당신은 혹시 근무시간에 합법적으로 테일러 스위프트 콘서트 직캠 보는 여성을 본 적 있습니까,
That's me.
마지막으로 참여한 마부뉴스 정규레터 작업이 너무너무 재밌었어서! 꼭 남겨두고 싶었다.
QGIS 2탄은 잠시 미뤄두고... 우리 일러 웅니 얘기 쫌 할게요.

💡어떤 데이터?
다들 아마 아시겠지만 .... 테일러 스위프트 그녀는 타임지가 선정한(마부뉴스도 선정한 ㅎㅎ) 2023 올해의 인물!!!
올 3월부터 시작한 월드투어 The Eras Tour로 벌써 한화 1조가 넘는 수익을 벌어들였더랬죠.. (60회 공연으로 이미 1조 넘겼는데 앞으로 80회 넘게 남은.. (이미 앉아있지만 더더욱) 돈방석 위에 앉게 될 그녀)
도대체 그 투어가 뭐길래 이렇게 많은 이들이 찾았는지 알아보고자! Spotify에서 제공하는 각 음악의 특징을 활용해 투어의 구성을 알아보면 좋겠다고 선배가 제안해주셨다.
이번 레터하면서 처음 알았는데, 스포티파이는 API가 정말 잘 되어 있었다. Client ID & Secret Key 받는 방식도 아래 페이지에서 시키는 대로 했더니 정말 간단했다.
https://developer.spotify.com/documentation/web-api
(API 활용법 참고 링크)
또, 해당 API에서 뽑아낼 수 있는 정보에 대한 설명도 정말 자세하고 친절했다. 설명은 아래 문서에서!
https://developer.spotify.com/documentation/web-api/reference/search
(API 정보 참고 링크)
💡어떤 고민?
(1) 정보를 어떻게 빼올까?
다운로드 받을 수 있는 형태의 데이터 분석이나 크롤링은 많이 해봤지만 API 따오는 건 많이 안 해봤어서, 쿼리 날려서 정보 가져오는 걸 어떻게 해야할지 .. 고민하고 있었다.
바로 그 순간 등장한 나의 구세주, Spotipy 패키지
패키지 이름은 Spotify + python = Spotipy인 것 같은데, API 정보 뽑아내는 주요한 방법을 함수로 구현해둔 거였다... 짱편함 !!!!!!
https://spotipy.readthedocs.io/en/2.22.1/
(공식 다큐멘트)
공식 다큐멘트보다 아래 벨로그 글을 먼저 봤는데, audio feature 뽑는 등 분석 지향점이 비슷해서 API 파악에 도움이 많이 됐다 !!
(2) 어떤 정보가 필요하고, 어떤 과정을 거칠 것인가?
선배께서, 우선 정규 앨범 전곡의 음악적 특징을 다 뽑아보고 필요에 따라 투어 곡들을 골라내는 게 좋을 것 같다고 의견을 주셔서 그렇게 해보기로 했다. 그렇다면 내가 필요한 것은?
1) 정규 앨범 목록과 고유 ID 값
2) 정규 앨범 내 트랙 목록과 고유 ID 값
3) 각 트랙의 음악적 특징
4) The Eras Tour 트랙 목록
오케이 순서대로 가보잣.
먼저, 패키지를 설치 및 장착하고 스포티파이에서 준 내 client ID 값과 Secret 값을 넣어준다.
pip install spotipy
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
client_credentials_manager = SpotifyClientCredentials(client_id='내 아이디', client_secret='내 비번')
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
1) 정규 앨범 목록과 고유 ID 값
특정 아티스트의 앨범에 대한 정보를 얻기 위한 함수는 artist_albums. 그 아티스트의 고유 ID와, 얻고 싶은 앨범의 타입, 검색할 앨범 개수 등의 매개변수가 필요했다.
- album = 정규 / single = 싱글 / appears_on = 피처링 등 / compilation = 여러 가지 섞인 (소위 짜깁기) 음반

아티스트 고유번호는, 간단하게 search 함수를 이용해서 'Taylor Swift' 이름을 검색해 알아냈다.
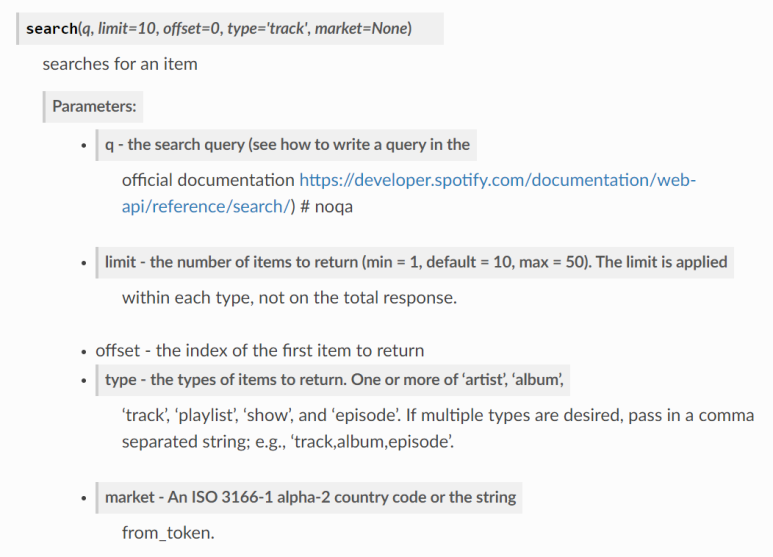
track_results = sp.search(q='Taylor Swift', type='artist', limit=10, offset=0)
06HL4z0CvFAxyc27GXpf02
요것이 스포티파이 속 테일러 스위프트의 고유 ID.
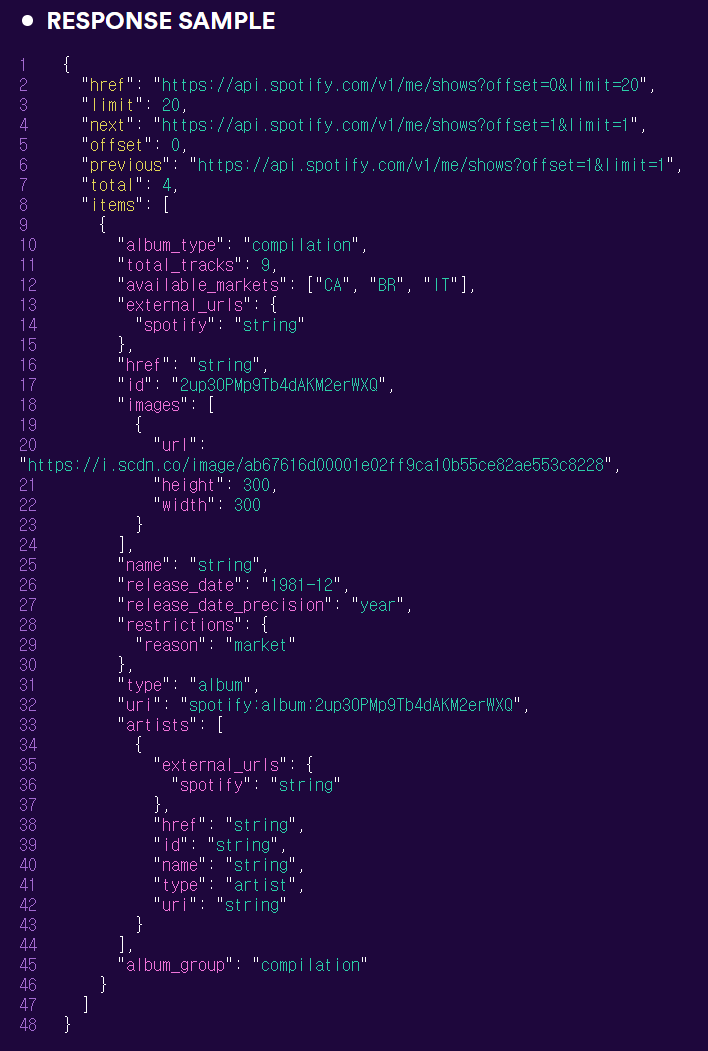
artist_albums 함수의 결과가 어떻게 생겼는지 아래 예시를 통해 살짝 뜯어보자면, 앨범 이름이나 고유 ID 값은 모두 'items' 라는 key 값에 대응하는 value 속에 들어있었다.
그리고 그 value 값이 리스트로 묶여 있는 것으로 보아, 여러 앨범이면 리스트 요소가 여러 개일 것. 개별 앨범의 속성에 접근하려면 리스트 각 요소에서 다시 찾고 싶은 key 값에 대응하는 value를 찾아야 했다.
artist_name =[]
album_name = []
album_id =[]
album_type =[]
albums = sp.artist_albums(artist_id='06HL4z0CvFAxyc27GXpf02', album_type='album', country=None, limit=20, offset=0)
#(1) 'items'에 대응하는 value 값: albums['items']
#(2) value에 해당하는 리스트의 각 요소 돌기
for each in albums['items']:
artist_name.append(each['artists'][0]['name'])
album_name.append(each['name'])
album_id.append(each['id'])
album_type.append(each['album_type'])
album_df = pd.DataFrame({'artist_name' : artist_name, 'album_name' : album_name, 'album_id' : album_id, 'album_type' : album_type})
정규 앨범이 총 20개 이하니까 굳이 반복문 안 쓰고 limit=20, offset=0으로 걸어줬다. 찾은 값은 리스트에 넣어주고, 데이터프레임으로 만들기! 지금 우리가 얻은 정보는 각 앨범명과 앨범 개별 ID! (앨범 타입은 이미 설정해뒀지만 확인용으로 추출 ㅎㅎ)
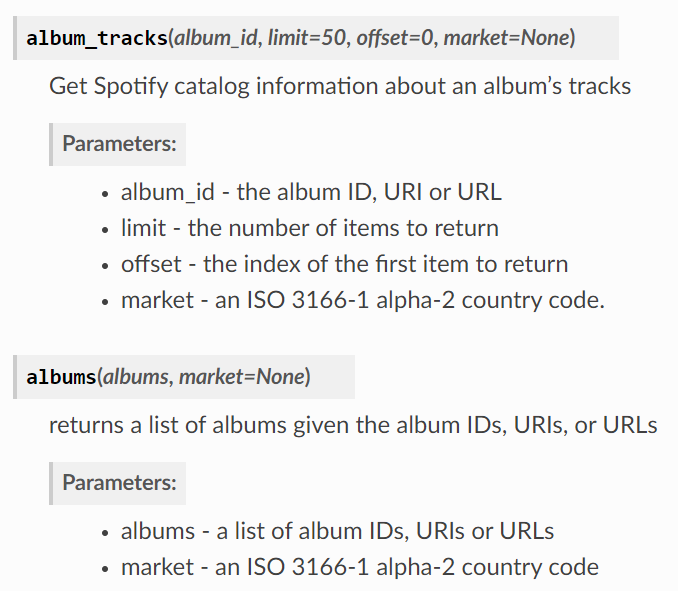
2) 정규 앨범 내 트랙 목록과 고유 ID 값
특정 앨범 내 트랙 정보를 얻기 위한 함수는 album_tracks. 아까 얻은 개별 앨범 아이디 이제 쓰면 된다.
t_artist_name =[]
t_album_name = []
t_album_id =[]
t_track_name = []
t_track_id = []
t_track_duration = []
for id_index in range(len(album_id)):
for i in range(0,200,20):
tracks = sp.album_tracks(album_id=album_id[id_index],limit=20, offset=i)
for each in tracks['items']:
t_artist_name.append(each['artists'][0]['name'])
t_album_name.append(album_name[id_index])
t_album_id.append(album_id[id_index])
t_track_name.append(each['name'])
t_track_id.append(each['id'])
t_track_duration.append(each['duration_ms'])
tracks_df = pd.DataFrame({'artist_name' : t_artist_name,
'album_name' : t_album_name,
'album_id' : t_album_id,
'track_name' : t_track_name,
'track_id' : t_track_id ,
'track_duration_ms' : t_track_duration})
얘 역시 Sample Response 보면서 구조 파악하고, 찾고 싶은 값을 찾아줬다. 아까 만든 album_id 리스트 살려서 야무지게 써먹기 ㅎㅎ
총 트랙 수는 limit으로 건 20개보다 분명 많을테니, 페이지 넘기듯이 '한번에 20개씩 찾되 총 200개 찾아줘' 라고 for 반복문을 걸었다. 이제 개별 트랙 이름과 ID, 곡 길이까지 땄다!
3) 각 트랙의 음악적 특징
특정 앨범 내 트랙 정보를 얻기 위한 함수는 audio_features. 스포티파이에서 임의로 정한 값이긴 하지만, 그래도 음악을 정량적으로 표현하고자 했다는 점에서 신기했다. 분석 때 뭘 쓸지 모르니, 우선 가져올 만한 건 다 가져왔다.

어쿠스틱한 정도, 얼마나 댄서블한지, 얼마나 에너제틱한지, 악기 소리 비중은 어느 정도인지 등등 흥미로운 정보가 많았다. 아까 가져왔던 519개의 트랙 각각의 음악적 특징을 뽑아야 하기 때문에, 역시나 반복문을 활용해 필요한 정보를 리스트에 쭉 담은 다음, 앞서 추출한 트랙 정보와 합쳤다.
f_track_name = []
acousticness = []
danceability = []
f_duration_ms = []
energy = []
f_id = []
instrumentalness = []
key = []
liveness = []
loudness = []
mode = []
speechiness = []
tempo = []
time_signature = []
track_href = []
type = []
valence = []
#총 519개의 트랙
for track_idx in range(len(t_track_id)):
features = sp.audio_features(t_track_id[track_idx])[0]
f_track_name.append(t_track_name[track_idx])
acousticness.append(features['acousticness'])
danceability.append(features['danceability'])
f_duration_ms.append(features['duration_ms'])
energy.append(features['energy'])
f_id.append(features['id'])
instrumentalness.append(features['instrumentalness'])
key.append(features['key'])
liveness.append(features['liveness'])
loudness.append(features['loudness'])
mode.append(features['mode'])
speechiness.append(features['speechiness'])
tempo.append(features['tempo'])
time_signature.append(features['time_signature'])
track_href.append(features['track_href'])
type.append(features['type'])
valence.append(features['valence'])
features_df = pd.DataFrame({'track_name' : f_track_name,
'acousticness' : acousticness,
'danceability ' : danceability,
'duration_ms' : f_duration_ms,
'energy' : energy,
'track_id' : f_id,
'instrumentalness' : instrumentalness,
'key' : key,
'liveness' : liveness,
'loudness' : loudness,
'mode' : mode,
'speechiness' : speechiness,
'tempo' : tempo,
'time_signature' : time_signature,
'track_href' : track_href,
'type' : type,
'valence' : valence})
#track df랑 합치기!
track_features_df = pd.concat([tracks_df, features_df], axis=1)
그럼 이제 앨범, 트랙, 트랙별 음악적 특징 모두 가져왔으니, 보여주기만 하면 되겠다!
(3) 무엇을 보여줄 것인가?
하단의 USA TODAY 기사에서 투어의 세트리스트를 얻었다. 얘는 어느 콘서트 기준인지 모르겠지만, 45곡 중 37번과 38번 곡은 매 공연 지역마다 달라지는 스페셜 트랙이라고 한다!

우선 어떻게 나오나 싶어서 위 45곡의 모든 음악적 특징을 순서대로 다 표현해봤다.
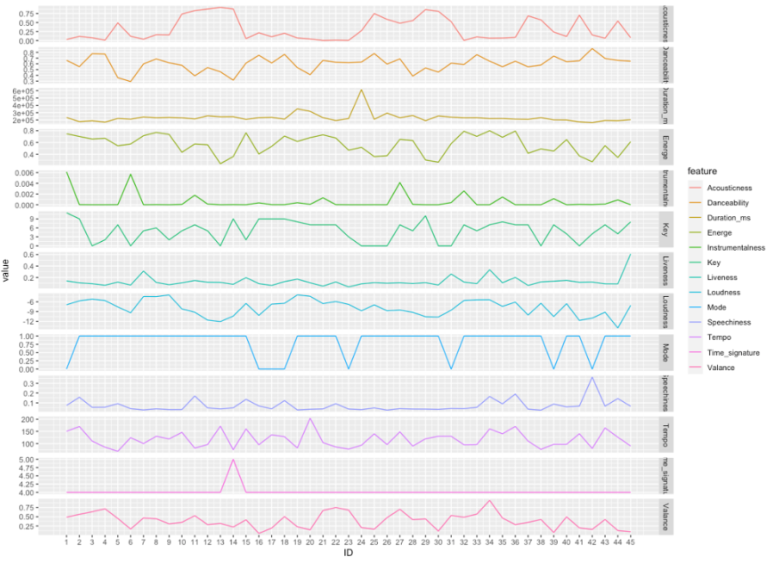
1) Energy와 Danceability의 흐름이 대체로 비슷했고, Acousticness의 흐름은 눈에 잘 보여서 재밌었다.
2) 혼자서 Duration_ms (곡 길이) 가장 높은 저 녀석이 10분 길이의 All Too Well이었는데, 저렇게 중반에 호흡 길게 가져가면 집중 팍 됐겠다! 싶었다.
3) Tempo도 오르락내리락 하는 걸 보니, 확실히 밀당 잘하는 재밌는 공연이었을 거라는 생각이 들었다.
4) Valence라는 지표도 꽤 흥미로운데, '노래의 긍정적인 정도'를 판단하는 지표였다. (1에 가까울수록 긍정적인 것) 장조 단조 여부로 판단하는 거려나? 기준은 잘 모르겠지만, 긍정 수치가 치솟은 34번 곡이 짱 신나는 Shake it off 였어서 왠지 믿음이 갔다.
요렇게 그래프를 찬찬히 보면서, 콘서트를 설명하는 데에 도움이 될 만한 것들을 추려봤다. 1차로 고른 지표들은 Acousticness & Duration_ms & Energy & Valence 이렇게 4개! 스페셜 트랙 부분은 비워두고, 그래프에서 특징적인 부분을 콘서트 세트리스트를 이용해 간단히 설명하고자 했다.
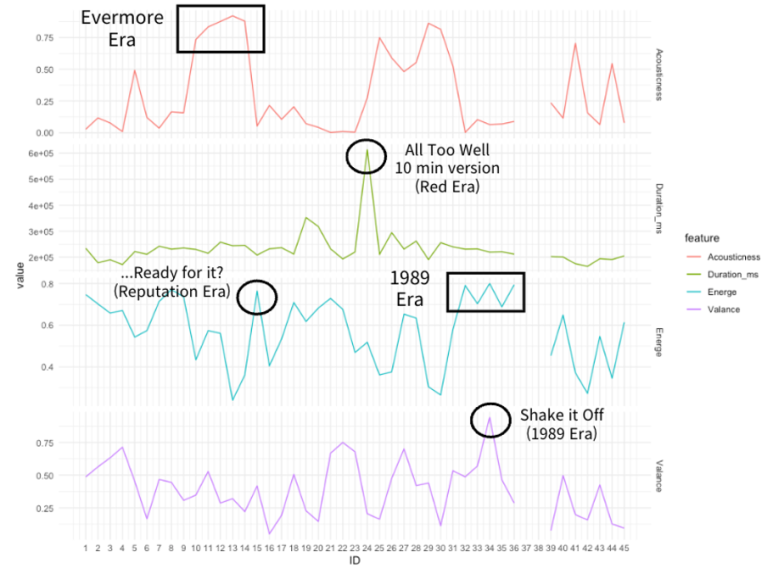
- 이번 테일러 콘서트는 각 정규앨범 별로 섹션(era)이 나뉘어 구성되어 있었다. 예컨대 7집 Lover의 수록곡들을 부를 때는 'Lover Era'인 것이고, 그 다음 2집 Fearless의 수록곡들을 부를 때는 'Fearless Era'인 것이다. 그래서 콘서트 명도 The Eras!
(1) 7집, 2집에 해당하는 Era 이후에는 얼터너티브 록, 포크 풍의 9집 Evermore Era가 시작된다. 콘서트 직캠을 보니 숲처럼 꾸며둔 무대 위에서 피아노를 연주하며 노래했던데, 내가 팬이었음 울었을듯 ㅇㅇ ㅜ
(2) 요렇게 서정적인 Evermore Era가 끝나면.. 테일러의 흑화 시기..라고 불리는 6집 Reputation 수록곡들이 등장한다. 에너지 수치가 확 높아지는 걸 알 수 있다. 특히 '...Ready for it?' 을 부를 때 표범을 연상케 하는 옷을 입고 분위기를 뒤집어 놓으시더라.... (일러 선배님 짱)
(3) 앞서 언급했듯 테일러는 공연 중반부에, 기타 메고 홀로 10분 길이의 'All Too Well' 무대를 꽉 채웠다. 아무리 생각해도 무대 장악력이 어마어마한 가수다.
(4) 또 잔잔하다가 Energy와 Valence가 확 튀는 구간이! (내가 젤 사랑하는 앨범) 5집 1989 Era다. 'Shake it Off'도 포함된 ㅎㅎ
하지만! 하나의 시각화로 너무 많은 정보를 전하기는 어렵고 그리 효과적이지도 않기 때문에, '콘서트의 분위기'를 보여주겠다 하는 목적에 부합한 딱 2개의 지표만 골랐다. 서로 교차되는 게 분명히 보이는 Acousticness와 Energy가 최종 선정 지표 되시겠다.
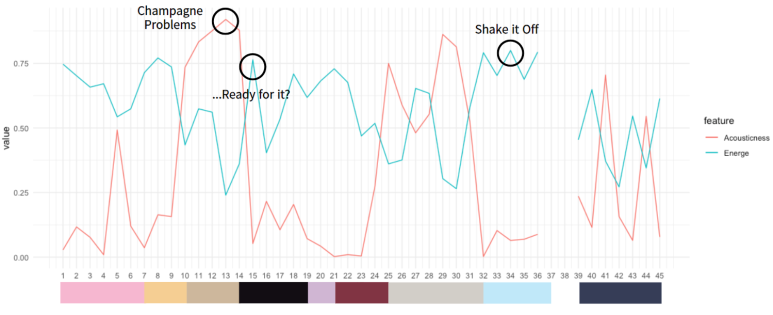
그래프를 겹쳐서 한 눈에 볼 수 있게 그리고, 그래프 아래에는 콘서트 구간 맞춰서 앨범 고유 색상으로 컬러바도 넣어줬다. 시각화 피드백 과정에서 이거 너무 10덕스럽다는 의견까지 나온,
결과가 어땠는지, 그리고 테일러 스위프트에 대해 무슨 말을 하고 싶었는지 더 궁금하다면 아래 기사 참조 - ㅎ.ㅎ
https://premium.sbs.co.kr/article/24fgp-tZEDM
사실 지향점을 선배께서 먼저 제안해주셨기 때문에 분석과 시각화에 대한 아주 깊은 고민이 들어가진 않았지만, 데이터로 요런 것까지 할 수 있구나, 하는 생각이 들어 개인적으로 기억에 남는 경험이었다. (연말결산 제외) 마지막 정규 레터에서까지 소중한 경험 얻어가서 행복했다 -
