📌 선형 회귀 Linear Regression
📍 최근접 이웃 회귀의 문제점
길이 50인 농어의 무게 예측
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42
)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=3)
knr.fit(train_input, train_target)
print(knr.predict([[50]]))[1033.33333333]
import matplotlib.pyplot as plt
distances, indexes = knr.kneighbors([[50]])
plt.scatter(train_input, train_target)
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
plt.scatter(50, 1033, marker='^')
plt.show()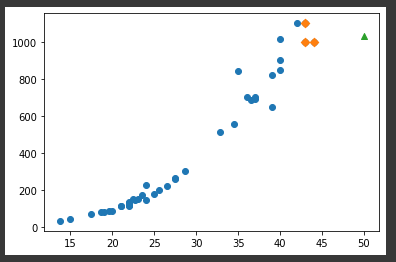
- 최근접 이웃의 데이터를 이용해 예측을 하기 때문에
훨씬 길게 입력된 길이에 비례하여 무게를 예측하지 못함
👉 훈련 세트 범위 밖의 데이터에 대해 예측 불가
📍 Linear Regression
선형 회귀로 예측
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.predict([[50]]))
print(lr.coef_, lr.intercept_)[1241.83860323]
[39.01714496] -709.0186449535477 // 기울기, y절편
학습한 직선 그리기
plot( x 범위 배열, y 범위 배열)
plt.scatter(train_input, train_target)
plt.plot([10, 50], [10*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])
plt.scatter(50, 1241.8, marker='^')
plt.show()
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))0.939846333997604 // 훈련 set R²
0.8247503123313558 // 테스트 set R²
-> 과대적합

-> 직선의 한계 : 길이가 너무 작아지면 음수로 떨어짐
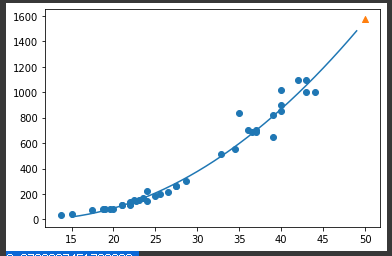
📌 다항 회귀 Polynomial Regression
📍 무게 = a x 길이² + b x 길이 + c
- 이차함수
- [길이²][길이] 2차원 배열로 data set
- 사이킷런은 입력 배열의 한 행이 하나의 샘플이길 기대함
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))📍 Linear Regression
- 예측 수행시 x항 차수 고려해 [길이², 길이] 차례로 입력
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]]))
print(lr.coef_, lr.intercept_)[1573.98423528] // 예측 무게
[ 1.01433211 -21.55792498] 116.0502107827827 // a, b, c
- 학습한 직선 그리기
x값 배열을 point로 생성
point = np.arange(15, 50)
plt.scatter(train_input, train_target)
plt.plot(point, 1.01*point**2 -21.6*point + 116.05 )
plt.scatter([50], [1574], marker='^')
plt.show()
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))0.9706807451768623 // 훈련 set R²
0.9775935108325122 // 테스트 set R²
-> 조금더 과대적합이 필요