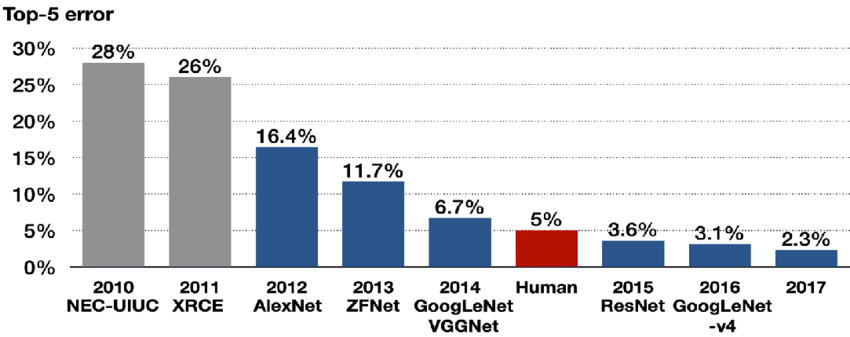
이번에 리뷰할 논문은 ILSVRC14에서 우승한 GoogLeNet 논문이다. network depth와 width는 증가했는데 동시에 computing resource 활용도 효율적으로 향상시켰다고 한다. 최적화에는 Hebbian principle, multi-scale processing을 적용했다. Auxiliary classifier, inception 구조를 주의해서 이해하면 좋을 것 같다.
여담으로 GoogLeNet이라는 이름은 최초의 CNN인 LeNet-5를 패러디한 이름이라고 한다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- GoogLeNet (Going deeper with convolutions) 논문 리뷰
- [DL - 논문 리뷰] Going Deeper with Convolutions(GoogLeNet)
- (GoogLeNet) Going deeper with convolutions 번역 및 추가 설명과 Keras 구현
Summary
이 논문에서는 Inception이라고 이름붙인 구조를 제안한다. Lin et al의 Network-in-Network(NiN) 구조에서 아이디어를 얻었는데, 이는 convolution network에 적용했을 때 1x1 convolution 후 ReLU activation을 하는 것과 대응한다. Lin et al에서는 NiN을 neural network의 representational power를 증가시키기 위해 사용하는데 여기서는 Inception을 1. computational bottleneck을 없애고자 dimension reduction을 하기 위해 사용되고 2. 그럼으로써 network의 depth와 width를 늘릴 수 있게 된다.
네트워크 성능을 향상시키는 간단한 방법은 그냥 네트워크 크기(depth나 width)를 키우는 것이다. 하지만 이는 두 가지 단점이 있다. 첫째는 늘어난 parameter로 인해 overfitting에 취약해진다는 것이고 둘째는 computational resource 사용량의 급격한 증가다.
이 두 가지 문제의 해결책은 (convolution에서조차) fully connected architecture를 sparsely connected architecture로 바꾸는 것이다. Arora et al의 연구에 따르면 dataset의 probability distribution이 large, very sparse deep neural network에 의해 표현이 가능하다면 last layer and clustering neurons의 activation들의 correlation statistics를 분석함으로써 최적의 network topology를 만들 수 있다고 한다. 이는 Hebbian principle – neurons that fire together, wire together –과도 일맥상통한다.
하지만 최근(당시)의 computing infrastructure는 non-uniform sparse data structure를 계산할 때 비효율적이다. dense matrix보다 계산 자체는 100배 적어지지만, lookup과 cache miss의 overhead가 크기 때문이다. 이때 sparse matrix computation에 관한 많은 문헌이 sparse matrix 여러개를 clustering해서 상대적으로 dense submatrices를 만들면 좋은 성능을 보인다는 것을 보여준다. Inception 구조는 이런 동기로부터 시작했고, localization과 object detection에서 좋은 성능을 보인다.
Inception 구조의 아이디어는 CNN이 어떻게 optimal local sparse
structure로 근사하고 dense component로 cover될 수 있는지 찾는 것이다. 그럼 inception 모듈은 어떻게 생겼나?
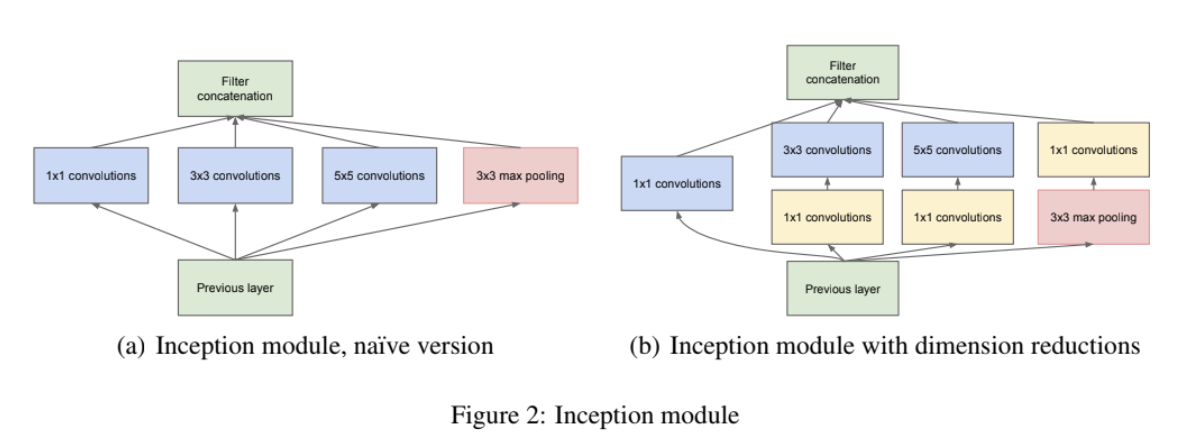
(이 부분에 대한 내 해석이 미진할 수 있다)
Arora et al은 layer-by layer construction을 제안한다. 우리는 last layer의 correlation statistics를 분석하고 그들을 high correlation을 가진 groups of units로 묶어야 한다. 이 cluster들은 next layer의 units를 이루고 previous layer의 units와 연결되어 있다.
논문의 저자들은 earlier layer에서의 각 unit들이 input image의 어떤 영역에 대응하며 이런 unit들이 filter bank로 group된거라고 가정한다. input과 가까운 lower layers에서는 correlated unit들이 local region에 밀집되어 있을 수 있는데, 단일 지역에 많은 cluster들이 있으니 다음 layer의 1x1 convolution으로 cover할 수 있다는 의미다. 넓게 퍼진 영역에서는 소수의 cluster들이 더 큰 patch convolution으로 cover될 것이다.(patch=filter인듯)
patch alignment issue를 피하고자 여기서는 편의상 Inception 구조에 1x1, 3x3, 5x5 크기의 filter를 사용했다. (filter size가 짝수면 patch의 중심을 어디로 해야 할지도 정해야하는데, 이를 patch-alignment issue라고 한다.) 또 pooling이 최근 network들에서 성공적이었기 때문에 alternative parallel pooling path를 stage마다 추가했다. 그렇게 해서 나온 구조가 위 사진 Figure 2 (a)이다.
이렇게 inception module이 output에 가까이 갈수록, 즉 higher해질수록 더 추상적인 feature(features of higher abstraction)를 포착하기 때문에 spatial concentration은 감소하게 되며 이를 위해 higher layer일수록 3x3과 5x5 convolution의 비율을 늘려야 한다.
그런데 (방금 설명한 naive 버전의) 문제는 이렇게 5x5 convolution이 많아지고 pooling unit을 추가하면 연산량이 너무 커진다는 것이다. 그래서 figure 2 (b)에 보이듯이 1x1 convolution을 사용해 dimension reduction을 한다. 이는 rectified linear activation도 사용할 수 있게 해 준다.
Inception network는 위의 모듈을 층층이 쌓고 가끔씩 reolution을 절반으로 줄이기 위해 stride 2의 max pooling layer을 끼워놓은 구조다. 그런데 training 중의 memory effeciency를 위해 lower layer은 전통적인 CNN으로 만들고 higher layer에서만 inception module을 쓰는 게 더 좋다고 한다.
이 구조의 장점은 1. dimension reduction을 통해 과도한 계산량 문제 없이 각 stage마다 unit 개수 증가를 상당히 허용한다는 것과 2. visual information이 다양한 scale로 처리되고 종합되어 다음 stage에서 여러 scale에서 동시에 feature를 abstract할 수 있다는 것이다.
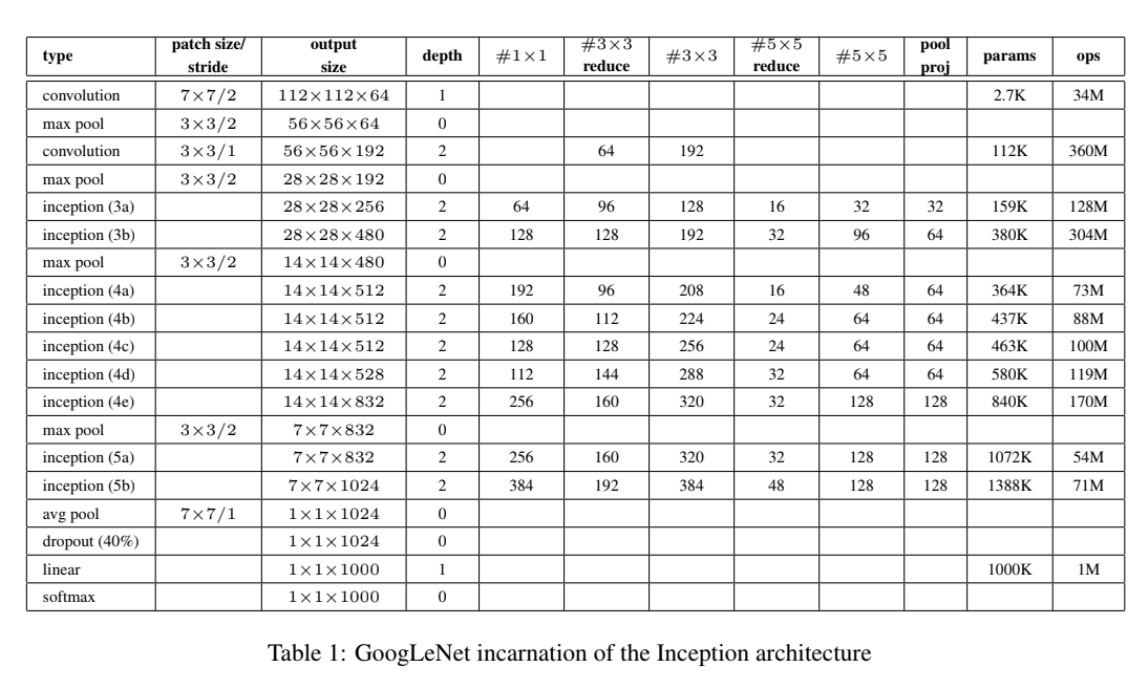
GoogLeNet의 architecture은 위의 표와 같다. Receptive field는 224x224 RGB color channel을 mean-subtraction한 것이다. #3x3 reduction, #5x5 reduction은 3x3, 5x5 convolution하기 이전에 사용한 1x1 reduction layer의 개수다. pool proj는 max-pooling 이후의 1x1 필터 수다. 흥미로운 점은 classifier 이전에 fully connected layer 대신 avgerage pooling layer을 사용한 것인데, 이는 성능에 큰 영향을 주기 보다는 다른 label set에 쉽게 adapt하고 fine-tuning할 수 있게 해서 편의상 사용한다.
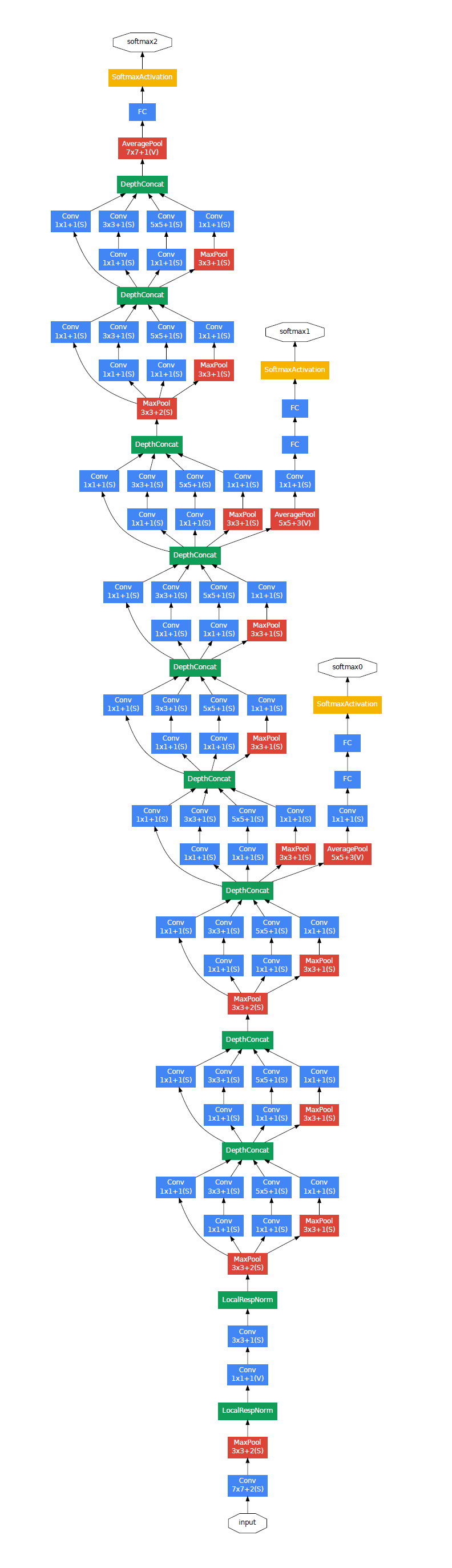
또 네트워크 깊이가 깊어질수록 backpropagation을 효과적으로 하는 것이 (vanishing gradient 문제 때문에) 문제가 된다. shallower network가 역전파 성능이 좋다는 것은 network 중간 layer들에서 생성한 feature들이 discriminative해야한다는 통찰을 제공한다. 이 논문에서는 auxiliary classifier 2개를 intermediate layer들에 연결해 1. classifier의 lower stages에서 discrimination을 encourage하고 2. 역전파되는 gradient 신호를 증가시키고 3. 추가적인 regularization을 제공한다. training 중에는 auxiliary classifier들의 loss에 가중치 0.3를 적용하여 network total loss에 더하며, test 중에는 auxiliary classifier를 제거한다.
Strengths
- NiN 구조를 사용하여 layer을 parallel하게 연결한 점이 흥미롭다.
- auxiliary classifier을 최초로 도입해서 gradient vanishing problem의 해결책을 제시했다.
- 가성비?면에서 sparser architecture의 가능성을 제시했다.
- context나 bounding box regression을 사용하지 않고도 detection 문제에서 competitive 성능을 보임으로써 inception module의 능력을 증명했다.
개인적으로 embedding과 같은 맥락으로 dimension reduction의 효과를 파악한 관점이 흥미로웠다. 내용이 어려워서 이해하기 어려웠는데 확실히 그만큼 유익한 내용이었던 것 같다. 내 예상과 달리 auxiliary classifier을 그렇게 중요하게 다루지 않는 것 같아서 의외였다.
