
자율주행의 3D segmentation을 위해 두 modality인 camera와 Lidar를 융합한 논문이다
Camera: scence에 대한 풍부한 정보를 가지고 있지만, object의 크기가 다양할 때, segment 성능이 낮아지고 3D segmentation 적용이 쉽지 않다.
Lidar: 3D semantic segmentation이 가능하지만, laser point들이 희소하기 때문에 object의 디테일이 떨어wu segmentation이 부정확하다는 문제가 있다.
Laser point가 희소한 이유? 센서로부터 등방성으로 퍼져나가기 때문에 멀리 갈수록 point들이 희소함
최근 Computer-vision의 트렌드는 multi-modal인 만큼 두 센서를 융합하여 3D semantic segmentation의 정확성과 강인함을 높이겠다는 논문이다.
3D semantic segmentation의 문제점?
저자는 Multi-modal segmentation이 3가지 문제점을 가지고 있다고 한다.
1) Heterogeneity between modalities
Lidar의 3D point cloud와 Camera의 scence는 기본적으로 균일하지 않다.
intra-modal feature extraction을 통해 이러한 비균일성을 해결할 수 있다고는 해도 joint optimization의 부족으로 인해 optimal한 feature가 나오지 않다.
2) Limited intersection on the field of view (FOV) between sensors.
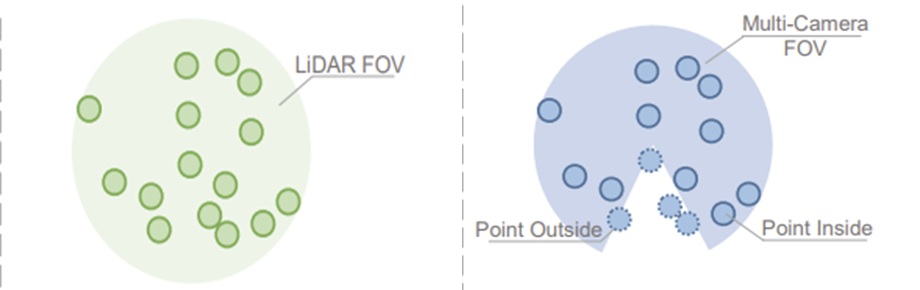
두 sensor 간에 FOV의 최대 교집합이 제한되어 있다. 그림에서 볼 수 있듯이, camera의 FOV가 제한되어 있다. 제한된 상황에서 multi-modal data을 통한 segmentation 성능은 시원치는 않을 것이다.
3) Multi-modal data augmentation
data augmentaion 기법은 주로 2D domain에 대해서만 다루고 있다.
point cloud를 projection해서 사용할 수 있다는 이야기인데... 이러면 point cloud에서 중요한 정보를 왜곡될 수 있다는 위험성이 있다.
한 마디로 3D point cloud에 대한 augmentation이 어렵다
How to slove it?
1) Jointly Optimize intra-modal extraction & inter-modal feature fusion
intra-modal (camera & Lidar)의 feature를 추출한 후, 다음과 같은 과정을 통해 inter-modal feature fusion을 진행한다.
- GF-Phase (Geometry-based Feature Fusion)
- Cross-modal Feature Completion
- SF-Phase (Semantic-based Feature Fusion)
2) GF-Phase를 위한 cross-modal 완성 및 semantic-based feature phase (SF-Phase) 제안
(1) cross-modal 완성
camera FOV outside 부분에 대한 feature를 예측하는 단계이다.
FOV inside point의 feature와 cross-modal supervision을 이용해 모델을 학습시킨다.
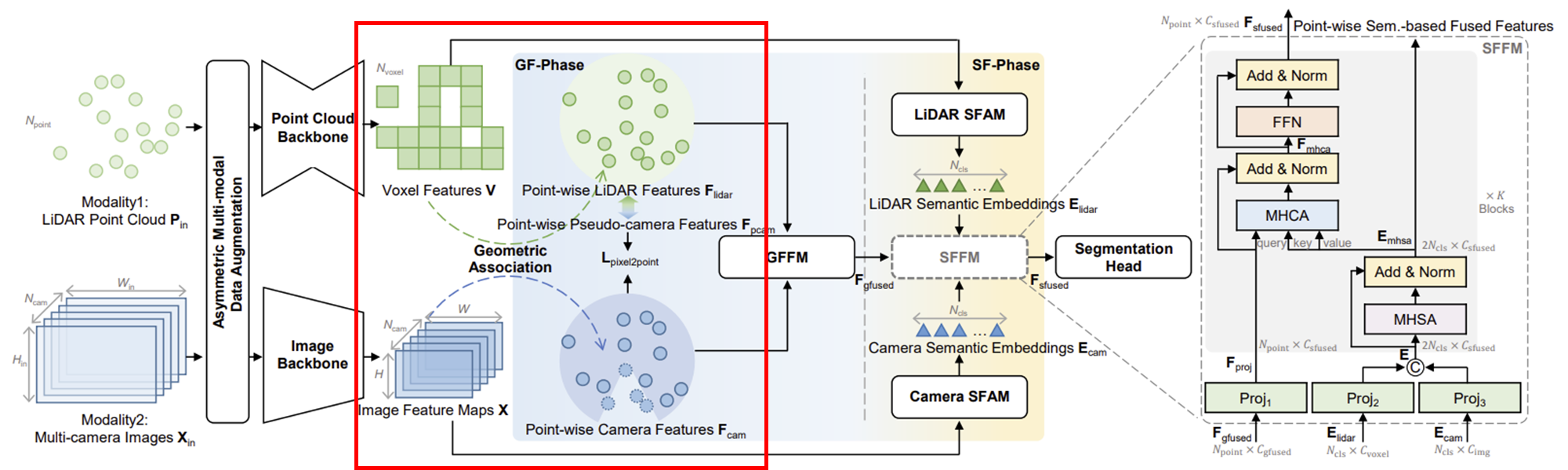
학습된 모델로 FOV 외부 포인트에 대한 가상의 카메라 특징(pseudo-camera features)을 예측하여 결측값을 완성한다.
cross-modal supervision?
서로 다른 모달리티(예: 이미지, 텍스트 등) 간의 상호 지도학습을 의미.
예를 들어, image-caption 모델에서:
1) image modality만 사용하면 시각 정보만 반영
2) Caption을 같이 사용하면 언어적 지식도 활용
3) 두 modality가 서로 지도학습을 하면서 상호보완을 함
(2) GF-Phase
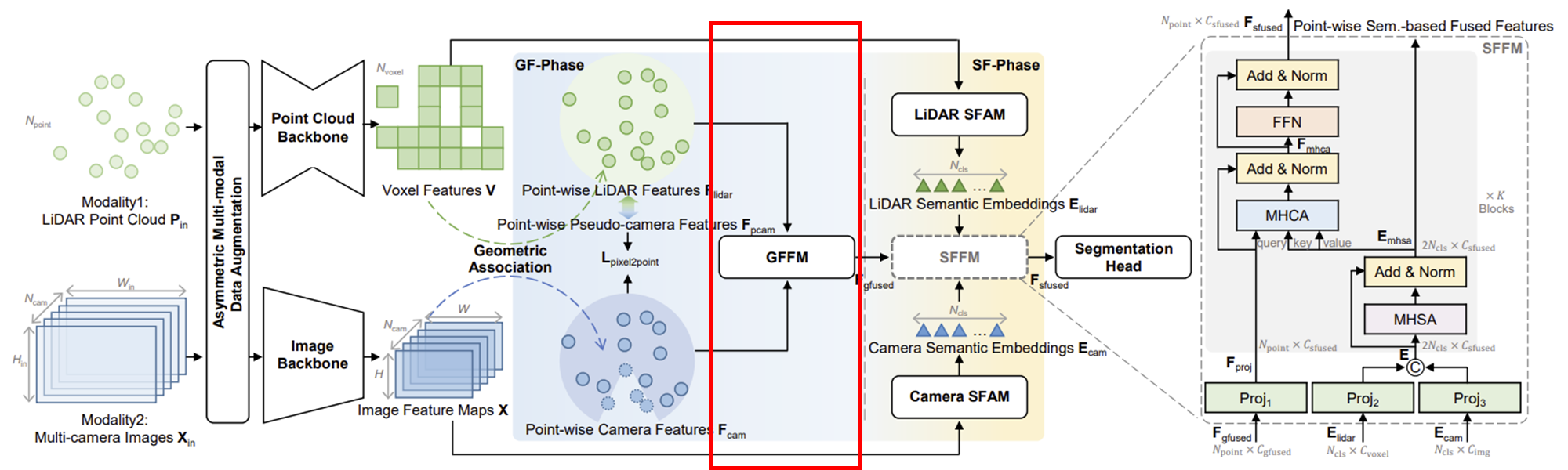
LiDAR feature과 카메라 feature을 Fully Connected Layer을 통해 동일한 차원의 feature으로 변환한다.
이후, concatenate하여 MLP를 통과시켜 geometry-based fusion feature을 생성한다.
Geometry-based Feature Fusion (GF-Phase)가 필요한 이유?:
1. 기하 정보 활용
- LiDAR point cloud는 3차원 공간 상에서 위치 정보를 포함하는데, GF-Phase에서는 이 기하 정보를 활용하여 feature들을 융합한다.
- Spatial Alignment 고려
- GF-Phase에서는 기하 정보를 바탕으로 LiDAR point와 camera pixel의 대략적으로 정렬할 수 있도록 한다.
- 이를 통해 fusion 시 발생할 수 있는 Spatial misalignment 문제를 완화할 수 있다.
- 보완적 특징 통합
- 다른 종류의 feature들을 기하 정보를 기반으로 융합하여 통합된 표현을 얻을 수 있다.
(3) SF-Phase
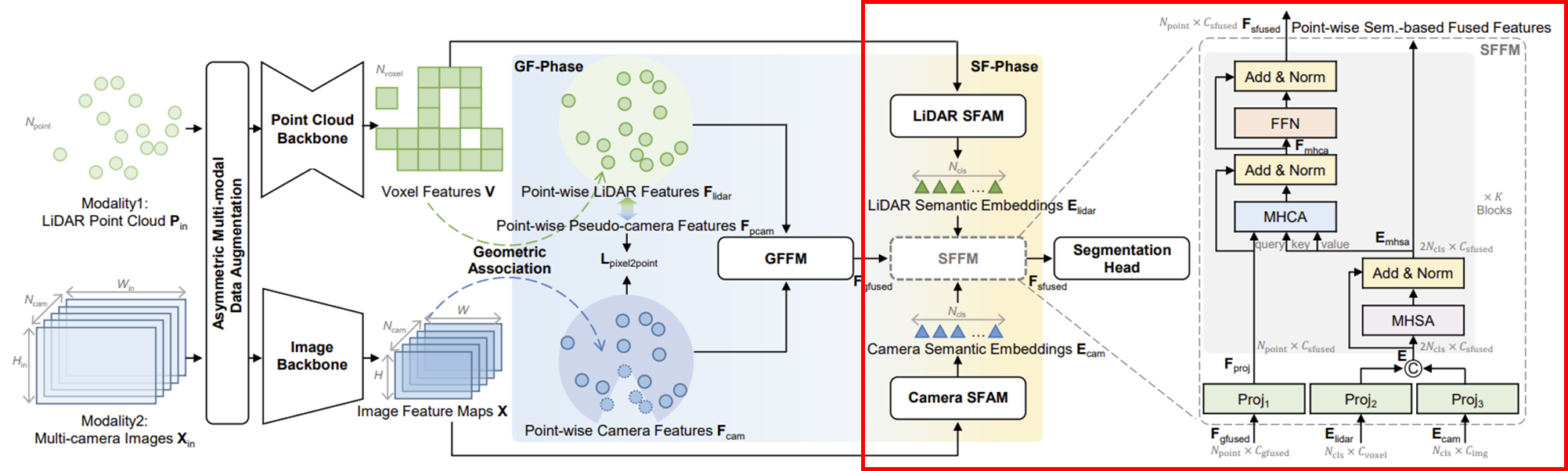
여기서 LIDAR SFAM과 Camera SFAM은 각각 sementic feature aggregate module이다.
간단하게 해당 모듈의 목적은 각각의 modality에서 나온 data로부터 각 category에 해당하는 semantic feature vector를 추출하는 것이다.
이후 두 modality에 대한 semantic feature vector를 SFAM을 input으로 넣음으로써, inter-modal feature fusion vector를 구할 수 있다.
3) Decomposed as the asymmetric transformation

- L-only: LiDAR data에만 회전, 평행이동, 스케일링 등의 변환 적용
- C-only: image에만 스케일링, 회전, 크롭, 색상변화, JPEG 압축 등의 변환 적용
- Symmetric: random flipping은 두 modality에 동일하게 적용되는 대칭 변환
이처럼 LiDAR와 이미지 각각에 독립적이고 비대칭적인 변환을 적용함으로써 보다 다양한 상황을 반영한 augmented 데이터를 생성한다.
개인적으로 느꼈던 2023 CVPR segmentation 트렌드 (계속 조사하고 있지만...ㅎ)
- 자율주행을 위한 Lidar를 이용한 multi-modal 연구가 활발하다.
- 주요 issue는 2D & 3D modality gap으로 인한 Lidar data performance degradation인 듯하다
- 주요 issue는 2D & 3D modality gap으로 인한 Lidar data performance degradation인 듯하다
- Computer-vision에 prompt질이 가능하도록 pre-trained model 연구를 성행하고 있다.
- CV에서도 few-shot 혹은 zero-shot learning을 위함이다.
- 그리고 pre-trained model에 관련된 연구에서 self-supervised learning에 대한 코멘트를 줄차게 들여놓는다.
- 순수 computer vision의 색깔은 많이 옅어진 느낌이 들었다. caption아니면 Lidar를 이용한 multi-modal 연구가 성행되고 있다.!
