[Paper] Distilling Bit-level Sparsity Parallelism for General Purpose Deep Learning Acceleration
Papers
0. Abstract
현재의 Accelerator를 사용하는 상황은 다음과 같다:
- DL 모델은 나날이 발전한다 : Model’s complexity 증가로 인해 High-performance가 요구된다.
- 대부분의 가속기(HW, Accelerator)는 Training은 배제되고, Inference만 가능하다 : Bitlet 방식은 Inference 뿐 만 아니라, 학습 시에도 사용 가능함. → General-Purpose
위의 문제점을 해결하기 위해, Bit-Interleaving 방식과 이를 활용한 Bitlet을 소개함.
- Bit-Interleaving : Bit-level sparsity 를 사용하는 새로운 방식
- Bitlet - 비트 인터리빙을 활용한 새로운 범용 가속기(General-purpose)
- 부동 소수점 FP32/16 둘 다 가능함.
- 고정 소수점 1bit ~ 24bit
- 고성능(High-Performance)
- x15 Performance 향상
- x8 Efficiency 향상
특히, 논문의 저자들은 General-Purpose에 굉장히 큰 초점을 두었다. 여기서 범용(=General-Purpose)이라고 하는 것은
- 여러 타입의 Precision 지원
- Training 시에도 가속기(accelerator) 사용 가능
1. Introduction
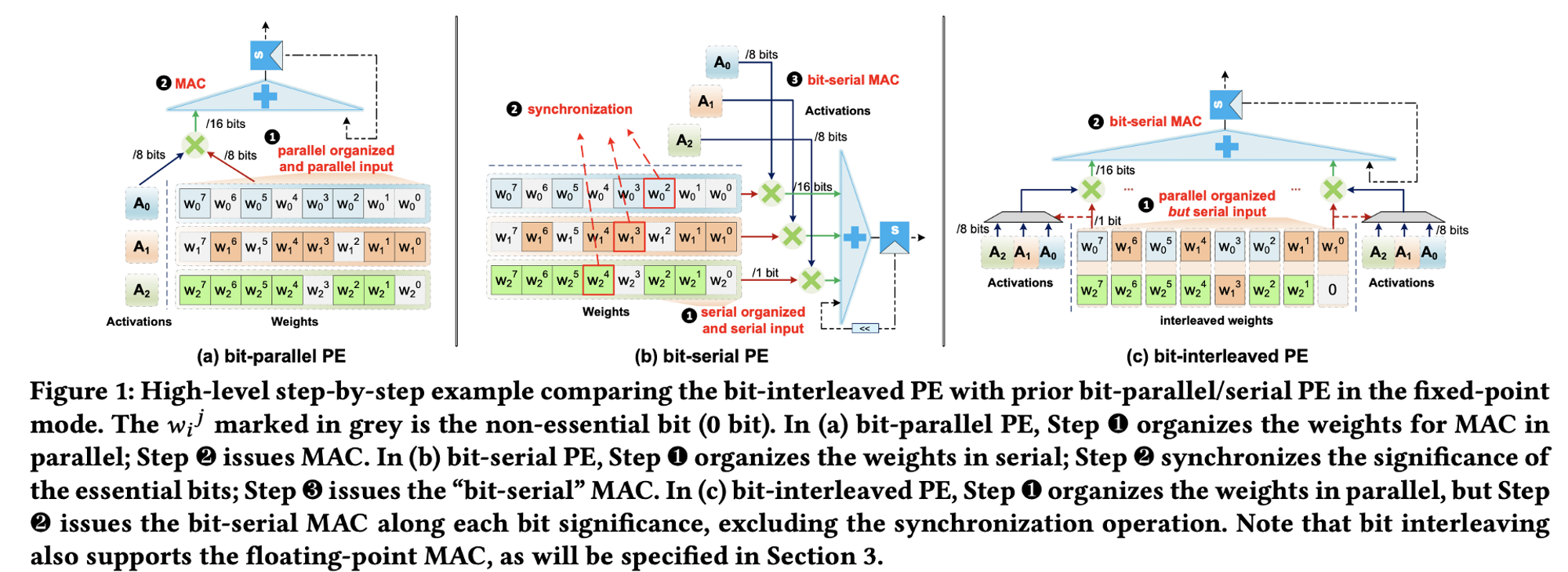
Activation 함수와 Weight(→ Conv-BN 을 거친 Feature Map이라고 이해하자.) 연산하게 될 때, 보통 Weight의 값은 FP32, FP16 등 특정 Precision을 가지고 있다.
(참고 : DL 에서 Quantization이란? → 모델의 weight과 activation을 나타내는 bit 수, 즉 bit depth를 줄이는 것을 의미)
이를 이 논문 이전의 방식에서는 Bit-parallel 하게 연산하거나, Bit-Serial 하게 연산해서 결과를 도출했는데, Bitlet 방식은 앞에 두 방식에서 장점은 가져오고 단점은 버렸다.
- Bit-Parallel
- 방식 자체는 심플함. 개의 Activation + Weight 를 가져와서 병렬로 처리한다는 것. (MAC : Multiply and Accumulate)
- 하지만, 문제는 실제 값이 0인 비트 자리들은 그만큼 공간이 낭비된다는 큰 단점이 있다.
- Bit-Serial
- 복잡한 Synchronization 단계가 “반드시” 포함됨.
- 공간에 대한 낭비는 없음(?).
- Bit-Interleaving
- Parallel의 방식을 채용함, 하지만 bit shifting을 통해 Parallel에서의 문제점이었던 빈 공간에 대한 낭비가 사라짐.
- MAC 연산 자체는 Serial의 방식을 가져옴. 하지만 bit shifting 덕분에 Serial의 큰 문제였던 Complex Synchronization 단계가 사라짐.
- 즉, Parallel의 장점과 Serial의 장점을 가져오면서, 자연스럽게 각 방법론에서 도출되는 단점은 사라지면서 장점만 남게 되었다.
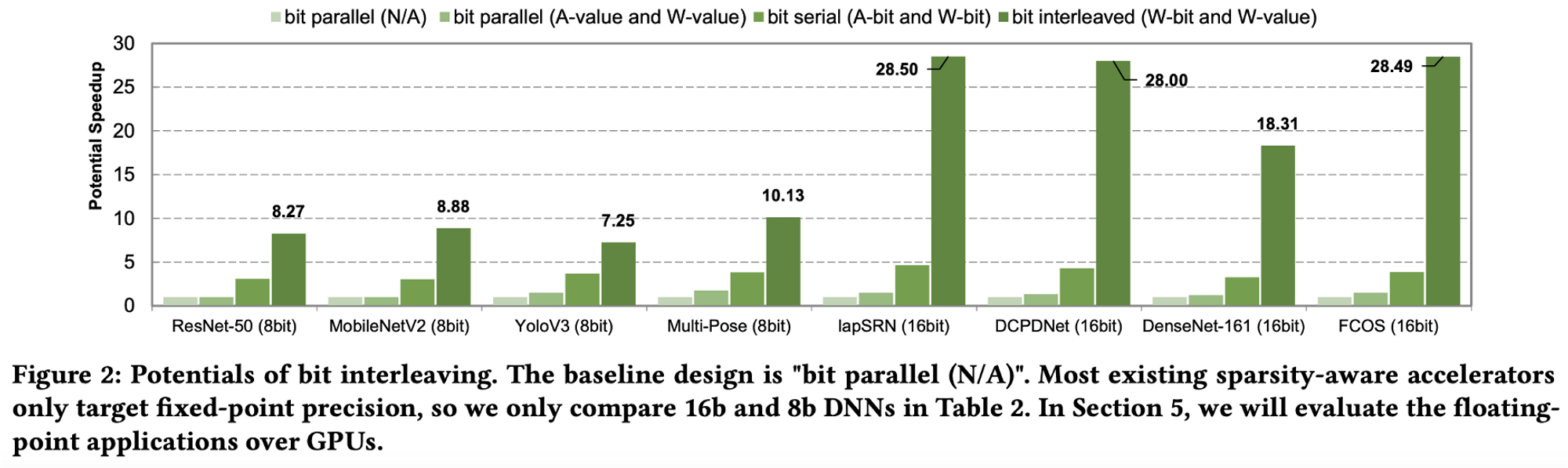
Bit-Interleaving 방식이 이전의 방법론들 (Parallel, Serial)에 비해 월등히 높은 잠재적인 속도 향상을 가지고 있음.
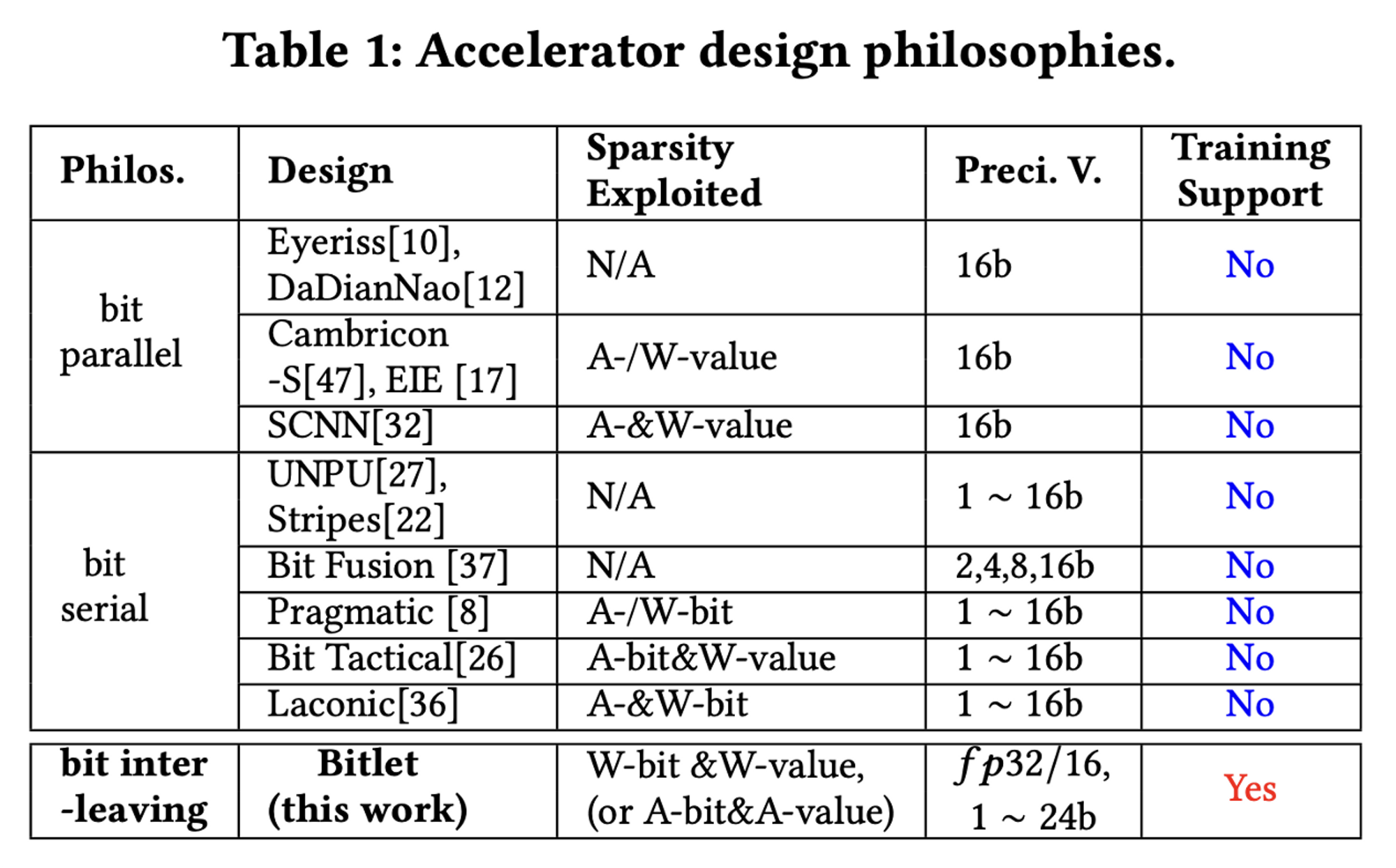
그리고, Bit-Interleaving을 사용한 Bitlet 가속기는 FP32/16 뿐 만 아니라, Fixed Point(고정 소수점) 1bit-24bit 까지 모두 지원하며 Training 역시 지원한다고 한다. = General-Purpose
2. Related Works
- 이전의 것들(Bit-parallel, Bit-serial)은 general-purpose가 아님.
- 추론(Inference) 시에만 가속기가 적용되고, FP precision에도 제약이 존재.
- 최적화 되어 있지 못한 Sparsity의 활용
- Bit-parallel : bit-level sparsity 를 활용할 수 없음.
- bit-level sparsity란?
→ parallel 연산 시에 실제 값이 없는 부분(= 0)이 그대로 살아있으면서 공간 낭비가 심하다고 했는데, 병렬에서는 어쩔 수 없이 처리하지 못하고 연산했었음.
- Bit-serial : synchronization이 필요함.
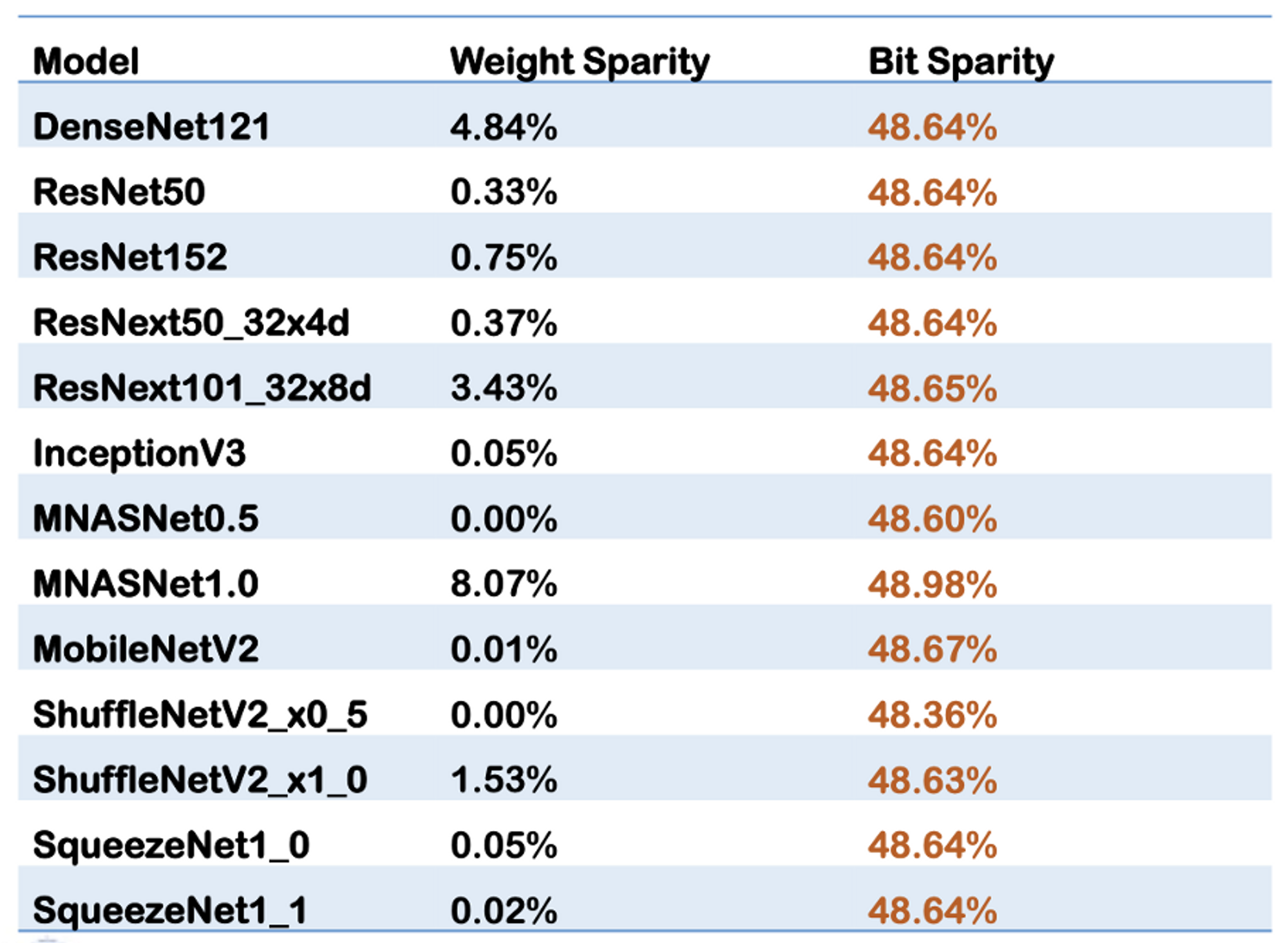
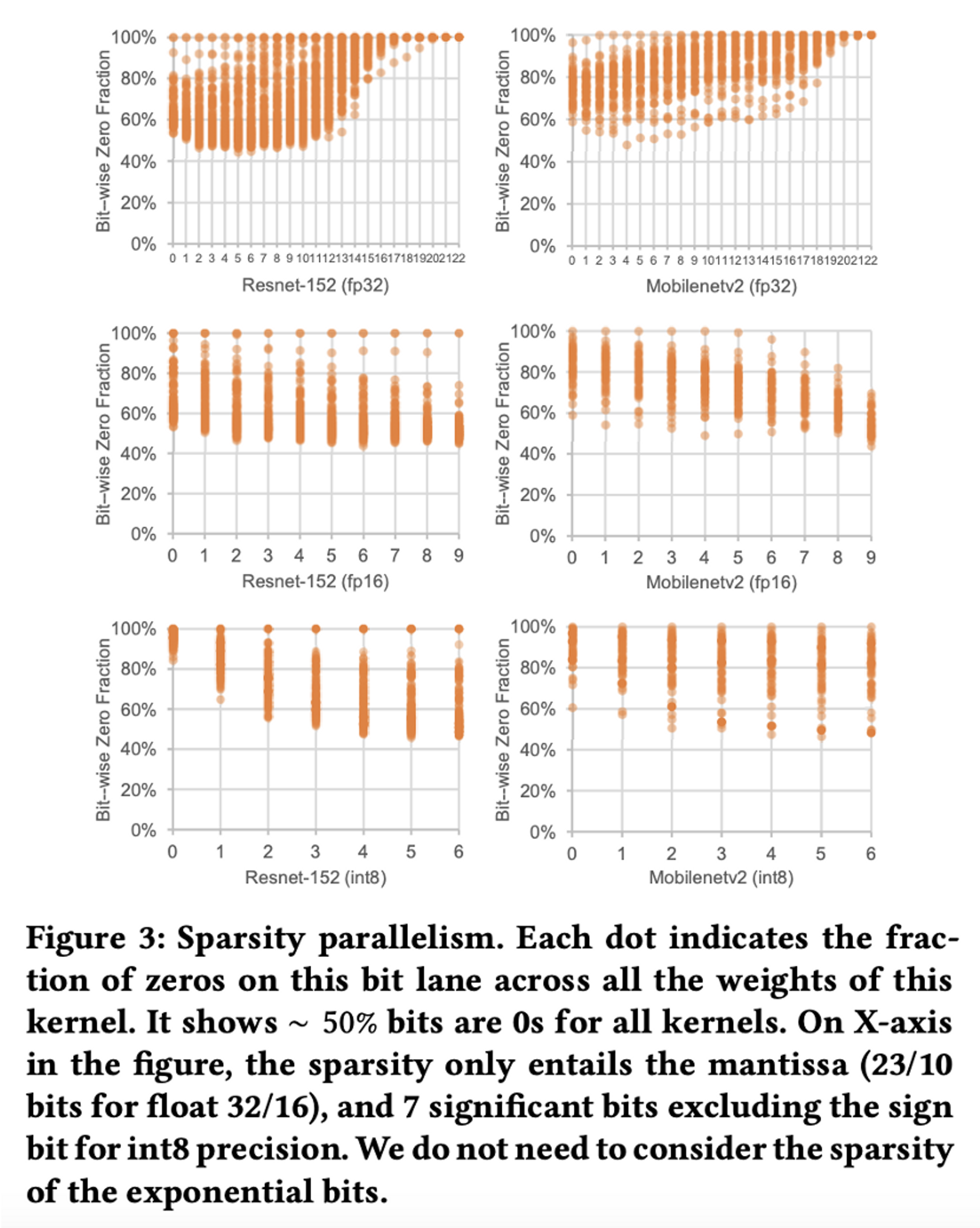
위쪽 표를 보면, 전체 네트워크(=모델)에서 Feed-Forward를 시킬 때 연산에 들어가는 실제 값(= 1)이 아닌, 0의 비율이 약 48%정도 된다.
이 말은, 48%의 공간 및 에너지 소모를 줄일 수 있는데 그러지 못한다는 의미.
아래쪽 그림은 심지어 이 bit-level sparsity가 일정한 패턴을 가지고 있다는 것을 볼 수 있다.
- 각 bit significance 에서 높은 Sparsity 를 보임.
- 균일한 Sparsity
- 병렬 처리에서 발생하는 좋은 점들
- 동기화 필요 없음.
- Bit-level 산술 연산은 독립적으로 수행 된다.
3. Methods - Bit Interleaving
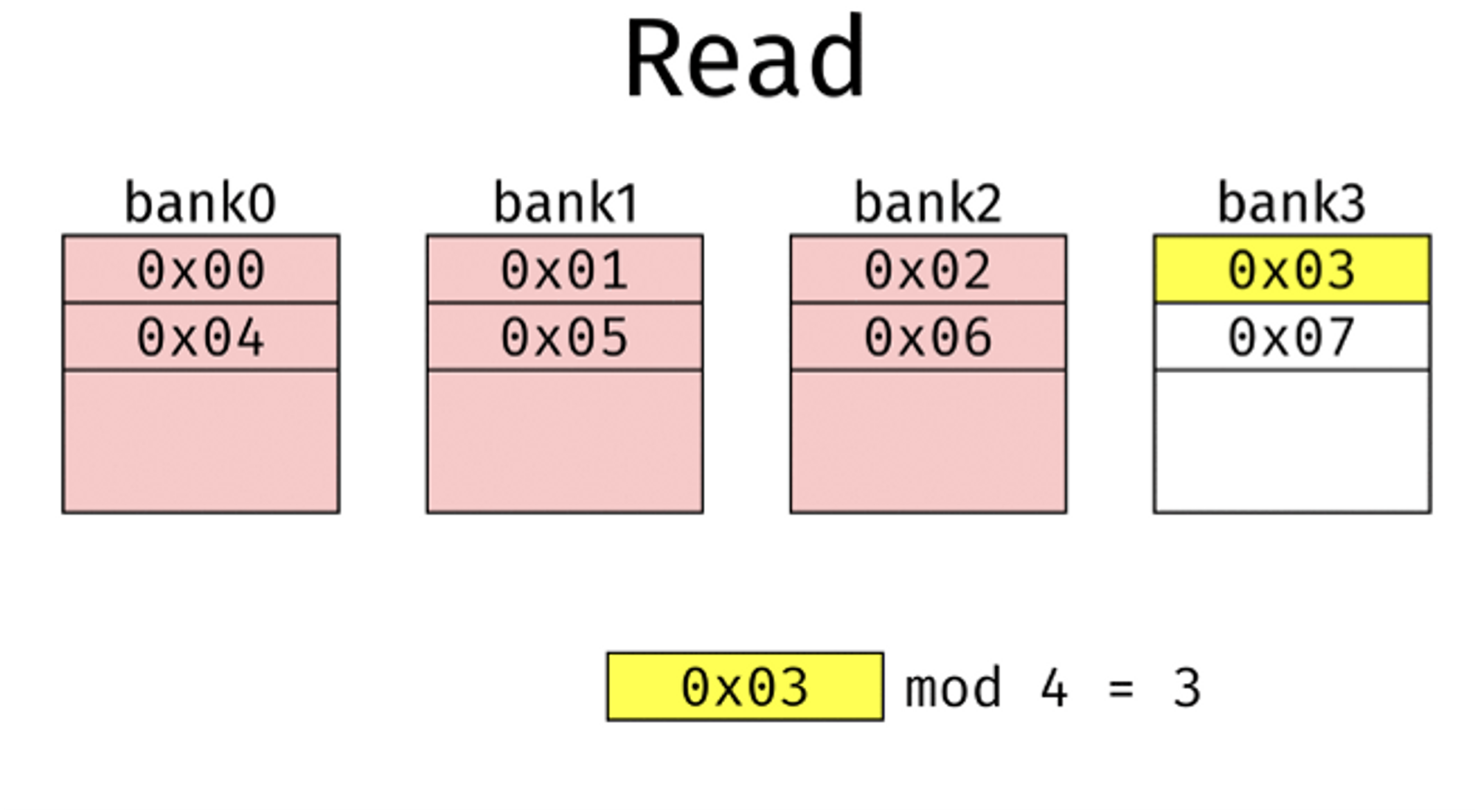
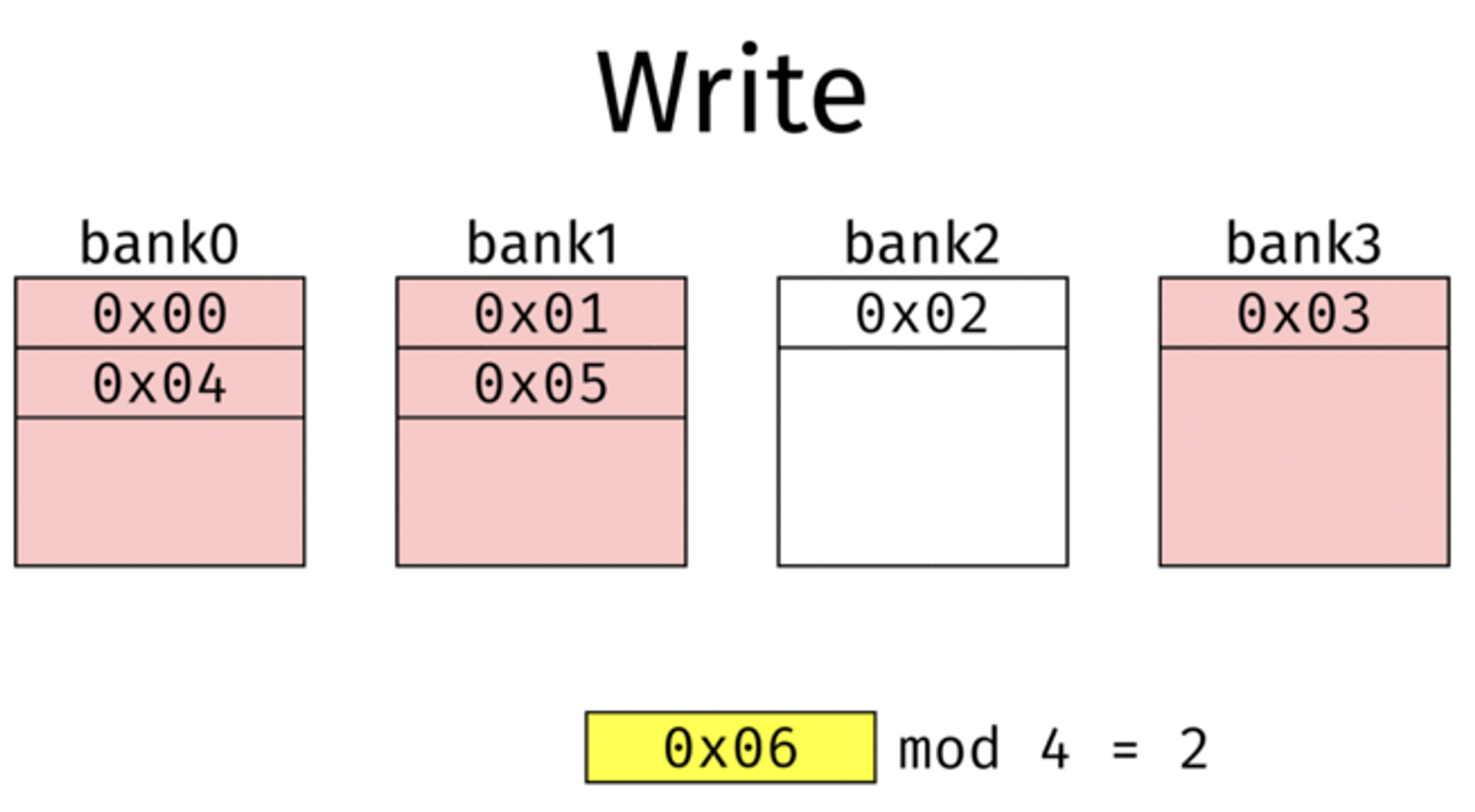
Interleaving이란? (예시 그림 : Memory Interleaving)
- 위에 그림처럼, 주 목적은 “메모리에 있는 데이터를 빠르게 접근하기 위함.” 이다.
- 메모리의 데이터를 bank에 넣는 것이 아니고, 메모리의 주소를 bank에 넣어두는 것. (=DB의 Indexing이랑 비슷한 방법)
- 위 그림에서는 modula 4 로 해서, bank0 - bank3까지 메모리 주소를 넣어둠.
- 참고 : https://ko.wikipedia.org/wiki/메모리_인터리빙
Bit-Interleaving의 목적
- Bit-level sparsity를 활용할 수 있는GP Accelerator 설계하기.
- 장점
- 복잡한 Synchronization 필요 없음.
- Sparsity를 효율적으로 이용할 수 있음.
Floating Point(FP, 부동 소수점)
- Floating Point 는 부호비트, 지수부, 가수부 순서로 구성되어있다.
- Significant : 부호비트, 1bit → 양수일 경우 0, 음수일 경우 1
- Exponent : 지수부, 5bit or 8bit → FP 32의 경우에 Exponent는 8bit의 공간을 차지함. 즉 2^128 승 까지 표현 가능
- Mantissa : 가수부, 10bit or 23bit → FP 32의 경우에 Mantissa는 23bit의 공간을 차지함. 2^23 승 까지 표현 가능.
>>> math.pow(2, 128)
3.402823669209385e+38- FP32 = 1Sig + 8Exp + 23Man
- FP16 = 1Sig + 5Exp + 10Man

FP 32bit 의 예시. 𝑓𝑝 = (−1)^S*1.M×2^E-127
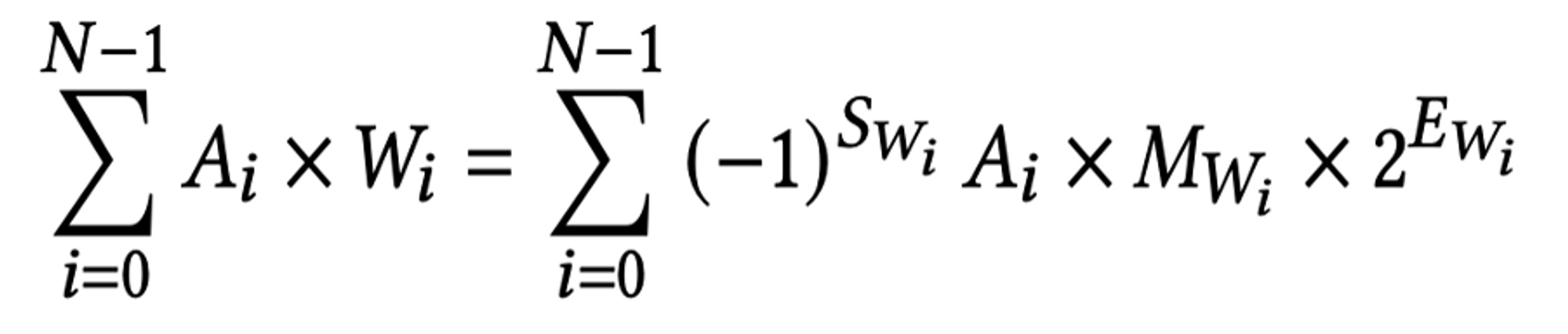
위 식을 Decomposition 하면
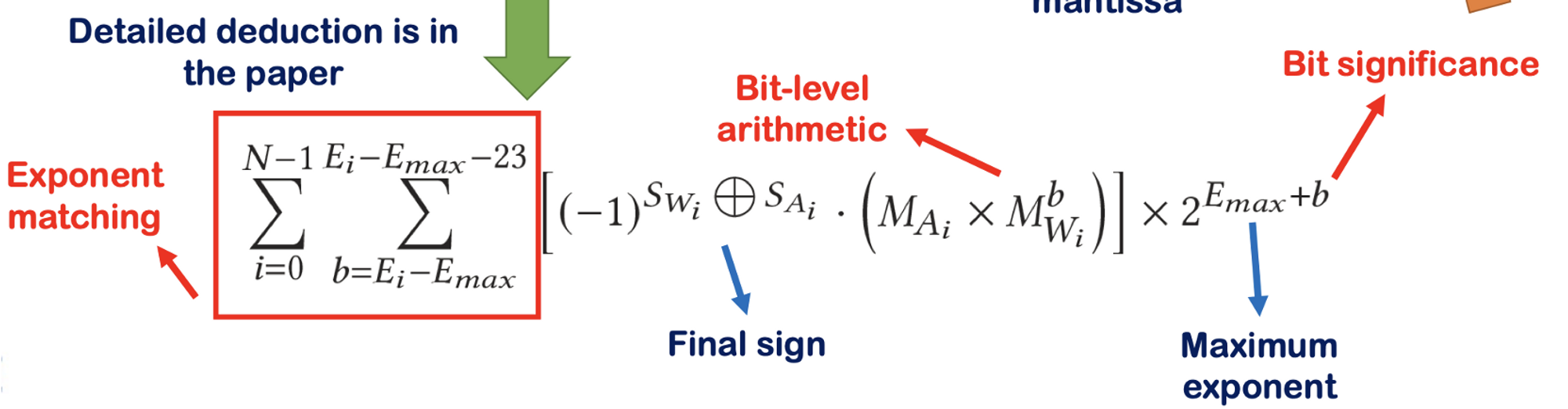
4. Bitlet Accelerator

Bitlet 가속기에서 사용하는 Bit-Interleaving에 대한 설명이다.
자세한 스텝 별 동작을 보기 전에, 기본적인 개념을 잡고 간다.
- = 12.625 인데, 1100.101 = = 8 + 4 + 0.5 + 0.125 = 12 + 0.625 = 12.625
- 맨 앞에 빨간색 테두리 있는 자리는 hidden bit ‘1’ in IEEE 754
- = 3 인데, 이 의미는 binary point 에서 hidden bit 까지의 개수, 즉 Exponent bit의 자리 수이다. (순서가 Significant - Exponent - Mantissa)
- 여기서 보면 맨 아래 이 가장 긴 자리를 가지고 있음 ()
- Bit-Interleaving 동작은 “Preprocessing” → “Exponent Matching” → “bit distillation(압축)” 3단계로 이루어져 있음.
이제 각 스텝 별 동작에 대해서 알아봐야 한다.
- Preprocessing
- 맨 앞에 hidden bit를 넣고, 뒤쪽에 전부 0으로 채운다.
- 이 때의 기준은 Emax 의 전체 비트 길이(= )
- 위 그림에서는 hidden bit 1bit + exp 6bit + 나머지 2bit = 9bit → Mantissa 9bit
- Dynamic Exponent Matching
- 가장 긴 Emax Weight 를 기준으로 하여, binary point를 일렬로 정렬한다. (기준점 맞추기)
- 그러면서 발생하는, binary point 이후 가수부의 길이가 나올텐데, 는 가수부가 5bit나 된다.
- 그래서, Emax weight = 에 zero-padding을 3개 더 넣어줌으로써 Mantissa 가 총 12bit가 된다. (왜 12bit로 확장되는지에 대해서 답할 수 있어야 함.)
- Bit Distillation
- 저 그림을 거꾸로 뒤집어서 Gravity를 적용한다고 생각하면 편하다.
- 0은 통과가능함.
결과론적으로 보면, 만약 Bit-Parallel 방식으로 연산한다면 총 MAC 연산이 6개가 들어가야 하는데 ( ~ ) Bit-Interleaving 을 하게 되면 총 3개만 하면 된다.
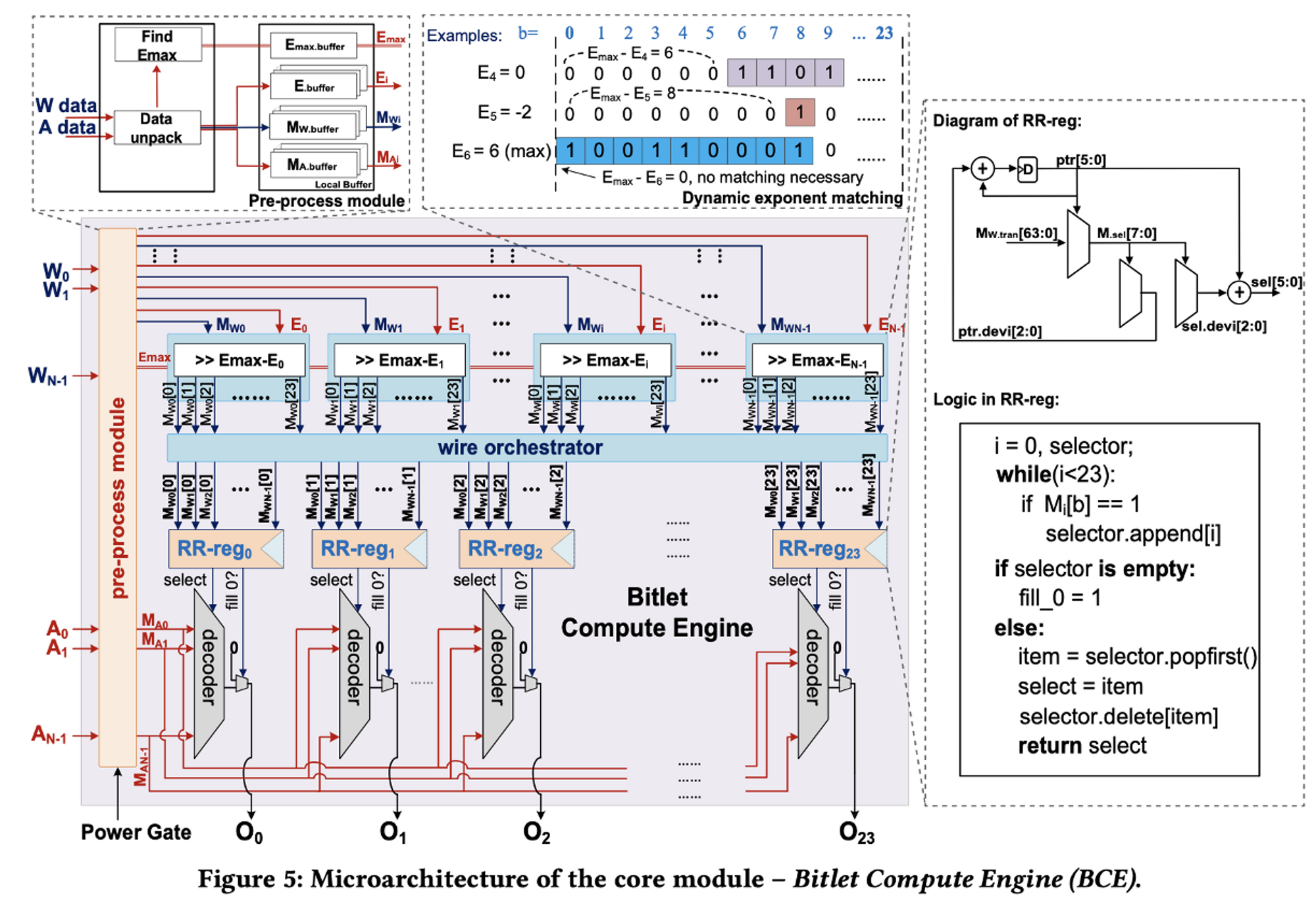
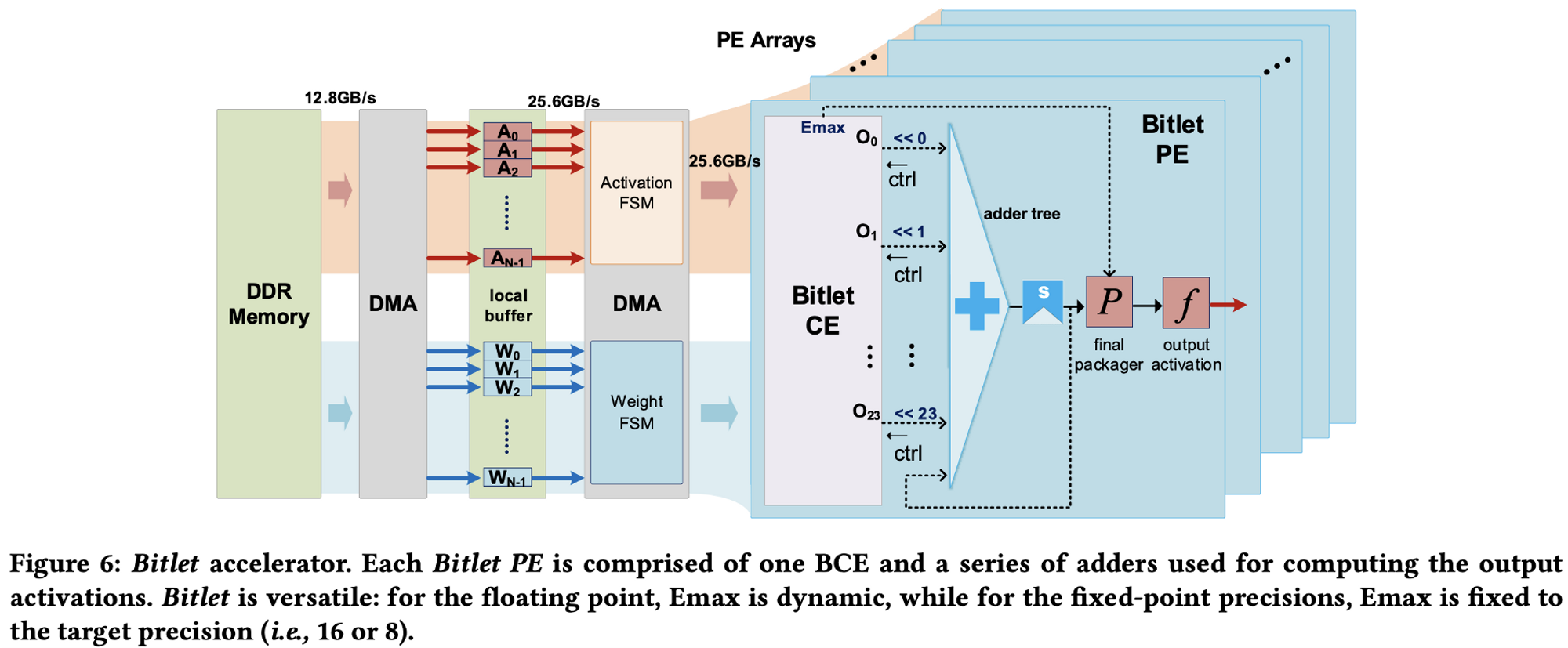
- CE : Compute Engine
- PE : Processing Element
위쪽은 칩(=CE)의 구조/설계 이고, 아래쪽은 실제 PE Flow이다.
(PE 이미지 쪽에 있는 Bitlet CE에 왼쪽의 칩 구조가 들어있음)
5. Evaluation
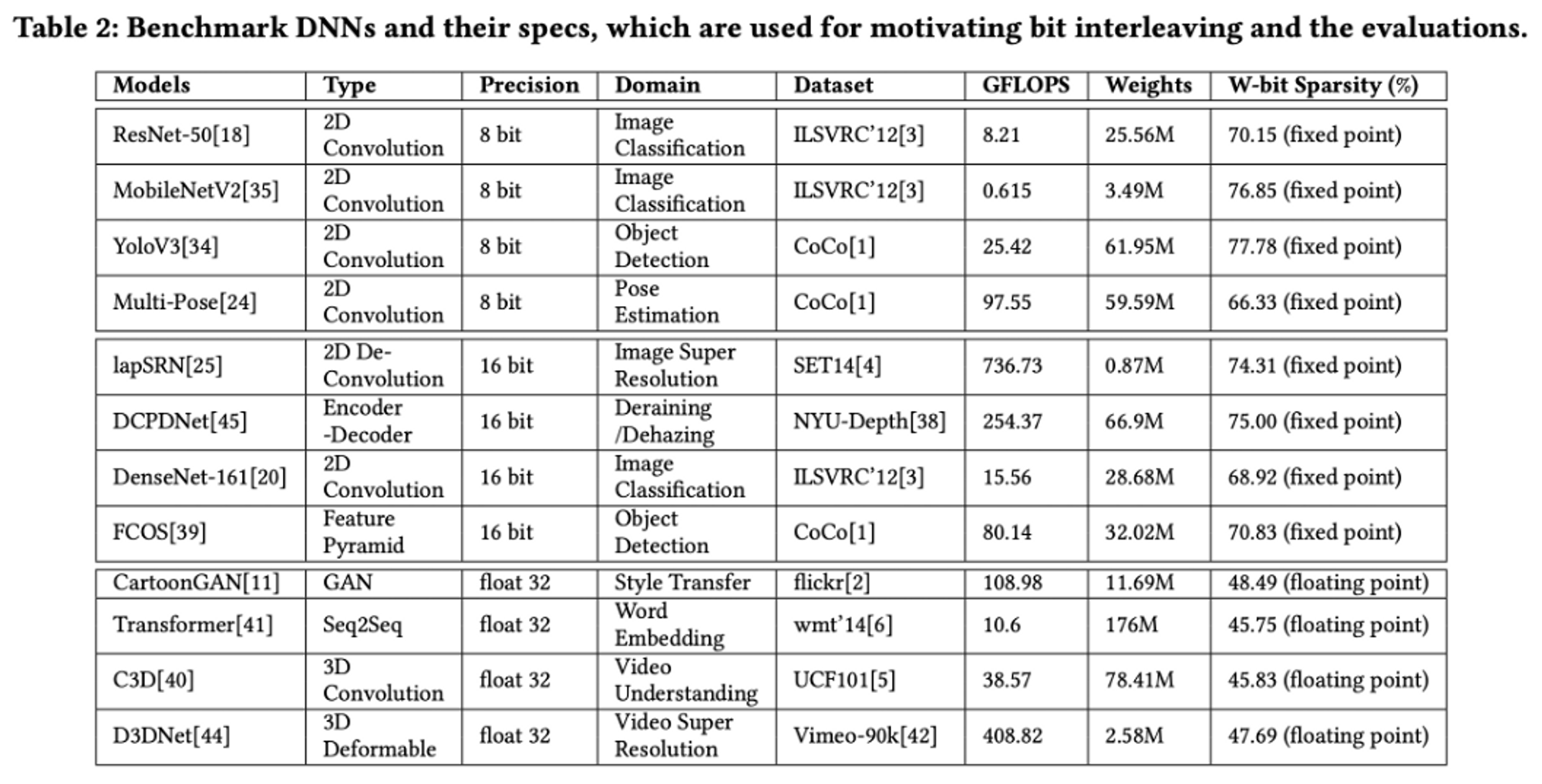
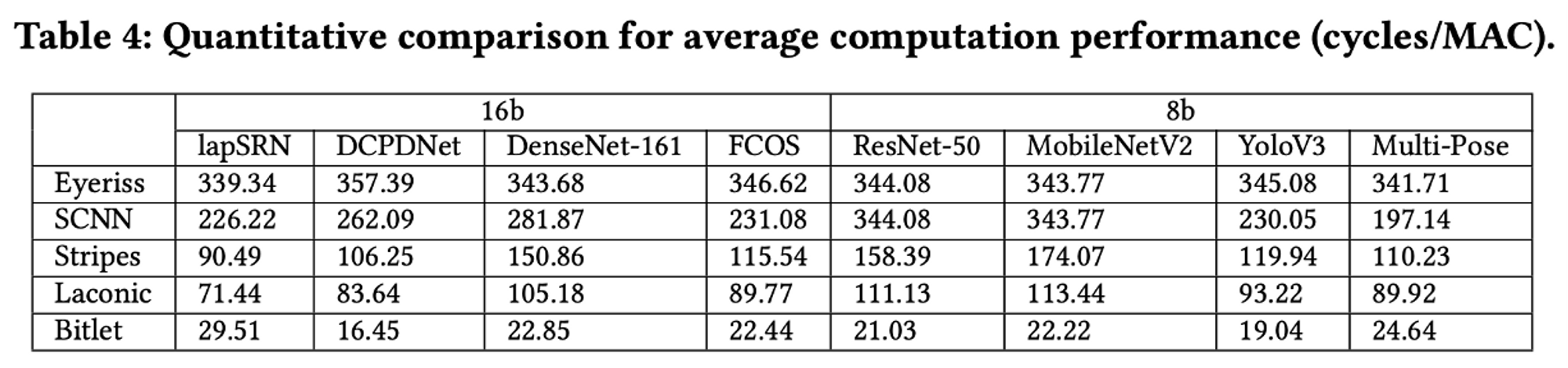
실험 대상이 되는 DL 네트워크이다.
21년도 논문임에도 불구하고, 되게 이전 모델들이 보이는데 내가 알기로는 저 ResNet, MobileNet 등등이 실제 H/W Accelerator에서 예시로 많이 사용하는 모델이었다.
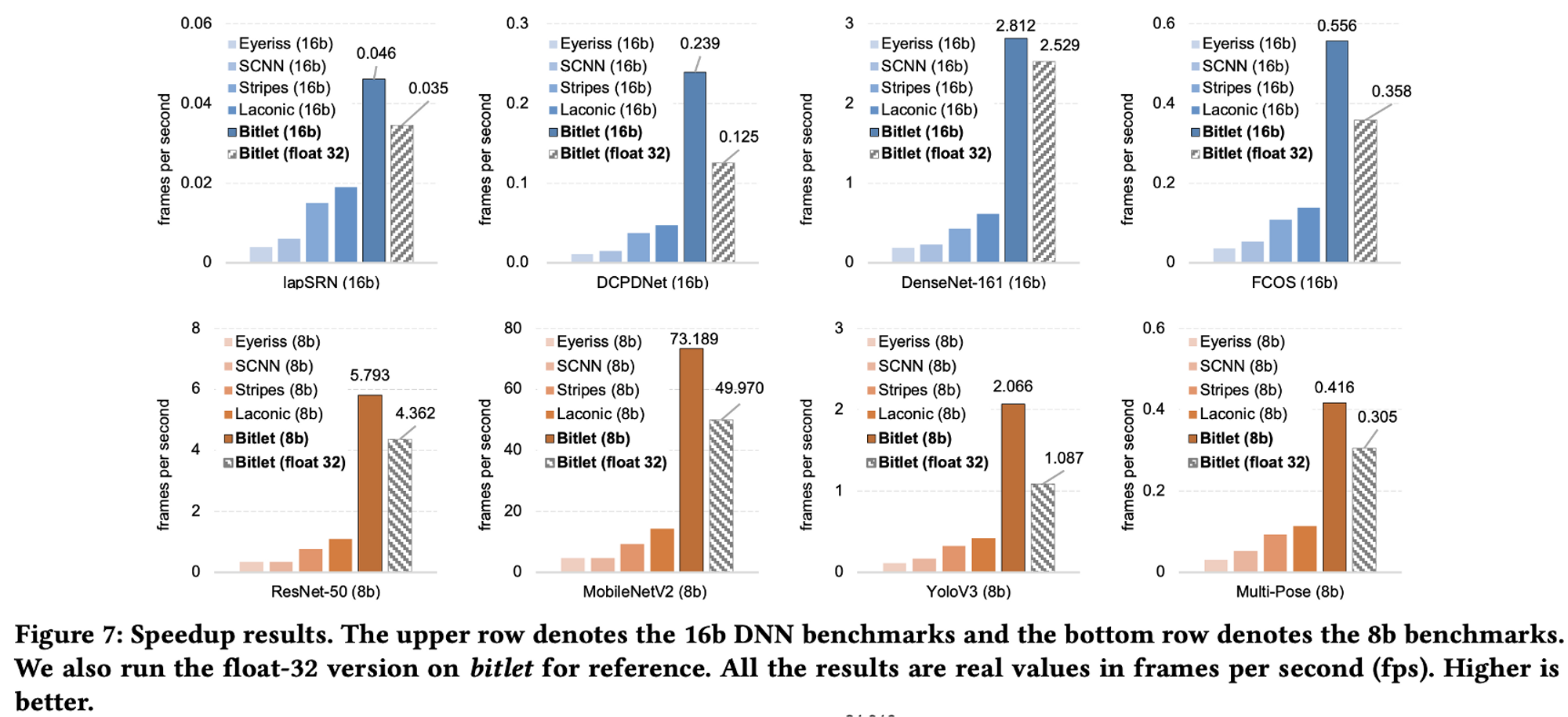
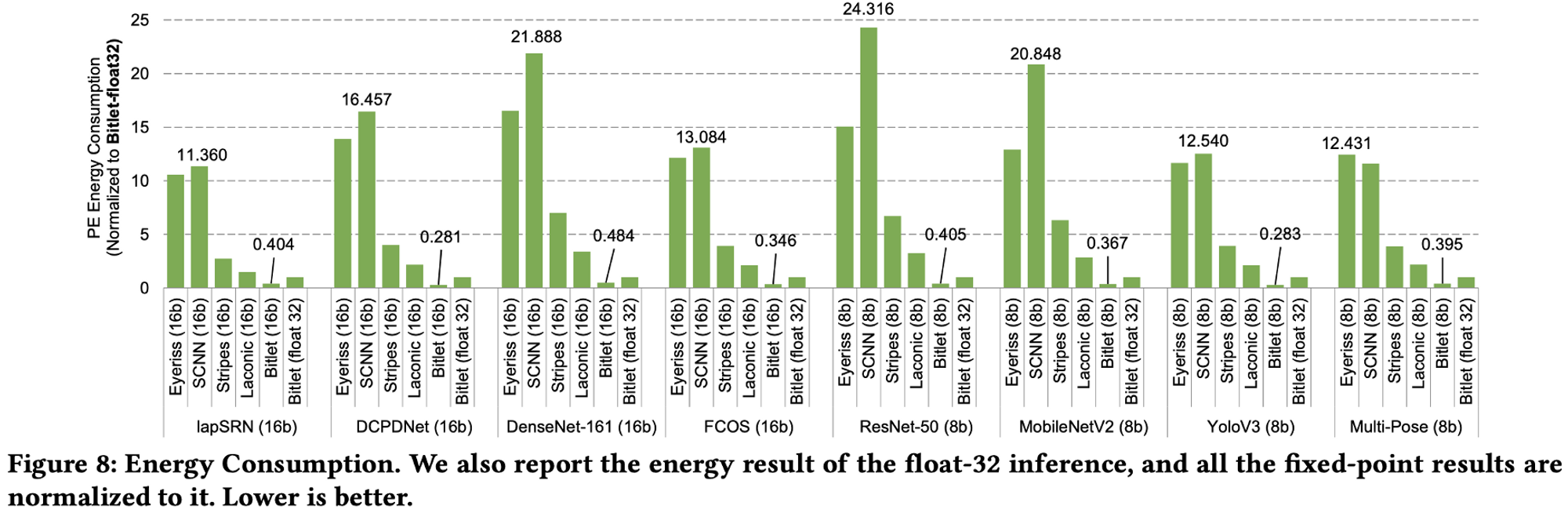
앞에 float 가 붙은 것은 Floating Point 를 의미하고, 8b/16b 는 각각 Fixed Point 8bit와 16bit를 의미한다.
그림을 보면, Eyeriss, SCNN, Stripes 등에 비해 많은 FPS 상승과 효율이 좋은 Energy Consumption을 보인다.
특정 모델에서만 좋은 것이 아니고, Evaluation 타겟으로 잡은 DL 모두에 대해서 좋은 성능을 보임을 알 수 있다.
