
논문 제목 : Going deeper with convolutions
논문 링크 : https://arxiv.org/abs/1409.4842
Introduction
기존과 데이터셋이 달라지지는 않았지만 성능이 향상된 이유는 새로운 아이디어, 알고리즘, 발전된 네트워크 아키텍쳐 덕분이다.
또 전력과 메모리 사용량 역시 중요한 부분이다.
실용적 활용을 위해 15억 번의 계산량을 넘지 않도록 했다.
이번 논문에서는 efficient deep neural network architecture에 집중했다.
여기서 "deep"이 2가지 의미로 사용되었다.
1) 네트워크 아키텍쳐 자체가 "깊어"지는 것
2) Inception module의 도입(더 deep해진 수준)
Related Work
LeNet-5를 시작으로 CNN은 일반적인 구조(Convolution layer가 쌓여있고, 그 뒤에 FC layer가 따라오는)가 널리 퍼졌다.
요즘 트렌드는 대용량 데이터에 대해 Dropout과 layer 수 증가이다.
Network-in-Network는 NN의 representation-power를 증가시키는 방법이다.
추가적 1x1 convolutional layer(+ ReLU)를 넣음으로써 현재 CNN에 pipeline을 만들어준다.
이 논문에서 1x1 convolutional layer는 2가지 목적이 있다.
1) 차원축소로 병목현상 제거
2) 네트워크 사이즈 제한
1)에 대한 설명은 아래 링크를 참고하자.
쉽게 말해 parameter 수가 줄어듦 -> 계산 감소 -> 병목현상 제거(걸림 x)
https://phil-baek.tistory.com/entry/3-GoogLeNet-Going-deeper-with-convolutions-논문-리뷰
현재 주도하는 object detection 은 R-CNN이다(새삼 옛날 논문..).
이는 object detection을 2개의 subproblem으로 줄여준다.
1) object 어디에 있는지
2) 그 object가 뭔지
우리는 이와 유사한 pipeline을 detection에 채택했다.
그러나 몇 가지 enhancement도 추가했다.
Motivation and High Level Consideration
성능을 높이는 가장 단순한 방법은 크기를 키우는 것이다.
크기는 1)깊이, 2)너비 를 늘려 키울 수 있다.
라벨링된 데이터가 많다면 가장 안전하고 확실한 방법이다.
다만, 단점이 2개 있다.
1) 큰 모델 = 많은 수의 파라미터 -> 오버피팅의 위험(특히 training set이 한정되면)
이는 병목현상의 주 원인이다.
좋은 퀄리티의 데이터 셋을 만드는것은 어렵고 비싸다(잘게 쪼개진 카테고리에서는 더더욱).
2) 소비되는 컴퓨팅 자원 증가
예산이 제한되어있어 효율적 컴퓨팅 자원의 분배가 선호된다.
이를 해결하는 근본적 방법은 convolution이더라도 FC(Fully connected)를 sparsely connected architecture로 바꾸는 것이다.
이는 생물학 시스템 모방 + Arora의 논문에서 나온 확고한 이론적 토대를 기반으로 한다.
- Arora 논문의 핵심 결과는 이렇다.
만일 데이터 셋의 확률 분포가 크고, very sparse한 DNN으로 나타내어 진다면,
최적의 네트워크 위상은 계층을 쌓을 때 마지막 계층의 활성화 함수의 상관관계 통계와 상관관계가 높은 output을 가진 neuron을 clustring함으로써 만들 수 있다.
이 사실은 Hebbian 법칙과도 일치한다 : 잘 맞는 neuron은 연결되어 있다 .
오늘날의 컴퓨팅 인프라는 non-uniform, sparse data 구조 연산에 매우 비효율적이다.
Dense 계산은 발전했지만(빠른 연산 시스템, 하드웨어), Sparse는 발전이 미미하다.
Sparse 연산을 위해 ConvNet들이 sparse connection을 시도했지만, 최적화된 병렬 연산을 위해 다시 fully connection으로 회귀했다.
중간 방식은 없을까? (sparsity는 가지되 현재 연산 시스템을 활용할 수 있는 것)
문헌에서 제시한 방법은 sparse matrices를 clustering해서 상대적으로 dense submatrices로 만드는 것이다.
Architecture Details
(이 부분은 다소 오번역이 있을 수 있습니다)
Inception 구조의 메인 아이디어는 다음과 같다.
1. 어떻게 최적의 local sparse 구조가 근사되고
2. 이를 쉽게 이용가능한 dense component로 구성
우리가 찾을 것은 최적의 local 구조를 찾아 이를 공간적으로 반복하는 것이다.
Arora가 제안하듯, layer-by-layer 만들기는 먼저 이전 단계 layer의 상관관계 통계를 본 뒤, 높은 상관관계끼리 cluster하는 것이다.
즉 이 cluster는 다음 layer의 unit을 만들고, 이전 layer의 unit과 연결된다.
Input에 가까운 layer일수록 상관관계된 unit들이 local region에 집중되어 있다.
찾으려는 물체 특징이 전체의 일부에 집중되어있기 때문이다.
(쉽게 생각하면 처음에는 input 이미지 그대로 -> 아직 사이즈 줄어들지 않아 local적으로 분포되어있음)
즉 1x1 convolution으로도 커버 가능하다.
그러나 물체의 특징이 별로 없는 곳(공간적으로 띄엄띄엄 분포된)에서는 clustering되는 unit이 줄어들 것이다.
따라서 이를 막기 위해 3x3, 5x5의 filter도 추가한다.
(patch alignment issue : 짝수 너비의 필터 중심을 어디로 할지 고민하는 문제, 이를 막기 위해 홀수 너비로 설정)
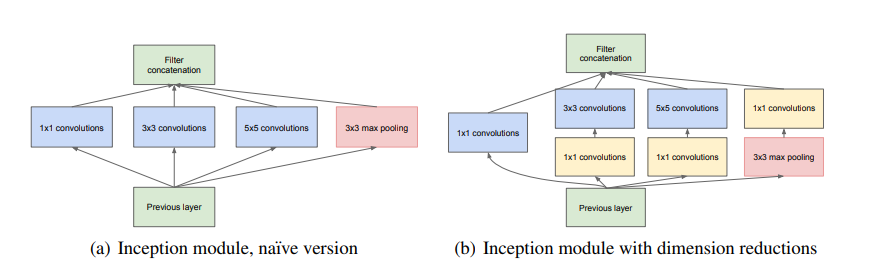
Pooling이 최근 좋은 성과를 내어 parallel pooling path도 추가했다.
더 높은 layer(output에 가까운)로 갈수록 공간적 집중도도 줄어들 것이기에 3x3, 5x5 convolution의 비중이 높아져야할 것이다.
그러나 이 naive form에는 문제가 있다.
5x5 convolution은 상당히 비싸다(=컴퓨팅 자원이 많이 든다).
거기다가 pooling하고 이 결과들을 합쳐서 다음에 전달..? 끔찍하다.
물론 sparse structure의 의도는 맞으나, 너무나 비효율적으로 동작한다.
그래서 등장한 것이 바로 1x1 convolution 추가다.
낮은 차원의 embedding도 꽤 많은 정보를 담기에 차원 축소는 할만한 가치가 있다.
1x1 convolution은 차원 축소를 해주기에 비싼 3x3, 5x5 convolution 이전에 쓰인다.
일반적으로 Inception network는 위의 모듈이 겹겹이 쌓여있고, 때때로 max-pooling layer가 쓰인다.
Max-pooling은 stride 2를 써서 grid를 반으로 줄이는 역할을 했다.
필수는 아니지만, 기술적 문제 등등..으로 인해 Inception module은 오직 high layer에서만 쓰고,
low layer에서는 전통적 convolution 구조를 따랐다.
이 구조의 장점은
1) 차원 축소를 통해 컴퓨팅 복잡도를 확 늘리지 않으면서 각 stage당 unit을 늘릴 수 있다.
2) 다양한 scale로 처리한 feature를 모아 처리한다는 점에서 직관과도 일치한다.
+) 대체 왜 inception module이 sparse 구조를 만드는지 이해가 잘 안되어서..
열심히 구글링한 결과 꽤 괜찮은 설명을 찾았다.
또한, 인셉션 모듈이 서로 다른 필터를 통한 연산결과들의 합을 output image로 추출하는 데에도 명확한 이유가 존재합니다. 바로 컴퓨터의 Infrastructure에 따른 결과입니다.
앞서, 당시의 CNN이 정확도를 높이기 위해 Dropout을 사용하고 있다고 말씀드렸습니다. 이는 분명히 에러를 낮추는 데 탁월한 효과를 보여주지만, 리소스의 사용 면에서 효율적이라고 보기는 어렵습니다. 컴퓨터의 연산장치는 non-uniform한 연산을 처리하는데 취약하기 때문입니다. 실제로, 컴퓨터 연산(CPU,GPU 등)은 dense한 연산을 처리하는 데 최적화되어 있습니다.
문제는 이것입니다. 리소스 사용면을 충족하고자 하면 dense한 네트워크를 구성해야 하지만, 이는 처음에 말씀드렸듯 오버피팅의 문제점을 내포합니다. Dropout과 같은 sparse한 연산과정을 도입하고자 하면, 정확도 면에서는 이득을 보게 되지만 리소스 사용이 비효율적인 면을 띠게 될 겁니다.
GoogLeNet에서 낸 결론은, 전체적인 구조 면에서는 Sparse한 구조를 갖되 실제 연산과정은 dense한 과정을 거치도록 하자는 것이었습니다. 각 필터들이 분리된 연산과정을 거친 후 합산되는 과정엔 이러한 목적을 담고 있습니다.
출처 : https://poddeeplearning.readthedocs.io/ko/latest/CNN/GoogLeNet/
즉 내가 이해한 바는 이렇다.
Dropout과 같은 기존 방식 : dense 구조를 sparse하게 연산
GoogLeNet : sparse 구조를 dense하게 연산
Reason : GoogLeNet은 convolution이 연속되어 연산되어 dense하지만, 여러 filter를 사용하여 다양한 feature들을 모두 사용한다. 즉 sparse한 구조를 띄고 있다.
참고 : GoogLeNet도 Dropout 썼다.
(1000% 이해는 아니지만 대략 감이 잡힌다.
이 부분이 도무지 이해가 안되어 계속...찾아봤다 ㅋㅋ..
그냥 각 구조에서 연산을 따로 하니까 sparse하게 한다고 생각하면 될듯...
어련히 넘어가고 싶은데 성격상 찜찜해서 못 넘어가겠다... 겨우 pass)
GoogLeNet
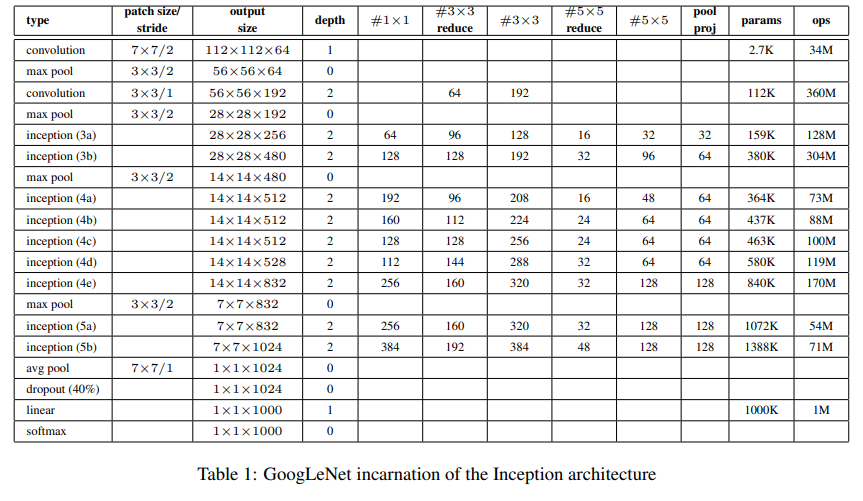
팀 이름이 GoogLeNet인 이유는 LeNet으로부터 따왔기 때문이다.
대회 출품 시에는 7개를 앙상블해서 제작했다.
그 중 6개는 Table 1과 동일한 위상을 가지고 있다(다만 sampling 방법이 다르다).
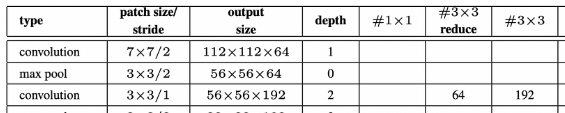
전반적인 architecture는 Table 1을 참고하자.
눈여겨봐야할 부분이 몇 가지 있다.
- 모든 convolution(Inception module 내부에도)에는 ReLU가 적용되었다.
- Receptive field의 size는 224x224(RGB)이다.
- #3x3 reduce, #5x5 reduce는 convolution 이전에 reduction으로 사용된 1x1 filter의 수이다
- pool-proj은 max-pooling 이후 1x1 filter의 수이다
- 모든 reduction/projection layer는 ReLU를 사용했다
FC layer에서 average pooling으로 바꾸면 0.6%의 top-1 accuracy 발전이 보인다.
Dropout의 사용도 FC layer가 없어졌음에도 여전히 중요하게 남아있다.
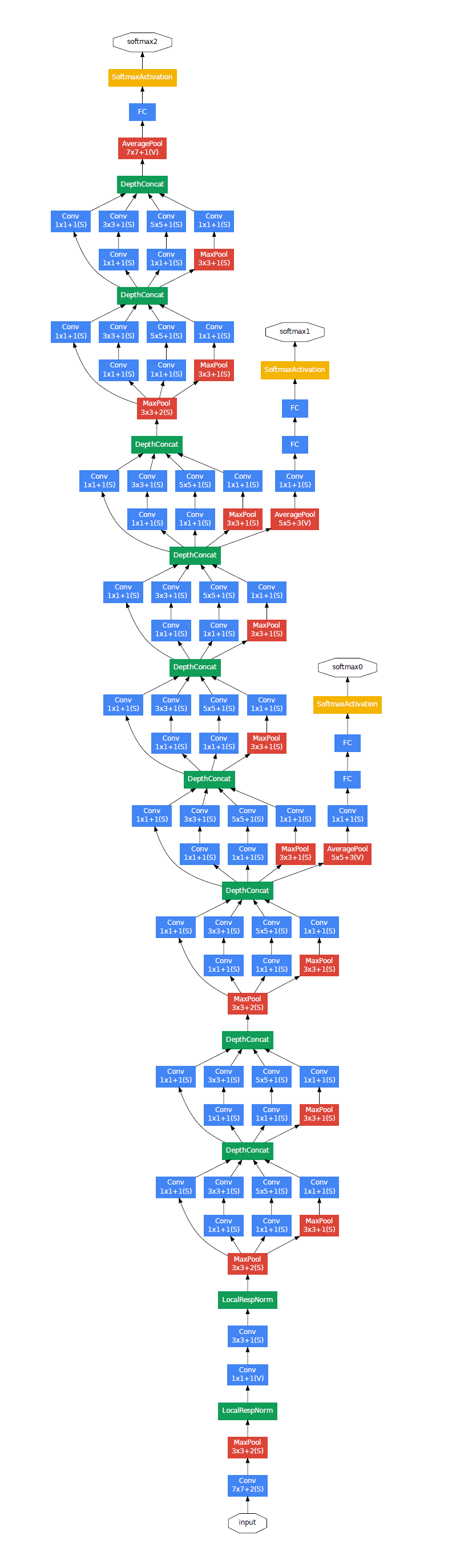
한 가지 문제는 network가 깊어서 gradient propagate가 잘 될까라는 것이었다.
이를 해결하기 위해 중간 구조에 auxiliary classifier를 달았다.
이유 : 상대적으로 얕은 network도 강력한 성능을 냈다
-> 그렇다면 중간에 feature도 구체적 특징을 지닐 것이다
-> 중간에 classifier를 달아서 보조로 쓰자
Auxiliary classifier의 loss를 0.3 weighted 해서 total loss에 더했다.
전체 구조는 다음과 같다.
- Average pooling layer(5x5 filter, stride 3)
- 1x1 convolution(128 filters) with ReLU
- FC layer(1024 units) with ReLU
- Dropout layer(0.7)
- Linear layer with softmax loss(classifier, 1000 classes)
Training Methodology
네트워크는 DistBelief 분산 ML system을 사용해서, 적절한 모델양과 데이터 병렬화를 통해 훈련했다.
CPU 기반임에도 대략 1주 이내 훈련 가능했다, 다만 유일한 제한사항은 메모리 사용량이었다.
구체적 훈련 방법은 다음과 같다.
1. 비동기 확률적 경사 하강법(0.9 momentum)
2. 고정된 learning rate(8 epoch마다 4%씩 감소)
3. Polyak 평균으로 추론 시 최종 모델 제작
이미지 샘플링 방법은 대회 준비를 하며 지나치게 변해서 딱 집어 말할 수는 없다.
다만 대회 이후에도 가장 잘 작동한 것은 아래의 방법이다.
1. 8%~100%로 분포된 다양한 patch size에서 화면비가 3:4 혹은 4:3으로 선택된 이미지 샘플링
2. Andrew Howard의 photometric distortion(광도계 왜곡) -> 과적합 방지
3. 랜덤 보간법(bilinear, area, nearest neighbor과 cubic을 동일 확률로)
(상대적으로 늦은 순간에 사용, 다른 hyperparameter 변화와 함께)
따라서 뭐가 좋다라고 말하기가 애매...
Results
대회에서 사용한 이미지는 다음과 같다.
- 1000개의 카테고리 이미지
- training에 120만개의 이미지
- validation에는 5만개
- testing에는 10만개
성능 측정은 top-5 error rate를 사용했다. 외부 데이터는 사용하지 않았다.
참여 방식은 다음과 같다.
1. 7개의 GoogLeNet을 개별적으로 훈련해, 결과를 합쳤다.
각 모델은 같은 initialization으로 훈련했다.
오직 sampling 방법과 그 순서만 차이가 있다.
2. 이미지 cropping을 상당히 공격적으로 했다.
한 이미지 당 4x3x6x2 = 144의 crop이 생성된다
4 : 먼저 이미지를 4개의 scale로 resize한다(너비나 높이가 각각 256, 288, 320, 352)
3 : 그리고 resize된 이미지에서 left, center, right square을 추출한다(세로 이미지면 top, center, bottom)
6 : 각 square에서 4 corner, center(1)를 224x224로 crop한다,
그리고 square 그 자체도 224x224로 resize한다(1) (4+1+1)
2 : 그리고 거울쌍도 사용한다
3. softmax 확률을 crop들에 대해 평균내어 결과로 사용했다
최종 결과는 top-5 error가 6.67%로 1등을 차지했다.
Conclusions
이 결과는 dense building block으로 최적의 sparse 구조를 근사하는 것이 성능 증가에 도움되는 방법으로 쓰일 수 있다는 강력한 증거이다.
약간의 컴퓨팅 증가로 기존의 얕고 좁은 network에 비해 질이 훨씬 개선된 것이 핵심 장점이다.
더 sparse한 구조로 옮기는 것이 현실적이고 쓸모있음을 보여주는 구체적 증거가 될 수 있다.
구현
Code
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x:Tensor):
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x먼저 Convolution Block이다.
Batch Normalization도 넣어줬다.
그 뒤에는 ReLU 활성화 함수도 넣는다.
class Inception(nn.Module):
def __init__(self, in_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = ConvBlock(in_channels, n1x1, kernel_size = 1, stride = 1, padding = 0)
self.branch2 = nn.Sequential(
ConvBlock(in_channels, n3x3_reduce, kernel_size = 1, stride = 1, padding = 0),
ConvBlock(n3x3_reduce, n3x3, kernel_size = 3, stride = 1, padding = 1)
)
self.branch3 = nn.Sequential(
ConvBlock(in_channels, n5x5_reduce, kernel_size = 1, stride = 1, padding = 0),
ConvBlock(n5x5_reduce, n5x5, kernel_size = 5, stride = 1, padding = 2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size = 3, stride = 1, padding = 1),
ConvBlock(in_channels, pool_proj, kernel_size = 1, stride = 1, padding = 0)
)
def forward(self, x:Tensor):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim = 1)Inception 모듈이다.
제일 핵심이 아닌가 싶다.
내부에는 크게 4개의 branch로 구성되어 각각 만들어줬다.
그리고 마지막에 torch.cat으로 합쳐준다(가로로 합치므로 dim=1, 세로로 쌓는건 dim=0).
class GoogLeNet(nn.Module):
def __init__(self, aux_logits = True, num_classes = 1000):
super(GoogLeNet, self).__init__()
# if aux_logits not boolean, assert
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
# 224 x 224 x 3 -> 112 x 112 x 64, 7x7+2(S)
self.conv1 = ConvBlock(in_channels = 3, out_channels = 64, kernel_size = 7, stride = 2, padding = 3)
# maxpool with ceil, 3x3 + 2(S), 112 x 112 x 64 -> 56 x 56 x 64
self.maxpool1 = nn.MaxPool2d(kernel_size = 3, stride = 2, ceil_mode = True)
# 56 x 56 x 64 -> 56 x 56 x 64, 3x3 reduce
self.conv2 = ConvBlock(in_channels = 64, out_channels = 64, kernel_size = 1, stride = 1, padding = 0)
# 56 x 56 x 64 -> 56 x 56 x 192
self.conv3 = ConvBlock(in_channels = 64, out_channels = 192, kernel_size = 3, stride = 1, padding = 1)
# 56 x 56 x 192 -> 28 x 28 x 192
self.maxpool2 = nn.MaxPool2d(kernel_size = 3, stride = 2, ceil_mode = True)
# 28 x 28 x 192 -> 28 x 28 x 256
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
# 28 x 28 x 256 -> 28 x 28 x 480
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
# 28 x 28 x 480 -> 14 x 14 x 480
self.maxpool3 = nn.MaxPool2d(kernel_size = 3, stride = 2, ceil_mode = True)
# 14 x 14 x 480 -> 14 x 14 x 512
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
# 14 x 14 x 512 -> 14 x 14 x 512
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
# 14 x 14 x 512 -> 14 x 14 x 512
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
# 14 x 14 x 512 -> 14 x 14 x 528
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
# 14 x 14 x 528 -> 14 x 14 x 832
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
# 14 x 14 x 832 -> 7 x 7 x 832
self.maxpool4 = nn.MaxPool2d(kernel_size = 3, stride = 2, ceil_mode = True)
# 7 x 7 x 832 -> 7 x 7 x 832
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
# 7 x 7 x 832 -> 7 x 7 x 1024
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
# 7 x 7 x 1024 -> 1 x 1 x 1024
self.avgpool = nn.AvgPool2d(kernel_size = 7, stride = 1)
self.dropout = nn.Dropout(p = 0.4)
# 1024 -> 1000(num_classes)
self.linear = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes) # inception4a
self.aux2 = InceptionAux(528, num_classes) # inception4d
else:
self.aux1 = None
self.aux2 = None
def forward(self, x:Tensor):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
x = self.inception4a(x)
aux1: Optional[Tensor] = None
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
aux2: Optional[Tensor] = None
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x = self.avgpool(x)
# N x 1024 x 1 x 1 -> N x 1024
x = x.view(x.size()[0], -1)
x = self.linear(x)
x = self.dropout(x)
if self.aux_logits and self.training:
return x, aux1, aux2
else:
return x
GoogLeNet 구현이다.
논문 그대로 구현하는게 목표여서 최대한 논문과 비슷하게 만들었다.
먼저 CNN 왕초보...라서 Input, Output size를 모두 기록하며 구현했다 ㅠ.ㅠ.
아래에 '잡지식'파트를 보면 알 수 있지만, Image Normalize가 논문과 조금 달라 논문 형태로 수정했다.
이 외에도 kernel_size가 다른 경우, 논문대로 했다(계산해보니 결과는 같더라..).
def load_dataset():
# preprocess
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
transforms.Resize((224, 224))
])
# load data
train = datasets.CIFAR10(root="./data", train=True, transform=transform, download=True)
test = datasets.CIFAR10(root="./data", train=False, transform=transform, download=True)
train_loader = DataLoader(train, batch_size=args.batch_size, shuffle = True)
test_loader = DataLoader(test, batch_size=args.batch_size, shuffle=True)
return train_loader, test_loader데이터 로드 코드이다.
보면 알 수 있듯이 먼저 데이터는 Tensor화 시키고, Normalize한 다음 Resize해준다.
데이터 증강은 따로 하지 않았다.
if __name__ == "__main__":
args = EasyDict()
args.batch_size = 100
args.learning_rate = 0.0002
args.n_epochs = 100
args.plot = True
np.random.seed(1)
seed = torch.manual_seed(1)
# load dataset
train_loader, test_loader = load_dataset()
# model, loss, optimizer
losses = []
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if torch.cuda.is_available():
print("we use GPU")
else:
print("we use CPU")
model = GoogLeNet(aux_logits = True, num_classes = 10).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
# train
for epoch in range(args.n_epochs):
model.train()
train_loss = 0
correct, count = 0,0
for batch_idx, (images, labels) in enumerate(train_loader, start=1):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
output, aux1, aux2 = model.forward(images)
loss_output = criterion(output, labels)
loss_aux1 = criterion(aux1, labels)
loss_aux2 = criterion(aux2, labels)
loss = loss_output + 0.3 * (loss_aux1 + loss_aux2)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, preds = torch.max(output, 1) # torch max output is max, max_index
count += labels.size(0)
correct += torch.sum(preds==labels)
if batch_idx % 10 == 0:
print(f"[*] Epoch: {epoch} \tStep: {batch_idx}/{len(train_loader)}\tTrain accuracy: {correct/count} \tTrain Loss: {(train_loss/count)*100}")학습 코드이다.
Auxiliary classifier의 loss도 같이 계산하는 부분도 눈여겨 봐야한다.
if __name__ == "__main__":
model.eval()
correct, count = 0,0
valid_loss = 0
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(test_loader, start=1):
images, labels = images.to(device), labels.to(device)
output = model.forward(images)
loss = criterion(output, labels)
valid_loss += loss.item()
_, preds = torch.max(output, 1)
count += labels.size(0)
correct += torch.sum(preds==labels)
if batch_idx % 10 == 0:
print(f"[*] Step: {batch_idx}/{len(test_loader)}\tValid accuracy: {correct/count} \tValid Loss: {(valid_loss/count)*100}")성능 점검 단계이다.
Step: 100/100 Valid accuracy: 0.8672999739646912 Valid Loss: 0.4842480953037739
약 86.7%의 accuracy를 얻게 되었다.
생각보다 학습이 잘됐다(구글링 한 결과 보통 7~80퍼대였다).
학습 Epoch를 시간 제한으로 인해 13으로 제한했음에도 괜찮은 결과이다.
하며 알게된 잡지식
1.super(Class, self).__init__() : 부모 클래스를 불러와서 초기화해줌,
안하면 부모 클래스 속성 사용할 수 없다(괄호 안에 Class는 굳이 안하고 super()해도 되지만 명확하게 해주기 위해..)
2.**kwargs : *args는 받은 값을 tuple 형태로 저장, **kwargs는 받은 값을 dict 형태로 저장(포인터가 아니다!)
3.flatten(input, start_dim, end_dim)과 view(*shape)는 같은 역할을 하낟.
다만 다른점이 있다면, view() 함수는 오직 contiguous data에서만 작용하지만 flatten() 함수는 모두 된다.
4.아니 대체 왜 input 처리할 때
x_R = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_G = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_B = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5을 하는 것일까?
데이터셋의 mean이 [0,485, 0,456, 0,406]이고 std가 [0.229, 0.224, 0.225]이다.
[출처 : https://thebook.io/080289/0365/]
아니 그러면 가 되어야 하는 것 아닌가..?
https://discuss.pytorch.org/t/correct-pre-processing-for-pretrained-googlenet/94734
명쾌한 해답은 없고 아마 높은 정답률을 위해 "double pre-process"를 한 것이 아닌가.. 추측해본다.
암튼 원래는 이게 맞다(참고로 위에 저 괴상한 식이 PyTorch 공식 제공 문서에 있다..).
+) 그냥 뺐다.
학습 코드 예제를 보면 0.5, 0.5, 0.5 로 normalize 한 뒤 또 하는거라
그걸 보완하기 위해 저런 이상한 코드가 생긴 듯 하다.
그래서 그냥 처음에 transforms.Normalize할 때 저 값을 바로 써서 했다.
5.초반에 1x1 convolution이 있는 것을 볼 수 있다.
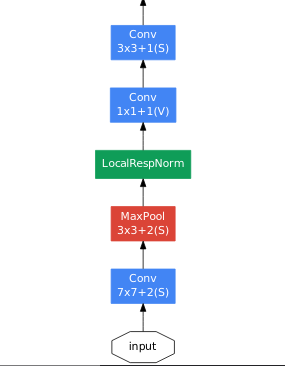
처음에는 feature map reduction을 위한 것인 줄 알았는데, 처리 전 후 모두 dimension이 64인걸로 봐서 아마 비선형성 증가를 위해 넣은 듯 하다.
다만 표기 시 일관성을 위해 #3x3 reduce에 넣은 것 아닐까..?
6.ceil_mode = True라는 구문이 자주 등장한다.
수학에서 말하는 ceil, floor이랑 비슷한건가 싶었는데 맞았다.
엄밀히 말하자면 다음과 같다.
먼저 정식 PyTorch 문서 설명이다.
ceil_mode (bool) – when True, will use ceil instead of floor to compute the output shape
이미지로 보자.
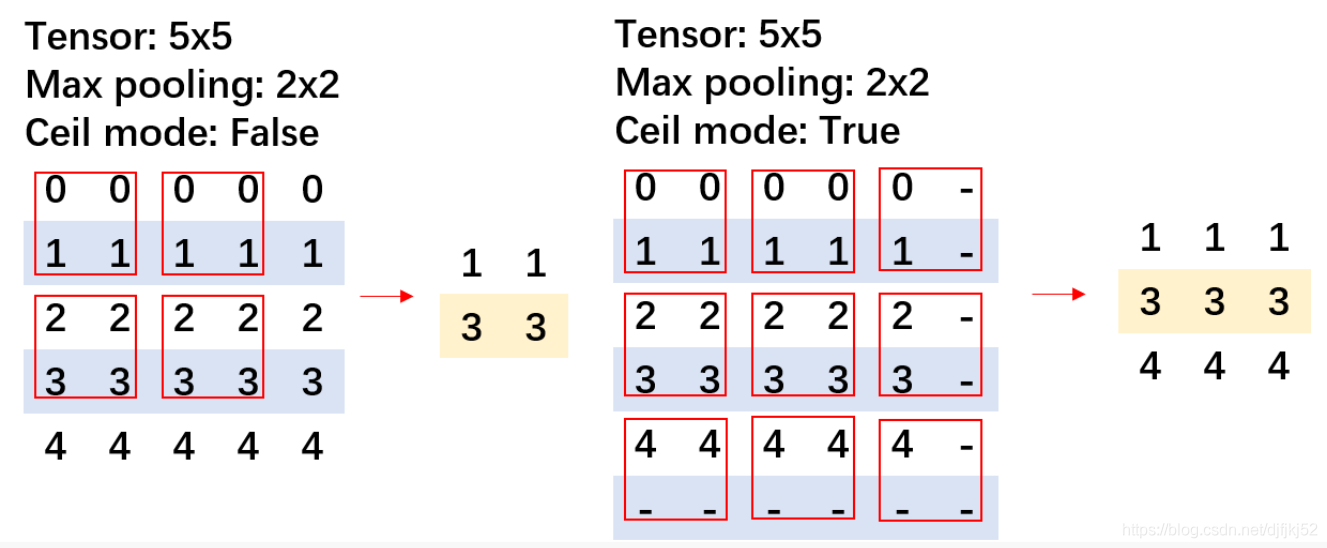
이런 느낌이다.
즉, 끝까지 가서 모든 값을 다 쓰는 것이다.
[이미지 출처 : https://blog.csdn.net/djfjkj52/article/details/117028618]
구현 코드들 참조하며 보는데 제각각 padding=1이니... ceil_mode이니.. 헷갈려서 내가 직접 계산하며 맞췄다..
이거랑 관련된 이슈가 하나있다.
논문에 쓰여진 그림과 글에는 분명 maxpool4가 kernel_size = 3, stride = 2인데,
PyTorch 제공 구현 version에는 kernel_size 가 2이다.
그렇지만, 계산해보면 같다(7x7xc).
따라서 별 문제 되지 않는다.
7.model.train(), model.eval()은 nn.Module이 제공하는 함수이다.
이걸 통해 self.training()을 조절할 수 있다.
함수 이름을 통해 알 수 있듯이, train 시에는 model.train()을, test 시에는 model.eval()을 입력해준다.
8.dummy check
if __name__ == "__main__":
x = torch.randn(3, 3, 224, 224)
model = GoogLeNet(aux_logits=True, num_classes=1000)
print (model(x)[1].shape)쫙 통과가 잘 되는지 보기 위해 dummy 값을 넣어준다.
만일 이상한게 있다면 중간에 멈출 것이다.
9.HyperParameter 저장에는 ArgumentParser 쓰기
argparse.ArgumentParser()라는 함수를 쓰면 하이퍼 파라미터를 무척 편하게 저장할 수 있다.
Ex.
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', action='store', type=int, default=100)
parser.add_argument('--learning_rate', action='store', type=float, default='0.0002')
parser.add_argument('--n_epochs', action='store', type=int, default=100)
parser.add_argument('--plot', action='store', type=bool, default=True)
args = parser.parse_args()사용 시에는 args.batch_size와 같이 쓰면 된다.
+) 슬프게도 parser는 colab에서 사용하기가 어렵다.. error 뜸
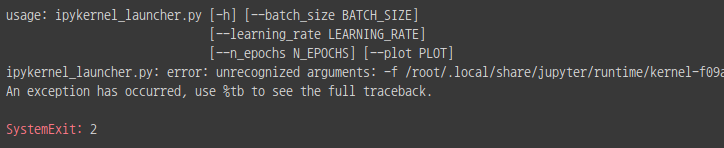
크아악.. 그래서 EasyDict를 사용했다.
EasyDict는 Dictionary처럼 쓸 수 있지만 접근은 위의 parser처럼 dot(.)으로 할 수 있다!
전체 코드는 github에 있습니다~~.
https://github.com/Parkyosep/Paper/tree/main/GoogLeNet
Reference
[1] https://wikidocs.net/119687
[2] https://phil-baek.tistory.com/entry/3-GoogLeNet-Going-deeper-with-convolutions-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
[3] https://sike6054.github.io/blog/paper/second-post/
[4] https://velog.io/@pabiya/Going-deeper-with-convolutions
[5] https://velog.io/@woojinn8/CNN-Networks-3.-GoogLeNet
[6] https://roytravel.tistory.com/338
[7] https://poddeeplearning.readthedocs.io/ko/latest/CNN/GoogLeNet/
[8] https://github.com/Lornatang/GoogLeNet-PyTorch/blob/main/model.py
[9] https://velog.io/@euisuk-chung/파이토치-파이토치로-CNN-모델을-구현해보자-GoogleNet편
[10] https://github.com/pytorch/vision/blob/main/torchvision/models/googlenet.py
[11] https://deep-learning-study.tistory.com/523
