📌 딥러닝 Data Set
📍 패션 MNIST
- 10개 클래스
- 28 x 28 흑백 픽셀
- 6만개 샘플
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = \
keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
- 이미지 샘플 10개 출력해보기
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10,10))
for i in range(10) :
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
print([train_target[i] for i in range(10)])
[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
📍 로지스틱 회귀
- 스케일링
0~255 픽셀값 -> 0~1, 28 x 28 차원으로
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)(60000, 784)
- OVR
다중분류 -> 10개의 이진분류 수행
10개 z 값 softmax -> 확률
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import cross_validate
sc = SGDClassifier(loss='log', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))0.8195666666666668 // 검증 set
- 1개 샘플의 z = 784개 픽셀 x 784개의 가중치w
-> 10번의 이진분류, 가중치 모두 다름
📌 인공 신경망
- 로지스틱 회귀와 동일
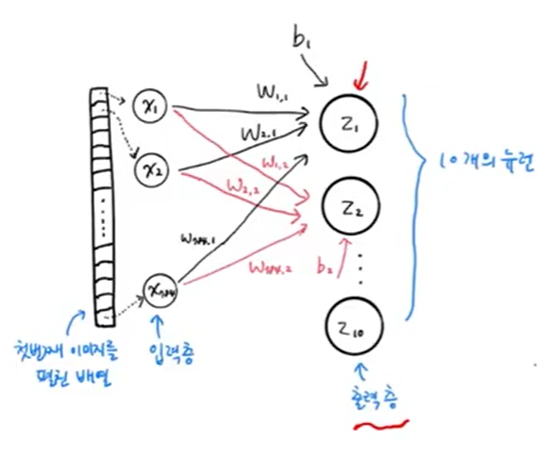
📍 케라스 모델 만들기
- Data Set
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42
)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)(38400, 784) (38400,)
(9600, 784) (9600,)
- Dense 객체 : 밀집층 (완전연결층, fully connected layer)
Dense(뉴런 갯수=클래스 갯수, 활성함수, input_shape)
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))- Sequential : 모델에 출력층(dense) 추가
model = keras.Sequential(dense)📍 모델 설정
-
compile(loss, metrics) : 손실함수, 정확도 등 설정
-
keras 손실함수
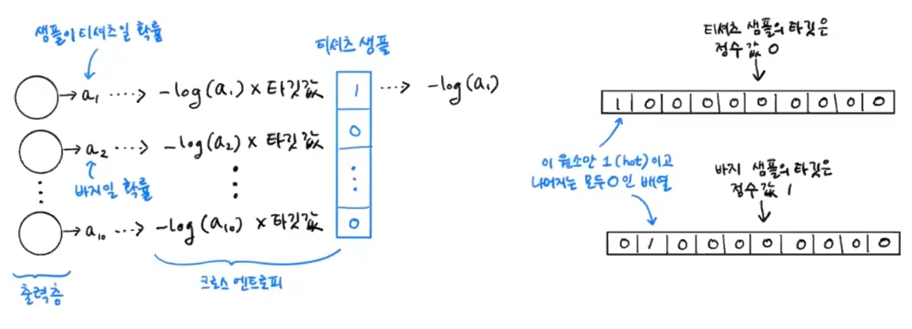
이진분류 : binary_crossentropy
다중분류 : categorical_crossentropy
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
print(train_target[:10])[9 4 9 0 4 9 3 6 4 7] // target 값 정수임
- 타깃값 -> 0,1 or 모든 정수
0,1 : categorical_crossentropy ( 원 핫 인코딩)
정수 : sparse_categorical_crossentropy
📍 모델 훈련
model.fit(train_scaled, train_target, epochs=5)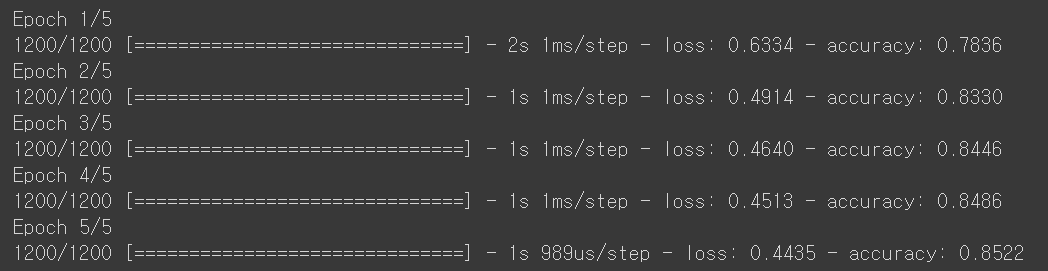
- 검증 : evaluate(검증set, target)
model.evaluate(val_scaled, val_target)
-> 검증 정확도 85%
📌 사이킷런 vs 케라스
-
사이킷런
모델 : SGDClassifier(loss)
훈련 : sc.fit()
평가 : sc.score() -
케라스
층생성 : Dense()
모델 : Sequential(dense), compile(loss)
훈련 : fit()
평가 : evaluate()
