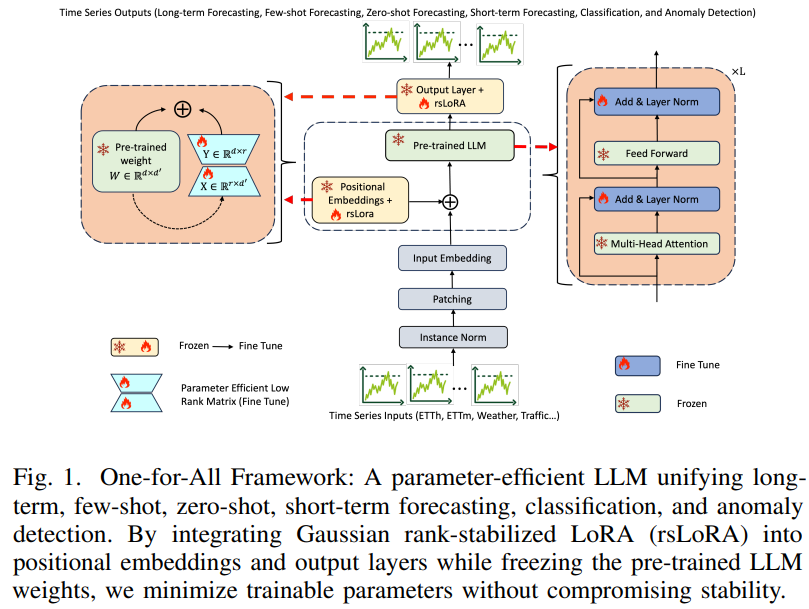
One-for-All: A Lightweight Stabilized and Parameter-Efficient Pre-trained LLM for Time Series Forecasting
Prasanjit Dey, Soumyabrata Dev, Bianca Schoen-Phelan
arXiv 2603.29756 (2026-03-31) · IEEE TKDE 투고 중
한 줄 요약
사전학습된 LLM 백본을 거의 그대로 얼리고, positional embedding과 output layer 단 두 군데에만 rank-16 rsLoRA 어댑터를 꽂아 시계열 예측에 적응시키는 경량 PEFT 방법이다. 총 파라미터 0.55M · 메모리 2.2 MiB로 GPT4TS(11.7M · 371 MiB) 수준의 정확도에 도달한다. 장기·단기·few-shot·zero-shot·분류·이상탐지 6개 시계열 태스크 전반에 "하나의 설정"으로 적용된다는 점이 제목 One-for-All의 의미다.
왜 이 논문이 흥미로운가
LLM4TS 연구는 크게 두 축으로 갈라져 있다. 한쪽은 성능을 밀어붙이는 쪽 — 시계열 토큰을 텍스트 공간으로 reprogramming하거나(Time-LLM) LLM 가중치 전체를 fine-tuning(GPT4TS)하는 방향이다. 다른 한쪽은 효율을 묻는 쪽 — 정말 이 큰 모델이 필요하냐, 얼마나 줄일 수 있냐는 질문이다.
이 논문은 후자에 속한다. 그런데 단순히 "작게 만들었다"가 아니라 LoRA의 rank 안정성 문제를 정면으로 다룬다는 점이 특이하다. 저자들은 표준 LoRA가 낮은 rank에서 gradient가 불안정해진다는 기존 이론 결과를 받아서, scaling factor를 대신 로 바꾼 rsLoRA(rank-stabilized LoRA) 를 시계열 PEFT에 가져왔다. 새 모델을 만든 논문이라기보다는 "기존 PEFT 이론을 LLM4TS 세팅에 맞춰 검증한" 논문에 가깝다.
바로 직전에 리뷰했던 Rethinking the Role of LLMs in Time Series Forecasting이 "LLM4TS가 언제 효과 있는가"를 매크로하게 정리한 글이라면, One-for-All은 "그 LLM4TS를 얼마나 작게 만들 수 있는가"를 미시적으로 답하는 글이라고 봐도 된다. 두 글을 같이 읽으면 LLM4TS의 언제와 어떻게가 맞춰진다.
배경 — LoRA와 rank 불안정성
LoRA 복습
LoRA(Low-Rank Adaptation)는 pretrained weight 를 동결한 뒤, 업데이트를 저차원 분해로 근사하는 PEFT 방법이다.
여기서 , , . 는 Gaussian으로, 는 0으로 초기화해서 초기에 이 되게 맞춘다. 학습 가능한 파라미터는 개로, full fine-tuning의 개에 비해 훨씬 적다.
문제: rank가 작을수록 gradient가 죽는다
표준 LoRA의 scaling은 rank가 커질수록 업데이트가 빠르게 0으로 수렴해 gradient 신호가 소실된다는 게 알려져 있다. 반대로 rank가 너무 작으면 표현력이 부족해 학습이 불안정해진다. "작을수록 가볍지만 불안정해진다"는 tradeoff가 존재한다.
rsLoRA — scaling
논문은 Theorem 1로 scaling을 쓰면 forward·backward pass에서 차 모멘트가 rank에 무관하게 상수로 유지된다는 것을 보인다. 직관적으로 말하면 로 나누기 때문에 rank가 작아져도 activation 크기가 유지되고, rank가 커져도 폭발하지 않는다. 그래서 낮은 rank에서도 gradient가 살아 있다는 게 rsLoRA의 핵심 이론적 이득이다.
이 차이 하나 덕분에 rank 16에서도 학습이 안정적으로 이루어진다는 게 이 논문의 실험 파트에서 검증된다.
접근 방식 / 제안 방법
어디에 어댑터를 꽂는가
One-for-All은 pretrained LLM 백본(논문에선 GPT-2 family)을 다음과 같이 쓴다.
- self-attention 가중치: 완전 frozen. 건드리지 않는다.
- FFN layer: frozen.
- positional embedding: 여기에 rsLoRA 어댑터 주입.
- output projection (시계열 예측 헤드): 여기에 rsLoRA 어댑터 주입.
즉 LLM 본체의 의미 공간은 건드리지 않고, 입력 부분(positional)과 출력 부분(projection) 두 경계면만 살짝 비틀어서 시계열 형태로 바꾼다는 구도다. 기존 GPT4TS가 self-attention을 포함해 상당 부분을 fine-tuning했던 것과 대조된다.
왜 positional embedding인가
시계열과 텍스트의 가장 큰 차이는 순서 의미다. 텍스트에서 "다음 토큰"이 문법·의미 단위라면, 시계열에서는 규칙적인 샘플링 간격과 시간 동역학이다. 저자들은 이 차이를 흡수하는 지점이 positional embedding이라고 본다. output 쪽 어댑터는 LLM의 hidden state를 다시 시계열 공간으로 사상하는 역할이다.
학습 가능 파라미터
| 항목 | 크기 |
|---|---|
| positional rsLoRA () | rank 16 |
| output rsLoRA () | rank 16 |
| 합계 | 0.55M (≈ 2.2 MiB) |
이 숫자가 이 논문의 얼굴이다. 비교군:
| Model | Params | Memory |
|---|---|---|
| One-for-All | 0.55M | 2.2 MiB |
| TimesNet | 0.63M | 2.9 MiB |
| TIME-LLM | 6.46M | 3907 MiB |
| GPT4TS | 11.7M | 371 MiB |
| Autoformer | 10.53M | 62.6 MiB |
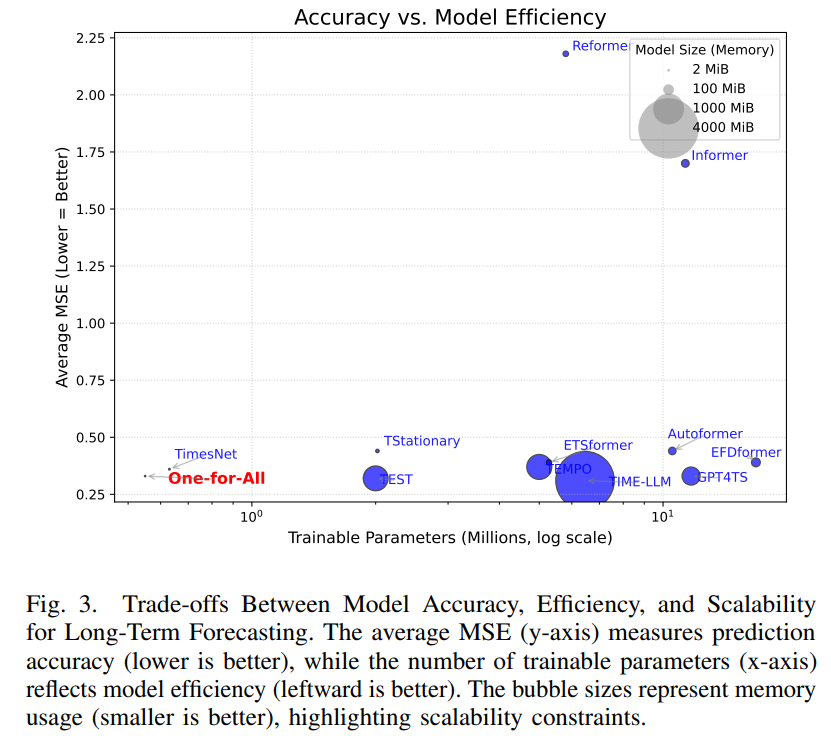
크기만 보면 TimesNet과 같은 급까지 내려왔고, 메모리 기준으론 TIME-LLM 대비 1776배 작다. 이 논문이 반복해서 자랑하는 포인트다.
실험 설계
| 항목 | 내용 |
|---|---|
| 태스크 | 장기예측, 단기예측(M4), few-shot(10%/5%), zero-shot(M3↔M4), 분류, 이상탐지 — 총 6종 |
| 데이터셋 | ETTh1/h2/m1/m2, Weather, M3, M4, UEA classification, SMD/MSL/SMAP/SWaT/PSM |
| Horizons | {96, 192, 336, 720} (장기), M4 각 frequency |
| LLM 백본 | GPT-2 계열 (frozen) |
| 베이스라인 | GPT4TS, TIME-LLM, TEST, TEMPO (LLM계) / FEDformer, Autoformer, Informer, Reformer, Non-Stationary Transformer, ETSformer (트랜스포머계) / TimesNet, LightTS (도메인 특화) |
| Metric | MSE/MAE (장기·few-shot), SMAPE/MASE/OWS (M4), sMAPE (zero-shot), F1 (이상탐지), Acc (분류) |
주요 결과
1. 장기 예측 — GPT4TS와 동률
5개 데이터셋 평균 MSE (horizon {96, 192, 336, 720} 평균, 낮을수록 좋음):
| Model | Params (M) | ETTh1 | ETTh2 | ETTm1 | ETTm2 | Weather | Avg |
|---|---|---|---|---|---|---|---|
| TIME-LLM | 6.46 | 0.41 | 0.34 | 0.33 | 0.25 | 0.23 | 0.31 |
| One-for-All | 0.55 | 0.43 | 0.36 | 0.36 | 0.26 | 0.23 | 0.33 |
| GPT4TS | 11.7 | 0.43 | 0.35 | 0.35 | 0.27 | 0.24 | 0.33 |
| TimesNet | 0.63 | 0.46 | 0.41 | 0.40 | 0.29 | 0.26 | 0.36 |
| Autoformer | 10.53 | 0.50 | 0.45 | 0.59 | 0.33 | 0.34 | 0.44 |
| Informer | 11.33 | 1.04 | 4.43 | 0.96 | 1.41 | 0.64 | 1.70 |
One-for-All(0.55M)이 GPT4TS(11.7M)와 정확히 같은 평균 MSE 0.33에 도달했다. TIME-LLM은 여전히 평균 0.31로 가장 좋지만 파라미터 11.8배, 메모리 1776배를 더 쓴다. 이 논문의 메인 셀링 포인트는 "정확도 1위 탈환"이 아니라 "같은 정확도 등급까지 크기를 떨어뜨렸다" 쪽이다.
2. Few-shot — 데이터 희소 상황
10% 데이터 few-shot 평균 MSE:
| Model | Params (M) | Avg MSE |
|---|---|---|
| TIME-LLM | 6.46 | 0.372 |
| GPT4TS | 11.7 | 0.400 |
| One-for-All | 0.55 | 0.416 |
| TimesNet | 0.63 | 0.526 |
5% 데이터에서는 One-for-All 0.464, GPT4TS 0.426, TIME-LLM 0.398. 데이터가 극단적으로 적어질수록 큰 LLM4TS 모델과의 격차가 조금 벌어지지만, TimesNet(같은 크기의 비-LLM 베이스라인)보다는 명확히 낫다. 저자들은 이 점을 "작은 파라미터 예산에서 LLM 사전학습 지식이 실제로 기여한다"는 증거로 제시한다.
3. Zero-shot — 데이터셋 이동
M3 학습 → M4 평가 / M4 학습 → M3 평가 (sMAPE, 낮을수록 좋음):
| 방향 | One-for-All | GPT4TS | TimesNet |
|---|---|---|---|
| M3 → M4 | 13.27 | 13.55 | 15.01 |
| M4 → M3 | 15.10 | 13.05 | — |
한 방향에선 이기고 한 방향에선 진다. 완전한 win은 아니고, zero-shot generalization에서는 pretrained LLM 백본 덕을 보는 부분과 못 보는 부분이 섞여 있다는 정도.
4. 분류·이상탐지 — 추가 태스크
시계열 분류(UEA benchmark 일부):
- Japanese Vowels 98%, SCP1 93%, Face Detection 68%
이상탐지(F1, 5개 데이터셋 평균):
| Model | Avg F1 |
|---|---|
| GPT4TS | 86.72 |
| TimesNet | 85.24 |
| One-for-All | 84.42 |
이상탐지에서는 평균 F1 기준 GPT4TS에 2.3p 뒤진다. 논문은 이를 "6개 태스크 전반에 걸친 one-for-all 적용성을 보이는 게 목적이고, 태스크별 SOTA 탈환이 목적은 아니다"라는 프레이밍으로 정리한다.
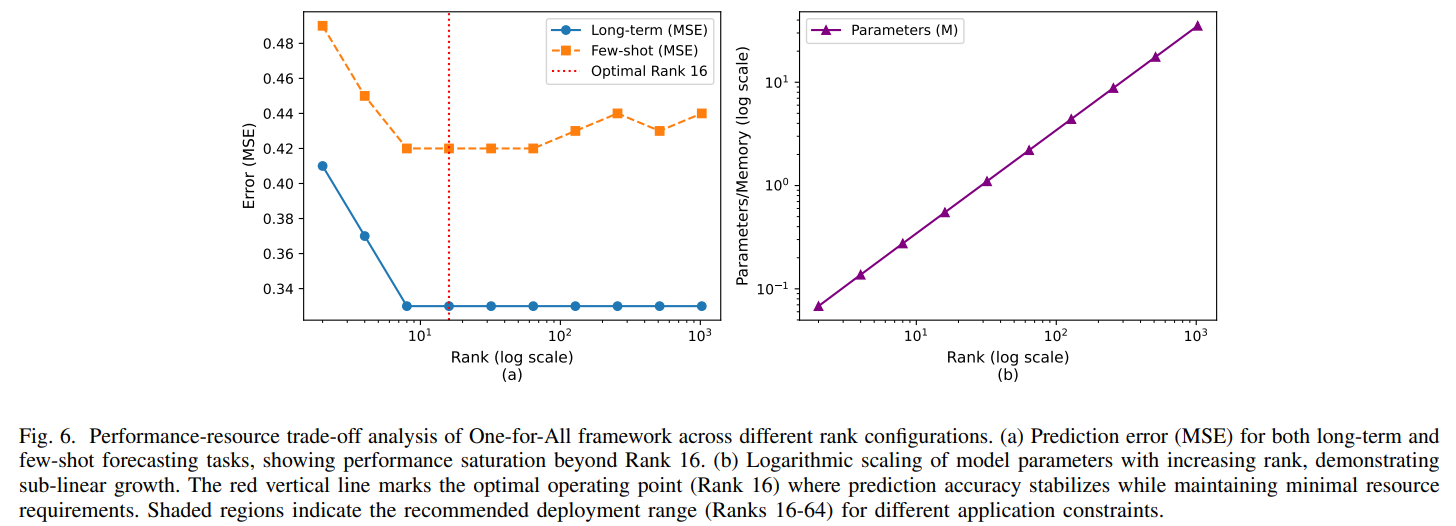
5. Rank ablation — rank 16에서 포화
| Rank | Params (M) | Memory (MiB) | Long-term MSE |
|---|---|---|---|
| 2 | 0.068 | 0.28 | 0.41 |
| 4 | 0.137 | 0.55 | 0.37 |
| 8 | 0.275 | 1.10 | 0.33 |
| 16 | 0.550 | 2.20 | 0.33 |
| 32 | 1.100 | 4.43 | 0.33 |
| 64 | 2.200 | 8.80 | 0.33 |
rank 8부터 이미 평균 MSE 0.33에 도달하고, rank 16 이후로는 사실상 변화가 없다. 이게 rsLoRA 이론 예측과 맞는 그림이다 — scaling 덕분에 낮은 rank에서 gradient가 죽지 않아 작은 rank만으로도 수렴이 가능하다는 것. 저자들은 rank 16을 기본 설정으로 고정한다.
한계
논문에 명시된 별도의 Limitations 섹션은 없고, 본문에서 읽히는 한계는 다음과 같다.
- 정확도 1위는 아니다: 거의 모든 태스크에서 TIME-LLM이 여전히 가장 좋은 MSE를 기록한다. One-for-All의 판매 포인트는 "동률 성능 + 극단적 경량화"지 accuracy SOTA가 아니다.
- zero-shot 방향성: M3↔M4 중 한 방향만 이긴다. 사전학습 지식의 전이 조건이 명확히 분리돼 있지는 않다.
- 이상탐지 등 일부 태스크에서 뒤진다: 범용성을 내세우지만, F1 기준 GPT4TS보다 약하다.
- LLM 백본이 GPT-2 계열로 고정: 더 큰/최신 LLM에서 같은 trend가 유지될지는 이 논문 범위 밖.
짧은 코멘트
이 논문에서 가장 마음에 든 건 "어디를 건드리지 않을지"를 먼저 정한 설계다. self-attention과 FFN을 전부 얼린 채 positional embedding과 output projection 두 경계면만 비트는 건, 시계열과 텍스트의 본질적 차이가 "순서 의미와 출력 공간"에 있다는 가설을 물리적으로 구현한 결정이다. 임의적으로 느껴질 수도 있지만 rank ablation에서 rank 8부터 이미 포화에 가깝다는 결과가 이 선택이 과하지 않음을 뒷받침한다. 작은 rank로 gradient가 살아 있다는 rsLoRA의 이론적 이득이 실험 쪽에서 매끄럽게 연결되는 게 이 논문의 단정한 구성이다.
한편 2.2 MiB라는 숫자가 과연 실무 의미를 갖는 조건이 뭘지 생각하면서 읽었다. 논문은 edge deployment를 주요 동기로 들지만, 물류·공급망 시계열 연구를 하는 입장에서 진짜 병목은 모델 크기보다 데이터 갱신 주기와 분포 드리프트인 경우가 많다. 그런 관점에서 이 논문이 더 와닿았던 건 few-shot 10%/5% 결과 쪽이다. 같은 0.55M 크기의 TimesNet보다 확실히 낫고, 11배 큰 GPT4TS와의 격차도 생각보다 작다. "큰 LLM4TS 모델을 쓸 수 없는 환경에서 pretrained LLM 지식을 얼마나 끌어올 수 있는가"에 대한 하나의 하한선을 제시한 셈이다.
참고
- arXiv: https://arxiv.org/abs/2603.29756
- 관련 — LoRA: Hu et al., LoRA: Low-Rank Adaptation of Large Language Models (arXiv 2106.09685)
- 관련 — rsLoRA 원 논문: Kalajdzievski, A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA (arXiv 2312.03732)
- 대비 — GPT4TS: Zhou et al., One Fits All: Power General Time Series Analysis by Pretrained LM (NeurIPS 2023)
- 대비 — TIME-LLM: Jin et al., Time-LLM: Time Series Forecasting by Reprogramming LLMs (ICLR 2024)
- 같은 맥락 — 직전 리뷰: [논문리뷰] Rethinking the Role of LLMs in Time Series Forecasting
