1. Using multiple decision trees
- Tree ensembles can make the algorithm more robust and less sensitive.

- Just having one decision tree makes the algorithm very sensitive to changes.
- As seen in the image above, if that squared cat changes to a floppy ear cat, then the best node changes from ear shape to whiskers.
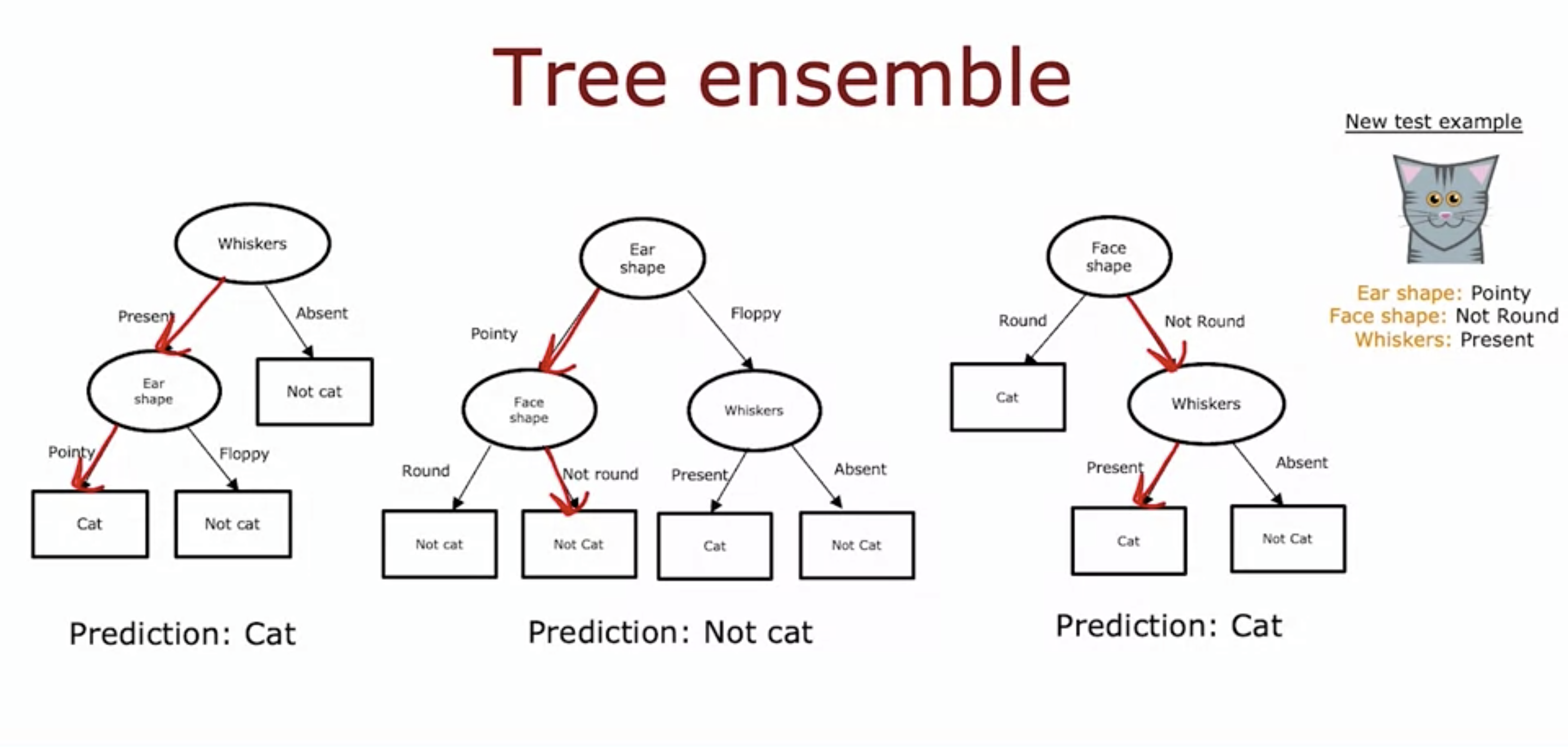
- By having more than 1 decision tree and making them all vote whether the test example is a cat, we can make our algorithm more robust and less sensitive to changes.
2. Sampling with replacement
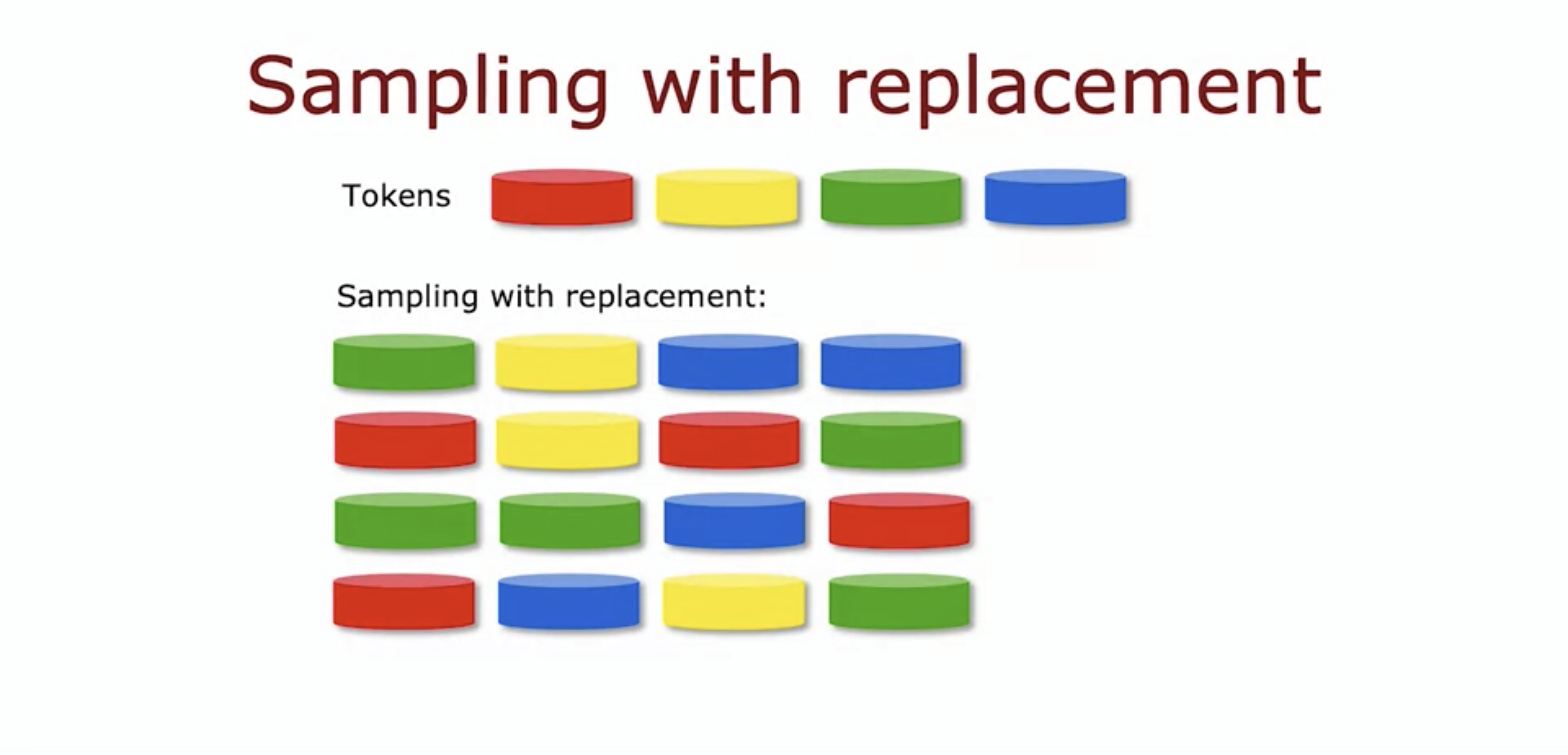
- Sampling with replacement mean we don't get rid of the sample after pulling out of the bag.
- This makes the data set different each time it is pulled out.
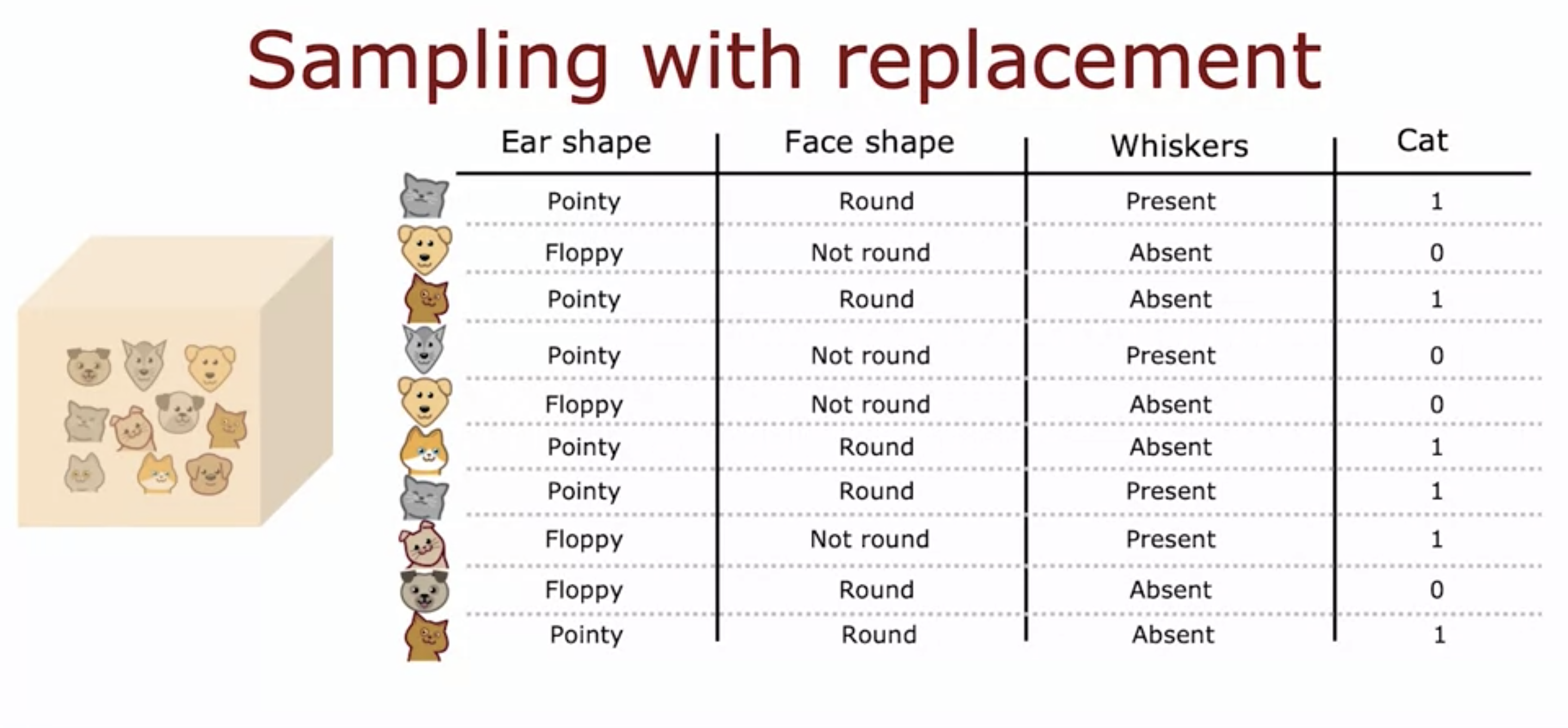
- In the example of cats and dogs, it is worth noting that the same cat or dogs can be sampled multiple times.
- Sampling with replacement allows creating data set that is somewhat similar to but different from the previous data set.
- This comes important when it comes to creating tree ensembles.
3. Random Forest Algorithm
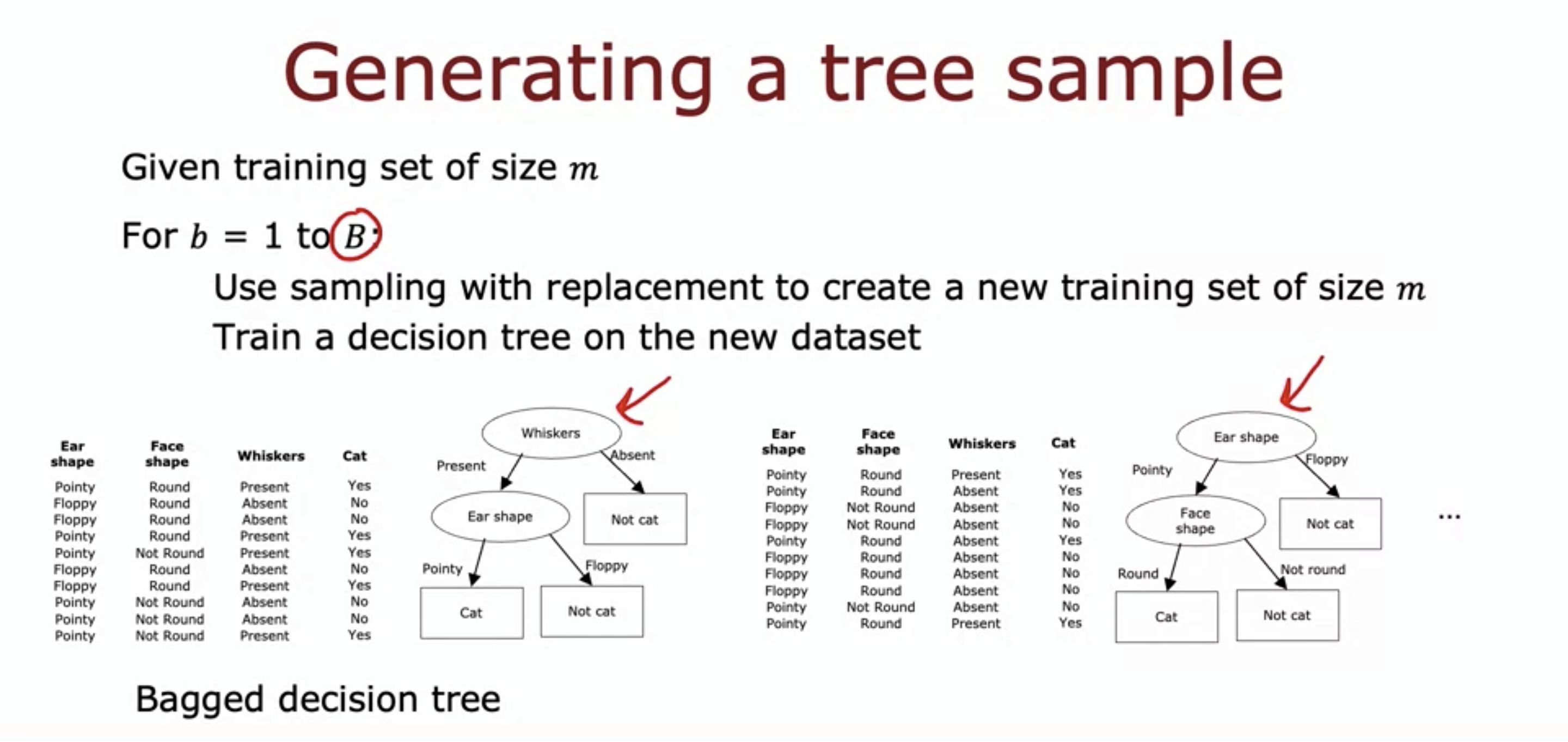
- If there are 10 training examples, we would sample the 10 training examples without replacement.
- This would make some examples repeated, but it is still ok.
- We would do this B times, where B is typically around 100.
- Key idea: even with this sampling method, we would very often end up with the same split node on the root node.

- Another modification to the algorithm is to choose features randomly at each node without replacement.
- This would help creating more diverse set of trees, each with different nodes of features.
- A feature is selected in the subset of k < n number of features, where n is the total number of features.
- Typical number of K is square root of n.
- This algorithm of creating random forest (tree ensemble) by generating random training examples and randomizing features is known as random forest algorithm.
- I am guessing it is called the forest because of lots of trees?
4. XGBoost

- Every time a new tree is created, we would increase the chance of selecting training example that previous trees have predicted poorly on.
- This is an idea of deliberate practice - for example, when you are practicing a piano piece, you would focus on practicing mainly the parts that I am not doing well.
- For B number of trees, Bth tree will have training examples that tree 1, 2, ... n - 1 did poorly on.

- XGBoost algorithm is a widely used one for the purpose.

- The implementation is as above.
5. When to use decision trees

- Decision trees work well on structured data, neural networks work well on unstructured data.
- Decision trees learn fast, neural don't but they can be faster by using transfer learning.

everything happens for a reason