SupervisedML
1.ML 1: Supervised vs Unsupervised ML
Field of study that gives computers the ability to learn without being explicitly programmed. (Arthur Samuel, 1959)Machine learning algorithms: Superv
2.ML 2: Regression Model
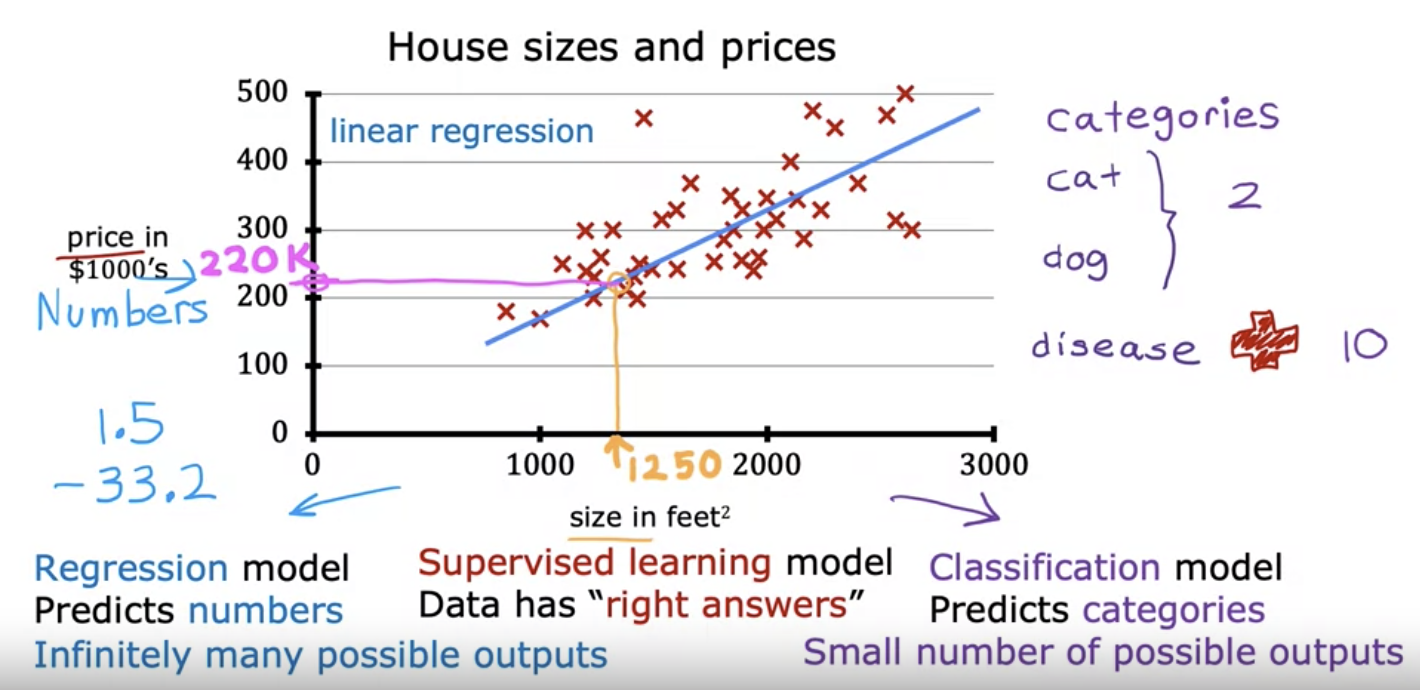
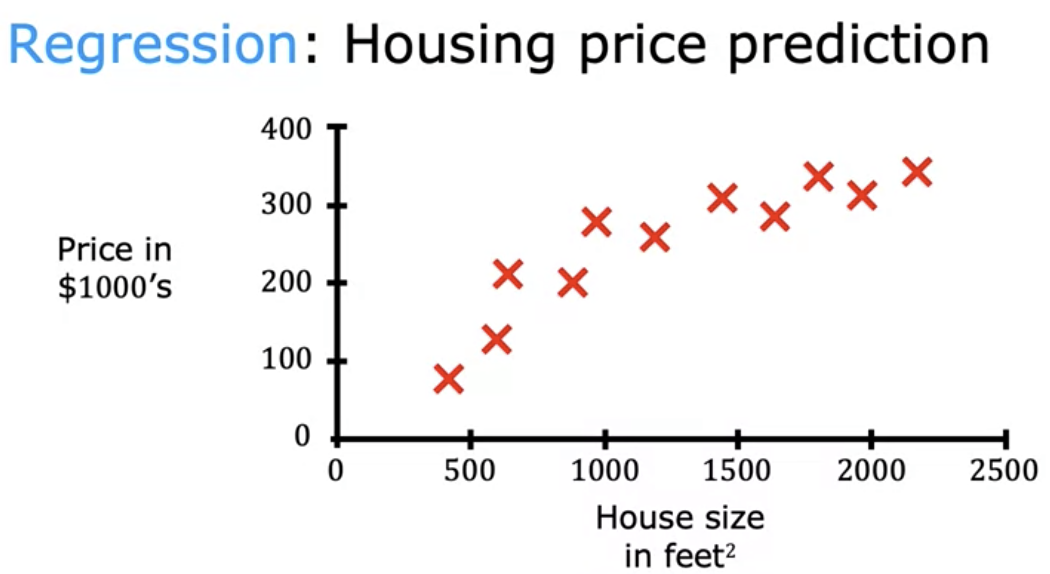
Linear Regression model: drawing a fitting linear line. Training set: Data used to train the model. ex: Table of house sizes in feet^2 and prices. x =
3.ML 3: Gradient Descent
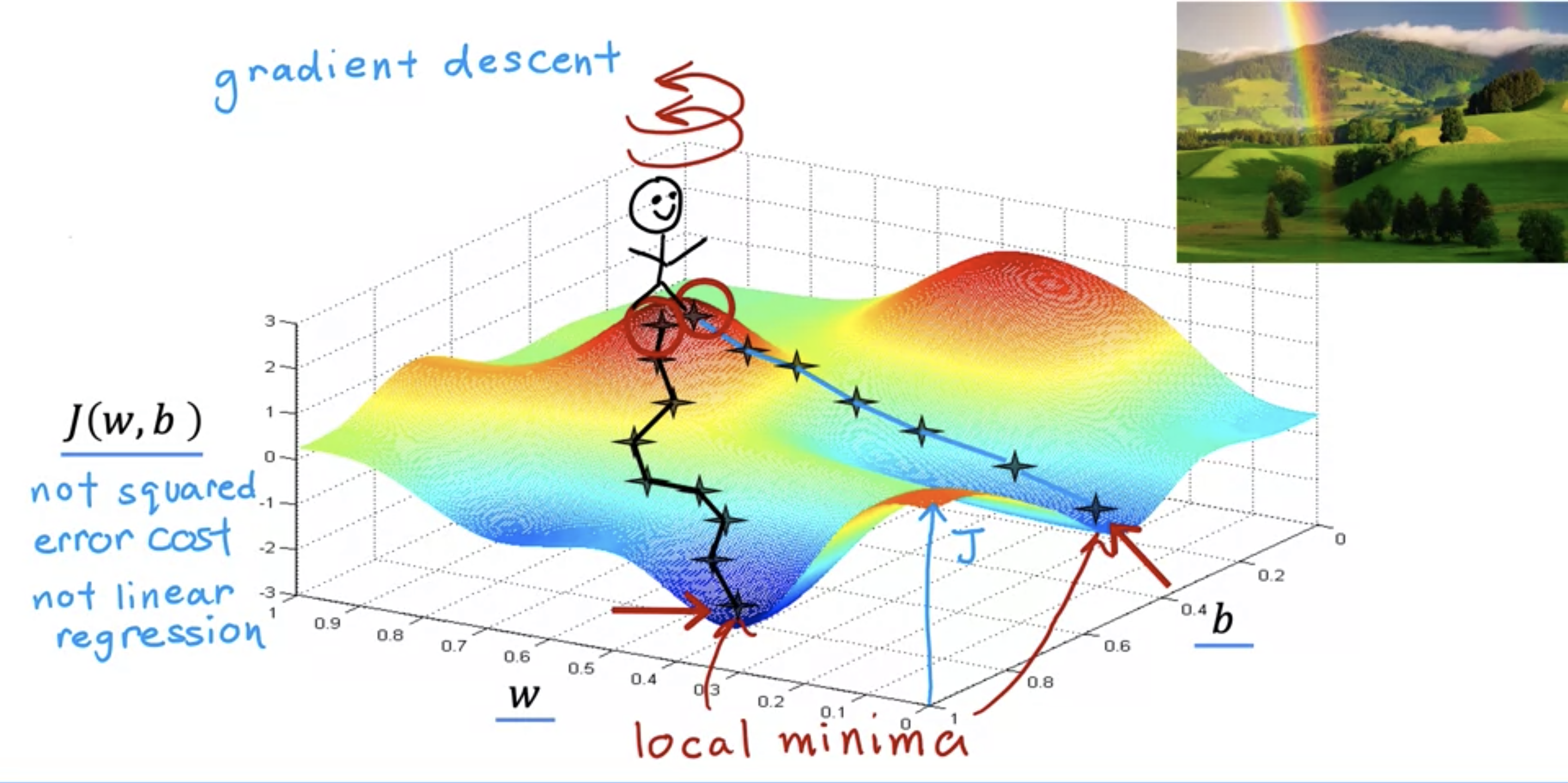
at a certain w and b value, take a 360 turn to look for the steepest descent.following the steepest descent after descent takes to the lowest valleys.
4.ML 4: Multiple Features
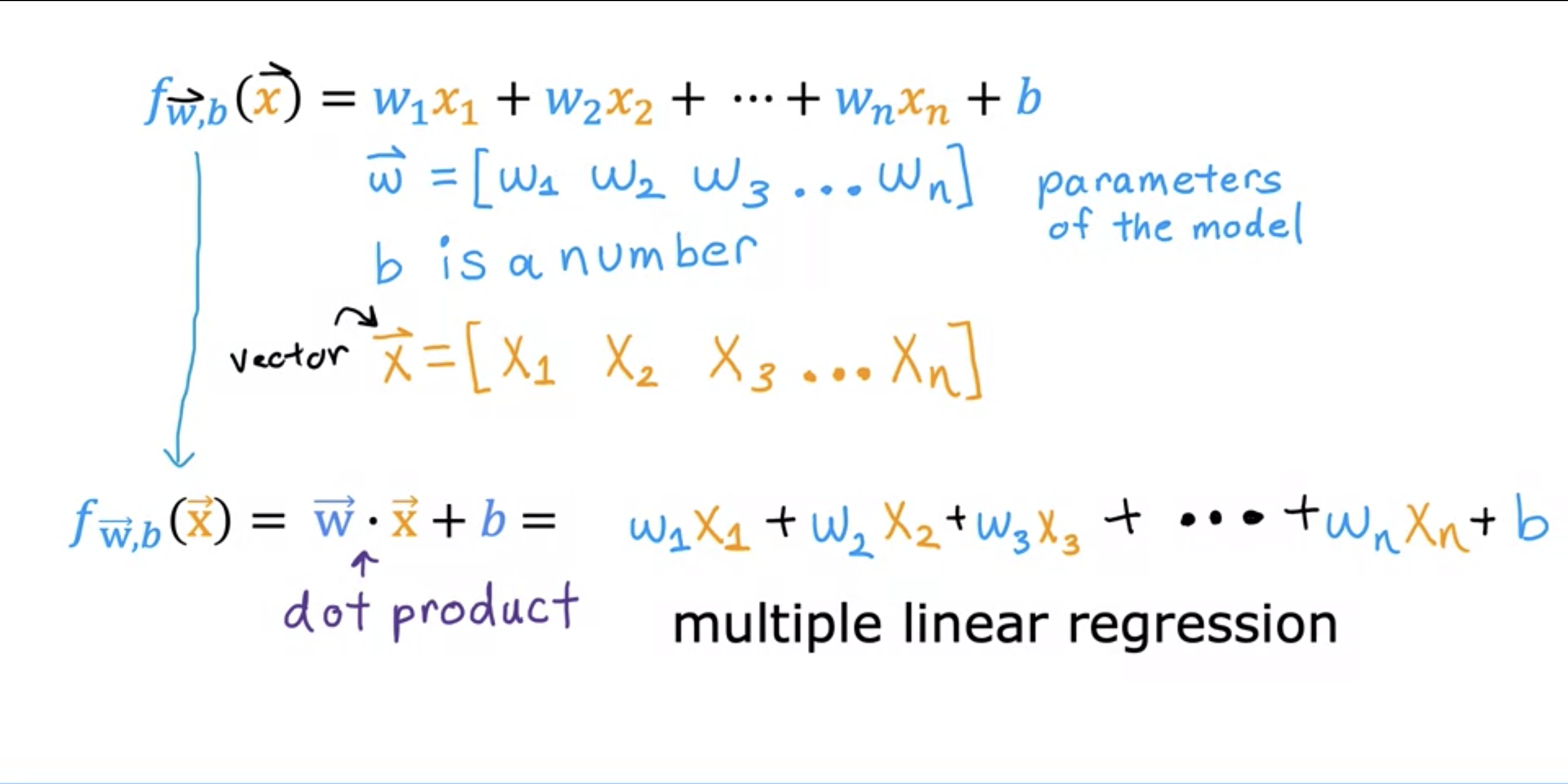
vector is just an array.dot product is multiplying by pair. multivariate regression refers to something else. subscript for the specific feature, supe
5.ML 5: Gradient Descent in Practice
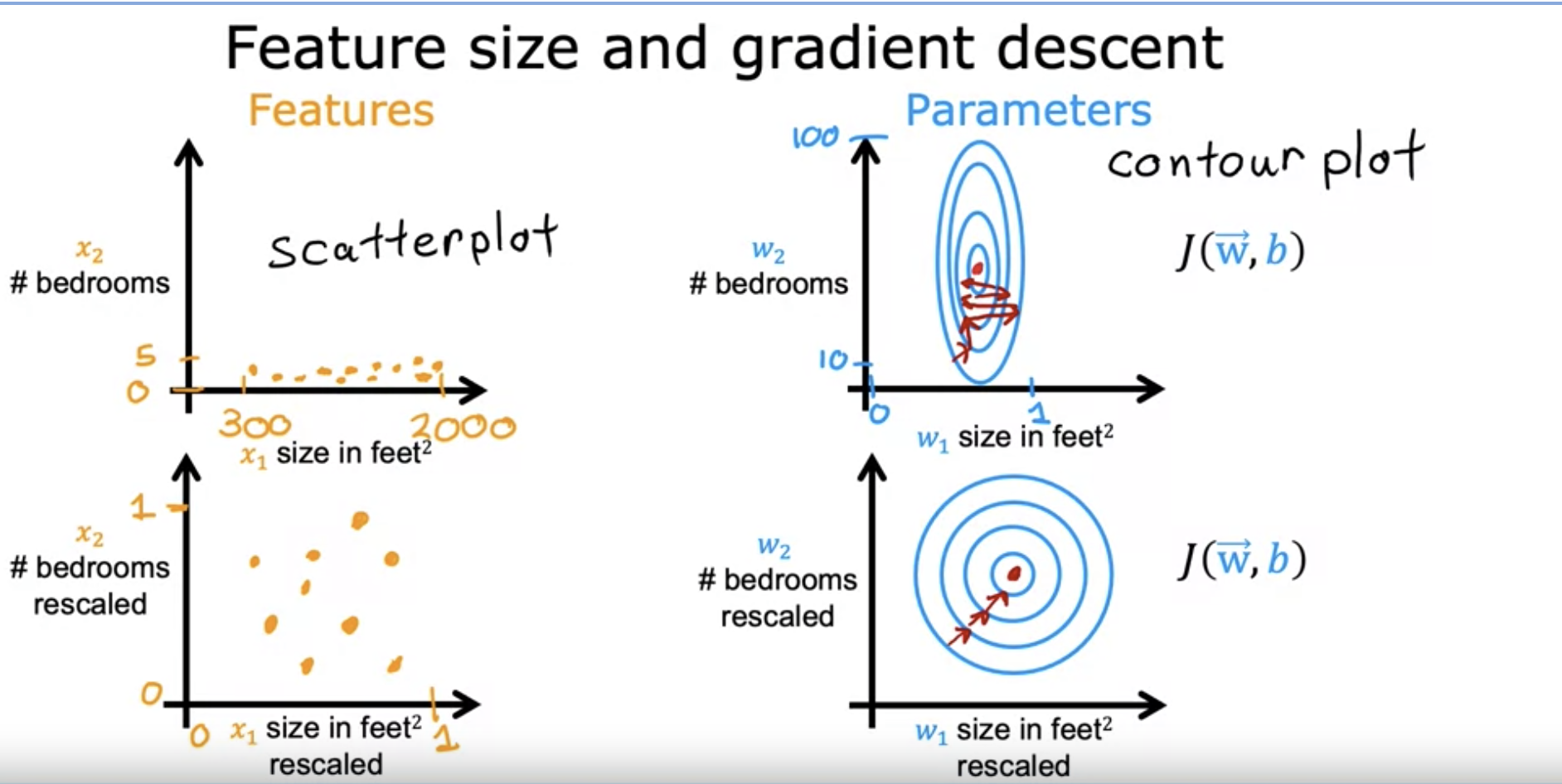
feature scaling is about rescaling the training set values to make gradient descent easier. Deviding the values by maximum possible value. Mean Normal
6.ML 6: Classification with Logistic Regression

Sigmoid function addresses the classification problem well.The output of logistic regression is the probability that class is 1 (positive). Above the
7.ML 7: Cost Function for Logistic Regression

The squared cost function for logistic regression shows many local minima, which is not ideal for gradient descent. The upper branch log function work
8.ML 8: Gradient Descent for Logistic Regression
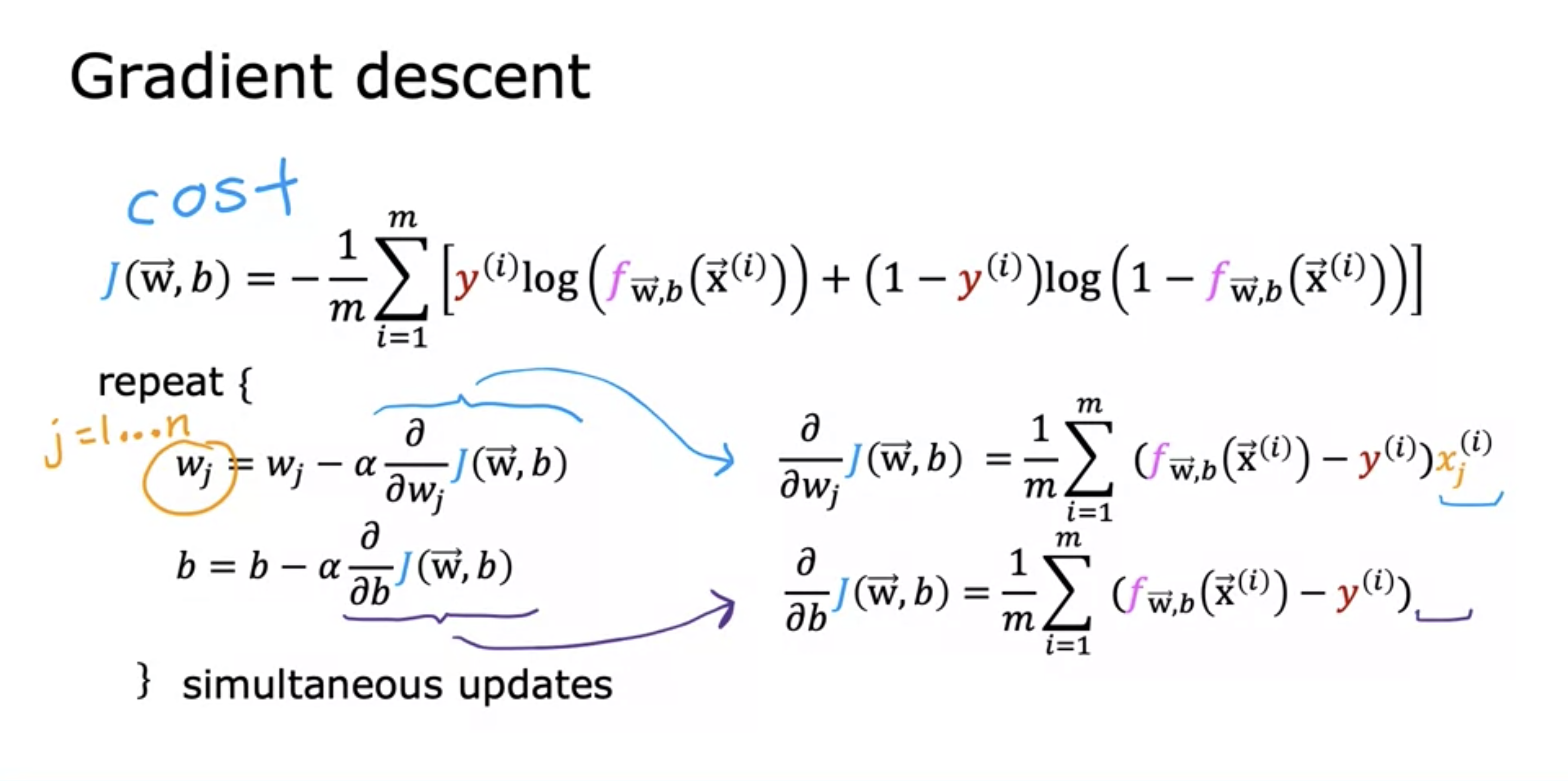
The formula for gradient descent for logistic regression is the same as that for linear regression. The base of the log could be e, which makes the de
9.ML 9: The Problem of Overfitting
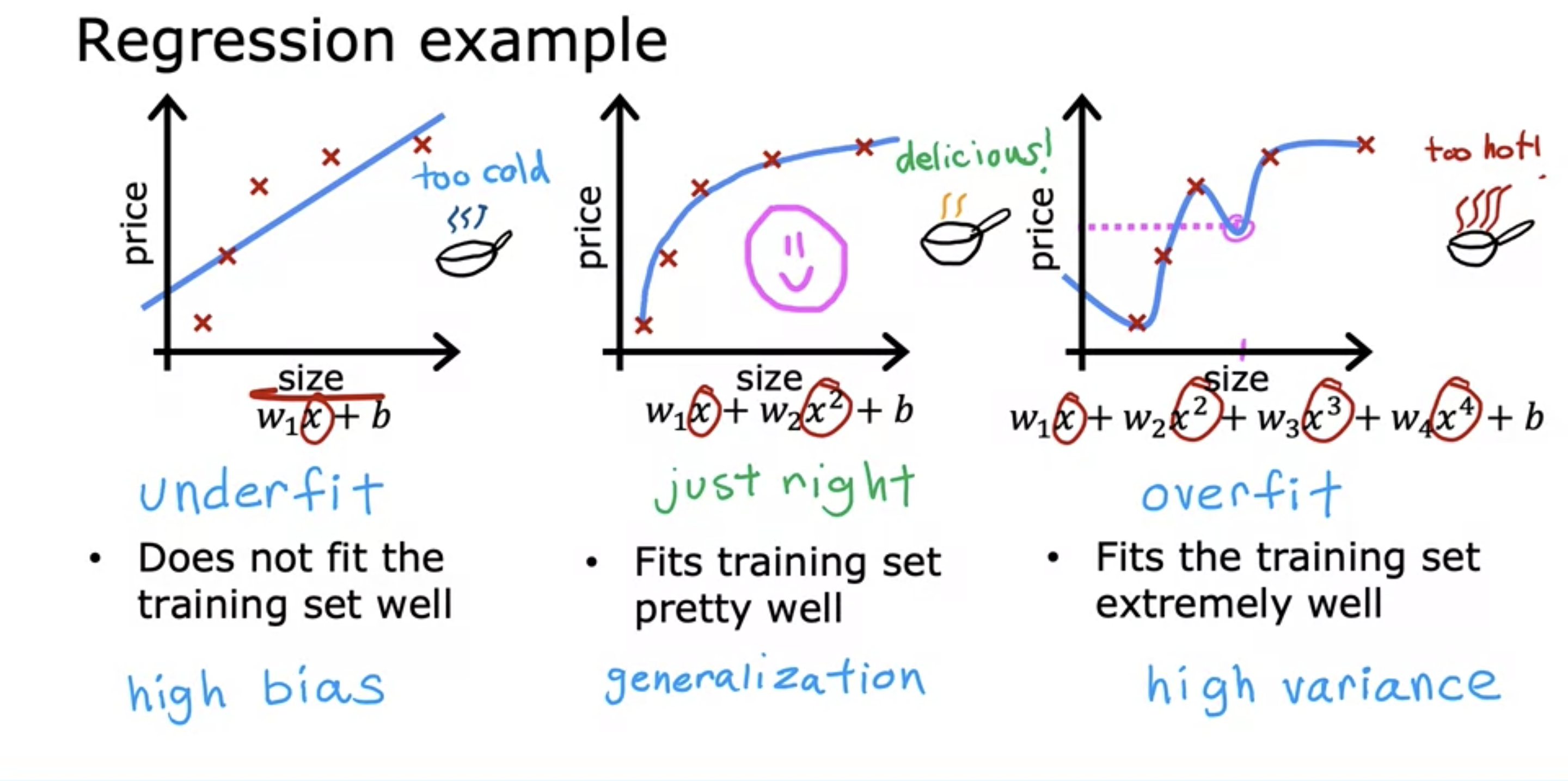
Underfit is when the model we came up with does not fit the data accurately because the model has high bias for certain model. Example above shows the
10.Advanced Learning Algorithms 1: Neural Networks
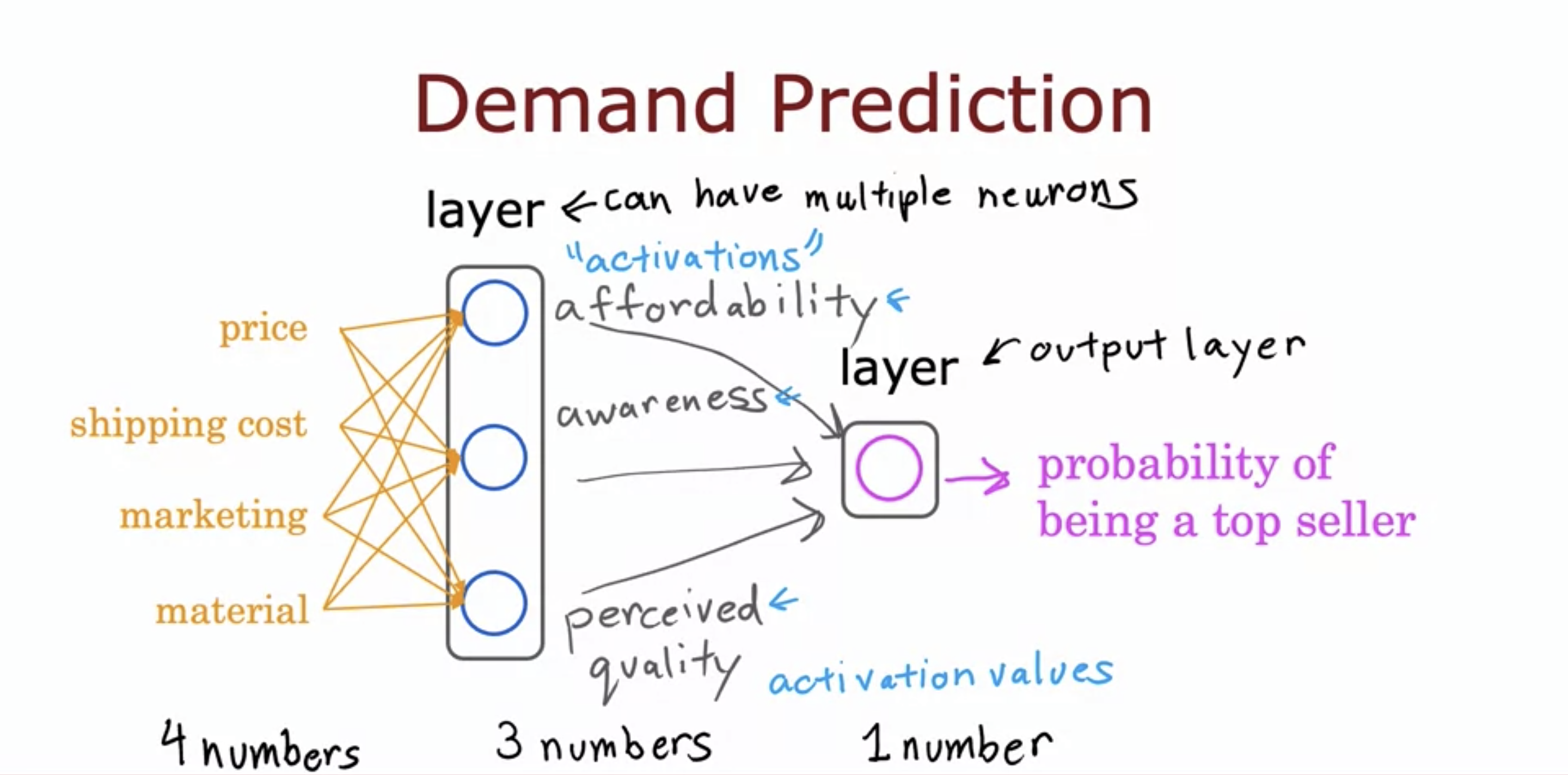
The features are combined to represent a factor that determines the output, which are then combined to output a single value. These factors are known
11.Advanced Learning Algorithms 2: Neural Network Model
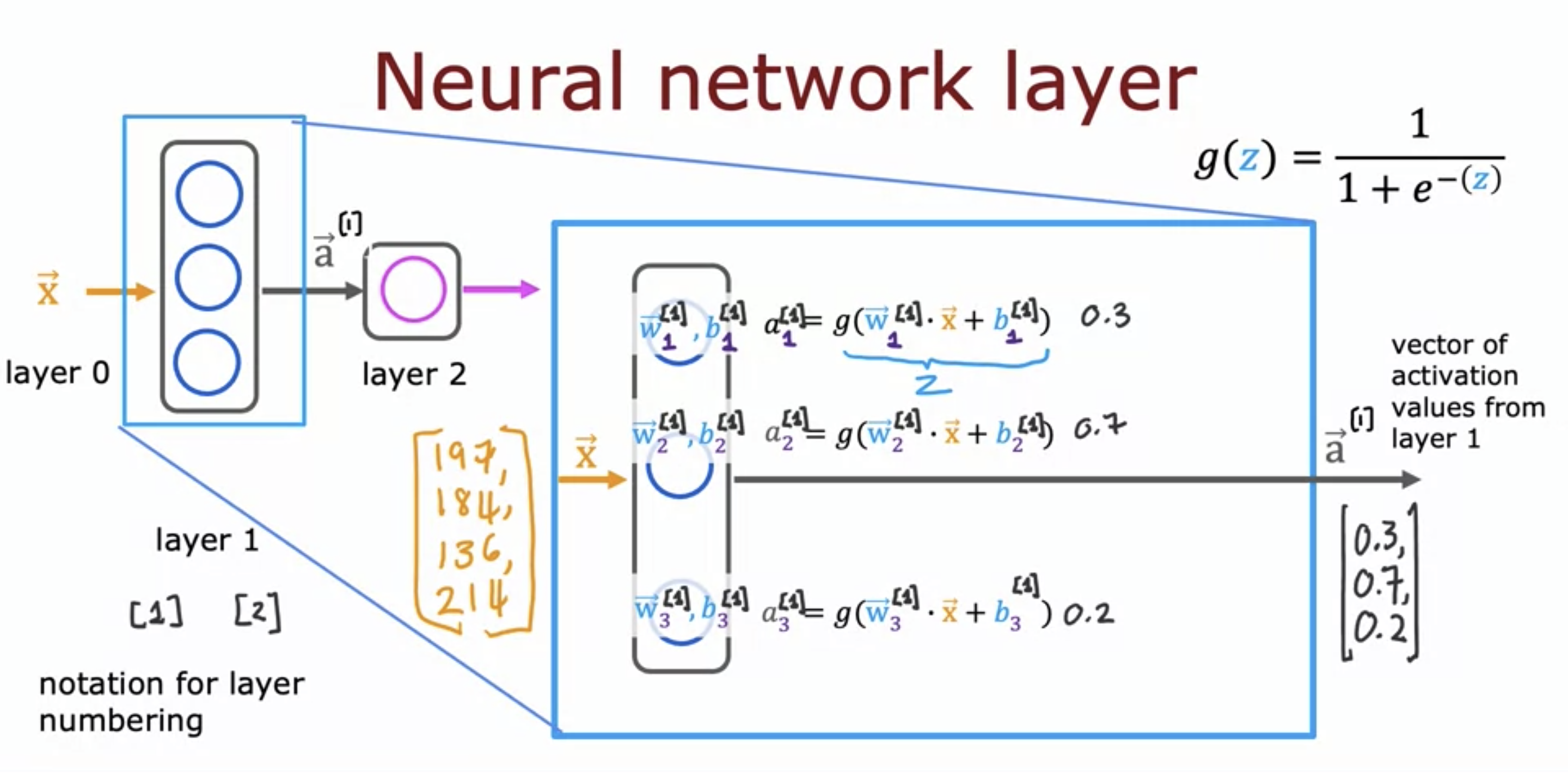
Each neuron is a logistic regression unit. The superscript with square brackets represent the n-th hidden layer. The input to layer 2 is the output fr
12.Advanced Learning Algorithm 3: Tensorflow Implementation
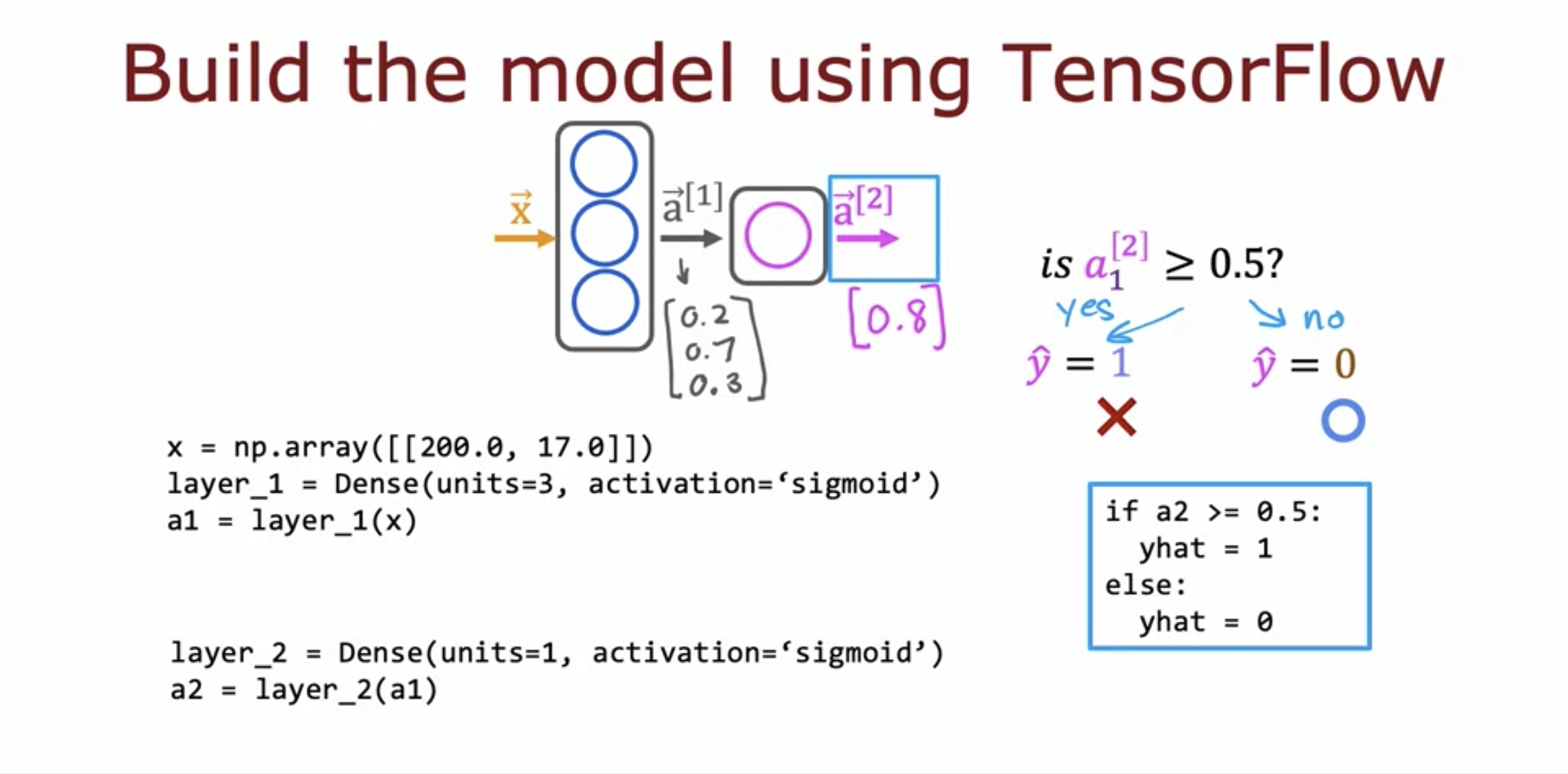
Dense to create a layer. row x column = 2D array / 2D Matrix2 columns for each feature. 3 units makes 1 x 3 matrix. Tensor is a data type that represe
13.Advanced Learning Algorithms 4: Speculations on AGI

AGI refers to making an AI that does anything a human can do. What is the "algorithm" that is used to train our brain from seeing with our eyes to s
14.Advanced Learning Algorithms 4: Speculations on AGI
AGI refers to making an AI that does anything a human can do. What is the "algorithm" that is used to train our brain from seeing with our eyes to s
15.Advanced Learning Algorithm 5: Vectorization

matmul to perform matrix multiplication.
16.Advanced Learning Algorithm 7: Tensorflow and Keras
Tensorflow and KerasTensorflow is a machine learning package developed by Google. In 2019, Google integrated Keras into Tensorflow and released Tensor
17.Advanced Learning Algorithm 8: Neural Network Training
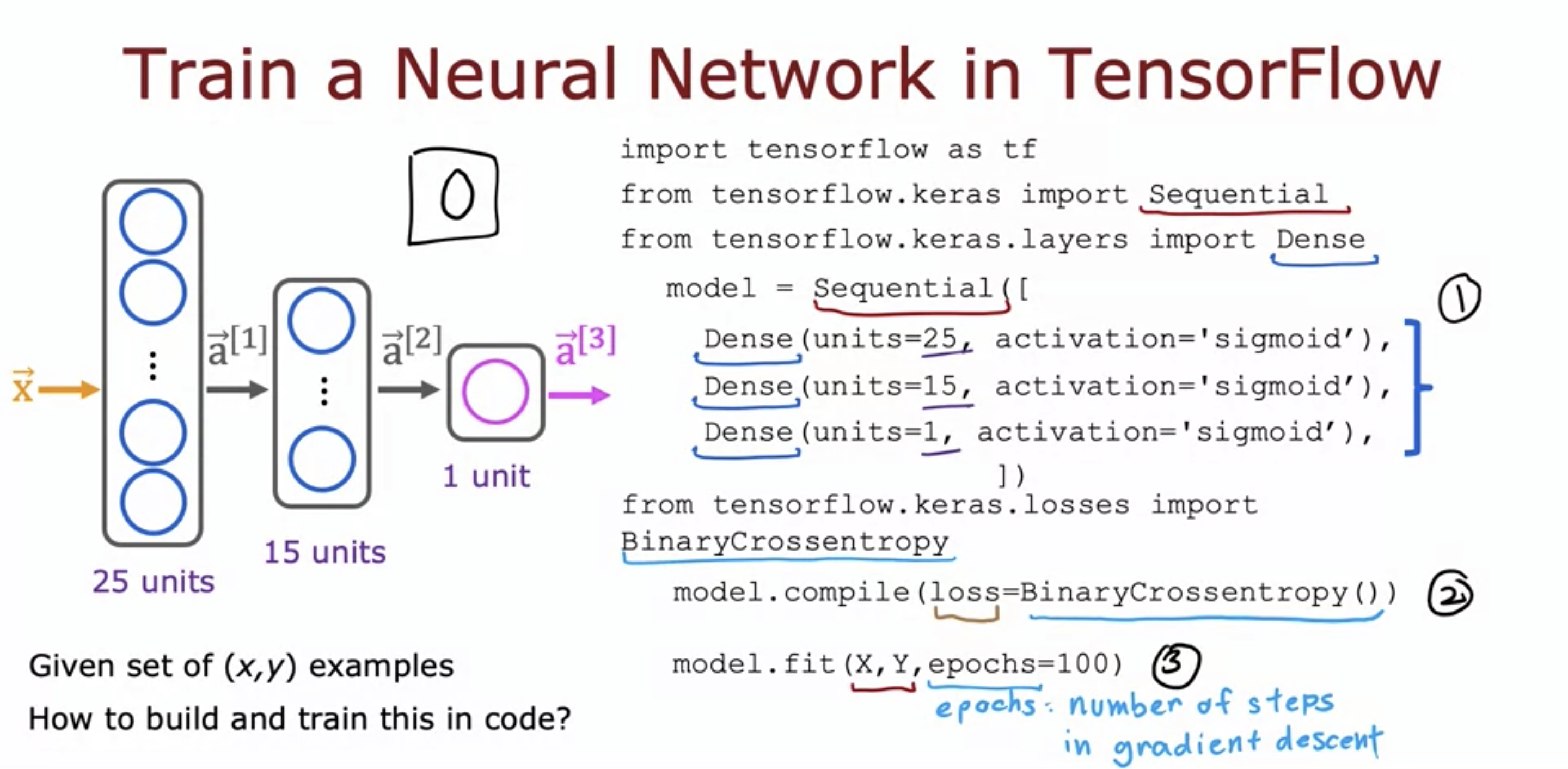
Binary Cross Entropy is another name for logistic loss function. The name originates from statistics - it is the name for that function. Binary becaus
18.Advanced Learning Algorithm 9: Activation Functions
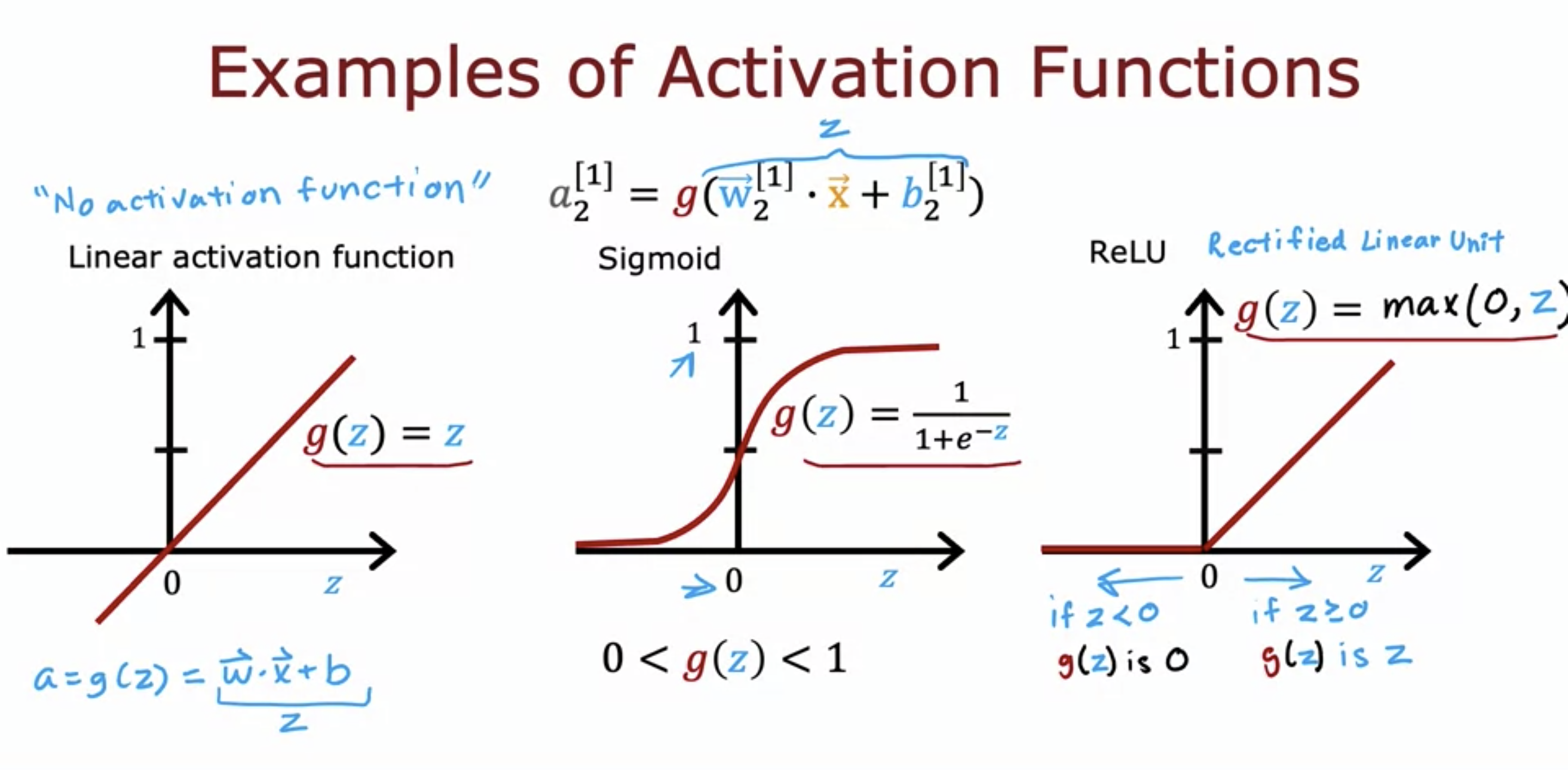
Linear Activation function - aka no activation function, just a straight line. ReLU stands for Rectified Linear Unitfor hidden layers, we use ReLU ins
19.Advanced Learning Algorithm 10: Multiclass Classification
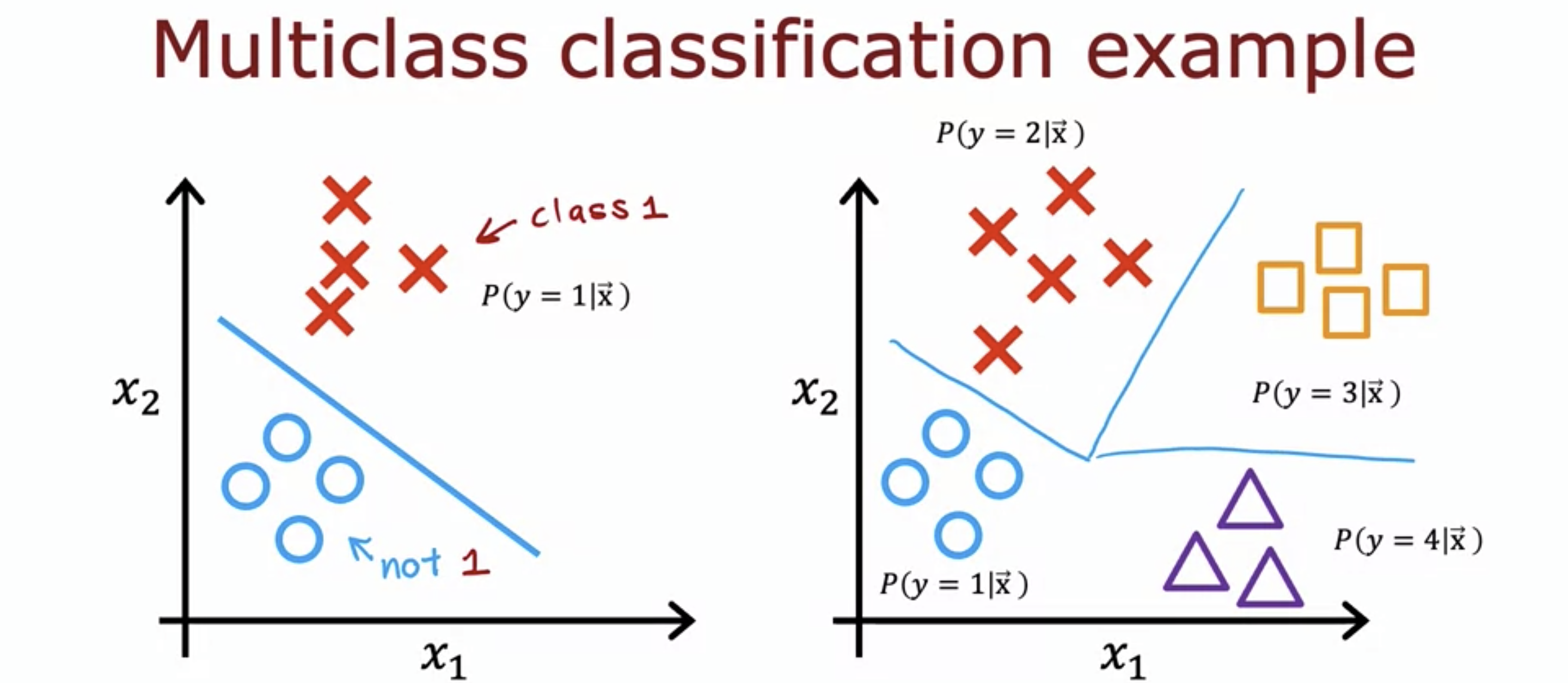
No more binary classification, now more categories.
20.Advanced Learning Algorithms 11: Additional Neural Network Concepts

Adam optimizer for faster gradient descent. If w_j (or b) keeps moving in the same direction, we increase the learning rate a_j. If w_j (or b) keeps o
21.Advanced Learning Algorithm 12: Back Propagation

Back propagation is basically a process to find a relationship between cost J function and the parameters. It works its way backwards from the result,
22.Advanced Learning Algorithm 13: Advice for Applying Machine Learning

1. Evaluating a Model 1-1. Motivation If there is only one feature, it is possible to plot the model and see if the model is overfitting or underfitt
23.Advanced Learning Algorithm 14: Bias and Variance
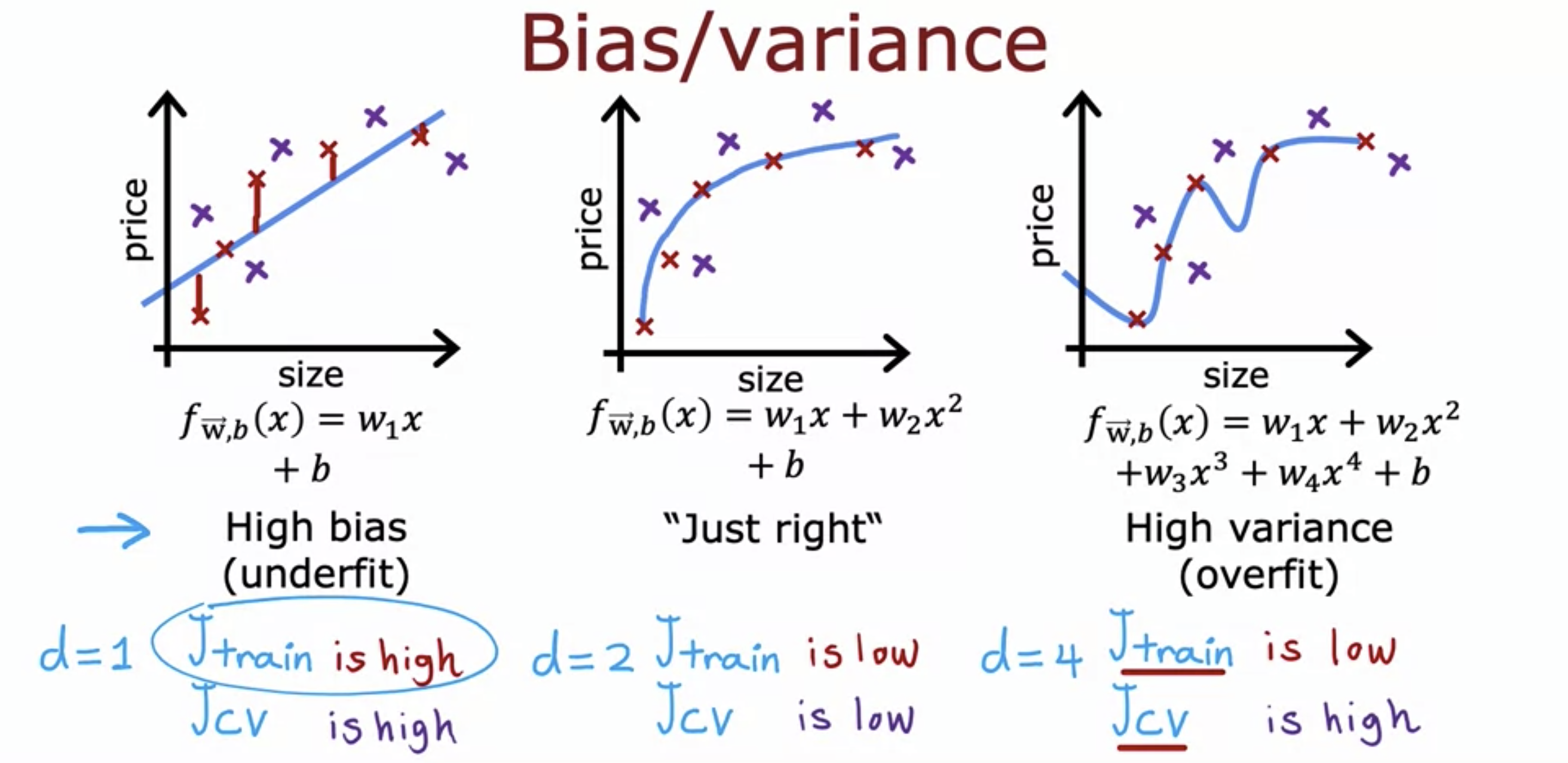
High bias means the model is too simple to capture the complexity of the underlying data. Both J_train() and J_cv() are high. High variance means the
24.Advanced Learning Algorithm 15: Machine Learning Development Process

1. Iterative Loop of ML Development Choosing an architecture: ML model, what data to use, what hyperparameters, etc. Training model: Training model w
25.Advanced Learning Algorithm 16: Decision Trees
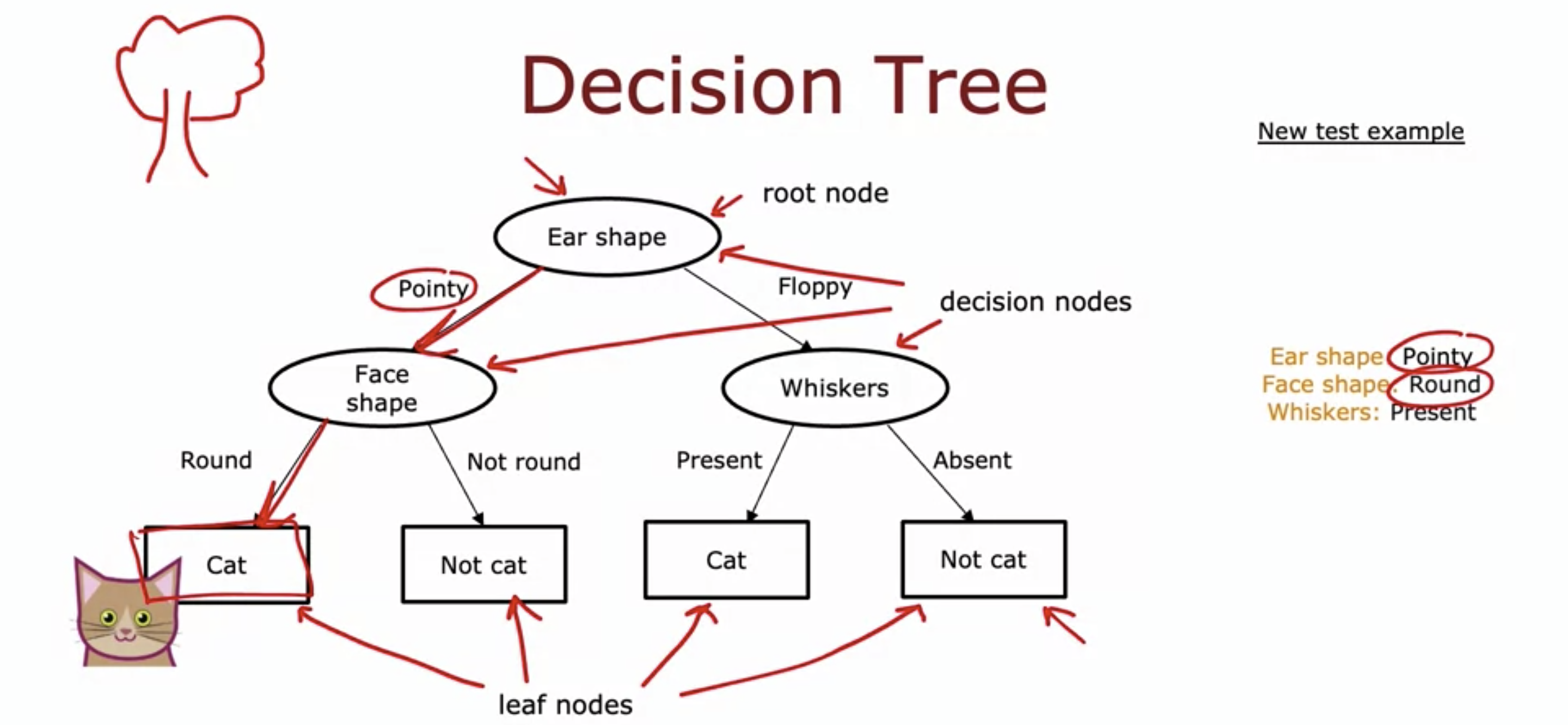
Root node, decision node, and leaf node. A training example goes down the tree and is classified whether it is a cat or not a cat. Depending on which
26.Advanced Learning Algorithm 16: Decision Tree Learning

The entropy function (denoted by H(p1), where p1 is the fraction of examples that are cats in this case) can be a measure of purity in one batch of ex
27.Advanced Learning Algorithm 17: Tree Ensembles

Tree ensembles can make the algorithm more robust and less sensitive. Just having one decision tree makes the algorithm very sensitive to changes.As s