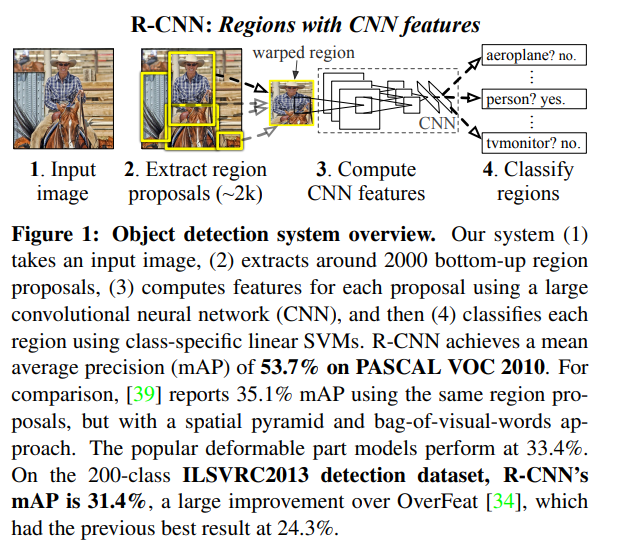
Rich feature hierarchies for accurate object detection and semantic segmentation(R-CNN)
Object Detection(Paper)

논문 제목 : Rich feature hierarchies for accurate object detection and semantic segmentation
논문 링크 : https://arxiv.org/pdf/1311.2524.pdf
이번에 읽을 논문은 Object Detection의 근간이라 할 수 있는 R-CNN이다.
처음에 분량보고 쫄았는데(장장 21 page..), 찐 논문은 11 page까지고 나머지는 Appendix라 안심했다.

위 사진은 Object Detection의 발전 과정이다.
R-CNN은 정말 초창기의 모델임을 알 수 있다.
참고로 최근 모델 or 요즘 가장 많이 쓰이는 모델을 찾는 법은 다음과 같다.
Hugging Face 접속 -> 카테고리 선택 -> Most Likes or Most Downloads로 정렬
하고 본인 입맛대로 쓰면 된다.
요즘 추세를 보아하니 detr or yolos(혹은 yolo 시리즈)가 인기있는듯하다.
[후기]
질질~~ 끌다가 겨우 다 읽었다.
일단 detection 논문은 처음이라... 읽다가 IoU? mAP? Hard negative mining? 하면서
찾으면서 읽느라 좀 오래 걸렸다.
논문 내용 자체야 예전에 따로 공부하며 알아서 비교적 이해는 쉬웠다.
머신러닝 기술인 SVM, SVR을 딥러닝과 접목해서 사용한 방식이 신기했다.
요즘은 아마 SVM 자체도 딥러닝으로 대체할 것 같은데..
이 논문에서는 연결고리가 있다는 것이 참신했다.
+) 이제 논문 읽으면서 굳이 안 읽어도 되는 파트가 눈에 보인다.
이거는 안 읽어도 이해에 큰 문제가 없구나~~ 싶은건 모두 제쳐두고 읽었다. ㅋㅋ
끝!
Abstract
R-CNN(region proposal with CNNs)는 기존의 모델보다 약 30% 높은 mAP(53.3%)를 달성했다.
이 방식은 두 가지의 핵심 아이디어가 있다.
1) high-capacity(높은 표현력)의 CNN을 bottom-up 영역 제안에 사용했다.
(bottom-up 방식은 픽셀 단위에서 출발해서 판단하는 것이다)
이는 object를 localize하고 segment하기 위함이다.
2) label된 학습 데이터가 부족할 때, auxiliary task에 지도된 사전 학습(+ domain-specific fine-tuning)은 성능을 높여준다.
1. Introduction
이 논문은 이미지 분류와 object detection 간의 다리를 놓는다.
즉, CNN이 object detection에도 효과가 있음을 보여주는 첫 논문이다.
당면한 문제는 두 가지였다
1) deep network로 object localizing하기
2) 적은 양의 주석달린 detection 데이터로 high capacity 모델 훈련시키기
문제 1 - object localizing
CNN을 활용할 방법으로는 세 가지가 제시되었다.
1. Regression
그러나 이는 좋지 않은 방식임이 드러났다.
2. Sliding-window
기존 논문보다 unit을 high up해서, receptive field를 넓혔다(195x195 픽셀).
그리고 stride도 넓혀서(32x32 픽셀) localization을 정확하게 했다.
3. Recognition using regions(채택됨)
이 방식은 object detection과 semantic segmentation 모두에 효과적이다.
1) 대략 2000개 정도의 category 없는 영역을 제안함(CNN 활용)
2) 제안된 영역에서 고정된 길이의 feature vector 추출(CNN 활용)
3) 각 영역을 linear SVM으로 category 분류
문제 2 - label 된 데이터는 부족하다(큰 CNN 학습하기엔 턱없이 모자람)
1. 기존 해결책 : 비지도 사전 학습 + 지도된 fine-tuning
2. 제시된 해결책 : 큰 auxiliary 데이터셋(ILSVRC)에 지도 사전 학습 후 작은 데이터셋(PASCAL)에 fine-tuning
+) 간단한 bounding-box regression(R-CNN BB)은 mislocalization을 낮춰줬다.
Bounding-box regression은 3.5절 참고
2. Object detection with R-CNN
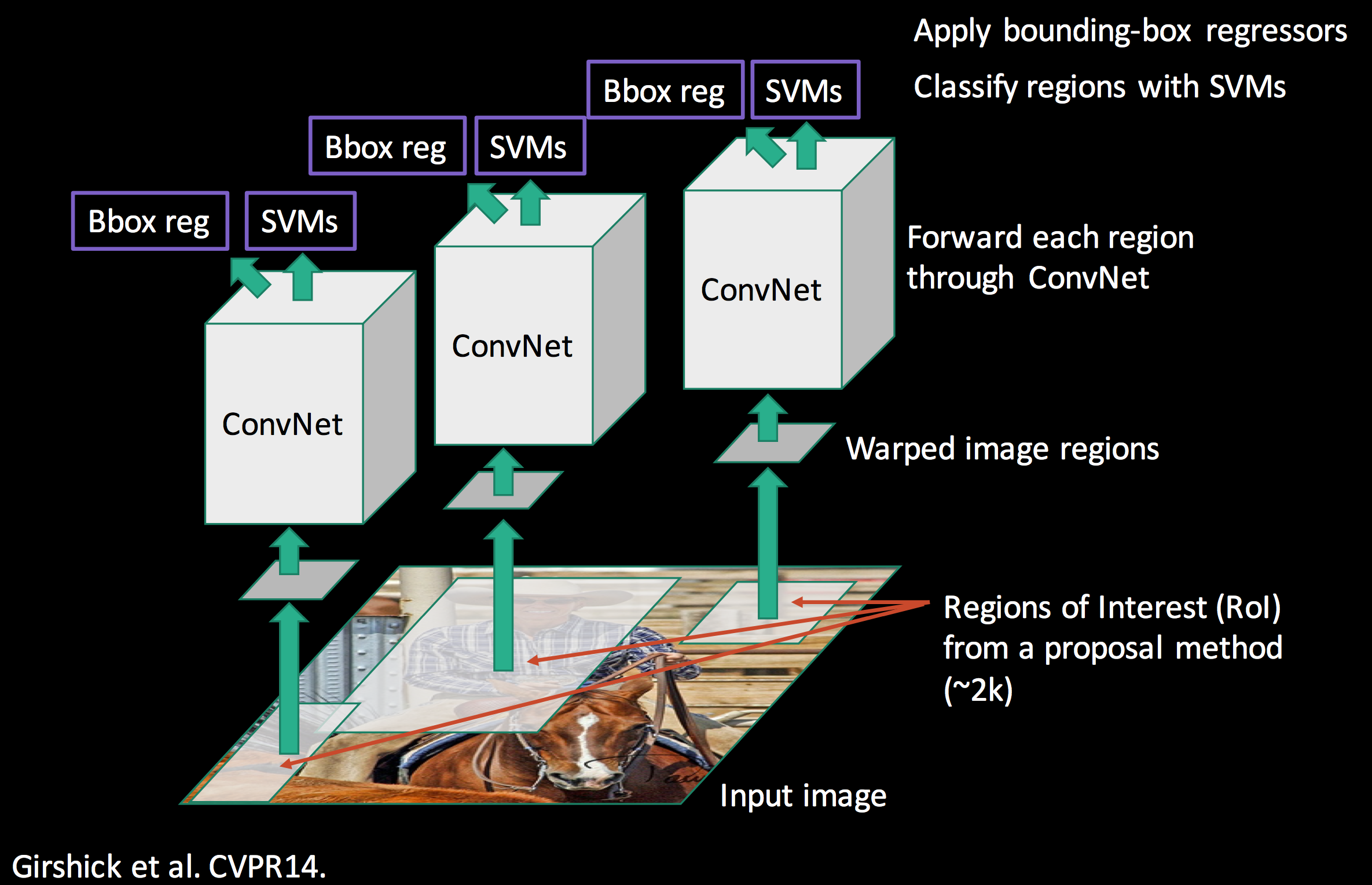
이 시스템은 세 가지 모듈로 구성된다(Fig. 1 참고).
1) category없이 영역 제안 - 가능한 후보군을 보여준다.
2) CNN으로 고정된 길이의 feature vector를 각 영역에서 추출한다.
3) linear SVM으로 분류한다.
2.1 Module design
Region proposals.
Category와 무관하게 영역을 제안했으며, selective search 방식을 사용했다.
Selective search란 다음과 같다.
이 사진처럼 random하게 영역을 제안하고, merge해가며 인식하는 것이다.

Feature extraction.
Alexnet에서 묘사된 Caffe 방식으로 4096차원의 feature vector를 추출했다.
Feature는 227x227 RGB(mean subtracted) 이미지가 5개의 conv layer와 2개의 FC layer를 forward propagating하며 계산되었다.
CNN을 통과시키기 위해 이미지를 warp(영상 찌그러뜨리기, 그냥 사이즈 맞추는 것)했다.
이미지 context를 위해 bounding box 주위에 p pixel(여기서는 p=16)을 유지한 채로 warp했다.
(즉 이미지 주변에 패딩처럼 p=16 pixel 남기고 다 잘라낸 후, warp)
2.2 Test-time detection
Test time에서는...
1) Selective search로 2000개의 영역을 제안한다(selective search "fast mode" 사용).
2) 각 제안된 영역을 warp하고 CNN을 통과시켜 feature를 추출한다.
3) 각 클래스에 대해, SVM으로 점수를 낸다.
4) 점수가 있는 영역에 대해, greedy NMS(Non-Maximum Suppression)을 적용한다.
Greedy Non-Maximum Suppression(NMS) 참고
Non-max suppression 알고리즘 작동 단계
1. 하나의 클래스에 대한 bounding boxes 목록에서 가장 높은 점수를 갖고 있는 bounding box를 선택하고 목록에서 제거합니다. 그리고 final box에 추가합니다(여기서 점수는 object에 대한 예측 점수이다).
2. 선택된 bounding box를 bounding boxes 목록에 있는 모든 bounding box와 IoU를 계산하여 비교합니다. IoU가 threshold보다 높으면 bounding boxes 목록에서 제거합니다.
3. bounding boxes 목록에 남아있는 bounding box에서 가장 높은 점수를 갖고 있는 것을 선택하고 목록에서 제거합니다. 그리고 final box에 추가합니다.
4. 다시 선택된 bounding box를 목록에 있는 box들과 IoU를 비교합니다. threshold보다 높으면 목록에서 제거합니다.
5. bounding boxes에 아무것도 남아 있지 않을 때 까지 반복합니다.
6. 각각의 클래스에 대해 위 과정을 반복합니다.
참고 블로그1, 참고 블로그2

Run-time analysis.
두 가지 특성이 R-CNN을 효율적으로 만들어준다.
1) 모든 CNN parameter는 공유된다.
2) CNN으로 계산된 feature vector는 타 방법과 비교해보면 상대적으로 저차원이다.
이러한 특성 덕분에 시간이 분할된다(아마도 줄어든다는 뜻인듯).
클래스와 연관된 계산은 feature vector와 SVM 간의 dot 연산뿐이다.
그래서 객체 탐지에 걸리는 시간은 GPU로 이미지 당 13초, CPU는 이미지 당 53초다.
2.3 Training
Supervised pre-training.
CNN으로 큰 auxiliary 데이터셋(ILSVRC2012 classification)으로 사전 학습했다.
Bounding box label이 없어서 이미지 단위의 주석만 사용했다.
결과는 AlexNet과 거의 유사했다(Top-1 error 2.2%만 높은 정도).
Domain-specific fine-tuning.
CNN을 새로운 과제(detection), 새로운 domain(warped window)에 적응시키기 위해 SGD를 사용했다.
SGD는 CNN parameter를 제안된 warped 지역으로만 학습했다.
1000-way classification layer를 (N+1)-way classification layer로 대체했다.
N은 클래스 수, 1은 배경을 위해 추가했다. 나머지 구조는 그대로다.
(VOC에는 N=20, ILSVRC2013에는 N=200을 사용했다)
제안된 지역 중 IoU가 0.5보다 같거나 크면 positive, 아니면 negative로 처리했다.
SGD는 처음 0.001의 LR로 시작했다.
이는 사전 학습 LR의 1/10 수준으로, SGD가 initialization을 망치지 않도록 하기 위함이다.
각 SGD때마다, 32개의 positive window, 96개의 배경 window를 균일하게 sampling하여 128 size의 mini batch를 만들었다.
Positive가 배경에 비해 너무 적었기에 positive window에 대해 bias sampling(?)을 진행했다.
Object category classifier.
배경 영역은 negative example(객체가 positive)로 판별하면 된다.
그러나 만일 영역이 배경과 객체에 걸친다면?
이러한 문제를 해결하기 위해 threshold 0.3의 IoU를 사용했다.
Threshold는 validation set에 {0, 0.1, ..., 0.5}로 grid search해서 찾았다.
Threshold가 달라지면 mAP도 감소했기에 이를 찾는 것은 중요했다.
Feature가 추출되고 training label이 모두 적용되면, 클래스에 대해 선형 SVM을 최적화했다.
학습 데이터가 너무 커서 standard hard negative mining 방법을 적용했다.
2.4 Results on PASCAL VOC 2010-12
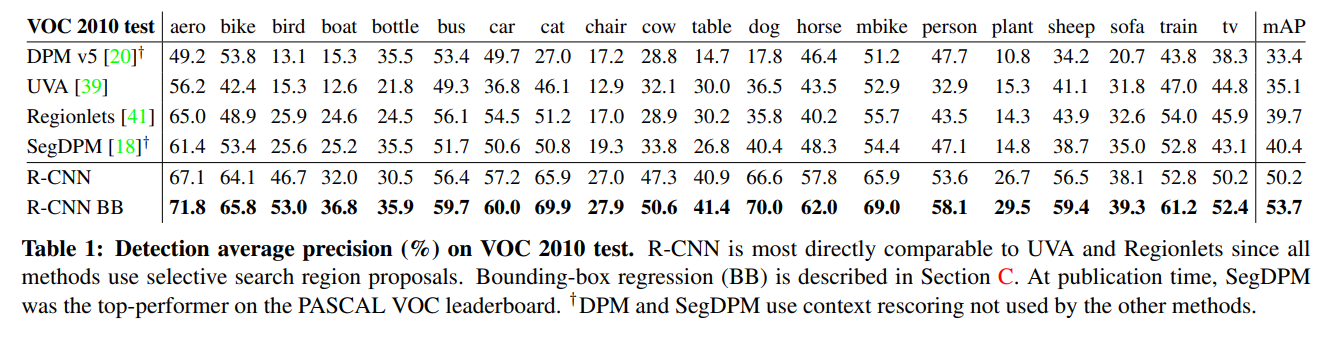
Table 1은 VOC 2010의 결과를 보여준다.
다른 방법에 비해 훨씬 높은 mAP와 속도를 달성했다.
2.5 Results on ILSVRC2013 detection
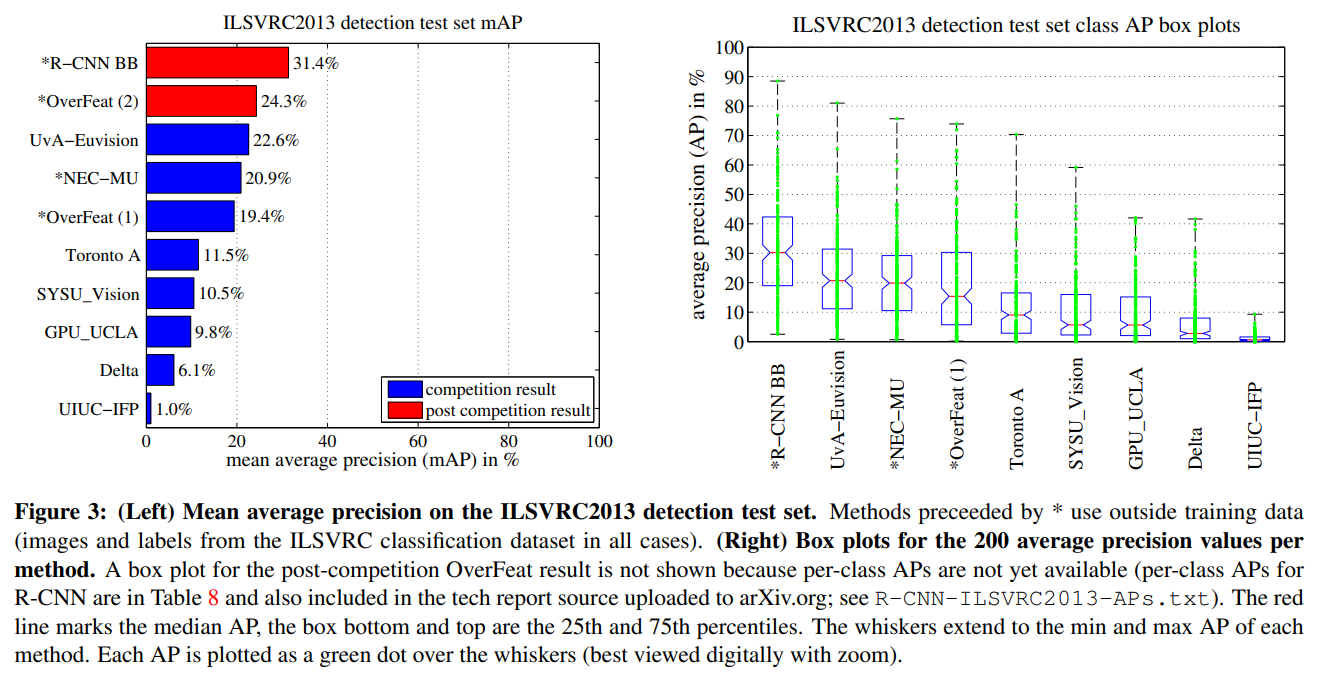
R-CNN BB(Bounding Box regression)을 200 클래스의 ILSVRC2013 detection 데이터셋에 적용했다.
결과는 31.4%의 mAP로, 다른 방법에 비해 확연히 높은 수치이다.
3. Visualization, ablation, and modes of error
3.1 Visualizing learned features
첫 레이어 filter는 직관적이고 이해하기 쉽다.
저자는 간단하고 non-parametric한 방법을 제시한다.
방법은 "speak for itself"이다.
먼저 특정 unit(feature)을 골라 대량의 데이터를 주고 영역 제시를 시킨다.
그 다음 activation이 높은 것부터 낮은 것으로 제안을 정렬하고, NMS를 적용한다.
그 다음 top-scoring 영역을 표시한다.

의 unit을 visualize했다.
Feature map은 6x6x256=9216 차원이다.
227x227 input 이미지에 대해 195x195의 receptive field를 가지고 있다.
Figure 4는 top 16 activation을 보여준다.
두 번째 열을 보면 강아지와 점을 잘못 분류한 것을 볼 수 있다.
네트워크는 모양, 질감, 색 등을 종합적으로 사용해 판별하는 것으로 보인다.
그 다음 FC layer는 이러한 많은 feature를 사용할 것이다.
3.2 Ablation studies
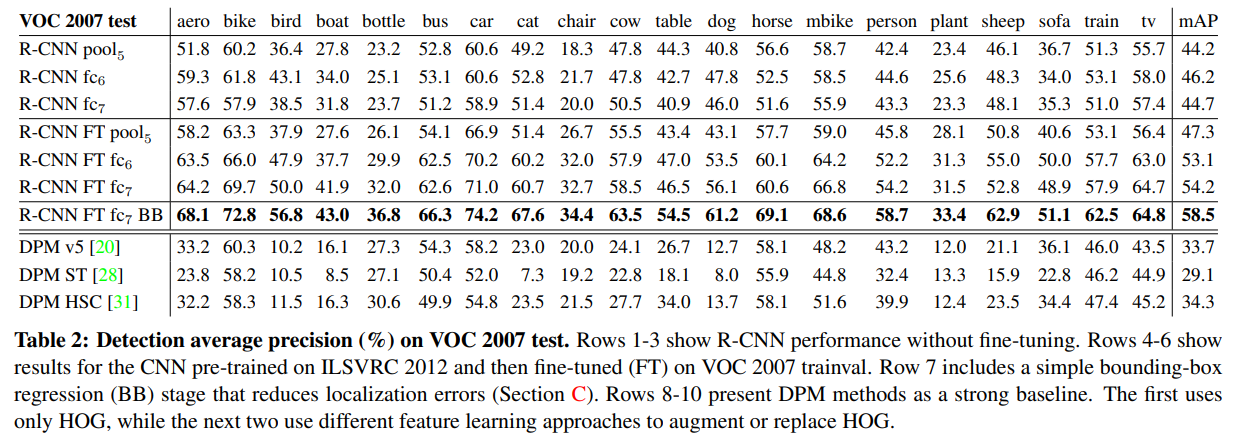
Performance layer-by-layer, without fine-tuning.
VOC 2007 데이터를 통해 어느 레이어가 detection 성능에 중요한지 살펴보자.
FC6는 Pool5에 연결되어 있다.
Pool5의 9216차원 벡터를 사용해 4096x9216 가중치를 계산한다.
중간 벡터는 max(0, x)로 대체된다(ReLU말하는 듯).
FC7은 네트워크의 마지막 레이어이다.
FC6에 연결되어 4096x4096 가중치를 계산한다.
먼저, PASCAL에서 fine-tuning 없이 결과를 관찰했다.
(즉 ILSVRC2012만 사전 학습한 것이다)
레이어 별로 성능을 분석한 결과, FC7이 FC6보다 성능이 좋지 않았다.
즉 29%(약 16.8M)의 CNN parameter가 제거되어도 mAP가 나빠지지 않는 것이다.
더 놀랍게도, FC6, FC7을 제거해도 성능이 비슷했다..
즉, CNN 표현력의 대부분은 FC가 아니라 conv layer에서 오는 것이다.
Performance layer-by-layer, with fine-tuning.
그 다음은 VOC 2007로 parameter를 fine-tuning하고 결과를 분석했다.
mAP는 약 8.0 상승해서 54.2%를 기록했다.
성능 상승은 FC6, FC7가 Pool5에 비해 더 컸다.
즉, 대부분의 성능 개선은 domain-specific non-linear classifier(FC layer)로부터 얻어진 것이다.
3.3 Network architectures
저자는 기본 구조 선택이 R-CNN 성능에 큰 영향이 있음을 알아냈다.
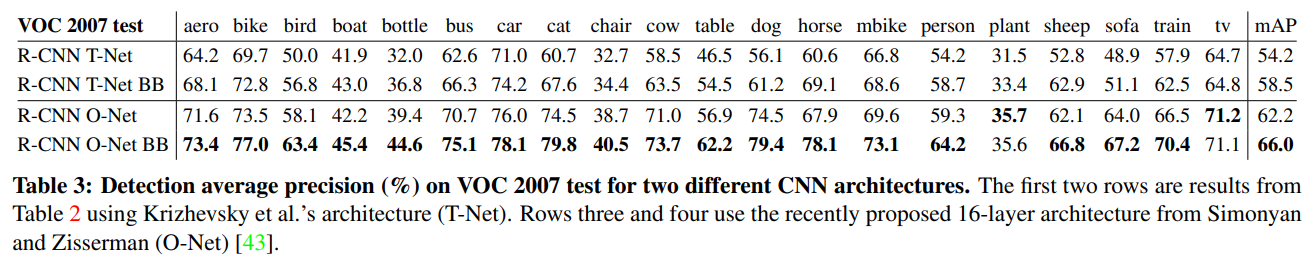
Table 3는 구조에 따른 성능 차이를 보여준다.
저자는 O-Net(OxfordNet = VGGNet), T-Net(TorontoNet = AlexNet)을 사용하여 성능을 측정했다.
사전 학습된 네트워크의 weight를 다운받고 fine-tuning했다.
차이점이라면 GPU 관계상 O-Net은 더 작은 minibatch를 사용했다는 점이다.
결과는 O-Net이 T-Net을 상회했다(mAP 66.0% vs 58.5%).
그러나 O-Net은 forward pass가 T-Net보다 7배 길다는 치명적 단점이 있다.
3.4 Detection error analysis
Hoiem이 제안한 detection analysis tool로 분석했다.
어떻게 fine-tuning이 모델을 바꾸고, 어떻게 error type이 다른지를 알기 위함이다.
Figure 5, Figure 6를 참고하자.
Figure 5이다.
Top rank된 FP(거짓 양성)의 분포를 알아보는 것이다.
- Loc : poor localization (IoU가 작은 case)
- Sim : confusion with a similar category (유사 class와의 혼동)
- Oth : confusion with a dissimilar object category (유사하지 않은 class와의 혼동)
- BG : a FP that fired on background. (background의 방해)
(Loc 비중이 많다 = 대체적으로 IoU가 작은 data로 인한 FP 문제가 많다)
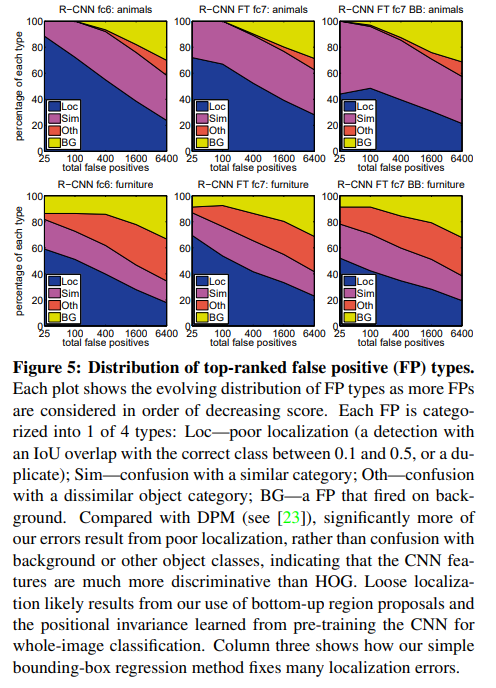
Figure 6이다.
객체 특징에 대한 민감도를 알아보는 것이다.
- occlusion(occ) : 맞물림
- truncation(trn) : 절단
- bounding box area(size) : bounding box로 인한 문제
- aspect ratio(asp) : warp로 인한 문제
- viewpoint(view) : 바라보는 각도와 같은 관점
- part visibility(part) : 특정 부위만 보이는 문제 (머리만)
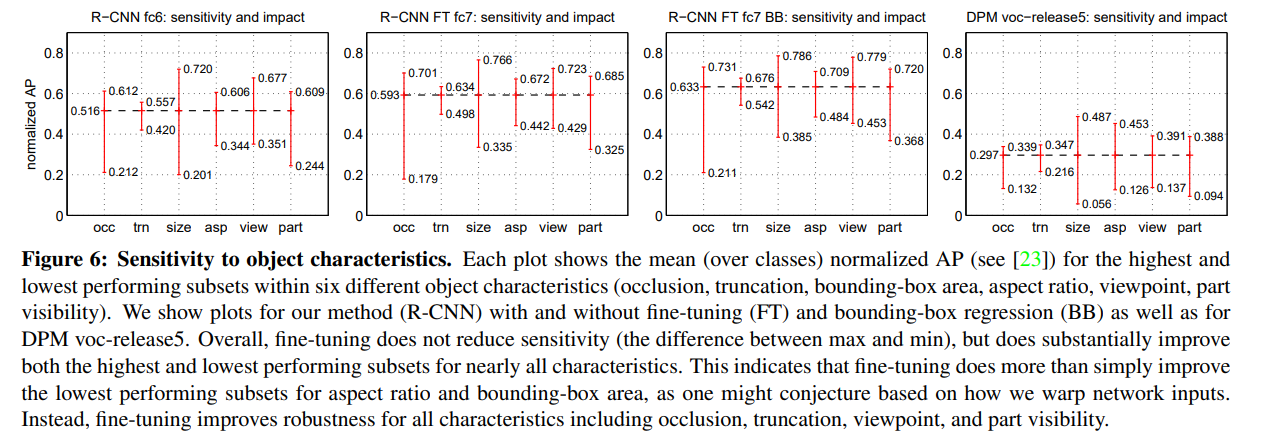
용어 설명은 다음 블로그를 참고했다.
3.5 Bounding-box regression
Bounding-box는 간단한 선형 회귀 모델이지만 상당히 많은 error를 감소시켰다.
아래는 Appendix C에 적힌 내용을 정리한 것이다.
새로운 detection window의 위치를 예측하는 모델이다.
Bounding-box Regression(Appendix C)
는 알고리즘이 제시하는 bounding box의 위치 및 너비,
는 ground-truth이다.
목적은 다음 함수를 최적화하는 것이다.
★은 중 하나를 의미한다.
여기서 각각 기호는 다음과 같다.
: learnable model parameter
: P의 feature
: L2 regularization 상수, 여기서는 1000
: 하단 참고
그 다음 함수 를 정의할 수 있다.
이 함수는 P를 transformation하는 함수이다.
제시된 P를 ground-truth의 추정값 으로 바꾸는 transformation을 적용할 수 있다.
즉 요약해보자면 P(제시된 bounding box)에 d라는 transformation을 적용해 최대한 원래의 bounding box G에 가깝게 만들어야 한다.
여기서 CNN에서 추출한 feature를 사용한다.
이미지 출처
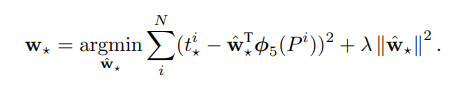
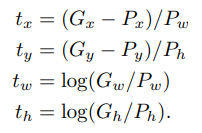
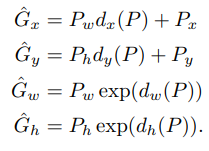

4. The ILSVRC2013 detection dataset
4.1 Dataset overview
Train : 395,918 장
Validation : 20,121 장
Test : 40,152 장
Val, Test 분할은 같은 이미지 분포에서 추출되었다.
그러나 Train은 ILSVRC2013의 이미지 분포에서 추출되었다 -> 추출 방식이 다르다!
또 Val, Test는 모두 라벨링되어있지만,
Train은 되어있는 것도 있고, 안된 것도 있다(부분적으로 된 것도 있다!).
(이를 not exhaustive라 한다)
심지어 negative 이미지도 가지고 있다.
Negative 이미지란 어떠한 객체도 없는 사진으로 '없다'는 것을 판별하는지 테스트하기 위한 사진이다.
이를 해결하기 위해 Val set도 학습에 활용했다.
Val set을 학습, validation 모두에 활용하기 위해 val1, val2로 쪼갰다.
선택은 클래스 불균형이 최소화되도록 선택되었다.
4.2 Region proposals
PASCAL때와 같은 방식으로 영역 제안을 실시했다.
Selective search는 fast mode로 val1, val2, test에 실행했다(train에는 안했음).
Selective search가 이미지 해상도에 따라 영역 제안 수가 달라지기에, width를 500 픽셀로 고정했다.
한 이미지 당 평균 2403개의 영역이 제안되었다.
4.3 Training data
학습 데이터를 위해, selective search와 val1의 ground-truth를 합쳐 이미지와 box를 만들었다.
한 클래스 당 N개의 ground-truth 박스를 만들었다.
이를 이라고 부른다.
Ablation study에서는 N = {0, 500, 1000}일때 val2의 mAP를 보여준다.
R-CNN은 세가지 과정에서 학습 데이터가 필요하다.
1) CNN fine-tuning
을 사용했다.
방식은 PASCAL때와 정확히 동일하다.
2) detector SVM 학습
Positive example의 Ground-truth box는 에서 사용했다.
Hard Negative Mining은 val1에서 5000 이미지를 선택했다.
val1의 모든 이미지 쓰기 vs 5000개의 이미지
이미지 수는 거의 절반이다.
그러나 실험한 결과 mAP는 0.5 줄었으나 SVM 학습 시간은 거의 반으로 줄었다.
따라서 5000개만 써도 충분
Train은 라벨링이 모두 되어있지 않아 negative example을 추출하지 않았다.
3) bounding-box 회귀 학습
val1으로 학습했다.
4.4 Validation and evaluation
서버에 제출하기 전 점검을 시행했다.
시스템 hyperparameter는 PASCAL과 같은 값으로 설정했다.
차선책이지만, 광범위한 데이터 튜닝 없이 R-CNN이 ILSVRC에서 잘 돌아가는지 보기 위함이었다.
BB regression 있는 것, 없는 것 두 버전을 제출했다.
4.5 Ablation study
Ablation study는 모델이나 알고리즘을 구성하는 다양한 구성요소(component) 중 어떠한 “feature”를 제거할 때, 성능(performance)에 어떠한 영향을 미치는지 파악하는 방법을 말한다. 출처
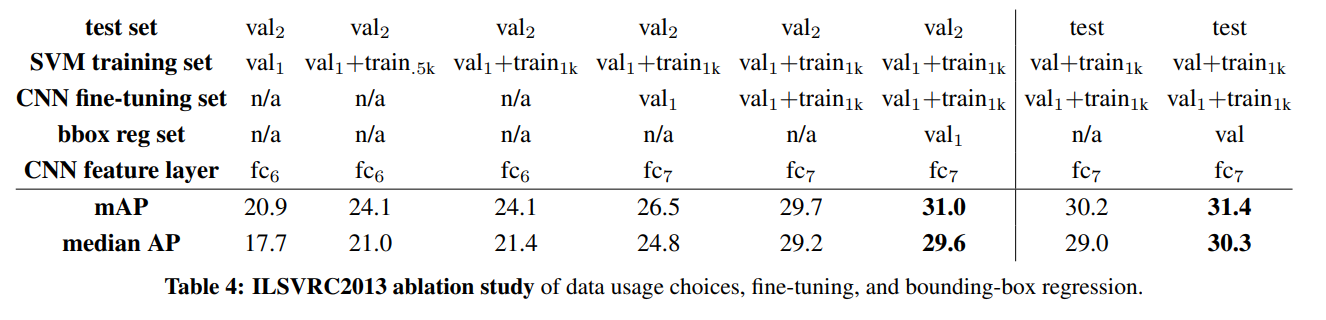
학습 데이터 양, fine-tuning, BB regression에 대해 ablation study를 진행했다.
val2의 mAP는 test의 mAP와 거의 일치했다.
이는 val2의 mAP가 test performance 가늠에 좋다는 것을 의미한다.
Fine-tuning없이 ILSVRC, val1으로 사전 학습된 CNN은 20.9%를 달성했다.
1) 학습 데이터 양
을 사용하자 성능이 24.1%까지 올랐다.
2) Fine-tuning
의 예제로 fine-tuning하니 26.5%까지 올랐다.
N은 500, 1000일 때 큰 차이가 없었다.
Fine-tuning set을 val1에서 까지 증가시키니 mAP가 29.7%까지 올랐다.
3) BB regression
BB regression을 사용하자 31.0%까지 올랐다.
그러나 이는 PASCAL에서 증가한 것 만큼은 아니었다.
6. Conclusion
본 논문에서는 기존의 모델보다 30% 나아진 object detection 결과물을 제시했다.
이는 2가지 인사이트 덕분이다.
1) 높은 표현력의 CNN
2) 학습 데이터가 적을 때, 큰 CNN을 사전 학습한 후 fine tunning
Reference
Paper
[1] https://aigong.tistory.com/34
[2] https://intelligentcm.tistory.com/81
NMS
[3] https://wikidocs.net/142645
[4] https://deep-learning-study.tistory.com/403
mAP
[5] https://www.waytoliah.com/1491
[6] https://velog.io/@joon10266/Objection-Detection-mAP%EB%9E%80

아주 유익한 내용이네요!