1. Evaluating a Model
1-1. Motivation

- If there is only one feature, it is possible to plot the model and see if the model is overfitting or underfitting.
- However, if there are more than one feature, it is impossible to plot.
- How do we then find out if our model is doing well and close to accurate?
- We need a more systematic way to calculating it.
1-2. Training Set and Testing Set

- Can split the data set into training set and testing set.
- 70% & 30%, 80% & 20%, so on.

- Regularization term is added in the cost function for the trained model.
- Losses for the test set and the training set are computed.

- If the model is overfitting, the loss value for the test set will be high and for training set will be low, since overfitting models does not generalize to new training data.

- The same could be done for classification problem.
- There is another way to compute the loss, which is computing the fraction of data that is misclassified.

2. Model selection and training/cross validation/test sets

- J_test() is a better estimate than J_train() of how well the model will generalize to new data, since the parameters are already fit using the training set of data.

- How do I report generalization error?
- One flawed way is to select the model with the least J_test() and report J_test() as the generalization error.
- This is flawed because we already used J_test() and selected the model with the least J_test(), so it is a rather optimistic estimate of the generalization error.
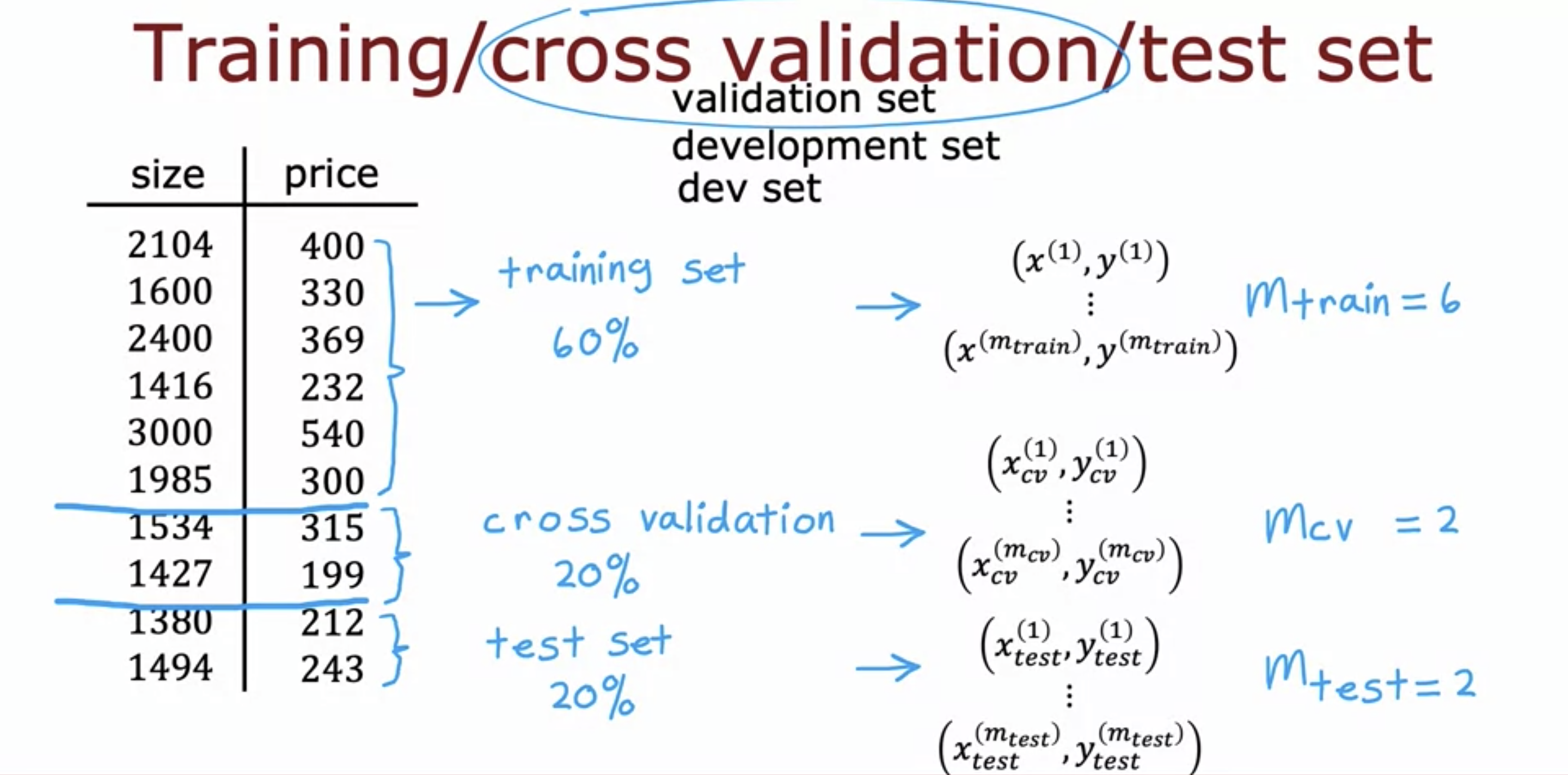
- The better alternative is to split the data set further into cross validation set as well.

- Cross validation error is also computed as above.
- None of the formulas include regularization term because the reg term is only used for training purpose.

- Compute J_cv() for every model, and choose the one with the least J_cv() as the main model.
- Then estimate generalization error using the test set data.
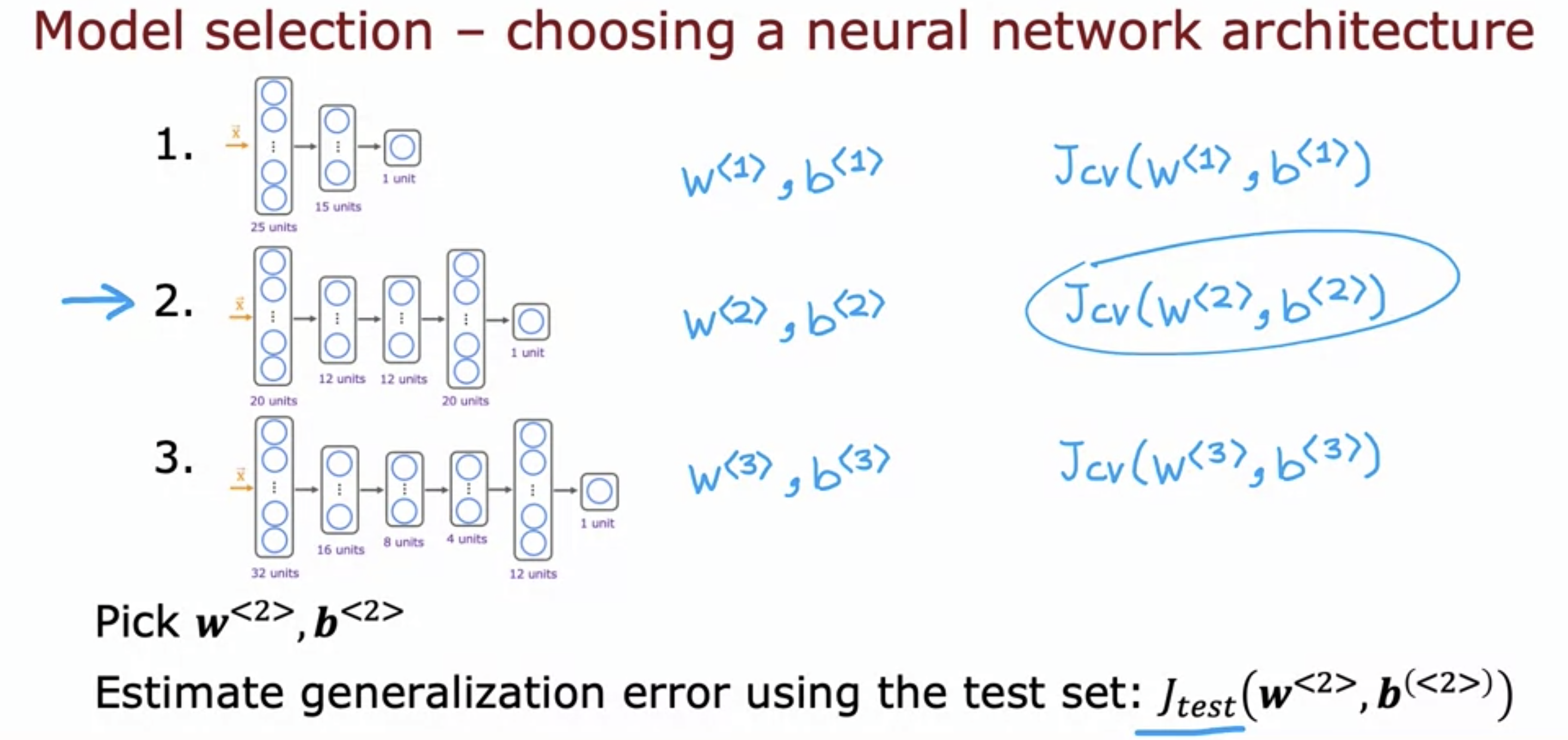
- To choose the best neural network model, we can compute J_cv() for all three of these models, and choose the one with the least J_cv() value.
- Assuming it is a classification problem, we can compute the cost using the fraction of data misclassified.
- Then we can use the test set to estimate generalization error.
- The test set is only used after choosing the model to report predicted generalization error.

everything happens for a reason