TL; DR
- Retrieval Stage
- feature는 영상 기록, 검색 기록, 인구통계학적 특성, 영상 경과 시간 등으로 구성
- user 영상 검색어 history를 통해 w2v으로 임베딩하고, DNN 모델 학습 시 input으로 사용
- 특정 시점 이전 history를 feature로 설정하고 시점 직후 완전히 시청한 영상을 label로 설정
- 수 천 개의 Negative Sampling을 한 후 Softmax 방식으로 학습
- user embedding vector와 가장 가까운 item embedding vector를 찾아 retrieval 수행
- Ranking Stage
- Retrieval Stage와 유사한 구조 사용
- 과거 영상 컨텐츠과의 interation feature는 높은 중요도를 보임 (일반화가 잘 되는 feature)
- Logistic Regression 방식으로 학습 (최종 logit 값에 해당 영상의 평균 시청 시간을 곱함)
전체 아키텍쳐는 Retrieval stage, Ranking stage와 같이 일반적인 구조입니다. Retrieval stage에서 feature는 영상 기록, 검색 기록, 인구통계학적 특성, 영상 생성 경과 시간으로 구성됩니다. 영상 기록과 검색 기록은 따로 W2V(CBOW) 방식으로 학습된 뒤, average pooling을 통해 정보를 압축시켜 다른 feature들과 결합됩니다. 유저의 history가 주어졌을 때 바로 다음 완전히 시청하는 영상을 positive sample로 간주하고, 이에 대한 negative sample은 약 2000~3000 정도로 구성하여 학습합니다.
1. Introduction
저자는 현존하는 추천 알고리즘들은 소규모 데이터셋에는 적합하나 구글 유튜브 동영상과 같이 방대한 데이터셋에는 적합하지 않다는 부분을 문제로 제기했습니다.해당 문제는 아래와 같이 세 가지 관점에서 볼 수 있습니다.
- Scale은 방대한 데이터셋으로 인해 발생하는 문제입니다. 많은 데이터를 학습시킬 수 있으면서도 효과적인 serving을 할 수 있도록 만드는 것이 현재 유튜브 추천 시스템에 필요한 부분이라고 하였습니다.
- Freshness는 새로운 영상들이 수 초 마다 생성이 되는 문제입니다. 이러한 영상들을 최대한 빨리 serving 모델에 반영하는 것이 필요하다고 하였습니다.
- Noise는 불확실성으로 인하여 user hiostory와 ground truth에 대한 신뢰성이 떨어지는 문제입니다. 알 수 없는 요인들에 의해 user history가 구성되는데 이를 user의 ground truth로 간주하기에는 어렵다는 부분을 언급하였습니다. 또한 영상 컨텐츠에 대한 메타데이터가 구조화 되어 있지 않아 이에 대해 robust한 훈련 프로세스를 구축이 필요하다고 하였습니다.
2. Overview
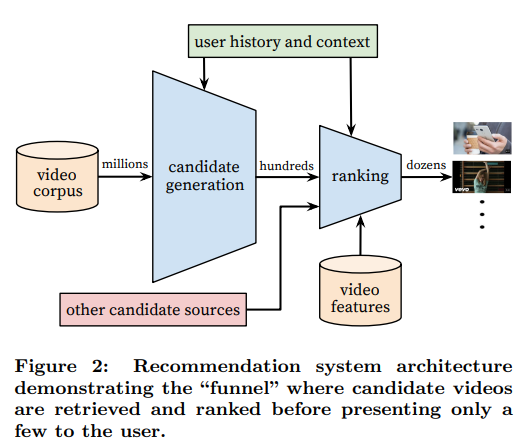
<그림1: 유튜브 추천 시스템 아키텍쳐>
위와 같이 아키텍쳐가 retrieval, ranking 두 stage로 나누어져 있는 것을 알 수 있습니다.
- retrieval stage는 유저의 youtube 활동기록을 input으로 사용합니다. collaborative filtering 방식으로 학습되며, 넓은 범위의 개인화를 제공합니다. 유저간 유사성은 시청한 영상, 검색어, 인구통계학적 특성과 같은 feature로 표현됩니다
- ranking stage는 retrieval stage에서 샘플링된 후보군들에 대해 점수를 부여하여 정렬합니다. 최종 유저에게 출력될 컨텐츠의 순서를 결정합니다.
모델 개발과정에서는 offline metric (precision, recall, loss)들을 활용하였지만, 최종 모델 결정시에는 A/B 테스트를 통한 online metric (클릭률, 시청시간)도 함께 활용하였습니다.
3. Retrieval Stage (a.k.a. Candidates Sampling)
본 논문의 모델 전 사용하던 모델은 user의 과거 history를 활용한 Matrix Factorization 방식의 모델입니다. 본 논문의 모델은 이 Matrix Factorization 모델의 비선형적인 일반화 모델이라고 볼 수 있습니다.
3-1. Recommendation as Classification
저자는 추천 task를 특정 유저(U)가 특정 상황(C)에 다양한 영상(V)에서 특정 시점에(T) 특정 영상을(i) 볼 확률을 예측하는 extreme multiclass classification 문제라고 보았습니다.
u는 user embedding을 의미하며, v는 content embedding을 의미합니다. user의 history와 context를 활용하여 적절한 embedding 값을 찾아내고 이를 통해 softmax loss를 최소화하는 것이 목적이라고 하였습니다. 사실 유튜브에는 ‘좋아요’ 혹은 영상에 대한 설문이라는 명백한 user feedback이 있지만, 암묵적 feedback인 시청을 완전히 끝낸 영상을 positive sample로 활용하였다고 하였습니다.
3-2. Efficient Extreme Multiclass
저자는 multiclass 학습을 위해 모든 label을 loss 계산에 넣는 것은 비효율적임을 지적하며, 따로 개발한 negative sampling 방식을 소개했습니다. 기존에 있는 content corpus 내에서 추출한 뒤, importance weighting을 통해 다시 조정합니다. 몇 천 개 정도의 negative sample을 활용하였습니다. 일반적인 softmax 기법보다 100배 이상 시간복잡도가 적었다고 합니다. 인기있는 대안은 hierarchical softmax가 있었으나, 딱히 효과를 보지는 못했다고 합니다.
수 십 밀리초 안에 수 백 만 개에 대해 sampling 하려면 수 많은 클래스에서 sublinear 복잡도의 approximate scroing 알고리즘이 필요합니다. 이전 유튜브에서는 hashing방법을 사용하였으며 본 논문에서도 유사한 방법을 사용합니다. serving시에 calibration은 필요하지 않기에 scoring 문제는 내적을 이용하는 nearest neighbors search 문제로 볼 수 있습니다. (즉, 다양한 nearest neighbors search 알고리즘을 사용할 수 있습니다.) A/B 테스트 결과, nearest neighbors search를 통한 방법이 성능에 크게 민감하게 작용하지 않는 것을 확인하였습니다.
3-3. Model Architecture
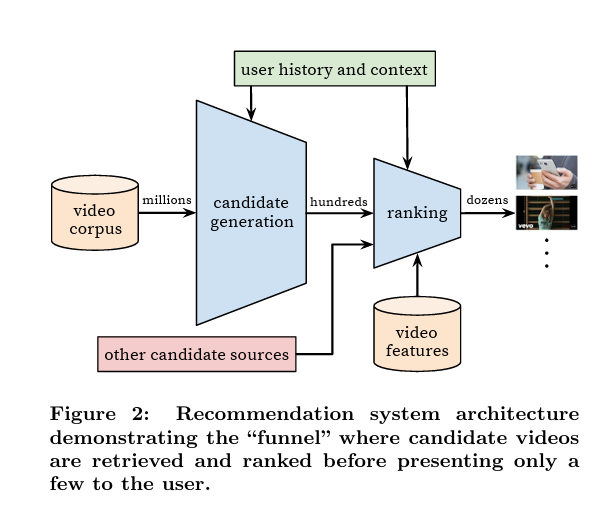
CBOW 언어 모델에 영감을 받아 각 영상을 학습시킨 후, FFN에 input으로 활용하였습니다. 각 유저의 시청 기록에 대한 영상 feature는 가변 길이의 embedding vector로 변환된 후 average pooling 연산을 적용하도록 하였습니다. 여기서 중요한 것은, 영상 embedding에 활용된 모델을 이후의 FFN과 함께 다시 training 시켰다는 것입니다.
<그림2: Retrieval Stage 아키텍쳐>
3-4. Heterogeneous Signals (이질적 시그널)
matrix factorization를 뉴럴네트워크로 구현함에 따른 이점은 임의의 다른 numerical & categorical feature 또한 모델에 input으로 넣을 수 있다는 것입니다. 검색 기록은 시청 기록과 유사하게 볼 수 있습니다. 검색 쿼리는 unigram 그리고 bigram 으로 토큰화 후 임베딩 됩니다. 검색 쿼리 또한 average pooling 연산을 취합니다.
인구통계학적 feature는 신규 user에게 추천이 잘 작동하는 데 기여를 합니다. user의 접속 지역, 기기 종류 또한 임베딩되고 다른 input들과 concatenate 됩니다. 유저의 성별, 로그인 상태, 나이와 같은 부분들도 input에 들어갑니다.
Example Age Feature
매초마다 몇 시간 분량의 영상들이 유튜브에 업로드 됩니다. 이러한 최근 업로드된(앞서 언급한 fresh) 영상은 추천에 있어 매우 중요합니다. 저자들은 유저가 관심있는 컨텐츠를 주로 선호하기는 하지만, 새로운 영상 컨텐츠에 대한 선호도 있다는 것을 지속적으로 관찰해 발견했다고 합니다. 사용자가 보고 싶은 새로운 동영상을 단순히 추천하는 1차 효과 외에도 바이럴 콘텐츠를 부트스트래핑하고 전파하는 중요한 2차 현상이 있습니다.
3-5. Label and Context Selection
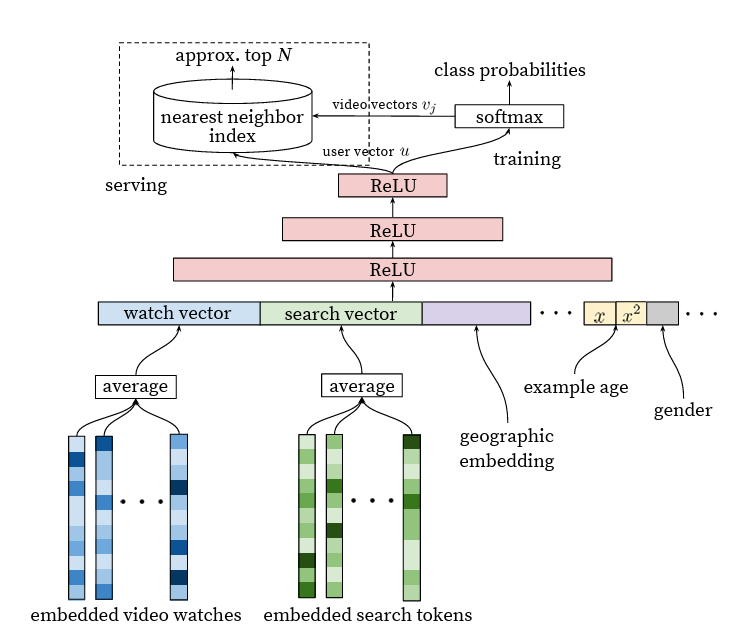
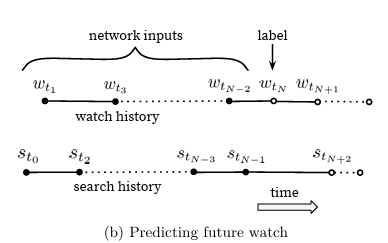
영상 기록과 같은 시퀀스 정보를 버리고 검색 쿼리에 대한 토큰을 representing 하는 것으로 인해 모델은 더 이상 ground truth lable에 대한 원래 정보를 알지 못한다고 합니다. 저자는 user가 보지 않은 미래의 특정 영상을 label로 설정하는 것 보다 바로 직후의 영상을 lable로 설정하는 것이 더 예측하는데 더 나은 성능을 보여준다는 것을 알았다고 합니다. 일반적으로, 영상 컨텐츠 소비 패턴은 매우 비대칭적인 co-watch 확률로 이어집니다. 예로, 에피소드 시리즈 같은 경우 해당 시리즈를 연속적으로 볼 확률이 높습니다. 또한 작은 틈새에 있는 것을 집중하기 전에 이미 매우 유명한 장르로부터 시작해 일부 artist를 발견하곤 합니다.
이러한 부분으로 저자는 user의 다음 영상을 예측하는 것이 더 높은 성능을 보여준다는 것을 발견했다고 합니다.
<그림3: 문제로 지적한 기존 학습 구조: history 중 특정 영상을 random하게 holding-out하게 되면 data leakage가 발생>
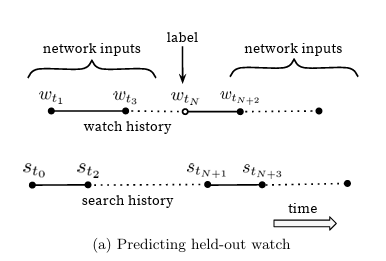
<그림4: 저자들이 제안한 학습 구조: label로 특정 영상을 설정하면 이에 대한 input은 해당 영상을 시청하기 전으로 rollback한 history 데이터>
4. Ranking Stage
<그림5: Ranking Stage 아키텍쳐>
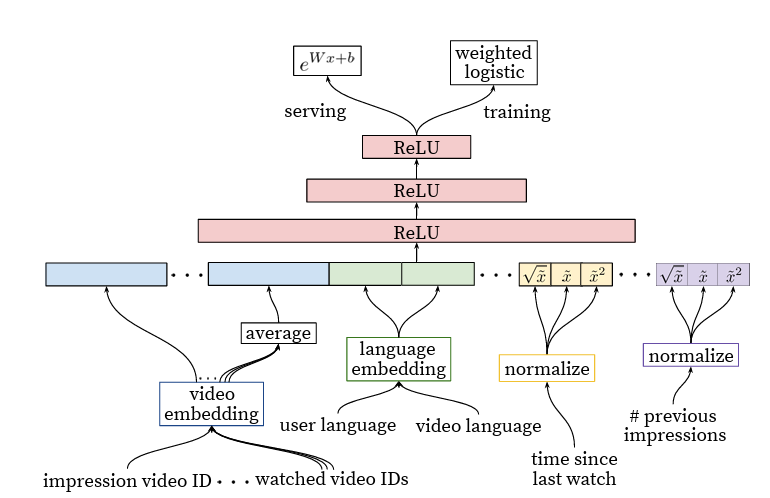
ranking 의 주요 목적은 후보군들을 유저특성이나 interaction 환경에 맞도록 specialize 그리고 calibrate 하는 것입니다. 예로, 어떤 유저가 주어진 어떤 영상을 주로 시청한다고 해본다고 했을 때 그 영상을 클릭할 확률은 그 유저가 접속했을 때의 상황이나 영상의 썸네일 등으로 달라질 수 있습니다. ranking task를 수행할 동안 영상에 대한 많은 메타데이터 그리고 영상에 대한 유저의 관계를 이용할 수 있습니다. 이는 ranking task는 이미 100 몇개의 소규모로 압축된 데이터셋을 가지고 학습하는 것이기 때문입니다.
ranking은 또한 다른 retrieval 알고리즘으로부터 추출된 candidates들을 앙상블하는 역할도 하기 때문에 중요합니다. ranking stage에서도 retrieval stage 과 유사하게 DNN 구조를 가지고 logistic regression 을 하는 방식을 사용했습니다. 최종 모델을 결정하기 위해 A/B 테스트를 하였고, 클릭률 보다는 impression 당 평균 시청 시간을 metric으로 사용했습니다. impression 당 평균 시청 시간을 사용하는 것이 user가 해당 영상에 대한 engagement 정도를 더 잘 잡아낼 수 있다고 보았습니다.
4.1 Feature Representation & Engineering
ranking stage에서 feature는 기본적인 feature(user의 로그인 여부, 시청 지역, 기기 등)부분과 더불어 과거 시청한 영상, 검색어도 있습니다. feature engineering이 많이 필요하지는 않은 DNN 이지만 raw data를 그대로 넣는 것은 학습에 어려움이 있어 직접 하였습니다. 저자들이 찾아낸 중요한 점은 유저의 이전 interaction을 영상 그 자체로 설명해줄 수 있는 것과 다른 사용자들의 경험과 일치하는 비슷한 영상들 입니다. interaction이 발생했던 영상에 대해 과거 정보를 설명하는 feature는 다른 영상들에 걸쳐 일반화가 잘 되기 때문에 강력한 영향이 있습니다.
과거 비디오 노출 빈도를 설명하는 기능은 추천에서 "변동"을 도입하는 데에도 중요합니다(연속적인 요청은 동일한 목록을 반환하지 않음). 사용자가 최근에 비디오를 추천받았지만 시청하지 않은 경우 모델은 자연스럽게 다음 페이지 로드에서 이 노출을 강등합니다. 최신 노출 및 시청 기록을 제공하는 것은 이 백서의 범위를 벗어나는 자체 엔지니어링 위업이지만 반응이 좋은 권장 사항을 생성하는 데 필수적입니다.
4.2 Modeling Expected Watch Time
ranking task에서는 훈련데이터의 평균 시청 시간을 예측하도록 설계하였습니다. 하지만 직접 평균 시청 시간을 target으로 두지 않고, 영상이 유저에게 보여진 후 클릭이 되었으면 1 아니면 0 로 변환한 값을 target으로 사용했습니다. 이후 모델 output logit 값에 평균 시청 시간을 곱해 최종 logit 값을 산출하는 방식으로 평균 시청 시간 정보를 반영하도록 하였습니다. 최종 inference 시에는 모델 output 값에 exp(x) function을 적용해 평균 시청 시간 분포와 비슷하게 하도록 하였습니다.
