Hallucination(환각, 허위 사실을 생성하는 것)은 LLM(Large Language Model)의 대표적인 단점으로 꼽히는 현상입니다. 이를 줄이고자 하는 연구는 계속되고 있으며, 그 중 Prompt를 이용해 모델 스스로 검증할 수 있게 하는 방법을 제안한 논문을 리뷰하고자 합니다. (Meta에서 2023년 9월 발표)
Introduction
LLM 모델은 파라미터 수가 증가할수록 성능이 증가하고 정확도가 올라갑니다. 그러나 모델은 틀렸더라도 "진짜처럼 보이는" 거짓 답변을 생성하려는 경향이 있고, 따라서 Hallucination 문제는 발생할 수밖에 없습니다. 특히 한 번에 여러 문장을 생성하고자 하는 longform task의 경우 hallucination 문제는 더욱 심각해집니다.
최근 언어모델 연구에서는 모델 스스로 reasoning을 하도록 하는 연구를 지속하고 있습니다. 그 연구의 연장선으로, 본 논문에서는 Chain-of-Verification(CoVe)라는 접근법을 제안합니다. CoVe 방식을 짧게 소개하자면, 모델에게 처음에는 응답 초안을 먼저 생성하도록 한 뒤, 응답에 대한 검증을 할 수 있는 검증 질문을 생성합니다. 응답 초안에 대한 검증 질문을 모델에게 던져서 이에 대한 검증답변을 얻고, 검증답변과 초기 답변이 일관성 있는지 확인하면서 개선된 최종 답변을 얻습니다.

또한, 검증 질문과 검증 답변을 한 개의 프롬프트로 한 번에 생성하도록 하는 것보다 각각을 독립적으로 진행했을 때 hallucination이 더 많이 개선된다는 것도 실험을 통해 증명했습니다. 즉, 각각의 검증 단계는 프롬프트 하나를 통해서가 아니라 독립적으로 이루어져야 한다는 것이지요. Experiment 세션에서는 CoVe를 list-based questions, closed book QA 그리고 longform text generation 세 가지 과제를 준 상태에서 성능 평가를 합니다.
Hallucination을 줄이는 3가지 방법
들어가기에 앞서, Hallucination을 줄이고자 하는 연구는 많이 진행되었고 진행되고 있습니다. 논문에서는 이러한 연구들을 세 가지로 분류시킵니다.
1. Training-time correction
학습을 하는 동안, 혹은 모델의 weight를 직접 조절하면서 hallucination이 발생할 확률을 줄이는 방법입니다. LLM에 강화학습을 적용하는 방식 (Instruct-GPT처럼) 이 이에 해당한다고 볼 수 있습니다.
2. Generation-time correction
위의 방식처럼 학습에 관여하는 것이 아닌, 기본 LLM 모델에게 초반에 스스로를 검증할 수 있는 과정을 수행하도록 지시하는 방법입니다. 예를 들면 토큰을 생성할 때 probability(토큰이 적절할 확률)를 계산하게 하거나, 답변에 대한 confidence score(신뢰도 점수)를 측정하게 하는 방법도 있습니다. 또한 두 개의 LLM을 두고, 한 LLM이 답변을 생성하면 나머지 LLM이 답변에 대한 평가를 하도록 하는 방법도 제안된 적이 있습니다. CoVe도 이 유형에 해당하지만, 두 개의 LLM이 토의하는 방식은 아니라고 논문에서는 강조합니다.
3. Via augmentation (tool-use)
외부 툴을 이용해 hallucination을 줄이고자 하는 방법으로, Retrieval-augmented generation이 대표적입니다.
그 외에도 흔히 사용되는 Chain-of-Thought(CoT), self-verification 등의 방법들이 예시로 등장합니다.
Chain-of-Verification (CoVe)
CoVe는 총 4가지 스텝으로 진행됩니다.
- Generation Baseline Response
- Plan Verifications
- Execute Verifications
- Generate Final Verified Response
각각에 대해 자세하게 설명하겠습니다.
Step 1. Baseline Response
질문에 대한 초기 답변을 생성하는 단계입니다. 일반적으로 LLM을 사용할 때는 이 단계에서 끝난다고 보면 되고, 특별히 더 설명할 건 없네요...
Step 2. Plan Verifications
Step 1에서 만들어진 초기 답변에 대해 검증을 할 수 있는 검증 질문을 생성하는 단계입니다. 예를 들어 Step 1에서 모델이 "멕시코-미국 전쟁(Mexican-American War)은 1846년부터 1848년까지 미국과 멕시코 사이에 벌어진 무력 충돌입니다"라고 답변을 했다면, 이 초기 답변이 정확한지 확인하기 위한 검증 질문인 "멕시코-미국 전쟁은 언제 시작되고 끝났나요?"를 만드는 것입니다. 논문에서는 이 단계에서 초기답변-검증질문 쌍으로 구성된 몇 개의 예시를 주는 few-shot prompt를 짜서 진행했다고 합니다. 물론 Zero-shot으로도 가능은 합니다.
Step 3. Execute Verifications
Step 2에서 만든 검증 질문들을 토대로 검증 답변을 생성하는 단계입니다. 예를 들어 Step 2의 예시에서 만든 검증 질문인 "멕시코-미국 전쟁은 언제 시작되고 끝났나요?"에 대해 "멕시코-미국 전쟁은 1846년에 시작되고 1848년에 끝났습니다."라는 검증 답변을 생성하는 것입니다. 이 과정에서 retrieval-augmentation을 사용할 수도 있겠지만, 본 논문에서는 이를 사용하지 않고 오로지 LLM만 적용했다고 합니다.
Step 2와 Step 3, 즉 검증 질문을 생성하고 검증 답변을 하는 과정도 논문에서는 아래와 같이 4가지 방법으로 나누어 실험을 진행했습니다.
- Joint
- Step 2와 Step 3를 하나의 prompt로 진행하는 방법입니다. 즉, 초기 질문과 초기 답변이 주어진 상황에서 검증 질문을 만들고 이에 대한 검증 답변을 하는 과정을 하나의 prompt로 한 번에 진행하는 것입니다.
- 이 방식은 분명한 단점이 있습니다. Prompt가 한 번에 들어가기 때문에 검증 답변을 생성하는 과정에서 초기 답변을 참고할 수밖에 없고, 이로 인해 잘못된 답변을 반복해서 생성할 수 있다는 것입니다.
- 예를 들어, LLM이 "도쿄는 대한민국의 수도이다"라는 잘못된 초기 답변을 했다고 생각해봅시다. 이에 대한 검증질문으로 "대한민국의 수도는 어디입니까?"를 만들었을 때, 검증 답변을 생성하는 과정에서 초기 답변의 정보를 확인할 수밖에 없고, 초기 답변을 토대로 다시 "대한민국의 수도는 도쿄입니다"라는 잘못된 검증 답변을 생성할 수도 있다는 것입니다.
- 2-Step
- Joint 방식의 단점을 극복하고자 하는 방법으로, Step 2와 Step 3를 하나의 prompt로 한 번에 생성하지 않고 별도의 prompt를 통해 생성하는 방법입니다.
- 즉, 초기 답변을 보고 검증 질문을 생성하는 prompt를 쓰고, 그 다음에 검증 질문을 보고 검증 답변을 생성하는 또 다른 prompt를 사용하는 방식입니다.
- 이 방식에서는 검증 답변을 생성할 때 초기 답변을 참고할 수 없게 되고, 초기 답변으로 인한 hallucination이 발생하지 않게 됩니다.
- Factored
- 2-Step에서는 검증 질문들을 모아서 하나의 prompt로 만들고, 검증답변들을 한 번에 생성하게 합니다.
- Factored는 더 나아가서 각각의 검증질문들로 대해 독립적인 prompt들을 구성하고, 각각의 prompt를 하나하나 사용해서 검증 답변들을 생성하도록 하는 방식입니다.
- 즉, 먼저 검증 질문들을 쪼개고 (아마 마침표 단위로), 각각의 검증 질문들로 개별적인 prompt를 써서 검증 답변을 하나하나 생성하도록 하는 것입니다.
- 이 방식은 초기 답변을 넘어서 여러 검증답변들끼리도 서로를 참고하지 못하게 하는 방법입니다. 단점이라면 computationally expensive하다는 것인데, 이 작업 자체가 배치 단위로 돌릴 수 있기 때문에 추론 속도 상으로는 문제가 없다고 합니다.
- Factor + Revise
- Factored 방식에서 더 나아가 cross-check할 수 있도록 하는 방법입니다. 즉, 초기 답변과 검증 질문, 그리고 검증 답변 간의 불일치를 검증하는 방법입니다.
- 예를 들어 초기 답변이 "1845년 미국이 텍사스를 합병한 이후..."라고 가정합시다. 이 때 검증질문으로 "텍사스는 미국에서 언제 분리 독립했나요?"가 나옵니다. 즉 검증질문 자체가 잘못된 상황이죠? 당연히 검증 답변은 초기 답변과 다른 연도인 "1836년"을 제시할 것입니다. 이렇게 검증 과정에서 불일치가 있는지를 확인하는 과정이 추가되는 방식이라고 보면 됩니다.
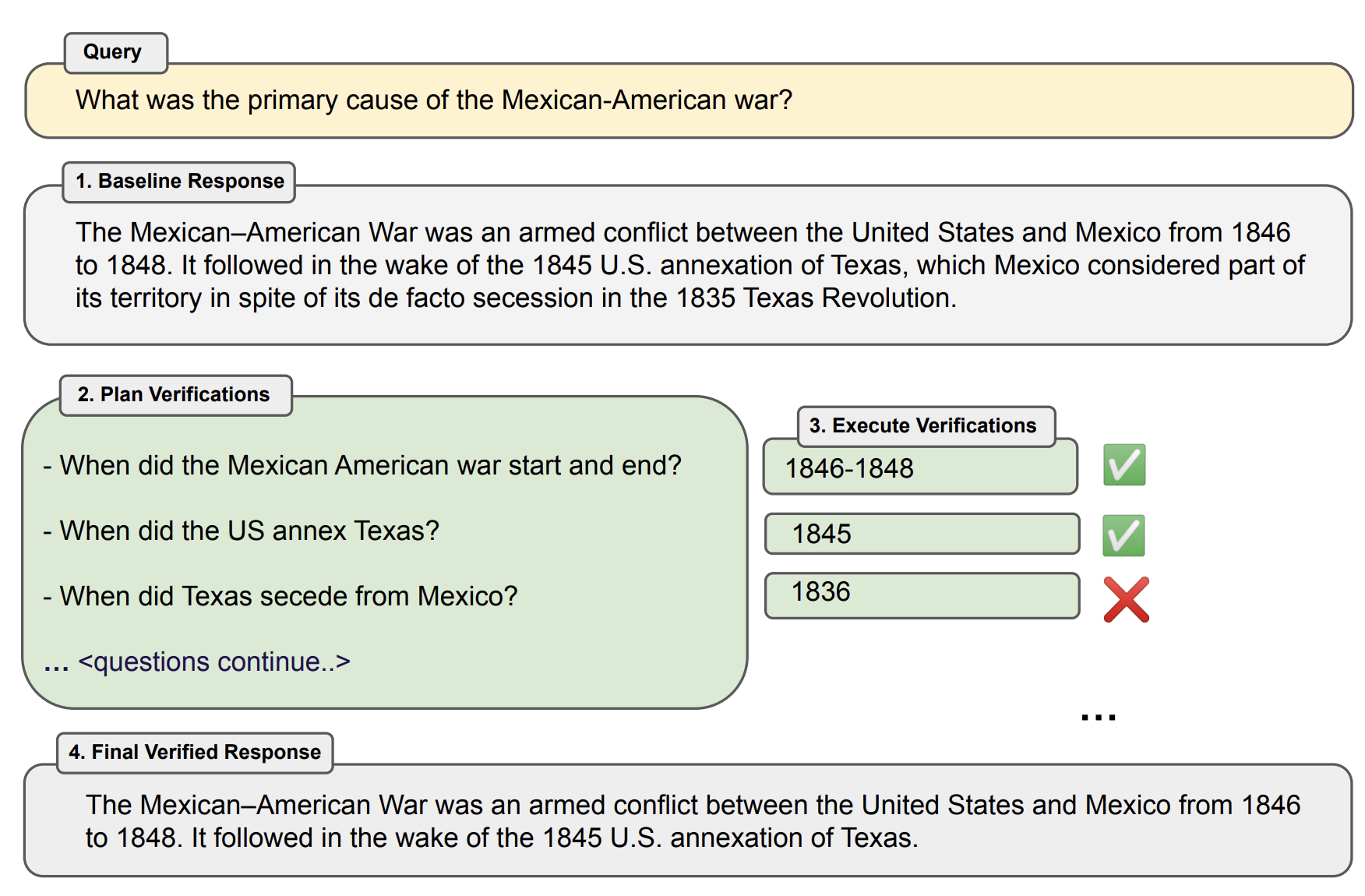
Step 4. Final Verified Response
검증 결과를 바탕으로 최종 답변을 생성하는 단계입니다. 이 때 few-shot prompt를 이용하는데, 초기 답변 + 검증 질문 + 검증 답변을 보고 개선된 답변을 생성하는 예시를 여러 개 주는 prompt를 사용합니다.
Experiments
Tasks
총 4가지 데이터로 Task를 구성해서 실험을 진행했습니다.
- Wikidata
- Entity가 빠져있는 기본 질문 틀을 만들고, 질문 틀에 entity를 채워서 56개의 질문을 생성한 데이터입니다. (2024.11.08 내용수정)
- 예를 들어 "{City}에서 태어난 {Profession}들은 누가 있어?"라는 질문 틀을 만들고, 이를 토대로 "보스턴에서 태어난 정치인들은 누가 있어?"라는 질문을 만드는 방식입니다.
- 평가 지표로는 Precision을 사용했습니다.
- Wiki Category List
- QUEST라는 Wikipedia Category lists로부터 만든 데이터셋을 사용합니다.
- 질문은 카테고리 앞에 "Name some (몇 개 말해봐)"을 붙여서 만듭니다. "멕시칸 호러 영화 몇 개 말해봐"와 같은 식이죠.
- 8개 이상의 답변을 가지고 있는 55개의 테스트 질문을 사용했으며, 평가 지표로는 마찬가지로 Precision을 사용했습니다.
- MultiSpanQA
- 여러 개의 독립적인 답변을 갖고 있는 질문들로 구성된 질문셋으로, CoVe는 retrieval-augmentation을 사용하지 않고 LLM만을 이용해 검증을 하기 때문에 Closed-book setting을 가정합니다.
- 답변의 길이가 짧은 418개의 질문을 사용합니다.
- Longform Generation of Biographies
- Biography(전기)를 생성하는 능력을 평가하기 위한 데이터셋입니다.
- "Tell me a bio of <entity>"의 형태로 질문이 구성되어 있습니다.
- 평가를 할 때는 FACTSCORE metric을 이용합니다. 이 방식은 retrieval-augmented language model을 이용해 답변의 정확도를 체크하는 방식인데, Llama + Retrieval + NP가 합쳐진 방식이라고 보면 됩니다.
Baselines
평가를 위한 baseline model로는 Llama 65B 모델을 사용합니다. Instruction fine-tuned되지 않은 상태로 사용하며 (즉, baseline으로는 Llama2를 사용하지 않습니다) few-shot examples만 몇 가지 주고 성능을 측정합니다.
위의 baseline model과 대비하여 CoVe 적용 시의 성능을 평가하기 위해 CoVe 역시 Llama 65B 모델을 기본으로 합니다. 즉 Llama 65B에 앞서 언급한 자체검증과정을 추가하는 것이죠. 검증 답변을 생성하는 과정에서는 joint, 2-step, factored와 같은 변화를 주면서 성능측정을 진행합니다.
추가로 Instruction fine-tuned된 Llama2와도 비교를 진행합니다. Llama2는 zero-shot으로 평가를 하며, Innstruction fine-tuned된 모델의 특성상 답변을 너무 많이 생성하는 경향이 있기 때문에 "list only the answers separated by comma"와 같은 문구도 프롬프트에 추가시키고, 후처리를 위해 NER 레이어도 쌓았다고 합니다. 그럼에도 성능이 좋지는 않아서 few-shot prompt를 사용했다고도 합니다.
그 외에도 longform generation task에 대한 성능 비교를 위해 InstructGPT, ChatGPT, PerplexityAI도 사용해 비교실험을 했습니다.
Results
평가를 통해 얻고자 한 결론은 크게 아래의 두 가지입니다.
- CoVe가 LLM으로부터 발생한 hallucination을 얼마나 줄일 수 있는지
- 정확한 답변의 양을 최대한 줄이지 않으면서 부정확한 답변을 필터링해낼 수 있는지
그 결과 아래와 같은 결론들을 얻었습니다.
-
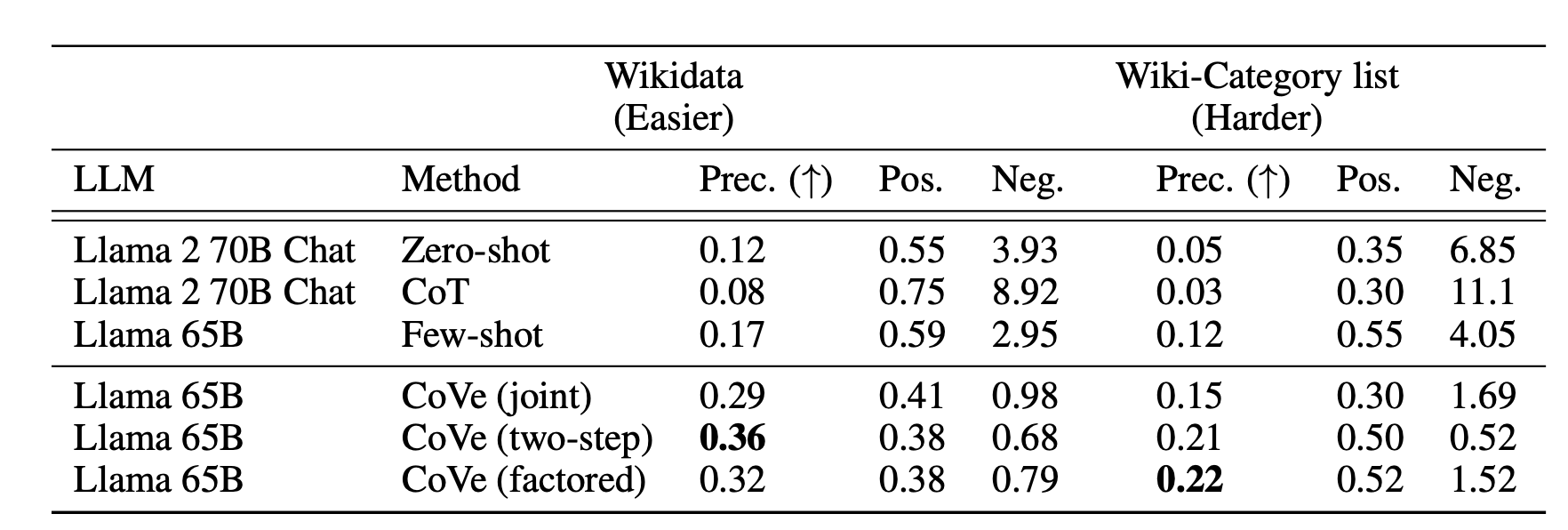
CoVe는 List-based answer tasks에서 precision을 올렸습니다.
-
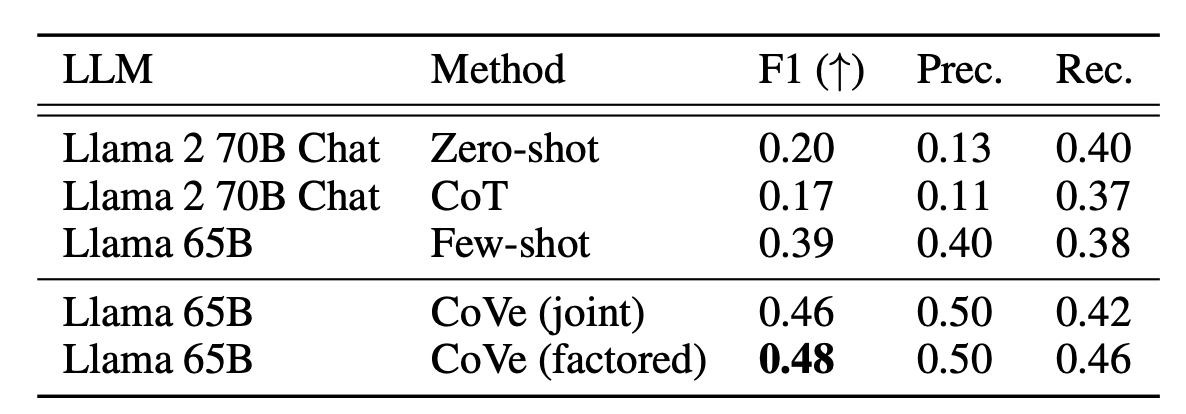
CoVe는 closed book QA에서 역시 성능을 올렸습니다.
-
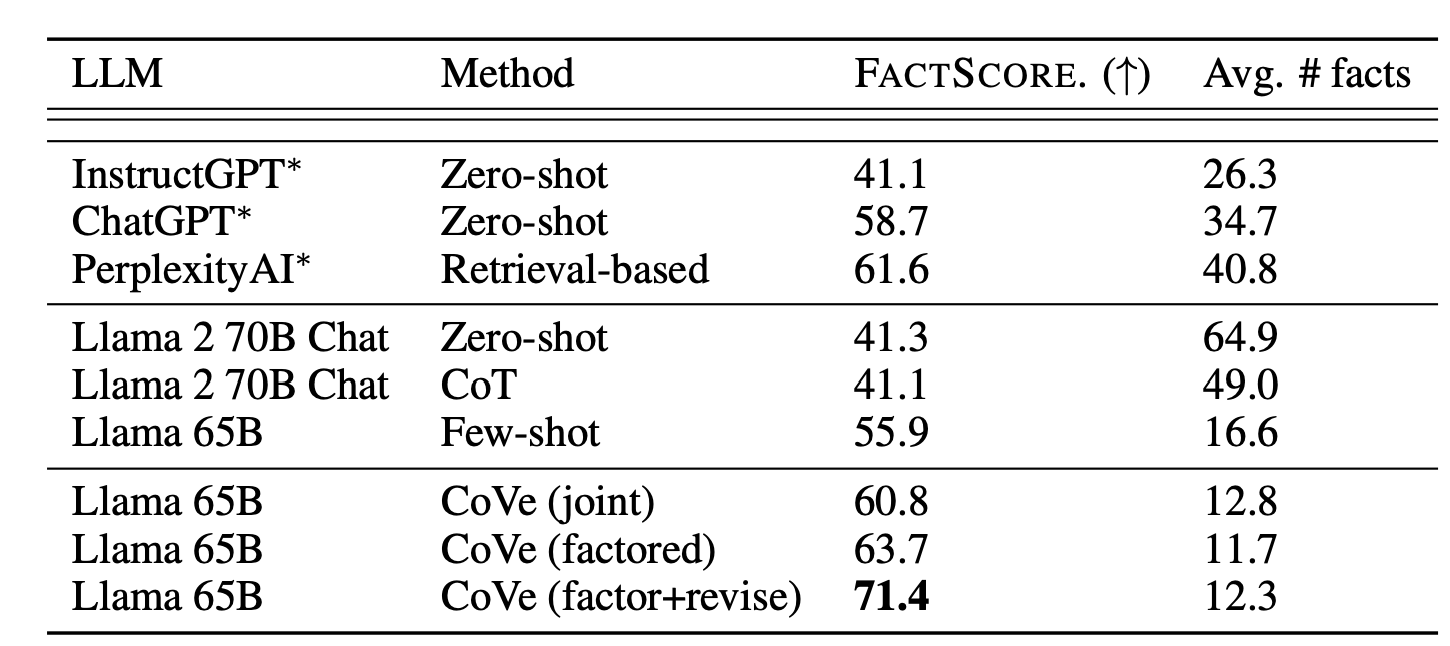
CoVe는 longform generation에서 역시 성능을 올렸습니다.
-
Instruction-tuning과 CoT를 동시에 진행해도 hallucination을 줄일 수는 없었습니다.
- Llama에 Instruction-tuning을 적용한 Llama2에 CoT(Chain-of-Thought)를 적용하더라도 hallucination을 줄이지는 못했습니다. 심지어는 few-shot시킨 baseline Llama가 Llama2보다도 성능이 좋았다고 합니다. 즉, Instruction-tuning의 효과보다 zero-shot에서 few-shot을 통해 예시를 준 경우가 오히려 hallucination 줄이기에 도움이 되었다는 것이지요.
-
Factored CoVe, 2-step CoVe가 성능을 올렸습니다.
- 검증 질문을 하고 검증 답변을 생성하는 과정에서 joint 방식보다 2-step, factored 방식이 성능이 좋았다고 합니다. 특히 2-step은 Wikidata에서, factored는 Wiki-Category 데이터에서 성능이 좋았습니다.
-
추가적인 검증 과정이 hallucination을 줄였습니다.
- longform generation task에서는 추가로 factor-revised 방식도 평가를 진행했는데, 이 방식이 더 성능이 좋았다고 합니다.
-
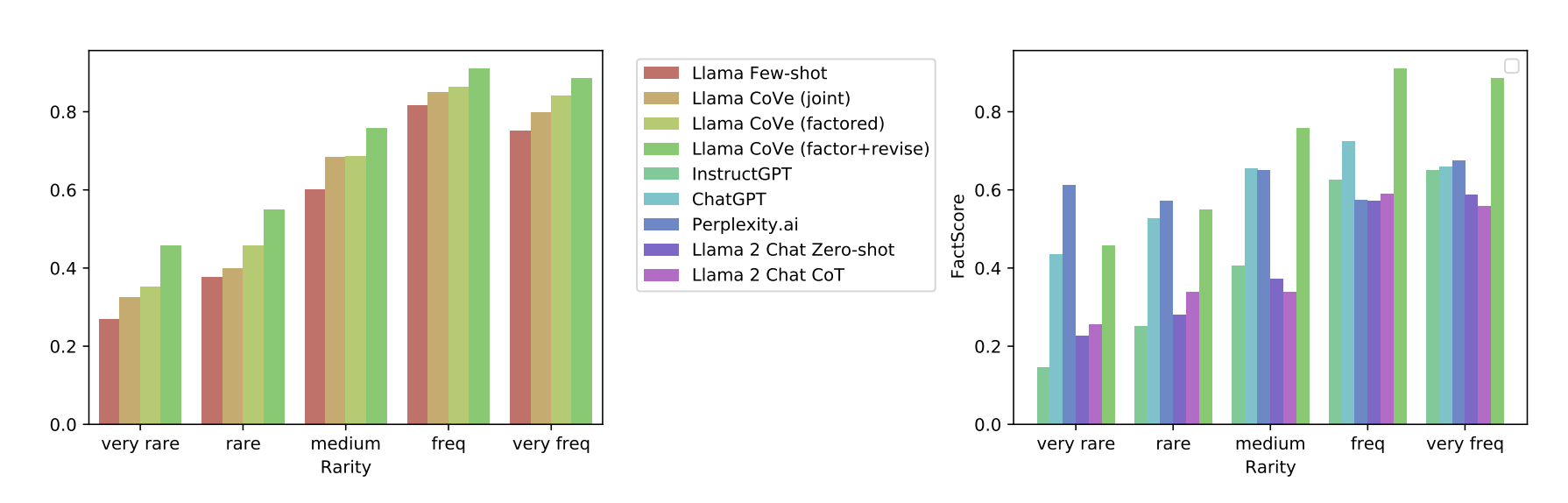
CoVe-based Llama가 InstructGPT, ChatGPT, PerplexityAI의 성능을 넘었습니다.
- 심지어는 PerplexityAI는 retrieval-augmentation을 통해 팩트체크를 하는 모델임에도 더 좋은 성능이 나왔습니다. 단, rare한 질문에 대해서는 여전히 PerplexityAI의 성능이 더 좋았습니다.
-
Shortform verification questions들이 longform query에 비해 정확하게 답변되었습니다.
- 대신 longform question도 쪼개서 질문하면 성능이 좋았습니다.
-
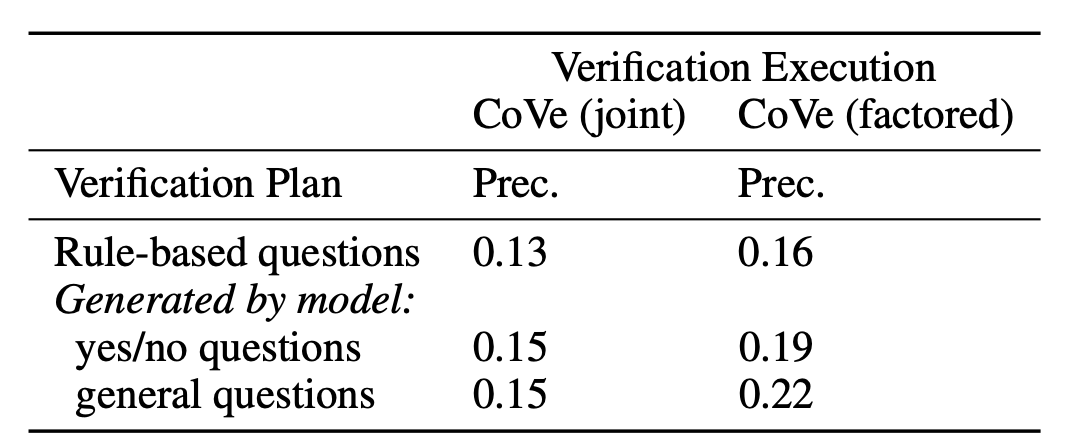
LLM으로 만들어진 검증 질문이 heuristic하게 직접 만든 검증 질문보다 좋은 성능을 가져왔습니다.
-
Open verification question이 Yes/no-based question보다 성능이 좋았습니다.
Conclusion & Limitations
CoVe는 단순한 질문들에 대해서 보다 정확한 답변을 할 수 있게 만들었습니다. 검증 과정에서 이전 답변을 참고하지 않도록 프롬프트를 분리시킬수록 정확도는 더 올라갔고, 기존의 언어모델들에 비해서 성능 향상 (Precision 저하)을 이루었습니다.
대신 여전히 한계점들은 남아 있습니다. 첫 번째로, Hallucination을 줄이기는 했으나 완전히 없애지는 못했다는 것입니다. 두 번째로, 논문에서 평가를 정답이 명확한 데이터를 이용해서 진행했는데, Hallucination은 정답이 명확하지 않은 경우에도 발생할 수 있다는 것입니다. 세 번째로, 별도의 검증 과정을 추가시키면서 computational expense는 어쩔 수 없이 증가했습니다. 마지막으로, CoVe는 모델 스스로 정확히 검증을 할 수 있다는 가정 하에 검증을 진행하는데, 보다 더 정확한 검증을 위해서는 외부 툴이 필요하다는 것입니다. 따라서 논문에서도 추후 연구로 retrieval-augmentation과 같은 tool-use 방식을 검증 과정에 적용시키는 것도 가능하다고 언급했습니다.
실제로 현업에서 LLM을 적용시킬 때 항상 문제가 되는 것이 Hallucination 문제입니다. 룰 베이스드 방식에 비해 예측하기도 힘들고, 조절하기도 힘들기 때문이죠. 그런 관점에서 이 논문처럼 Hallucination을 줄이고자 하는 연구는 관심이 가게 됩니다. 비록 이 논문에서도 Hallucination을 온전히 없애지는 못했는데, Hallucination 감소가 인간 수준까지 많이 이루어진다면 언젠가는 현업에서도 더 적극적으로 LLM을 사용하는 날이 오지 않을지 생각해봅니다.

Wikidata 설명 부분에 오류가 있는 거 같습니다.
논문 4.1.1을 읽어보면
"Who are some [Profession]s who were born in [City]?" 라는 질문 틀을 활용하여
질문 틀에 entity를 채워서 56개의 질문을 생성한 거 아닐까요?
제가 해석하기엔 그런데, 한 번 확인해주시면 감사하겠습니다.
이 글 덕분에 해당 논문 공부하는 데 많은 도움 받고 있습니다 🙏