GDSC-ML
1.[GDSC-ML] Practice: Improve accuracy of ImageNet Classification project

learning_rate: 2e-05, batch size: 16 learning_rate: 0.001, batch size: 256
2022년 10월 13일
2.[ML] Hyperparameter Tuning: Learning rate and Batch size

https://openreview.net/pdf?id=B1Yy1BxCZBatch Sizesmall: converges quickly at the cost of noise in the training processlarge: converges slowly wit
2022년 10월 13일
3.[ML] Various ways for Hyperparameter Tuning in Machine Learning
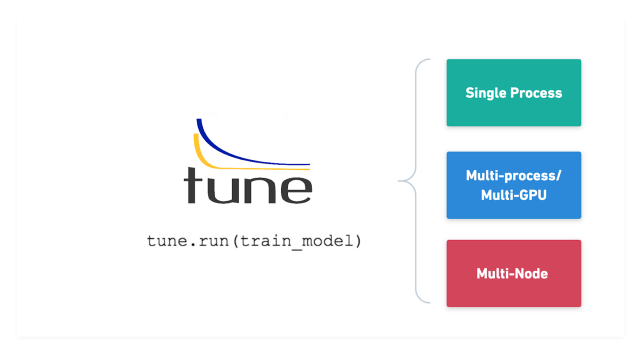
The process of finding the right combination of hyperparameters to maximize the model performanceRandom SearchGrid SearchEach iteration tries a combin
2022년 10월 13일
4.[Paper Review] Attention is all you need
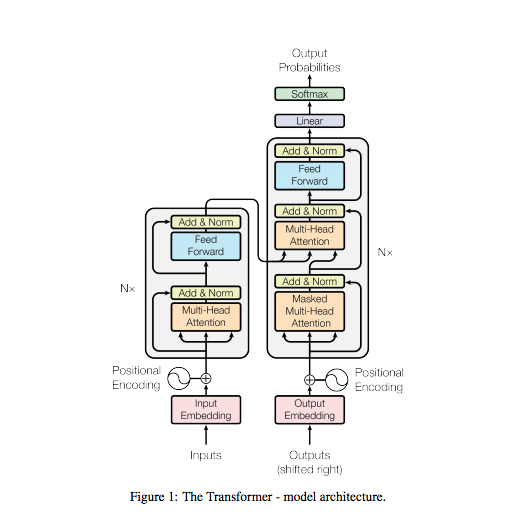
Before RNN LSTM : slow to train Can we parallelize sequential data? Transformers Input sequence can be transmitted **parallel ** No concept of t
2022년 11월 17일
5.[Docker] Let me like you, Docker : part 1

A python file("hw1.py") runs well on my laptop.But what if it does not on my friend's?➡ ModuleNotFoundError: No Module named 'xgboost'➡ The module isn
2022년 11월 28일