TL;DR
- Model features
- Embedding Vector에 대한 행렬곱 연산을 적용해 토큰 간 interaction 정보를 학습 (Attention)
- Deocding block 학습 시 특정 토큰 이전의 토큰에 대해서는 masking 처리(0으로 대체)
1. Introduction
저자들은 시퀀스 기반 아키텍처를 설계하는데 있어 RNN 기반 모듈 보다 효과적인 Transformer 모듈을 제시합니다. Attention 매커니즘은 input과 output 길이의 관계없이 다양한 task를 수행할 수 있는 모델을 만들 수 있다고 언급합니다. 또한 Transformer는 행렬연산으로 되어 기존 RNN 기반 아키텍처 대비 더 빠른 학습을 가능케 언급합니다.
2. Architecture
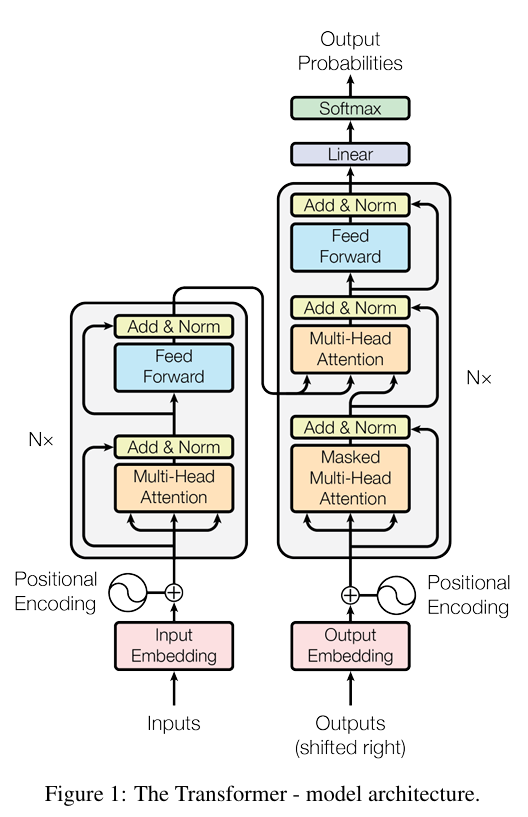
위 그림은 저자들이 제시한 Transformer의 아키텍쳐로서 두 stage로 나누어져 구성됩니다.
- Encoder : 입력 sequene를 학습하여 이를 latent vector로 encoding 하는 부분
- Decoder : latent vector에서 task에 적합한 정보를 decoding 하는 부분
Encoder block은 MHA(Multi-Head Attention)과 FFN(Feed Foward Neural network) 두 개의 연속적인 하위 layer로 연결되어 있습니다. MHA에서는 저자들이 말하는 attention 연산이 적용됩니다.
Decoder block은 두 MHA(Multi-Head Attention)과 FFN(Feed Foward Neural network) 의 layer로 이어져 있습니다. Decoder block에서의 MHA는 특정 단어 토큰 이전의 단어 토큰을 모두 masking 처리하는 연산 상 다른 점이 있습니다.
<Attention & Multi-Head Attention>
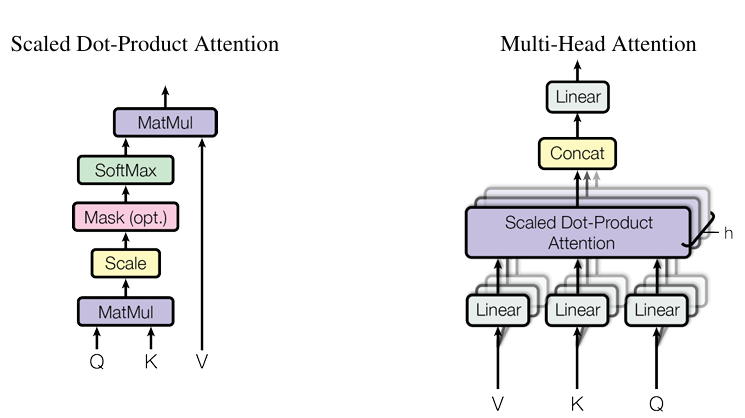
사실 본 논문의 핵심은 위 그림에 나와있는 ‘Attention’ Operation의 정의 입니다.왼쪽 그림의 Scaled Dot-Product Attention은 Attention 연산 동작 과정을 보여줍니다.오른쪽 그림은 Attention Layer를 여러 번 통과시킨 후 나온 Output을 Conatenate하여 원래의 차원으로 다시 Linear Projection하는 과정을 보여줍니다. (Multi-Head Attention)
Self-Attention Operation Process
-
Q, K, V 각각 에 대해 Embedding Vector 차원으로 Linear Projection
-
Q, K에 대해 행렬곱(A)을 수행 후 K의 Dimenstion 루트 값으로 나눔
→ (이후 진행될 Softmax에서 값이 너무 커져 모든 값이 1로 수렴하는 문제 방지)
-
A 행렬에 대해 row-by로 Softmax 연산을 적용
→ 해당 단어의 vector가 다른 단어의 vector와 가지는 정보(dot-product)를 0~1 까지 정규화
-
A와 V를 행렬 곱하여 원래의 Dimension과 같은 output을 산출
Multi-Head Attention Operation Process
-
위 Self-Attention 을 여러 개 사용한 후 마지막 차원으로 concatenate
→ Sequence Lenth by (Embedding Dimension * Attention 갯수) 형태의 행렬이 생성
-
원래의 Embedding Dimension 차원으로 Linear Projection
