Rethinking the Role of LLMs in Time Series Forecasting
Xin Qiu, Junlong Tong, Yirong Sun, Yunpu Ma, Wei Zhang, Xiaoyu Shen
arXiv 2602.14744 (v1 2026-02, v2 2026-03) · cs.CL
Code: github.com/EIT-NLP/LLM4TSF
한 줄 요약
"LLM은 시계열 예측에 별 도움이 안 된다"는 최근 회의론을 80억 관측치 규모로 다시 검증해서 뒤집는 재평가 논문이다. LLM4TS는 특히 cross-domain 일반화에서 뚜렷한 이득을 보였고, 90% 이상의 task에서 pre-alignment가 post-alignment를 앞섰다. 사전학습 지식은 분포 시프트 상황에서, LLM 아키텍처 자체는 시간 동역학 모델링에서 각각 다른 역할로 보완하는 것으로 나타났다.
왜 이 논문이 흥미로운가
LLM을 시계열 예측에 갖다 붙이는 시도(LLM4TS)는 2023년 즈음부터 활발해졌다. Time-LLM(시계열 패치를 텍스트 토큰으로 reprogramming)이나 GPT4TS(GPT-2의 self-attention·FFN을 동결한 채 시계열에 fine-tuning) 같은 대표 시도들이 잇따라 나왔고, 한동안은 "LLM 사전학습 지식이 시계열에도 transfer된다"는 입장이 우세였다.
그런데 작년부터 정반대 방향의 회의론이 강해졌다. 대표적으로 Are Language Models Actually Useful for Time Series Forecasting? (2024)이 다음과 같은 주장을 내놨다:
- LLM 백본을 키워도 시계열 성능은 별로 안 오른다.
- LLM 가중치를 무작위로 초기화해도 결과가 비슷하다 → 사전학습 지식이 사실상 안 쓰이는 거 아니냐.
- 결론: LLM을 시계열에 가져다 붙이는 건 계산 낭비다.
이 논문은 그 회의론을 평가 범위가 좁아서 생긴 착시라고 주장한다. 결론을 바꾸기 위해 새 모델을 제안하는 게 아니라, 훨씬 큰 규모의 재평가로 같은 질문에 다른 답을 낸다는 점이 특징이다. 새 SOTA 모델을 내놓는 논문이 아니라 "LLM4TS는 언제 효과 있는가"를 정리하는 논문에 가깝다.
배경 — 두 가지 alignment 패러다임
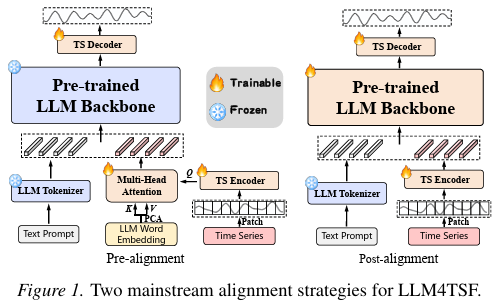
이 논문이 비교하는 핵심 축은 시계열 임베딩을 LLM에 어떻게 "맞춰 넣을지" 의 두 가지 방식이다.
Pre-alignment (LLM frozen)
LLM에 입력하기 전에 시계열 표현을 LLM의 토큰 공간과 정렬시킨다.
- 메커니즘: 시계열 임베딩 을 query로, LLM 단어 임베딩의 PCA 주성분을 key/value로 두는 attention. 어휘 전체( 차원) 대신 PCA로 압축한 ()을 사용한다.
- LLM 파라미터는 frozen — 사전학습 지식을 그대로 보존한다.
- 즉 "시계열을 텍스트 모달리티 쪽으로 끌어와서 LLM에 넣는다"는 발상.
Post-alignment (LLM fine-tuned)
시계열을 일단 LLM에 통과시킨 뒤 나중에 출력 단에서 시계열 공간으로 사상한다.
- 메커니즘: 시계열 임베딩 와 prompt 임베딩 를 함께 LLM에 넣고 를 계산.
- LLM 파라미터까지 같이 학습 — 시계열 인코더와 LLM 둘 다 업데이트.
- "시계열과 텍스트를 동시에 모델링한다"는 발상에 가깝다.
이 두 접근의 우열을 17개 시나리오에서 직접 비교하는 게 이 논문의 첫 번째 큰 실험이다.
실험 설계
데이터셋 (17개)
| 구분 | 데이터셋 |
|---|---|
| In-domain (10) | ETTh1, ETTh2, ETTm1, ETTm2, Weather, Traffic, Exchange, Covid, ECL, NN |
| Out-of-domain (7) | Wind, Solar, AQShunyi, CzenLan, ZafNoo, NASDAQ, PEMS |
10개 in-domain + 7개 out-of-domain으로 총 17개. OOD 데이터셋을 별도로 두고 평가한다는 점이 이 논문의 차별화 포인트다 — 기존 회의론 논문들은 in-domain만 봤기 때문에 LLM4TS의 장점이 안 보였다는 게 저자들의 진단.
기타 설정
- Horizons: {96, 192, 336, 720} 4단계
- Lookback: 512 timesteps
- LLM backbone: 주로 GPT-2, 보조로 Qwen-3도 테스트
- Baselines: Chronos, UniTS, Moirai 같은 시계열 foundation 모델들 (DLinear/PatchTST 같은 전통 강자는 메인 비교에 안 들어감)
- 총 관측치: 약 80억
분해 실험 — 세 가지 변종
이 논문의 핵심은 LLM4TS의 효과를 세 변종으로 나눠서 비교하는 거다.
- w/ pre-training: 사전학습된 LLM 그대로 사용 (full LLM4TS)
- w/o pre-training: 같은 아키텍처지만 가중치를 무작위 초기화
- w/o LLM: LLM 모듈 자체 제거, encoder-decoder만 사용
이 셋을 비교하면 pretraining 지식이 주는 이득과 LLM 아키텍처가 주는 이득을 분리할 수 있다.
주요 결과
1. Pre-alignment가 post-alignment를 압도한다
"pre-alignment methods outperform post-alignment approaches in over 90% of tasks"
OOD zero-shot 결과 일부 (MSE, 낮을수록 좋음):
| Dataset | Pre-align | Post-align | Chronos | UniTS | Moirai |
|---|---|---|---|---|---|
| Wind | 1.015 | 0.963 | 1.422 | 1.358 | 1.236 |
| Solar | 0.228 | 0.274 | 0.434 | 0.871 | 0.936 |
| AQShunyi | 0.612 | 0.688 | 0.808 | 0.890 | 0.668 |
Pre-alignment가 거의 모든 OOD 데이터셋에서 베이스라인 foundation 모델들(Chronos·UniTS·Moirai)을 이기거나 비슷한 성능을 보였다.
2. Pretraining과 아키텍처는 상호 보완적이다
세 변종(w/ pre-train, w/o pre-train, w/o LLM)을 비교한 결과, 흥미로운 분업이 드러났다.
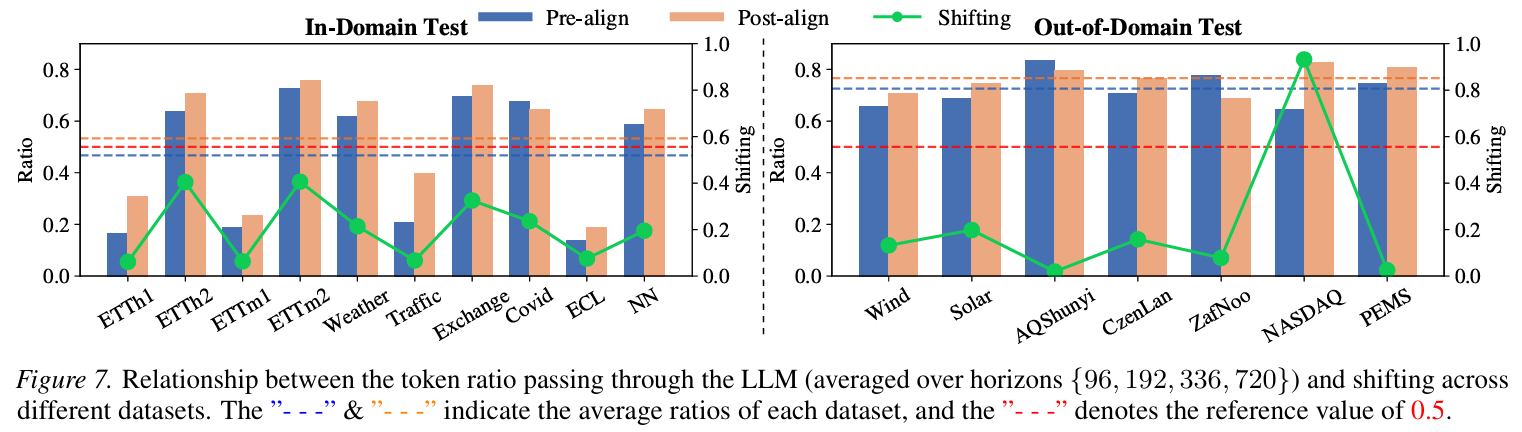
- 사전학습 지식: 데이터 분포가 학습 분포와 다른(distribution shifting이 큰) 상황에서 결정적이다.
"when shifting is strong, pretrained LLM parameters are more likely to provide meaningful performance benefits"
- LLM 아키텍처 자체: 시간 동역학(transition)이 복잡한 데이터에서 강하다. 사전학습 없이 무작위 초기화한 트랜스포머도 단순 인코더-디코더보다 낫다.
"when transition is high, a trainable Transformer backbone, even without pretrained LLM parameters, outperforms the w/o LLM variant"
즉 LLM4TS의 이득은 "사전학습이냐 아키텍처냐"의 단일 기여가 아니라 둘이 다른 데이터 특성에 기여한다는 분업 구조라는 게 이 논문의 핵심 발견.
3. Token-level routing analysis — LLM이 언제 쓰이는지 직접 본다
가장 흥미로운 ablation 중 하나. 저자들은 시계열 토큰마다 LLM을 통과시킬지 말지 결정하는 router를 학습시킨다 (Gumbel-Softmax로 미분 가능하게 만든 binary routing).
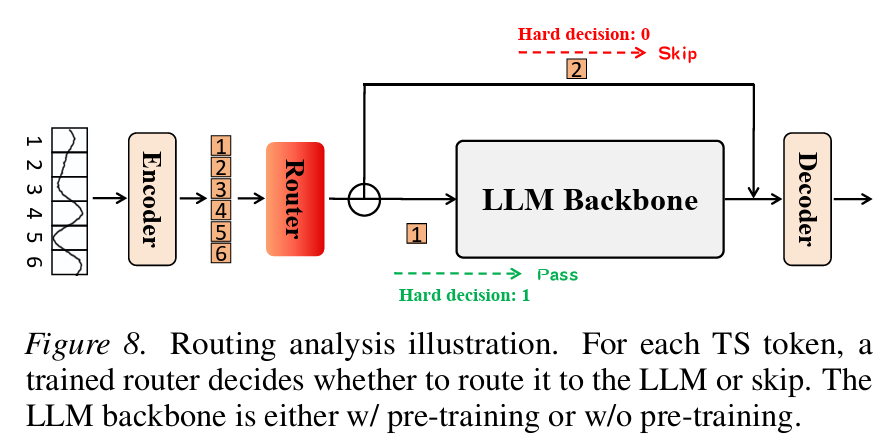
router의 결정을 분석하면:
| Dataset | w/ pre-train (pass ratio) | w/o pre-train (pass ratio) |
|---|---|---|
| ETTh2 | 64% | 43% |
| ETTm2 | 73% | 28% |
| Wind (OOD) | 66% | 14% |
사전학습 LLM은 토큰의 60~70%를 LLM으로 라우팅하는데, 무작위 초기화 LLM은 14~43% 수준에 그친다. 즉 pre-trained 모델이 더 자주 LLM 경로를 "선택"한다 = 그 경로가 실제로 도움이 된다는 신호다.
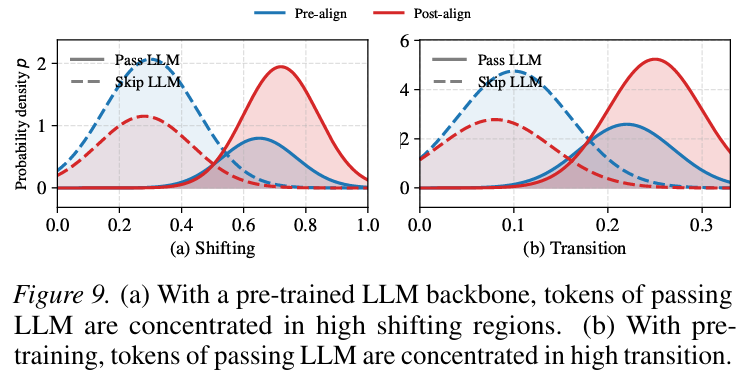
게다가 router가 LLM으로 보내는 토큰들은 distribution shifting이 큰 영역에 집중돼 있다 (Figure 7, 9). LLM의 사전학습 지식이 OOD/shifting 영역에서 가장 활발하게 동원된다는 정량적 증거.
4. Prompt가 무시 못 할 차이를 만든다
저자들은 시계열 입력과 함께 데이터셋 식별자 + 통계 기술자(stationarity·trend 등) + 배경 정보를 텍스트 prompt로 함께 넣는다. 이 prompt를 빼면:
"omitting prompts weakens the effectiveness of LLMs and leads to noticeable performance degradation, an effect that is particularly pronounced in out-of-domain scenarios"
특히 OOD 상황에서 prompt 제거의 손실이 크다. 단순히 LLM 파라미터를 키우는 게 아니라 의미 있는 텍스트 안내가 따로 필요하다는 결론.
5. LLM 자르기/축소는 손해다
기존 일부 LLM4TS 연구들은 효율성 위해 LLM의 절반 정도 layer만 쓰는 식으로 축소했다. 이 논문은 이런 축소가 성능을 깎는다고 보고한다.
"layer truncation as in prior work leads to noticeable performance degradation"
또 LoRA 같은 PEFT보다 full-parameter fine-tuning이 가장 잘 동작했다 (Figure 10). "분포 혼합이 커질수록 온전한 LLM이 필수" 라는 결론을 정량적으로 뒷받침.
6. 큰 LLM이 항상 좋은 건 아니다
저자들은 GPT-2 외에 Qwen-3도 테스트했다.
"stronger general capabilities do not consistently translate into improved performance"
NLP 일반 성능이 더 좋다고 시계열 forecasting 성능이 자동으로 따라오지는 않는다. Alignment 설계가 잘못돼 있으면 백본을 키워도 무의미하다는 메시지.
한계 — 저자 본인이 짚은 부분
논문 discussion에서 명시한 한계:
- 분포 의존성: "performance remains sensitive to data distribution, preventing uniformly strong results across all scenarios"
- 단순 스케일업 무의미: "Blindly scaling up LLM backbones does not necessarily lead to better performance"
- 저-shifting 데이터셋에서는 사전학습 이득 없음: ETTh1, Traffic, ECL 같은 데이터셋에서는 encoder-decoder만으로 충분하다. 즉 모든 시계열에 LLM을 붙여야 한다는 주장은 아니다 — 이 점은 이전 회의론의 일부 결론을 부분적으로 인정하는 셈이다.
짧은 코멘트
이 논문에서 가장 인상 깊은 건 token-level routing analysis다. LLM의 효과를 "전체적으로 켜고 끄는" 단일 ablation이 아니라 시계열 토큰 단위로 LLM이 언제 동원되는가까지 정량화한 접근이 좋다. 사전학습 LLM이 distribution shifting이 큰 영역에 LLM 경로를 더 자주 선택한다는 결과는, 단순히 "LLM이 도움이 된다"보다 훨씬 구체적인 메시지를 준다.
동시에 흥미로운 건 이 논문이 LLM4TS 회의론에 대한 정면 반박이 아니라는 점이다. 두 진영의 결과가 충돌하는 게 아니라 평가 분포가 달랐을 뿐이라는 메타 관찰에 가깝고, 이 논문도 ETTh1·Traffic 같은 저-shifting 데이터셋에서는 사전학습 이득이 거의 없다는 점을 인정한다. 결국 "LLM4TS는 언제 도움이 되는가"의 조건을 명확히 한 게 가장 큰 기여로 보인다.
참고
- arXiv: https://arxiv.org/abs/2602.14744
- Code: https://github.com/EIT-NLP/LLM4TSF
- 반대편 입장: Are Language Models Actually Useful for Time Series Forecasting? (arXiv 2406.16964)
- 대표적 LLM4TS 모델: Time-LLM, GPT4TS
