Better plain ViT baselines for ImageNet-1k
이번에 소개할 논문은 5월 3일 Paperswithcode에 게재된
"Better plain ViT baselines for ImageNet-1k" 라는 논문입니다.
(논문 링크 : https://arxiv.org/pdf/2205.01580.pdf)
논문 자체가 3장으로 구성되어 있기 때문에, 읽기 편할 것입니다.
논문 제목에 나와있는 ViT 모델은 Image Classification task에서 사용되는 모델로써, NLP(Natural Language processing)에서 사용되는 Transformer 모듈을 Image task에 적용한 아주 유명한 모델입니다.
(ViT 이전에는 Convolution 연산이 Image Task의 독보적인 수단이었지만, ViT 이후로 Classification 뿐만 아니라 Object Detection(ex. DETR), Video Recognition 등에서도 Transformer 모듈이 활용될 정도로 ViT가 그 판도를 바꿔놓았습니다.)
기회가 되면 ViT 자체 논문과 Attention(name: Attention is all you need) 논문, BERT 논문에 대해서도 다뤄볼 예정입니다.
- ViT paper : An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
- Attention paper : Attention Is All You Need
- BERT paper : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
(본 블로그에 있는 DETR 요약 포스트 : DETR - End-to-End Object Detection with Transformer)
0. Abstract
ViT는 Vision Transformer의 약자입니다. ViT의 발표 이후로 Image Classification 뿐만 아니라 다양한 Image 분야에서 Transformer 모듈을 적극 기용하고 있습니다.
ViT는 Image Classification 모델로써, 분류 라벨을 1000개나 가지고 있는 ImageNet 경진대회 (ILSVRC, ImageNet Large Scale Visual Recognition Challenge)에서 매우 우수한 성능을 보였습니다.
Vision Transformer 기술을 ImageNet-1k 경진대회에서 잘 쓰기 위해서는 "sophisticated regularization"이 있어야 하는데, 사실 이러한 것들 말고 일반적인 데이터 증대 기법(standard data augmentation)만으로도 놀라운 성능을 보여줄 수 있습니다.
본 논문에서는 일반적인 ViT 모델에서 몇 개의 수정을 통해 성능을 dramatical 하게 올렸습니다.
특히, 90epochs 만으로 top-1 accuracy가 76%를 넘었고, 300 epochs 까지 가는데 하루도 걸리지 않았습니다.
1. Introduction
ImageNet 경진대회의 데이터셋 ImageNet 데이터셋은 Image Classification 모델의 지표, 랭킹을 매기는데 굉장히 중요한 지표입니다. 대부분의 Classification 모델이 ImageNet 데이터셋을 사용하여 벤치마크 점수를 매기고, 랭킹을 매기게 됩니다.
ViT 모델에 대한 논문은 ImageNet과 같이 large-scale의 Dataset을 대상으로 하여, 잘 tuning된 ResNet보다 우월함을 보였습니다. ImageNet Dataset은 Classification 분야의 testbed(실험의 기준점) 역할을 하며, 이 데이터셋을 사용하는 모델은 여러 수정사항 없이 간단한 baseline의 코드를 사용하는 것(코드 자체를 보유한다는 의미?)이 꽤나 높은 이점이 될 수 있습니다.
본 논문은 introduction 단락에서 big_vision 이라는 것을 소개하고 있습니다. 이 big_vision은 ViT를 포함하여 MLP-Mixer, LiT 등 vision transformer 모델을 baseline 적으로 가지고 있으며, 논문 자체적으로 baseline의 모델로 높은 성능을 보여줄 수 있었는지 기술하게 됩니다.
요약하자면, "ImageNet Dataset을 타겟으로 하여 ViT의 baseline 모델에 충실하게 실험을 진행했다."라고 말하고 싶은 것 같습니다. (이것은 big_vision에 코드가 탑재되어 있습니다.)
애초에 뒷부분을 보게 되면 모델 아키텍쳐의 변형이 이루어지지 않으며, batch_size 변경과 같은 아주 일반적이고 사소한 부분을 변형했습니다.
단순함을 추구하는 논문으로 볼 수 있겠네요.
2. Experimental setup
실험(훈련 및 평가)은 전부 ImageNet 데이터셋을 타겟으로 삼았습니다.
실험에 대한 모델은 ViT-S/16 모델로 선정하였고, 만약 컴퓨팅 자원이 많이 남는 경우엔 ViT-B/16이나 ViT-B/32를 써도 된다고 합니다.
Transformer 모듈 사용시 이미지를 n 크기의 "patch"로 나누는 부분이 있는데, 이 patch를 늘리는 것은 Image의 해상도(resolution)를 줄이는 것과 동일합니다.
(ViT-B/16의 경우 patch 크기가 16이 되고, ViT-B/32의 경우 patch 크기가 32가 됩니다. 이러한 이유 때문에 patch 크기를 언급한 것 같네요.)
실험은 Inception Crop, random horizontal flip, random Augmentation 그리고 Mixup Augmentation을 사용하였습니다.
3. Results
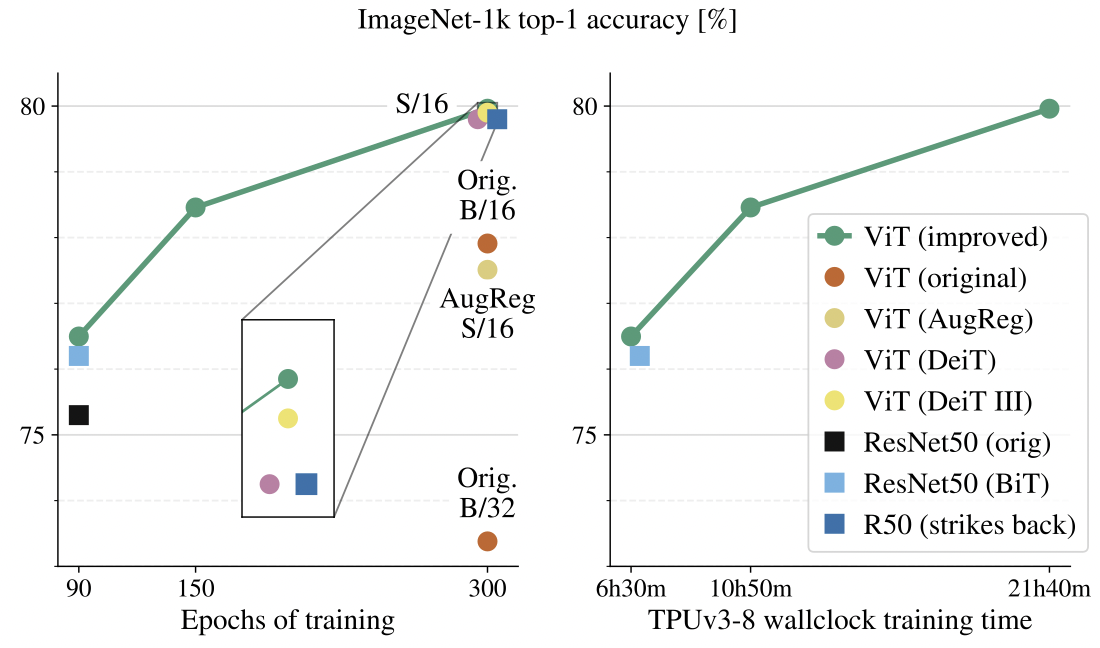
Experimental setup 파트의 setup을 통해 학습한 결과,
80%의 성능이 나오는 Epoch 300까지 21시간 40분밖에 걸리지 않았고
성능 또한 original ViT보다 2% 정도 더 높습니다.
ResNet original을 90 epoch 동안 학습시키고, improved ViT 역시 90 epoch 동안 학습시켰을 때는 성능이 1-2% 내외로 ResNet보다 더 높습니다.
기존의 ViT original 논문과 학습 부분에서 차이점을 둔 것은 다음과 같습니다:
- batch_size를 4096에서 1024로 낮춤.
- class token 대신 GAP(Global Average Pooling) 사용.
- 적은 수준의 Random Augmentation과 Mixup 사용.
- Position Embedding은 fixed 2D sin-cos 사용.
이렇게 ViT 모델에서 위와 같은 단순한 변경을 통해, 최종 300 Epoch에서 original ViT-B/32 모델 보다 약 6% 정도 성능 증가를 보였습니다.
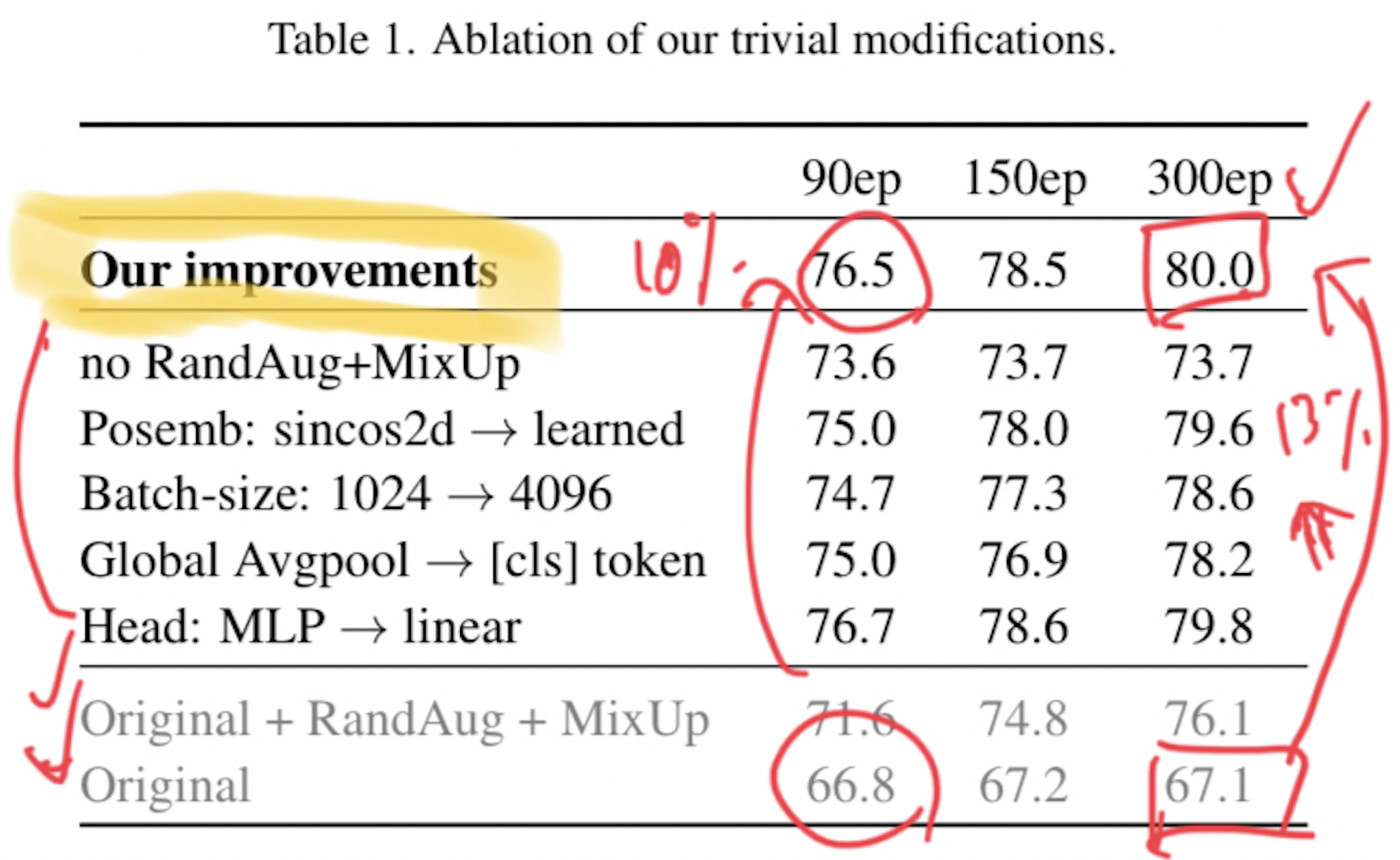
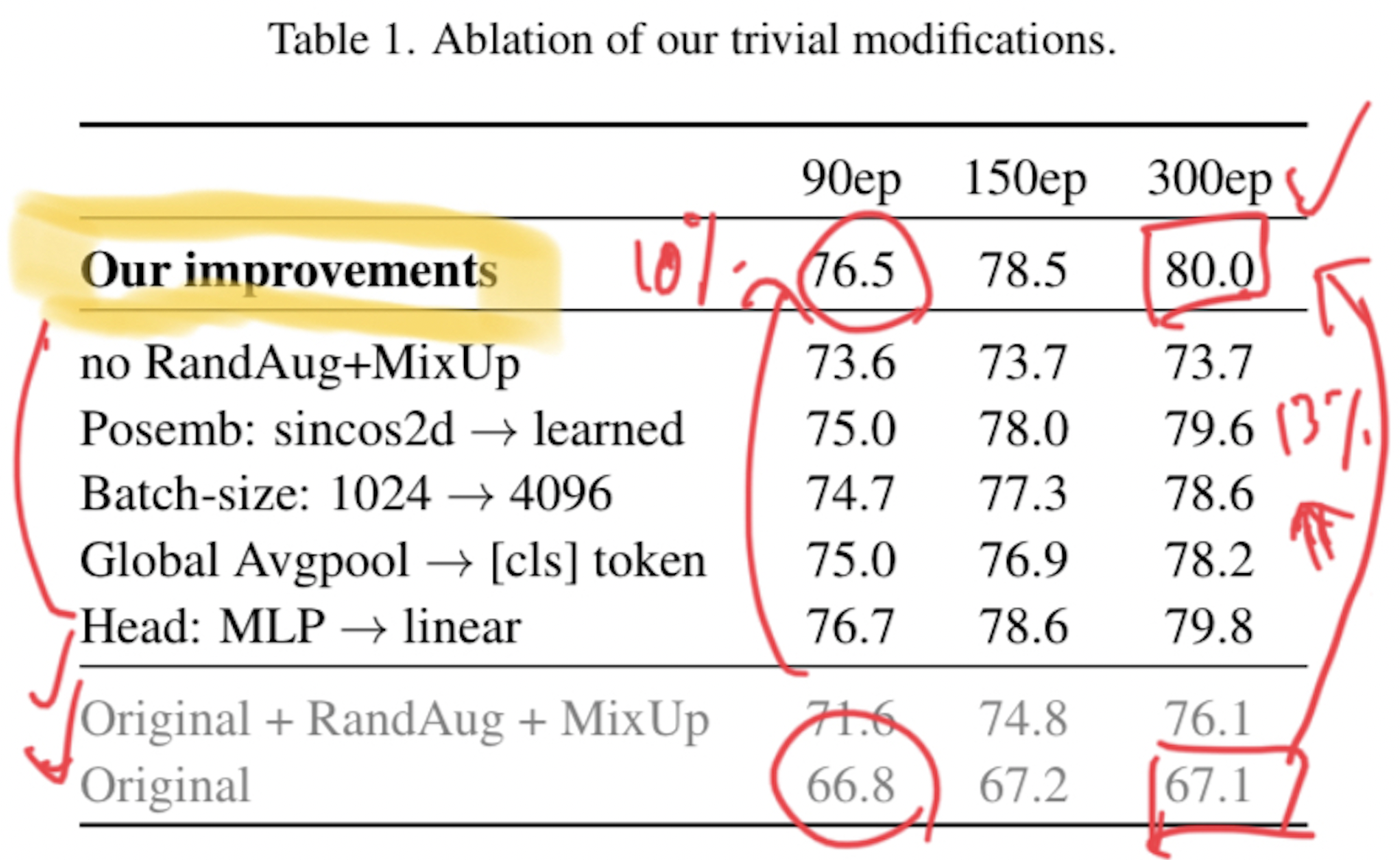
이 표를 보게 되면, original 보다 성능이 올라간 것은 확실한 사실입니다.
이 표에서 주목해야 할 부분은, 위에서 언급한 4가지 변경점을 하나씩 제거해 보았을 때의 성능 결과입니다.
가장 변경점이 적은 부분은 모델의 Head 부분을 MLP에서 linear로 변경하였을 때가 가장 성능 변화가 없었습니다. 그 외의 변경점은 1-2% 내외로 성능 하락이 존재합니다.
요약해보자면, "이렇게 단순한 baseline 모델에서 단순한 변경 사항들(batch_size 변경, GAP 추가, augmentation 기법 추가 등)을 사용함으로써 드라마틱한 성능 향상을 이루어낼 수 있다" 가 핵심이라고 볼 수 있겠습니다.
SAM(Sharpness Aware Minimization) 기법, CutMix, blurring, 고해상도에서의 파인 튜닝, 드롭아웃, 모델 구조 변경, stochastic depth와 같은 고급 기술(?)들은 하나도 적용하지 않았습니다.
5. Conclusion
항상 단순한 것을 추구하는 것은 가치있다고 하네요.
"It is always worth striving for simplicity."
(Paper Review는 제가 스스로 읽고 작성한 글이므로, 주관적인 내용임을 밝힙니다.)
