moirai2Forecast(..., patch_size=16, ...) 같은 라인이 있는 것처럼 보이는데, 실제 시그니처는
Moirai2Forecast(
prediction_length: int,
target_dim: int,
feat_dynamic_real_dim: int,
past_feat_dynamic_real_dim: int,
context_length: int,
module_kwargs: Optional[dict] = None,
module: Optional[Moirai2Module] = None,
)이다. patch_size는 Moirai2Module.from_pretrained(...)의 config에서 내려오는 값이라 wrapper 쪽에 따로 안 받는다. 사소한 함정이지만 초기 한 번 막혀서 적어둔다.
한계 (단일 사례 보고로서의)
- BTC/삼성 각 단일 window. 002와 비슷한 한계. 다른 시점·다른 변동성 구간에서는 숫자가 다를 수 있다. BTC는 고변동 구간에서 naive가 더 쉽게 깨지고, Moirai-2/Kronos의 상대 성능이 달라질 수 있다.
- Moirai-2 small 한 사이즈만. base/large는 공개 X. sample efficiency가 모델 크기에 어떻게 기대는지는 이 실험으로 답할 수 없다.
- 비교 대상 TSFM은 Kronos 하나. 같은 자리에 Chronos-2, TimesFM, Toto 같은 후보가 올라가면 그림이 더 풍성해진다. 그게 이 글의 다음 예고.
- 확률 평가는 9-level pinball + 80% PI coverage로 단순화. proper CRPS, log-score 같은 지표는 안 돌렸다.
- M4 weekly는 Moirai-2 훈련 도메인일 수 있음 (명시적 data leakage 확인은 못 했지만 M4가 GIFT-Eval pretrain에 포함되는 패턴이 있음). 따라서 B의 숫자는 "엄격 zero-shot"이 아니라 "pretraining covered의 재평가"에 가깝다.
- context 400은 공식 예제(1680)의 약 1/4. Moirai-2 훈련 시 본 window 길이 분포가 비공개라 "훈련 분포 내부에 있다"고 단정할 수 없다. 002와의 비교 대칭을 맞추느라 이 길이를 유지했지만, context를 늘려 다시 재보면 Moirai-2 숫자가 더 좋아질 여지는 열려 있다.
- 실행 당일 BTC/삼성 fetch 결과에 의존 — 재실행하면 같은 코드로도 window가 이동해 숫자가 달라진다. 이 글에 박힌 숫자는 2026-04-23 16시 기준 단일 snapshot이다.
정리
Salesforce/moirai-2.0-R-small은 11.39M 파라미터 / 45.6 MB의 작은 모델이다. 3090 Ti 24GB에 올리는 데 VRAM 걱정은 0순위 아래. 제약은 torch<2.5 pin 하나다.- 금융 OOD(002 Kronos의 그 BTC·삼성)에선 Moirai-2가 naive·drift와 비슷한 구간에 붙는다 — "이긴다"고 하기엔 너무 작은 차이, "진다"고 하기엔 살짝 위. Kronos가 같은 자리에서 3~4배 나쁘게 벌어지는 것과는 확연히 다르다.
- M4 weekly 200 시리즈 (in-distribution)에선 Moirai-2가 median·mean·p90 모두에서 naive last-value를 일관되게 끌어내린다. 수치 자체의 차이보다 variance 축소가 눈에 들어오는 결과.
- 확률 예측은 해석 주의. Moirai-2가 Kronos 대비 pinball 5배 낮은 건 사실이지만, 금융 OOD에서 이 우위는 "예측이 좋다"보다 "점 예측이 거의 flat + 넓은 band로 truth를 우연히 덮음"에 가깝다. sanity check에서 확인한 대로 Moirai-2 point forecast std는 truth std의 5% 수준. coverage 92%는 predictive power가 아니라 band width 덕이다. Kronos는 반대 — 좁은 band에 빗나간 median. 둘 다 금융 추세 추종은 실패고, uncertainty 표현의 정직성에서만 갈렸다. 다만 M4 같은 in-distribution으로 가면 점 예측에서도 Moirai-2가 naive를 일관 개선하므로, probabilistic 우위는 "도메인에 따라 정직성 지표도 되고 실력 지표도 된다".
- 002의 "Kronos zero-shot이 naive에 짐" → 014의 "Moirai-2 zero-shot도 금융 OOD에선 추세 추종 실패, 다만 uncertainty를 정직하게 표시 / in-distribution에선 점 예측까지 분명한 개선." 같은 금융 데이터 위에서 TSFM 두 세대를 같은 설계로 비교할 수 있었다는 자체가 이 글의 소득.
참고
- SalesforceAIResearch/uni2ts — Moirai 1.x/MoE/2 공식 레포
- Salesforce/moirai-2.0-R-small — 이번에 쓴 11.39M 가중치 (cc-by-nc-4.0)
- Moirai-2 논문 — "When Less Is More" (arXiv 2511.11698)
- GIFT-Eval 벤치마크 — 37개 TSFM 경쟁
- NeoQuasar/Kronos-small + shiyu-coder/Kronos — 002에서 쓴 모델·레포
- 002. Kronos zero-shot — BTC와 삼성전자에서 본 결과 (선행 글, 같은 데이터 로더 재활용)
- 본 실험 산출물:
experiments/2026-W17-moirai2/(run_financial.py,run_gift_mini.py, NOTES.md, outputs 8개)
