cs231n 11강 - Detection and Segmentation을 공부하며 upsampling 방식을 배웠다.
여기서 Transposed convolution 방식에 흥미가 생겨 자세히 알고자 글로 정리한다.
사실 보다가 ppt가 으잉? 싶어서 찾아보며 정리한 것이다.
Unpooling, Max Unpooling
먼저 일반적으로 학습 없이 바로 사용할 수 있는 unpooling 방식을 살펴보자.
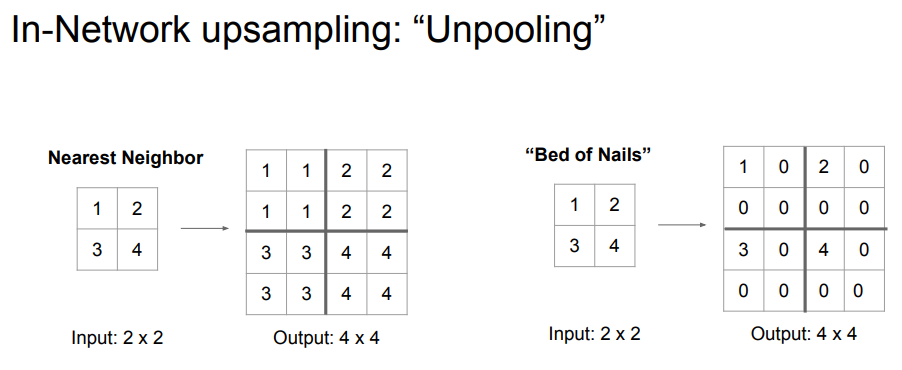
먼저 Nearest Neighbor이다. 쉽게 말해서 2x2 -> 4x4 복원 시 그냥 각 원소를 복사해서 넣는 것이다. 간단하다.
그 다음은 Bed of Nails이다. 1번째 위치에 input을 넣고 나머지는 0으로 채우는 것이다. 이름이 붙여진 이유는 톡 튀어나온 값이라서 마치 못처럼 보인다고 지은 것이다..

Max Unpooling은 조금 다르다. Max pooling은 각 최대 원소를 가져오는 것이다. 그래서 공간 정보가 조금 소실되는데, 이때 max 원소의 position을 기억한다. 그리고 복원 시 그 position에 input을 넣어 spatial details를 조금 유지하는 것이다.
Transposed Convolution
Downsampling
그렇다면 Transposed Convolution은 어떤 원리일까?
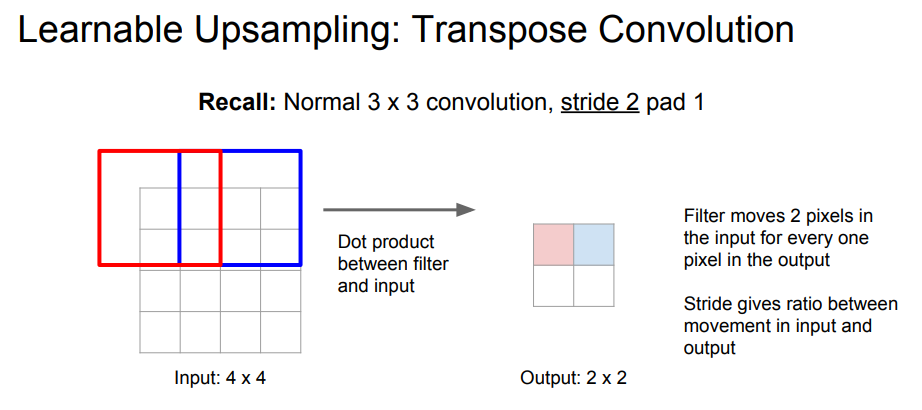
일반적인 Convolution 연산은 다음과 같다. 3x3 filter, stride=2, padding=1이라고 계산했다. Input이 4x4이므로 output은 (4-3+1*2)/2+1 = 2.5이지만 여기서는 2이다(보통 딱 떨어지게 설계한다). 이제 이를 복원해보자.
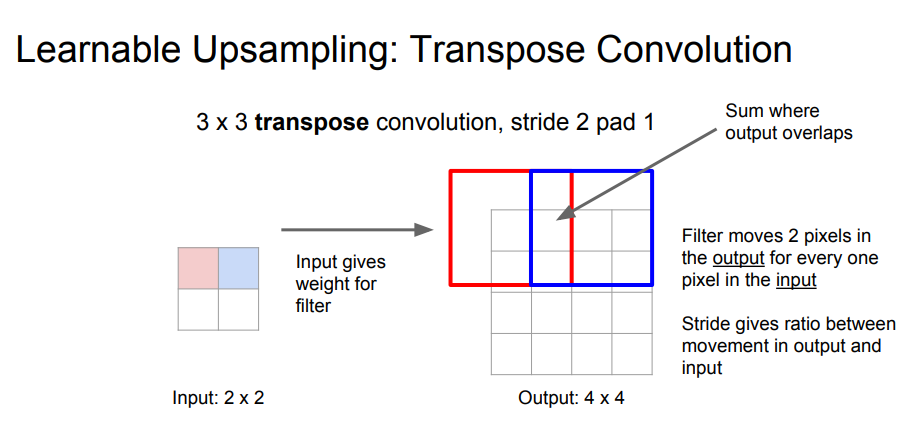
Input의 값과 filter weight가 곱해져서 Output에 쓰여진다. 여기서 좌측 상단 input은 빨간 테두리에 쓰여지는 것이다. 겹치는 값은 그냥 더해진다.
이렇게만 보면 이해하기가 조금 힘들다. 설명이 조금 부족하다. 그래서 추가적인 검색을 통해 학습했다.
이제 이해를 쉽게 하기 위해 matrix로 설명할 것이다.
먼저 downsampling부터 생각해보자. 여기서 downsampling은 convolution 계산이다(앞서 4x4를 2x2로 만든 과정).
filter size = 3x3
input size = 4x4
output size = 2x2
그렇다면 matrix로 표현한다면 input은 크기 16의 vector, output은 크기 4의 vector가 될 것 이다.
이를 위해서 [] * [16, 1] = [4, 1]를 만들어야 한다. 따라서 filter를 [4, 16] 크기로 만들어야 한다.
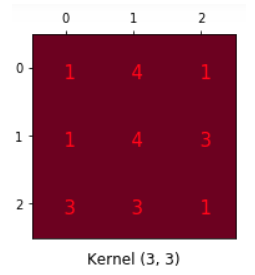
이렇게 생긴 Convolution kernel이 있다고 가정하자. Filter와 Kernel은 같은 말이다(2D냐 3D 이상이냐의 차이지만 여기서는 3x3을 생각할거니까 같다고 하자).
이제 이걸 Convolution matrix로 배치한다.
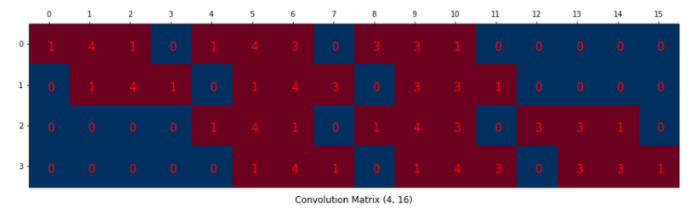
앞서 말한 [4, 16]의 크기이다. 처음에 보고 잘 이해가 안될 수 있다.
하지만 쉽게 이해하자면 다음과 같다.
0행의 1,4,1 - 1,4,3 - 3,3,1은 filter의 0, 1, 2행을 쓴 것이다. 왜 이렇게 썼을까?
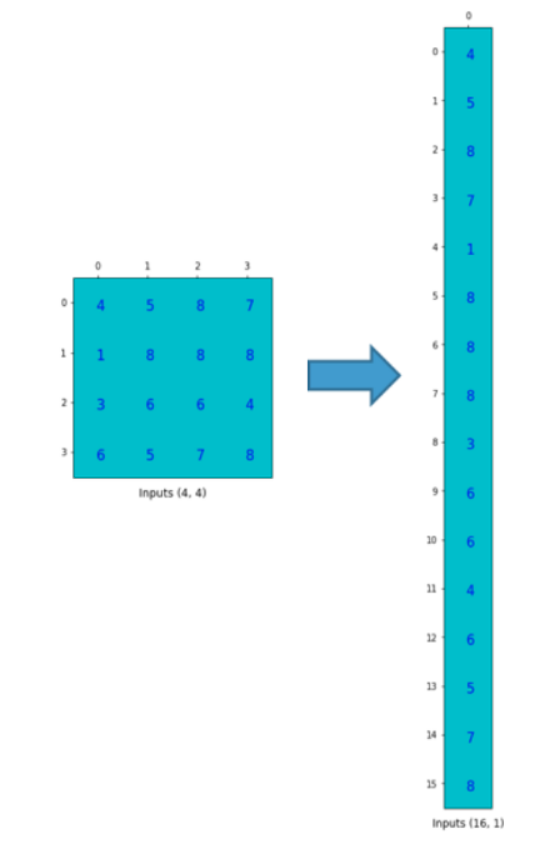
Input을 vector화 시킨 것이다. 이해가 되는가?
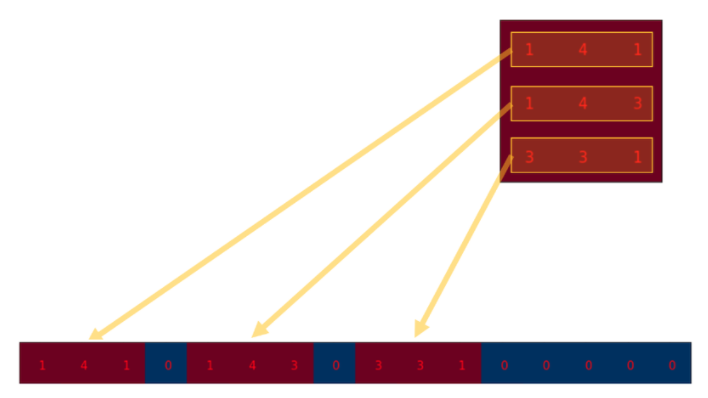
만약 여기서 0없이 1,4,1,1,4,3,3,3,1 이라고 썼다면 convolution 계산은 아마
이렇게 되었을 것이다. 우리가 원하는 것은 3x3 size 이므로 저렇게 띄워서 쓴 것이다.
마찬가지로
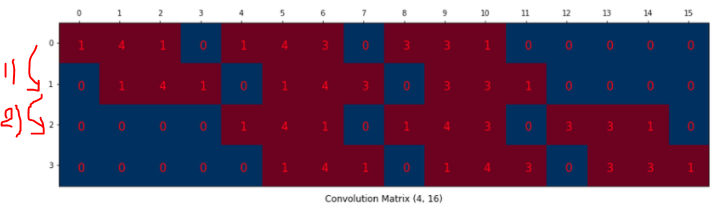
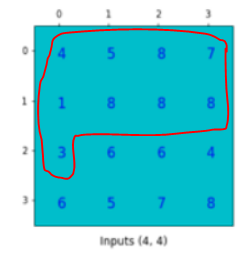
1)은 filter를 우측 상단으로 옮기는 과정이지만 2)는 필터를 우측 하단으로 옮기기 때문에 공백이 3칸 발생한 것이다.
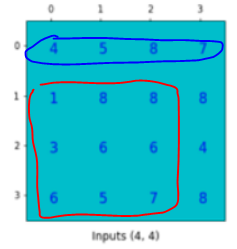
Filter를 우측 하단(빨간 테두리)로 옮기며 발생한 공백(파란 테두리)이다.
이제 이를 계산하면?
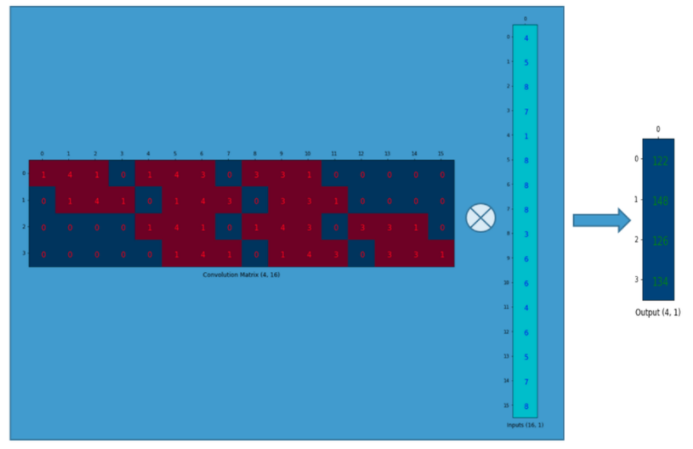
그냥 matrix multiply니까 쉽게 할 수 있다.
요약하자면 convolution은 convolution matrix(kernel weight의 재배치된 matrix)로 표현할 수 있다.
Upsampling
이걸 거꾸로 하면 upsampling이 되지 않을까? 정답이다.
앞서 [] * [16, 1] = [4, 1]를 통해 downsampling을 진행했다.
그렇다면 역행렬을 양쪽에 곱해줘서 생기는 식이 upsampling 아닐까?
[16, 1] = [] * [4, 1]
여기서 [ ]는 [16, 4] size일 것이다.
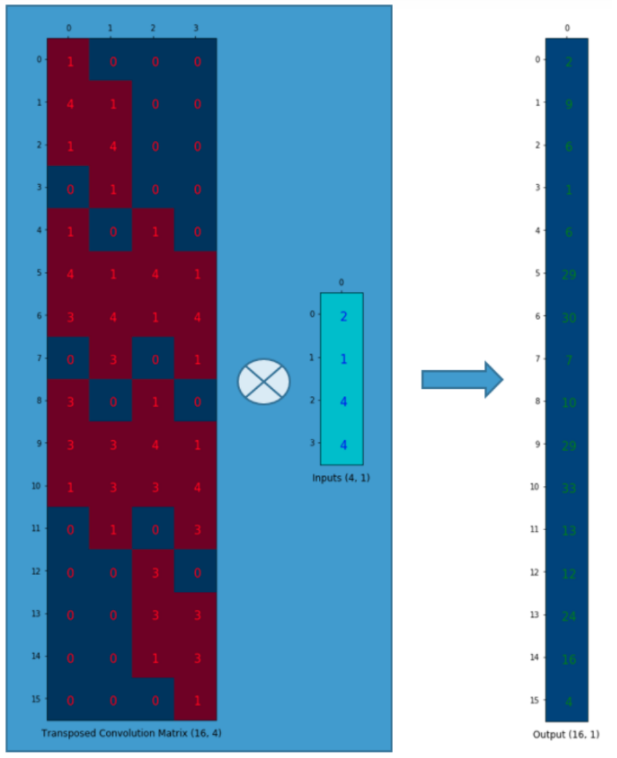
단순히 convolution matrix를 transpose 해보았다.
이렇게 보면 tranpose 된 matrix로 계산하므로 Transposed convolution이라고 부르는 것이다.
또 하나 중요한 것이 있다. 이 matrix의 값들은 모두 학습 가능한 값이다.
즉 굳이 기존 downsampling convolution matrix의 transpose일 필요없이 upsampling 잘하는 값으로 학습될 것이다(애초에 역행렬을 구해야 하긴 한다.. 그래서 학습을 통해 upsampling 잘하는 값을 찾는 것이다).
위에 길~~게 설명한 것은 이 방법이 왜 transpose라 불리는지를 설명하는 것이다. 그래서 기존 filter 값을 사용하지 않아도 된다.
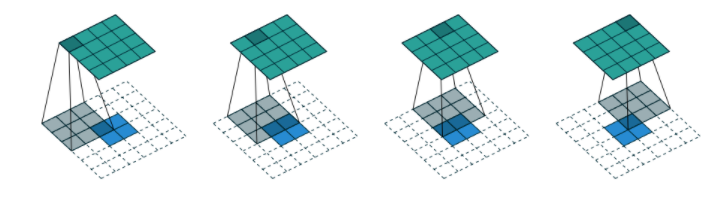
+) 처음에는 tranpose matrix 자체를 학습하는 줄 알았는데 Pytorch에서 사용 가능한 함수인 ConvTranspose2d 함수는 그 구성 요소인 filter를 학습하는 것 같다.
즉 matrix 전체가 아니라 filter만 찾아내어 앞서 나온 cs231n 과정처럼 복원하는 듯 하다.
Upsampling 잘하는 filter를 찾아내는 과정인 듯 하다..(그리고 그 filter로 앞서 말한 Tranpose Convolution을 통해 upsampling을 한다)
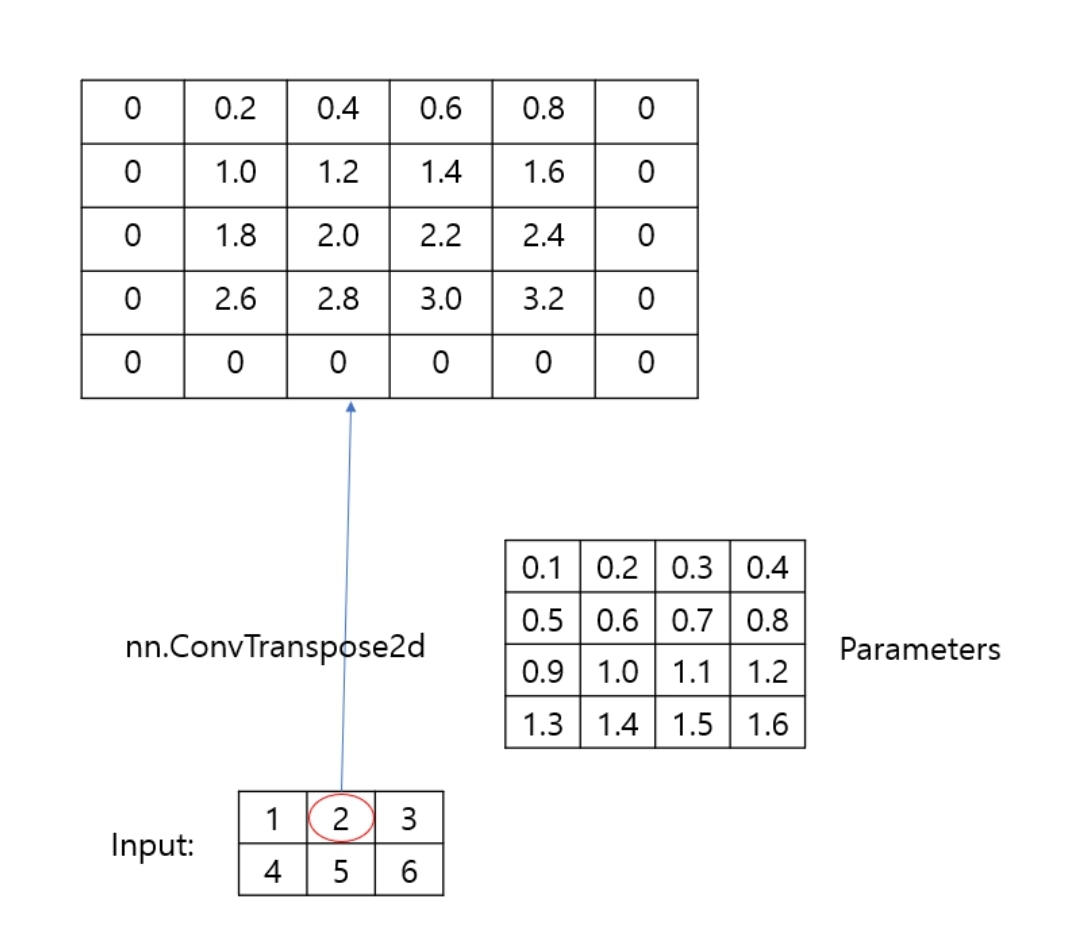
Upsampling 과정이다. ConvTranspose2d 함수가 적용되는 방법이다. https://cumulu-s.tistory.com/m/29 에 잘 요약되어 있다. 함수의 방식이 cs231n에서 설명한 대로 적용되는 것을 볼 수 있다.
Summary
Transposed Convolution은 기존 upsampling 방식들과는 다르게 학습 가능한 값으로 upsampling을 한다. 이름이 붙여진 이유는 위에서 길~게 설명했으니 넘어가고 model을 학습하며 upsampling weight를 파라미터로 설정해 잘 찾아내면 된다.
Reference
https://gaussian37.github.io/dl-concept-transposed_convolution/
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
https://zzsza.github.io/data/2018/06/25/upsampling-with-transposed-convolution/
https://realblack0.github.io/2020/05/11/transpose-convolution.html
http://machinelearningkorea.com/2019/08/25/upsampling2d-%EC%99%80-conv2dtranspose%EC%9D%98-%EC%B0%A8%EC%9D%B4/
https://simonjisu.github.io/deeplearning/2019/10/27/convtranspose2d.html
