1. Alternatives to Sigmoid Function
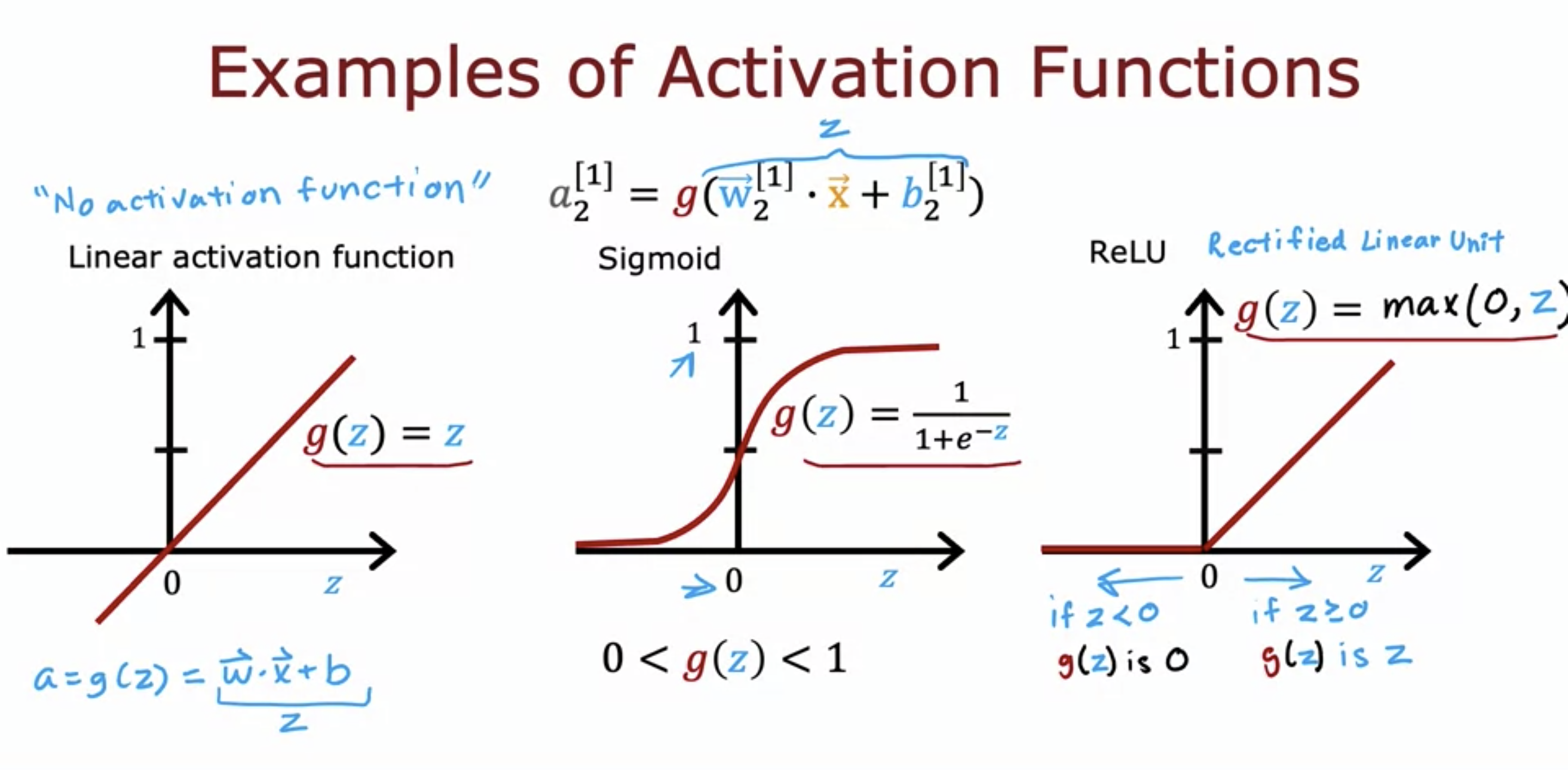
- Linear Activation function - aka no activation function, just a straight line.
- ReLU stands for Rectified Linear Unit
2. Choosing Activation Functions
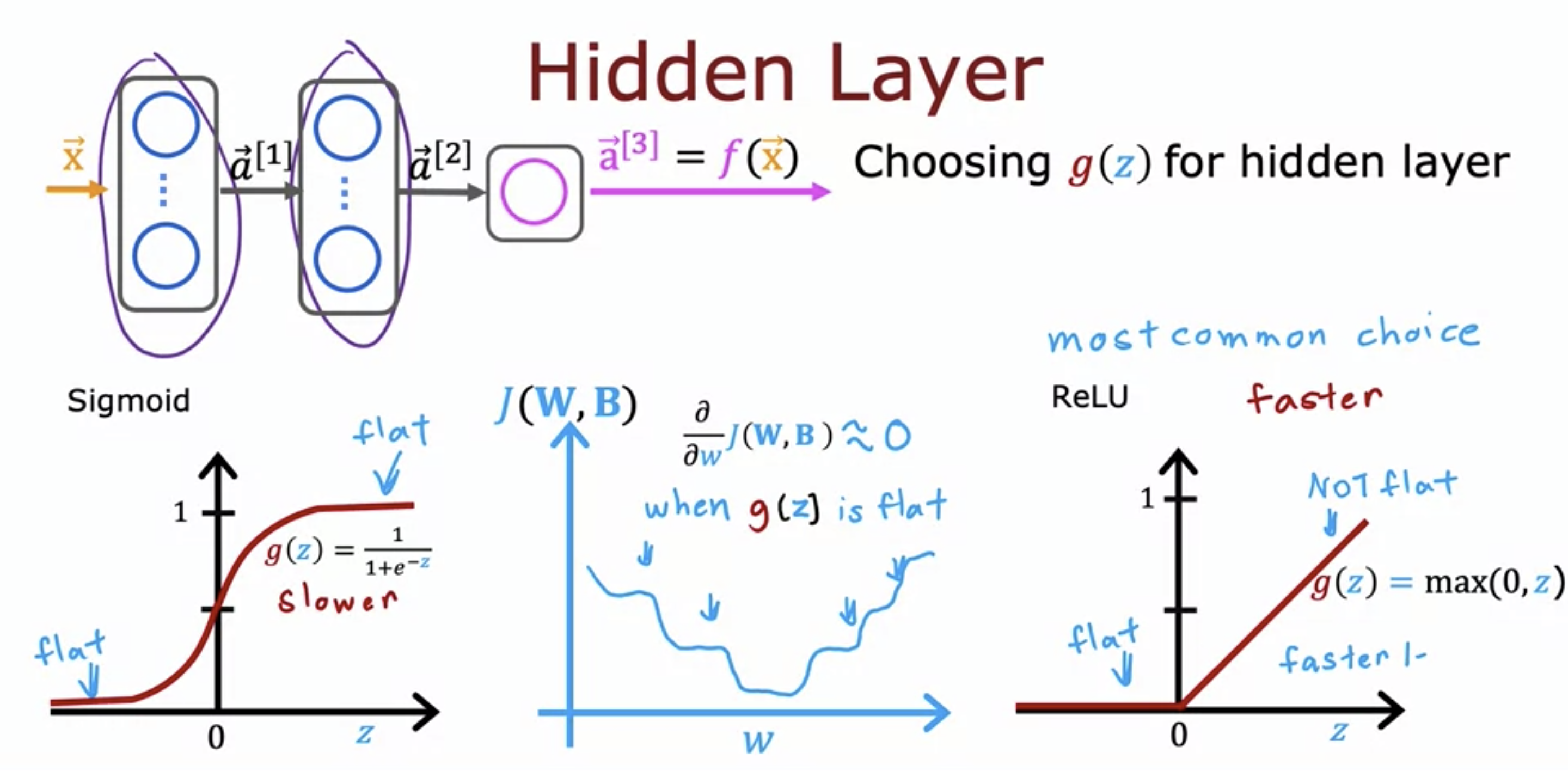
- for hidden layers, we use ReLU instead of sigmoid.
- Sigmoid computation takes longer.
- Because of 2 flatted parts in sigmoid, gradient descent may take longer.
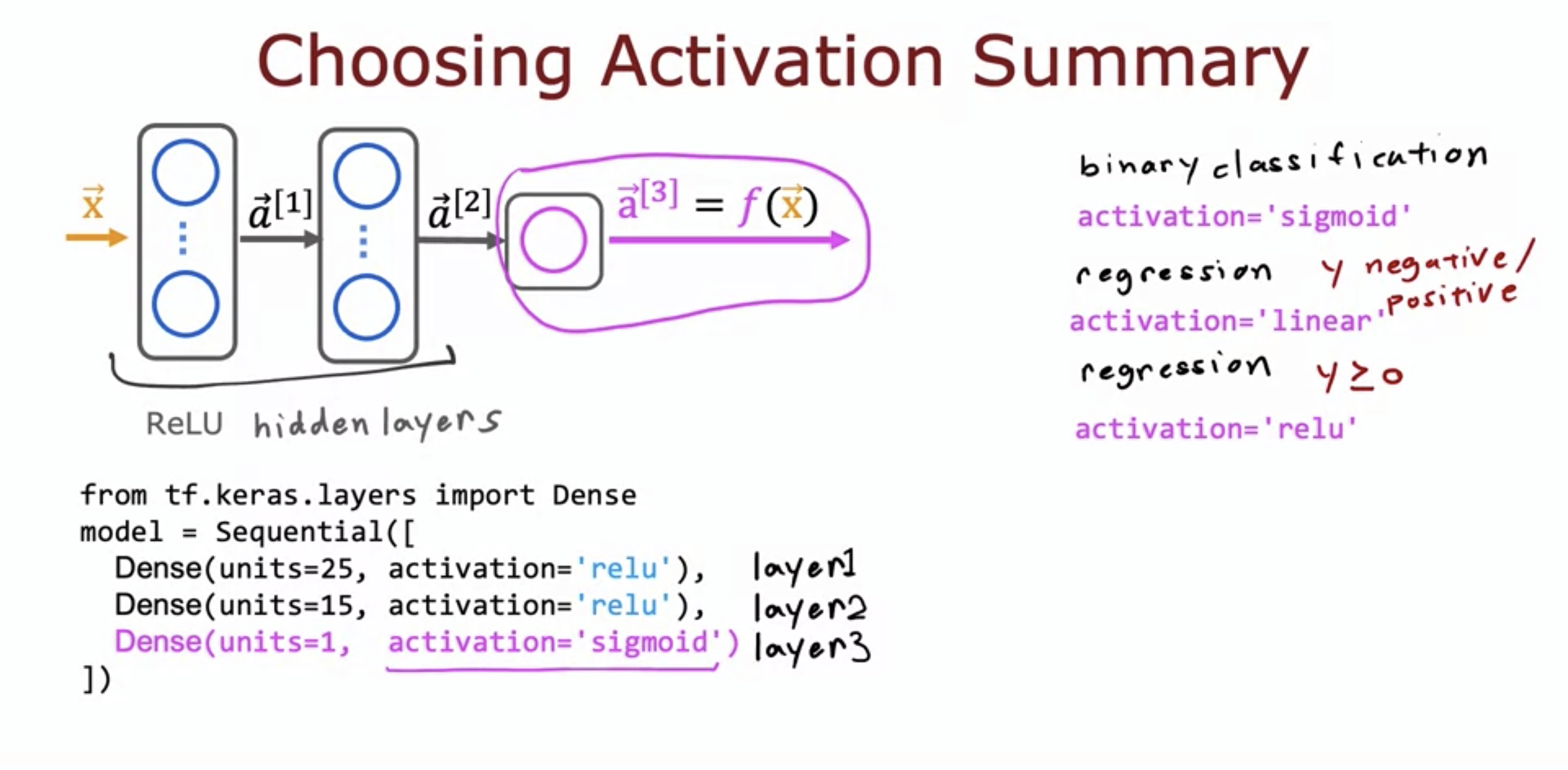
- Because of 2 flatted parts in sigmoid, gradient descent may take longer.
- Sigmoid for binary classification,
- Linear for y = - or + regression,
- ReLU for y >= 0 regression.
3. Why do we need activation functions?
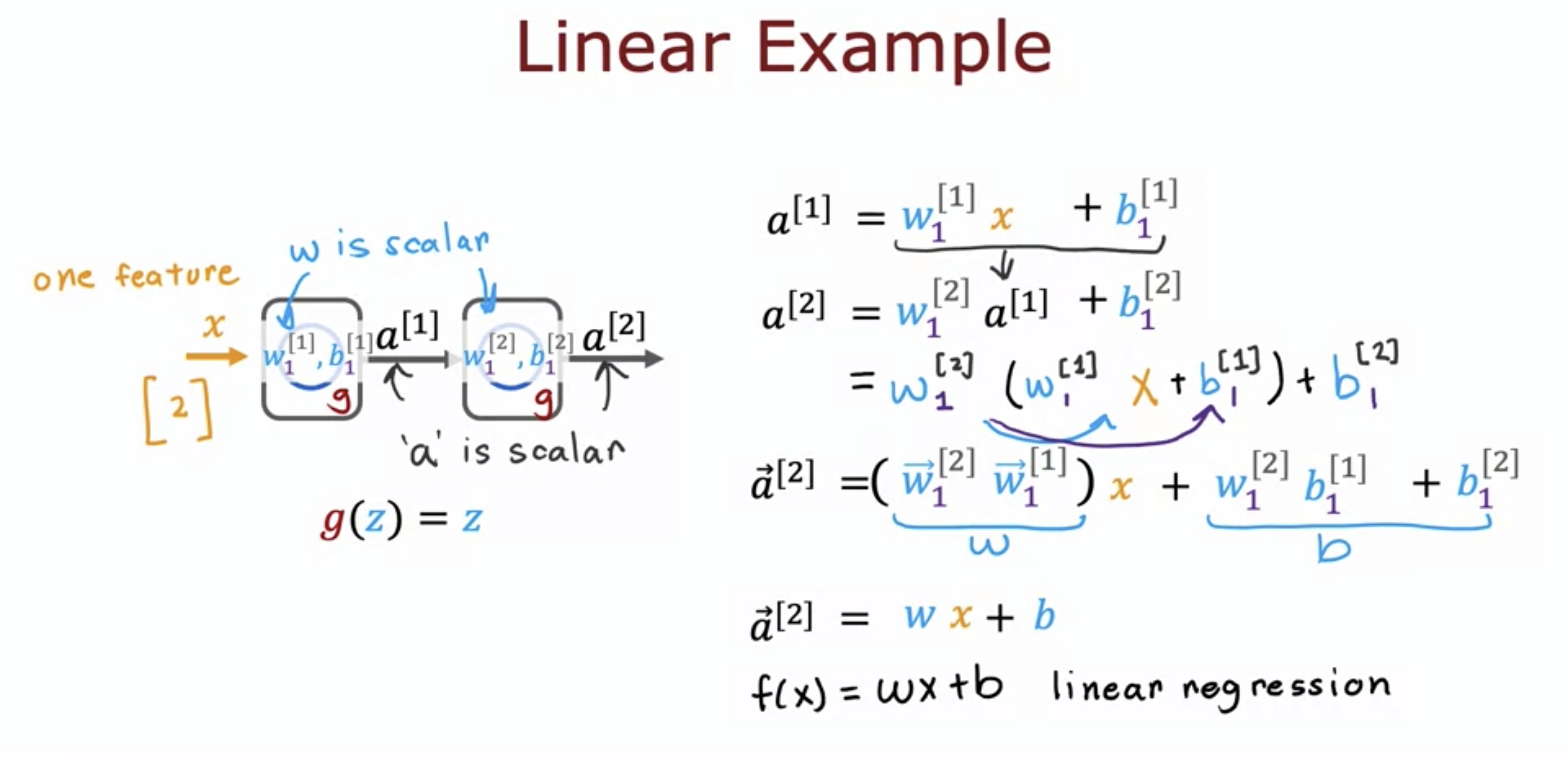
- linear function of linear function is still a linear function.
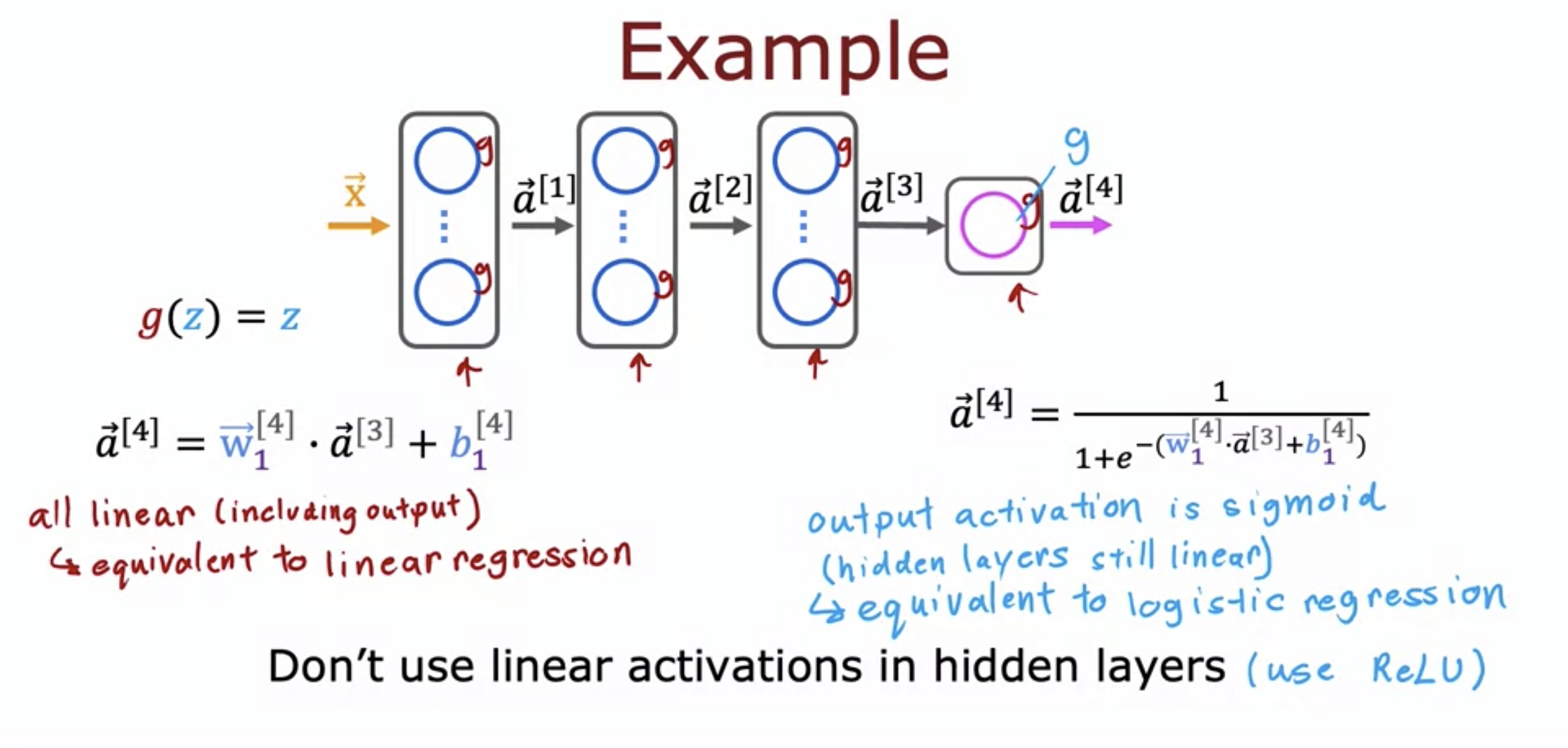
- Let's say hidden layer units are all linear.
- Even if the last output unit is sigmoid, the neural network cannot do what logistic regression model cannot do.
- Using linear activation function defeats the purpose of using neural network.

everything happens for a reason