2023-1 학부 학술제에 참가하기 위해서 어떤 작품을 만들지 고민하다가 집에 있는 ESP32CAM 모듈을 이용해서 가정용 얼굴인식 도어락을 제작해보았다.
작품 배경

기존의 도어락은 열쇠나 비밀번호 등의 인증 방식으로만 문을 열고 닫을 수 있었기 때문에, 보안성이 낮고, 불편한 면이 있었다.
이에 반해 얼굴인식 도어락은 얼굴 인식 기술을 활용하여, 보다 안전하고 빠르게 출입이 가능하다.
얼굴인식 기술 자체는 이미 상용화되어 있으며, 대형 빌딩이나 회사, 정부 기관 등에서는 보안 시스템으로 많이 활용되고 있다. 그러나 가정용 도어락 분야에서는 아직 많이 보급되지 않고 있다.

이는 얼굴인식 기술이 상대적으로 높은 비용이 필요하고, 인식률이 100%가 아니라는 점 등이 있기 때문이다.
또한, 얼굴인식 기술을 이용한 도어락은 사용자의 얼굴 이미지를 수집하고 처리해야 하기 때문에 개인정보 보호 문제에 대한 우려가 있다.
그래서 필자는 저렴한 가격과 작은 크기에 중점을 두고 간이 얼굴인식 도어락을 제작해 보았다.
ESP32-CAM

비용을 최소화하기 위해 ESP32-CAM 모듈을 사용하였다.
인터넷에서 1만원 중반대에 구매할 수 있었다.
이 모듈은 ESP32 기본 모듈에 카메라까지 내장되어있어서 저렴한 가격에 활용되는 모듈이다.
아두이노보다 빠른 프로세서, WiFi와 블루투스, 카메라를 하나의 보드에 통합하고 여기에 SD카드슬롯까지 부착된 모듈이다.
이 모듈을 이용하여 WiFi에 연결하고 촬영된 영상을 실시간으로 웹서버로 보내는 용도로 사용하였다.
ESP8266 D1 Mini

다음은 ESP8266 D1 Mini 모듈과 서보모터를 사용하였다.
이 모듈은 작은 크기에 아두이노 우노의 기능과 esp8266 와이파이기능 결합된 모듈이다.
이 모듈을 WiFi에 연결하고 웹서버를 제작하여 웹에서 Http 통신으로 모듈에 연결된 서보모터를 제어하는 용도로 사용하였다.
작품 구성도
다음은 기획한 작품의 구성도이다.
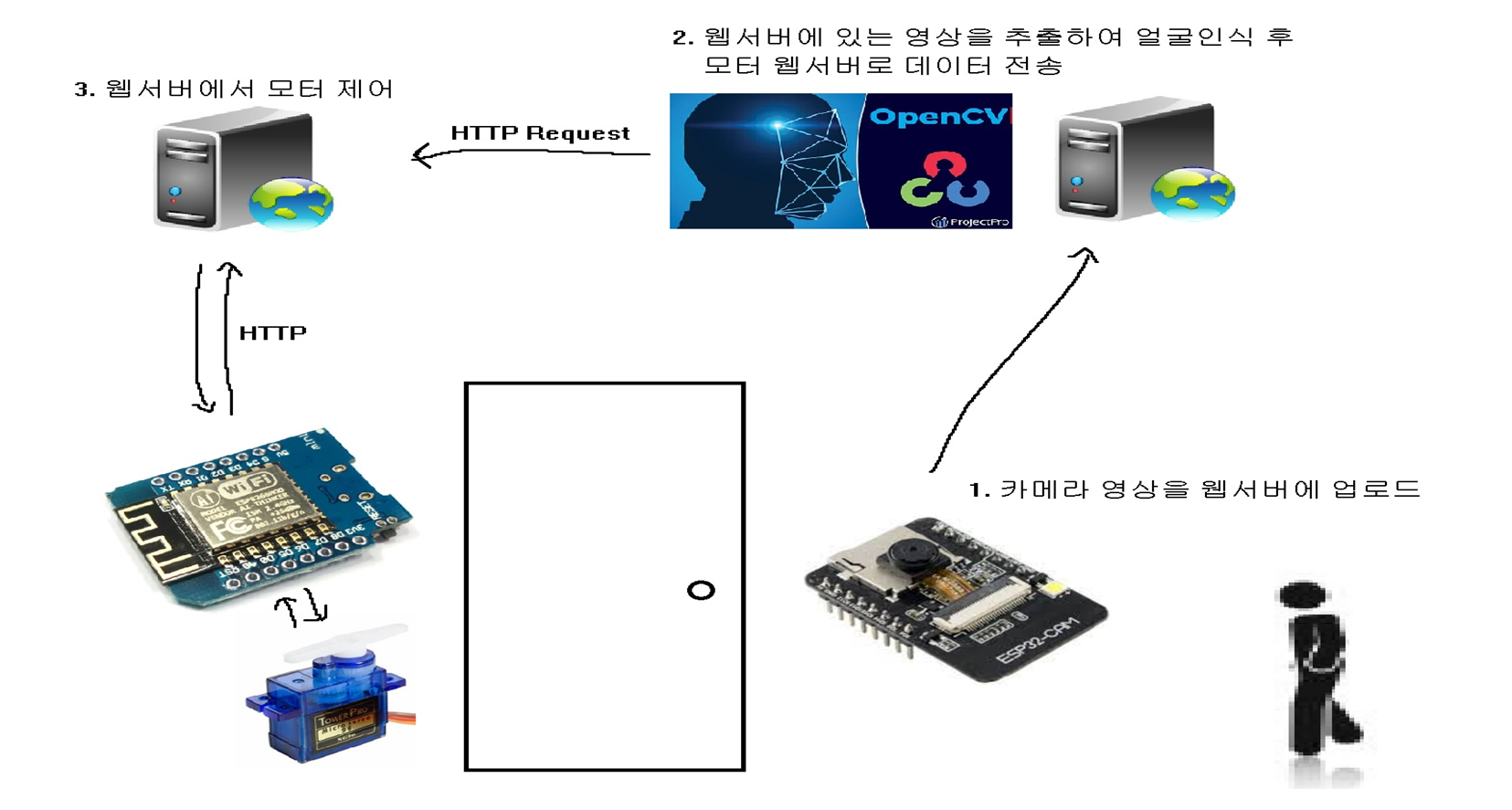
먼저 esp32cam 모듈로 영상을 촬영하여 실시간으로 웹서버에 업로드 한다. 그러면 서버컴퓨터에서 웹서버에 업로드된 영상을 추출한 뒤 opencv 라이브러리를 사용하여 얼굴인식 후 모터 웹서버로 데이터를 전송한다.
모터 웹서버에서는 데이터를 전송 받고 HTTP 통신으로 서보모터를 제어하게 된다.
보통은 1번과정과 2번과정을 라즈베리파이와 카메라 모듈을 사용하여 한번에 제작하는 경우가 많지만 필자는 비용과 크기를 최소화 하기 위해서 라즈베리파이를 사용하지 않았다.
기능 구현
먼저 ESP32-CAM 모듈의 초기 설정을 위해 예제 코드를 수정하여 모듈에 업로드 하였다.
#include "esp_camera.h"
#include <WiFi.h>
//
// WARNING!!! PSRAM IC required for UXGA resolution and high JPEG quality
// Ensure ESP32 Wrover Module or other board with PSRAM is selected
// Partial images will be transmitted if image exceeds buffer size
//
// You must select partition scheme from the board menu that has at least 3MB APP space.
// Face Recognition is DISABLED for ESP32 and ESP32-S2, because it takes up from 15
// seconds to process single frame. Face Detection is ENABLED if PSRAM is enabled as well
// ===================
// Select camera model
// ===================
//#define CAMERA_MODEL_WROVER_KIT // Has PSRAM
//#define CAMERA_MODEL_ESP_EYE // Has PSRAM
//#define CAMERA_MODEL_ESP32S3_EYE // Has PSRAM
//#define CAMERA_MODEL_M5STACK_PSRAM // Has PSRAM
//#define CAMERA_MODEL_M5STACK_V2_PSRAM // M5Camera version B Has PSRAM
//#define CAMERA_MODEL_M5STACK_WIDE // Has PSRAM
//#define CAMERA_MODEL_M5STACK_ESP32CAM // No PSRAM
//#define CAMERA_MODEL_M5STACK_UNITCAM // No PSRAM
#define CAMERA_MODEL_AI_THINKER // Has PSRAM
//#define CAMERA_MODEL_TTGO_T_JOURNAL // No PSRAM
// ** Espressif Internal Boards **
//#define CAMERA_MODEL_ESP32_CAM_BOARD
//#define CAMERA_MODEL_ESP32S2_CAM_BOARD
//#define CAMERA_MODEL_ESP32S3_CAM_LCD
#include "camera_pins.h"
// ===========================
// Enter your WiFi credentials
// ===========================
const char* ssid = "******";
const char* password = "***********";
void startCameraServer();
void setup() {
Serial.begin(115200);
Serial.setDebugOutput(true);
Serial.println();
camera_config_t config;
config.ledc_channel = LEDC_CHANNEL_0;
config.ledc_timer = LEDC_TIMER_0;
config.pin_d0 = Y2_GPIO_NUM;
config.pin_d1 = Y3_GPIO_NUM;
config.pin_d2 = Y4_GPIO_NUM;
config.pin_d3 = Y5_GPIO_NUM;
config.pin_d4 = Y6_GPIO_NUM;
config.pin_d5 = Y7_GPIO_NUM;
config.pin_d6 = Y8_GPIO_NUM;
config.pin_d7 = Y9_GPIO_NUM;
config.pin_xclk = XCLK_GPIO_NUM;
config.pin_pclk = PCLK_GPIO_NUM;
config.pin_vsync = VSYNC_GPIO_NUM;
config.pin_href = HREF_GPIO_NUM;
config.pin_sscb_sda = SIOD_GPIO_NUM;
config.pin_sscb_scl = SIOC_GPIO_NUM;
config.pin_pwdn = PWDN_GPIO_NUM;
config.pin_reset = RESET_GPIO_NUM;
config.xclk_freq_hz = 20000000;
config.frame_size = FRAMESIZE_UXGA;
config.pixel_format = PIXFORMAT_JPEG; // for streaming
//config.pixel_format = PIXFORMAT_RGB565; // for face detection/recognition
config.grab_mode = CAMERA_GRAB_WHEN_EMPTY;
config.fb_location = CAMERA_FB_IN_PSRAM;
config.jpeg_quality = 12;
config.fb_count = 1;
// if PSRAM IC present, init with UXGA resolution and higher JPEG quality
// for larger pre-allocated frame buffer.
if(config.pixel_format == PIXFORMAT_JPEG){
if(psramFound()){
config.jpeg_quality = 10;
config.fb_count = 2;
config.grab_mode = CAMERA_GRAB_LATEST;
} else {
// Limit the frame size when PSRAM is not available
config.frame_size = FRAMESIZE_SVGA;
config.fb_location = CAMERA_FB_IN_DRAM;
}
} else {
// Best option for face detection/recognition
config.frame_size = FRAMESIZE_240X240;
#if CONFIG_IDF_TARGET_ESP32S3
config.fb_count = 2;
#endif
}
#if defined(CAMERA_MODEL_ESP_EYE)
pinMode(13, INPUT_PULLUP);
pinMode(14, INPUT_PULLUP);
#endif
// camera init
esp_err_t err = esp_camera_init(&config);
if (err != ESP_OK) {
Serial.printf("Camera init failed with error 0x%x", err);
return;
}
sensor_t * s = esp_camera_sensor_get();
// initial sensors are flipped vertically and colors are a bit saturated
if (s->id.PID == OV3660_PID) {
s->set_vflip(s, 1); // flip it back
s->set_brightness(s, 1); // up the brightness just a bit
s->set_saturation(s, -2); // lower the saturation
}
// drop down frame size for higher initial frame rate
if(config.pixel_format == PIXFORMAT_JPEG){
s->set_framesize(s, FRAMESIZE_QVGA);
}
#if defined(CAMERA_MODEL_M5STACK_WIDE) || defined(CAMERA_MODEL_M5STACK_ESP32CAM)
s->set_vflip(s, 1);
s->set_hmirror(s, 1);
#endif
#if defined(CAMERA_MODEL_ESP32S3_EYE)
s->set_vflip(s, 1);
#endif
WiFi.begin(ssid, password);
WiFi.setSleep(false);
while (WiFi.status() != WL_CONNECTED) {
delay(500);
Serial.print(".");
}
Serial.println("");
Serial.println("WiFi connected");
startCameraServer();
Serial.print("Camera Ready! Use 'http://");
Serial.print(WiFi.localIP());
Serial.println("' to connect");
}
void loop() {
// Do nothing. Everything is done in another task by the web server
delay(10000);
}
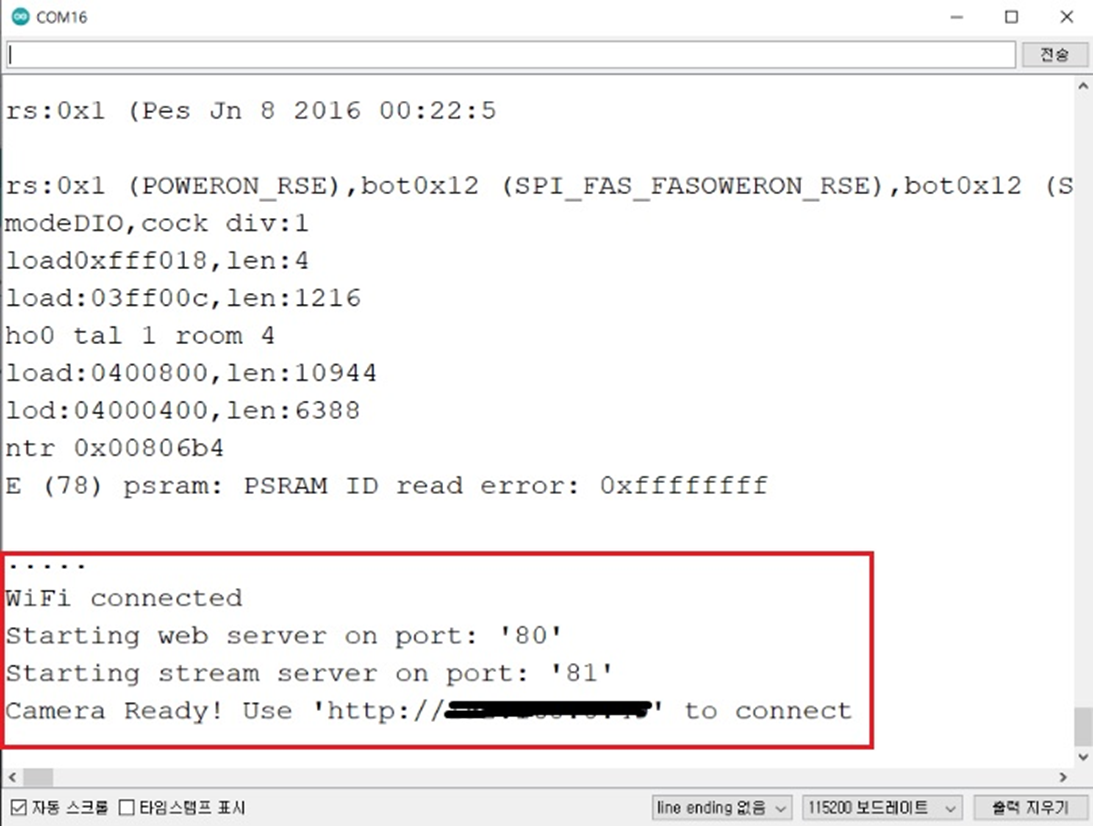
사용할 ssid 와 패스워드를 미리 입력하여 업로드한 뒤
모듈에 전원공급만 되면 자동으로 와이파이 연결 후 지정된 IP주소로 실시간으로 영상을 스트리밍 하게 된다.
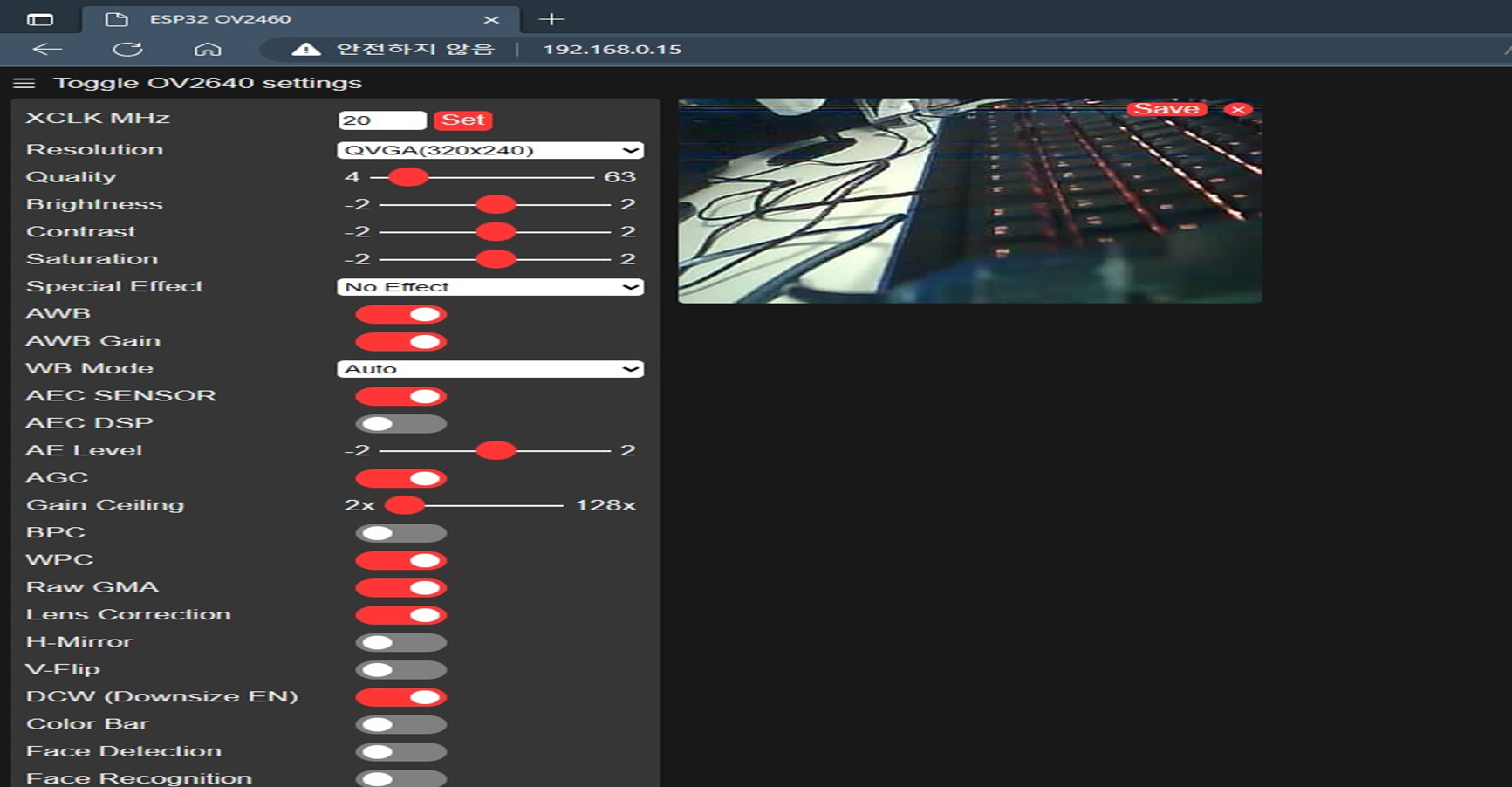
시리얼 모니터에 출력된 IP주소로 접속하게 되면 다음과 같은 웹페이지에서 실시간으로 영상을 확인 할 수 있다.
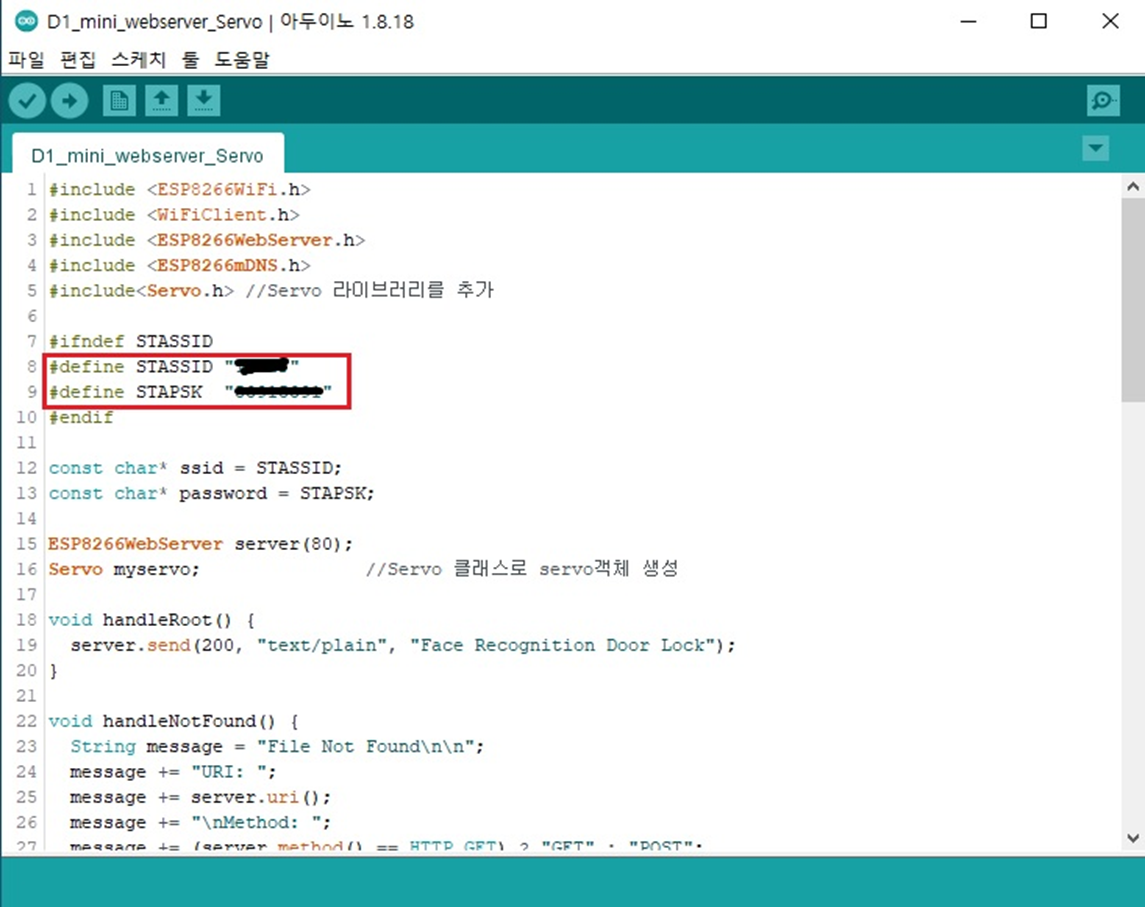
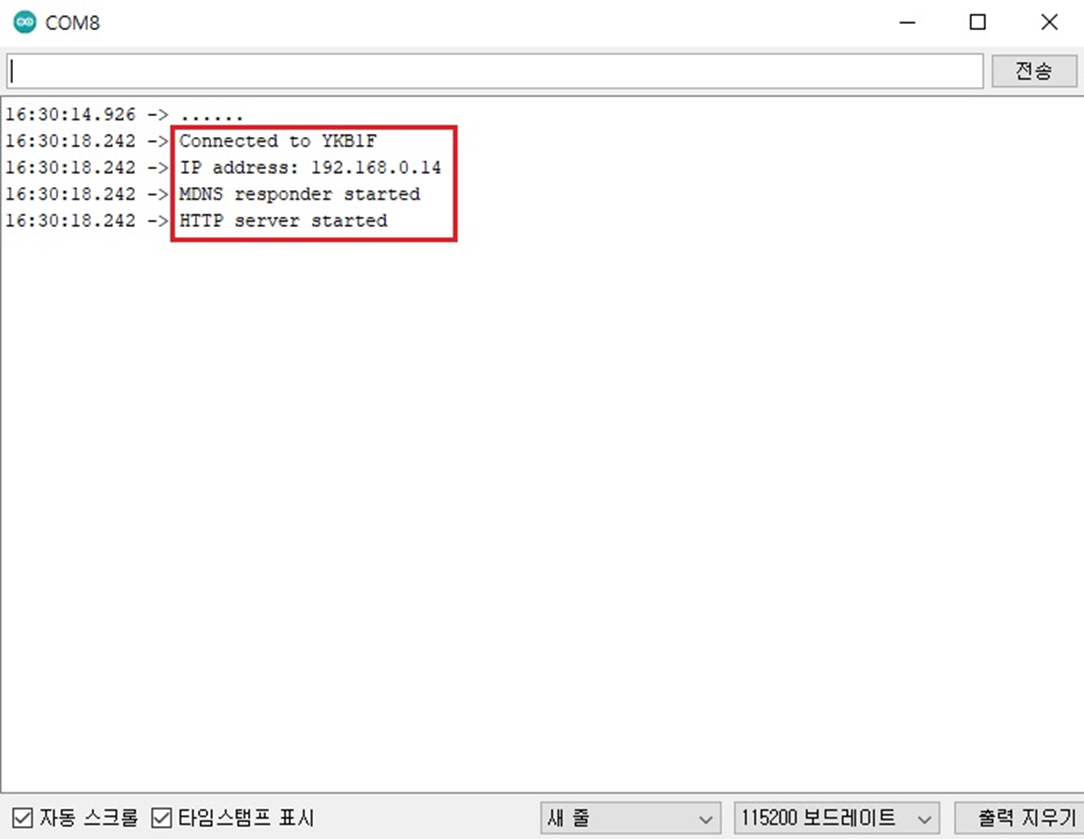
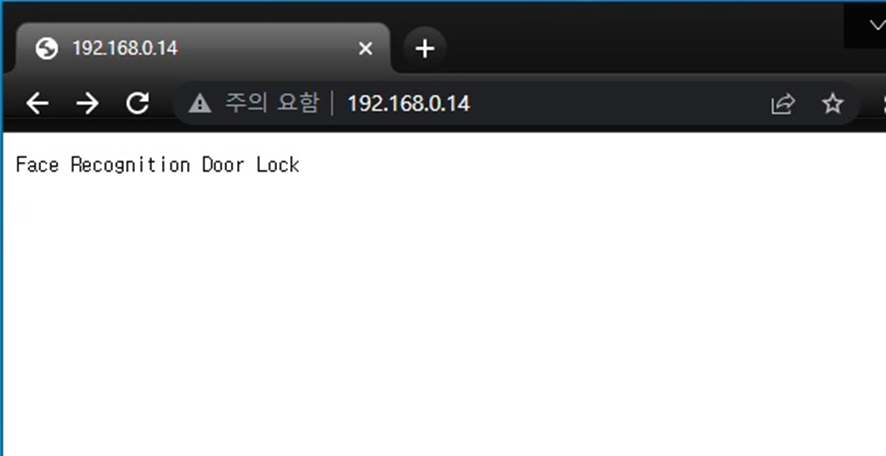
동일하게 서보모터가 연결된 D1 mini wifi 보드에도 초기 ssid와 패스워드 및 웹서버 설정과 기능을 업로드 하였다.
다음은 서버 컴퓨터에서 직접적으로 영상을 처리하고 얼굴을 인식하여 서보모터 웹서버로 데이터를 전송하는 부분이다.
먼저 얼굴 인식의 과정 이다.

얼굴을 인식하기 위해서는 다음과 같은 세 과정을 거친다.
사진이나 영상에서 얼굴이 있는 영역을 알아낸다.(face_location())
얼굴 영역에서 눈, 코, 입 등 68개의 주요 좌표를 추출한다.
68개의 좌표를 128개의 숫자로 변환한다.(face_encoding())
파이썬 패키지 dlib에는 이 과정이 구현되어 있다.
face_recognition 패키지의 face_location()과 face_encodings() 함수는
dlib 과 numpy에 쉽게 접근할 수 있도록 wrapping 해 놓은 함수이다.
필자는 이 함수들을 사용해서 사전에 등록할 사용자의 사진 1장씩을 인코딩 후 실시간 영상을 분석하여
등록된 사용자가 인식이 되면 서보모터 웹서버로 데이터를 전송하는 코드를 구현하였다.
import face_recognition
import cv2
import numpy as np
import requests
# 검색 할 샘플 사진을 로드 후 인코딩
known1_image = face_recognition.load_image_file("asset/images/obama.jpg")
known1_face_encoding = face_recognition.face_encodings(known1_image)[0]
known2_image = face_recognition.load_image_file("asset/images/Boris_Johnson.jpeg")
known2_face_encoding = face_recognition.face_encodings(known2_image)[0]
known3_image = face_recognition.load_image_file("asset/images/admin1.jpg")
known3_face_encoding = face_recognition.face_encodings(known3_image)[0]
# 검색 할 얼굴 인코딩 및 이름 배열 생성
known_face_encodings = [
known1_face_encoding, known2_face_encoding, known3_face_encoding,
]
known_face_names = [
"Obama", "Boris", "Admin",
]
# esp32cam 으로 업로드 된 영상을 실시간으로 cap 에 가져옴
cap = cv2.VideoCapture('http://192.168.0.15:81/stream')
# 서보모터 제어를 위한 웹서버 url
openUrl = "http://192.168.0.14/on"
# 프레임 스킵 변수
skip_frames = 10
frame_count = 0
while cap.isOpened():
# cap 객체를 통해 현재 프레임 읽어옴
success, frame = cap.read()
# 현재 프레임의 번호를 skip_frames 로 나눈 나머지가 0인지 확인
# 일정한 간격으로 프레임을 건너뛰기 위한 조건
if frame_count % skip_frames == 0:
# cv2.flip(frame, 1)은 프레임을 좌우로 뒤집음
# 이는 보통 카메라 영상이 거울 이미지로 표시되기 때문에 올바른 방향으로 보기 위한 조치
# cv2.cvtColor(...)는 BGR 형식으로 뒤집은 프레임을 RGB 형식으로 변환
# face_recognition 라이브러리는 RGB 형식의 이미지를 사용하기 때문에 변환 과정이 필요함
frame = cv2.cvtColor(cv2.flip(frame, 1), cv2.COLOR_BGR2RGB)
# frame.flags.writeable = False는 frame 객체를 읽기 전용으로 설정
# 이는 face_recognition 라이브러리의 일부 함수들이 원본 프레임을 변경하지 않도록 하기 위한 조치
frame.flags.writeable = False
# 주어진 프레임에서 얼굴을 감지하여 얼굴의 위치 정보를 추출
# 각 얼굴의 위치는 (top, right, bottom, left) 형태의 튜플로 표현
face_locations = face_recognition.face_locations(frame)
# 주어진 프레임에서 감지된 얼굴 영역을 바탕으로 얼굴의 인코딩 값을 추출
# 얼굴 인코딩은 각 얼굴을 128차원 벡터로 나타내는 작업, 얼굴의 고유한 특징을 표현
face_encodings = face_recognition.face_encodings(frame, face_locations)
# 앞서 False로 설정하여 읽기 전용을 다시 쓰기가 가능한 상태로 변경
frame.flags.writeable = True
# RGB형식으로 변환된 프레임을 다시 BGR형식으로 변환
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# face_locations와 face_encodings 리스트를 동시에 반복하면서 얼굴의 위치와 해당 얼굴의 인코딩 값을 추출
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
# 현재 프레임에서 인식된 얼굴과 사전에 등록된 얼굴들 간의 유사성을 비교하여 일치 여부를 판단
# matches는 유사성을 비교한 결과를 담고있는 리스트. Ture / False
matches = face_recognition.compare_faces(known_face_encodings, face_encoding, 0.5)
name = "Unknown"
# 현재 프레임에서 인식된 얼굴의 인코딩 값을 사전에 등록된 얼굴들의 인코딩 값과 비교하여 거리를 계산
face_distances = face_recognition.face_distance(known_face_encodings, face_encoding)
# face_distances 배열에서 가장 작은 거리 값을 가지는 인덱스를 반환
best_match_index = np.argmin(face_distances)
# 가장 가까운 거리에 해당하는 사전 등록된 얼굴과 현재 프레임에서 인식된 얼굴이 일치하는지 확인하고,
# 일치하는 경우 해당 얼굴의 이름을 가져오는 역할을 함
if matches[best_match_index]:
name = known_face_names[best_match_index]
if name != "Unknown":
color = (0, 255, 0)
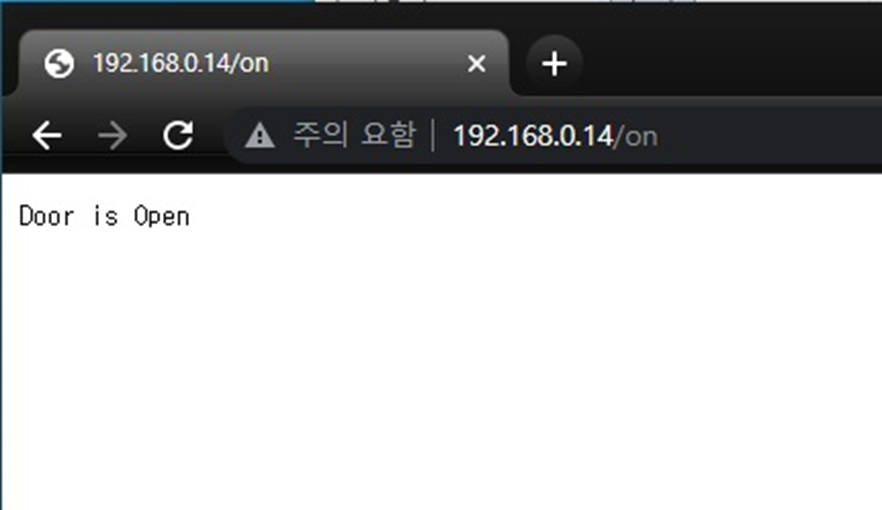
#등록한 얼굴이 인식되면 서보모터 동작 url
requests.get(url=openUrl)
else:
color = (0, 0, 255)
# 얼굴에 Bounding Box를 그림
cv2.rectangle(frame, (left, top), (right, bottom), color, 2)
# 얼굴 하단에 이름 레이블을 그림
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), color, cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (0, 0, 0), 1)
# 얼굴인식결과가 그려진 프레임 화면에 표시
cv2.imshow('Face Recognition', frame)
# 프레임 카운트 증가
frame_count += 1
if cv2.waitKey(5) & 0xFF == 27:
break
# 비디오 캡쳐 객체 해제
cap.release()
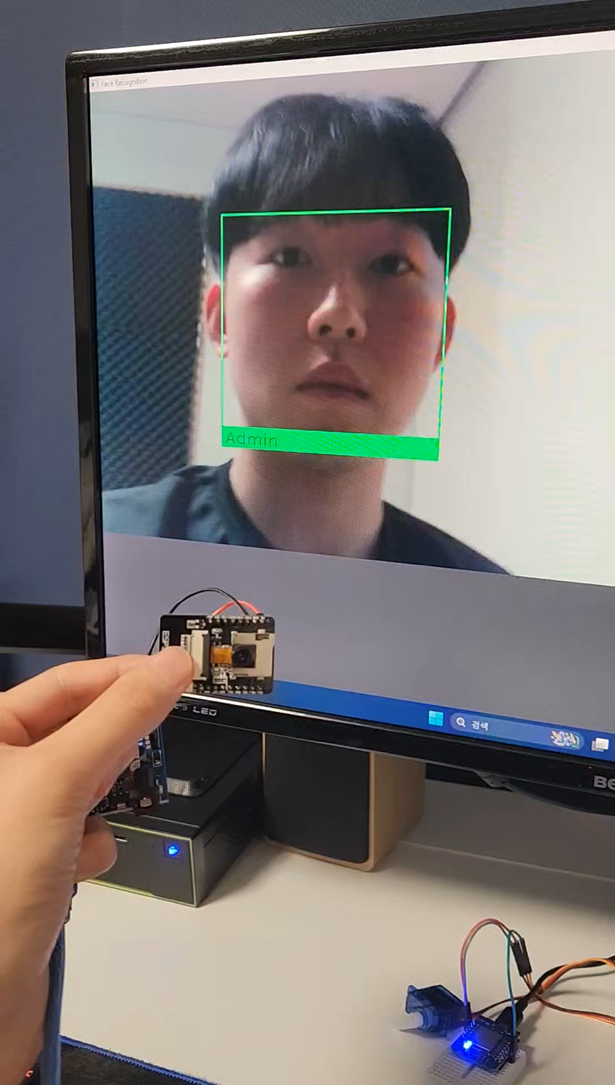
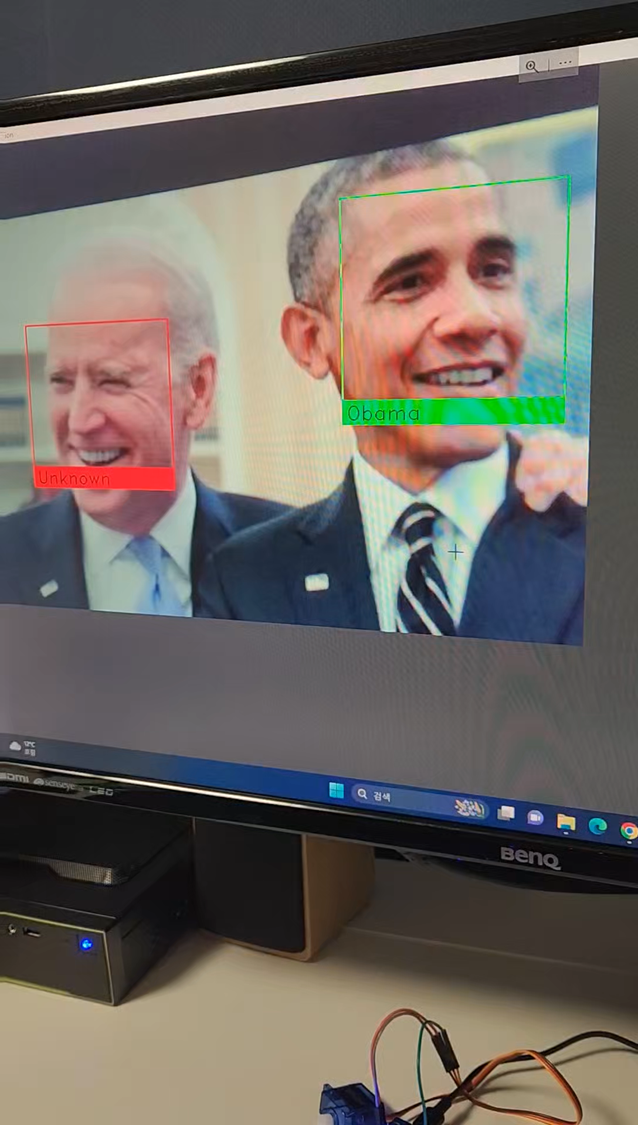
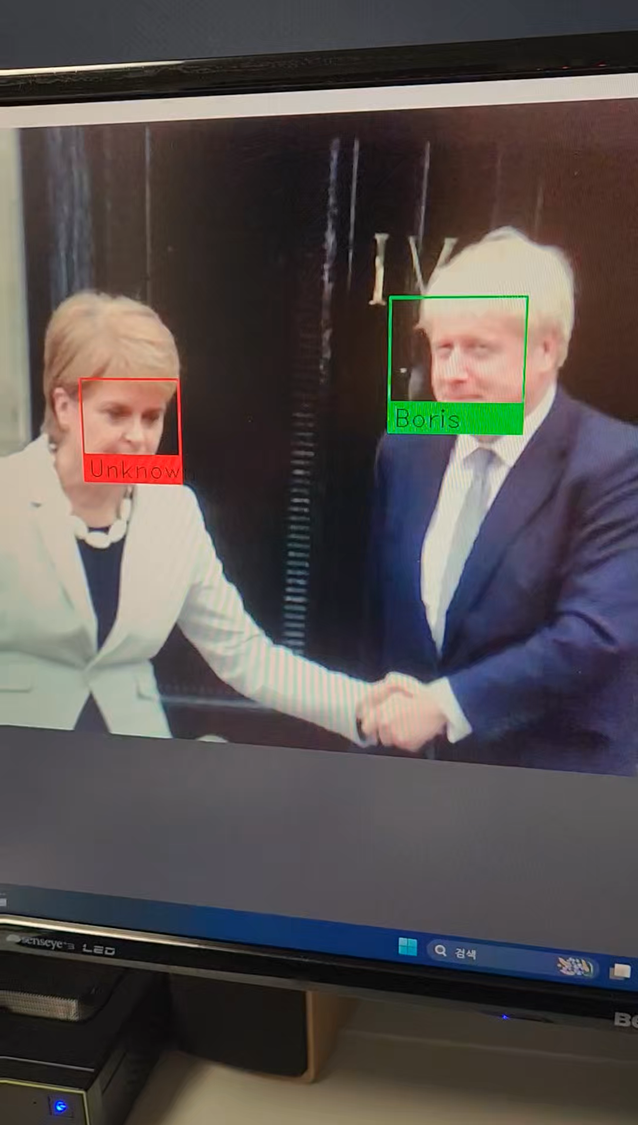
cv2.destroyAllWindows()다음은 실제 기능 구현 사진이다.
사전에 얼굴 사진 한장을 코드에 등록한 뒤, ESP32-CAM모듈로 얼굴을 촬영하면 서버 컴퓨터 화면에서 등록된 사용자의 얼굴을 인식하고, 초록색 테두리와 밑에 사용자의 이름이 표시되는것을 확인 할 수 있다.
그리고 등록된 사용자가 인식되면 서보모터 또한 작동되는것을 확인 할 수 있다.
문제점 및 한계
다음은 현재 작품의 문제점 및 한계점이다.
첫번째로 기능 구현 사진에서처럼 실제 사람이 아닌 이미지에 있는 얼굴도 인식하게되는 문제점이 있다.
두번째는 와이파이 연결 상태에 따라 속도라 달라진다.
세번째는 얼굴인식을 처리할 하드웨어가 있어야 한다.
마지막으로는 새로운 사용자의 얼굴 사진을 등록하고 관리하기 불편하다는 점이 있다.
다음은 각 문제점에 대한 해결 방안이다.
YOLO 객체 탐지 알고리즘

먼저 실제 사람이 아닌 이미지에 있는 얼굴도 인식하는 부분은
객체 탐지 알고리즘인 YOLO 알고리즘을 코드에 추가 수정하여 해결하거나
Sementic Segmentation
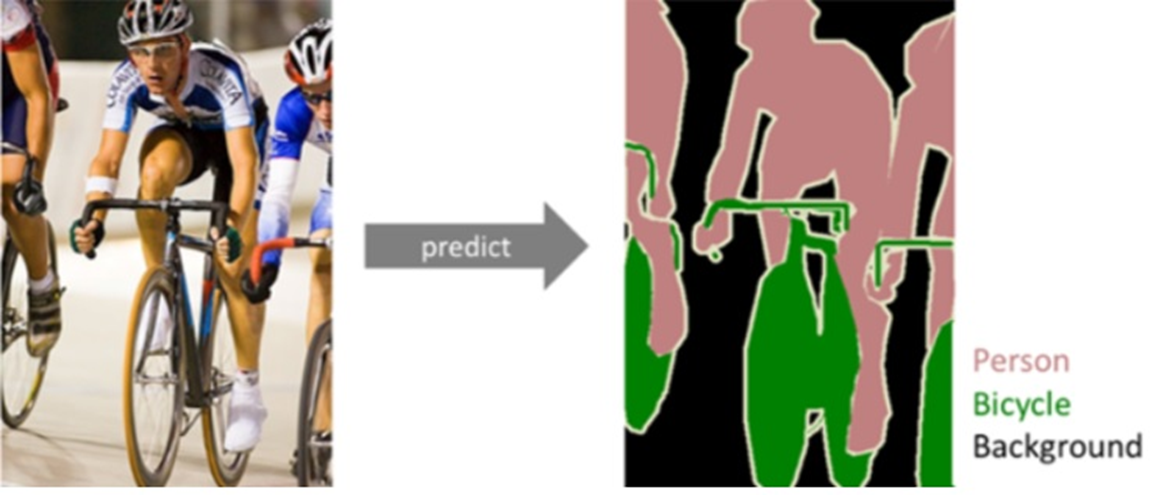
이미지에서 픽셀 단위로 관심 객체를 추출하는 방법인 시멘틱 세그멘테이션 방법을 사용하여
영상에서 실제 사람의 얼굴만 추출하여 해결 할 수 있다.

와이파이 연결 상태에 따라 속도가 달라지는 부분은
영상을 웹서버로 전송하는 카메라 모듈에 안테나를 부착하여 속도를 조금 더 높이는 방법이 있다.
위의 내용처럼 작품을 제작하고 발표를 진행해서 학부 학술제에서 우수상을 수상했다. ESP32-CAM 모듈을 처음 사용해보았는데 생각보다 저렴한 가격에 사용하기도 편해서 CCTV등의 다른 작품에도 사용 할 수 있을 것같다. 또한 발표 후 TinyML 등의 신 기술도 사용해보라는 피드백을 받았다. 따라서 다음 작품에서는 TinyML 등 새로운 기술을 포함한 작품을 제작해 보고 싶다.
