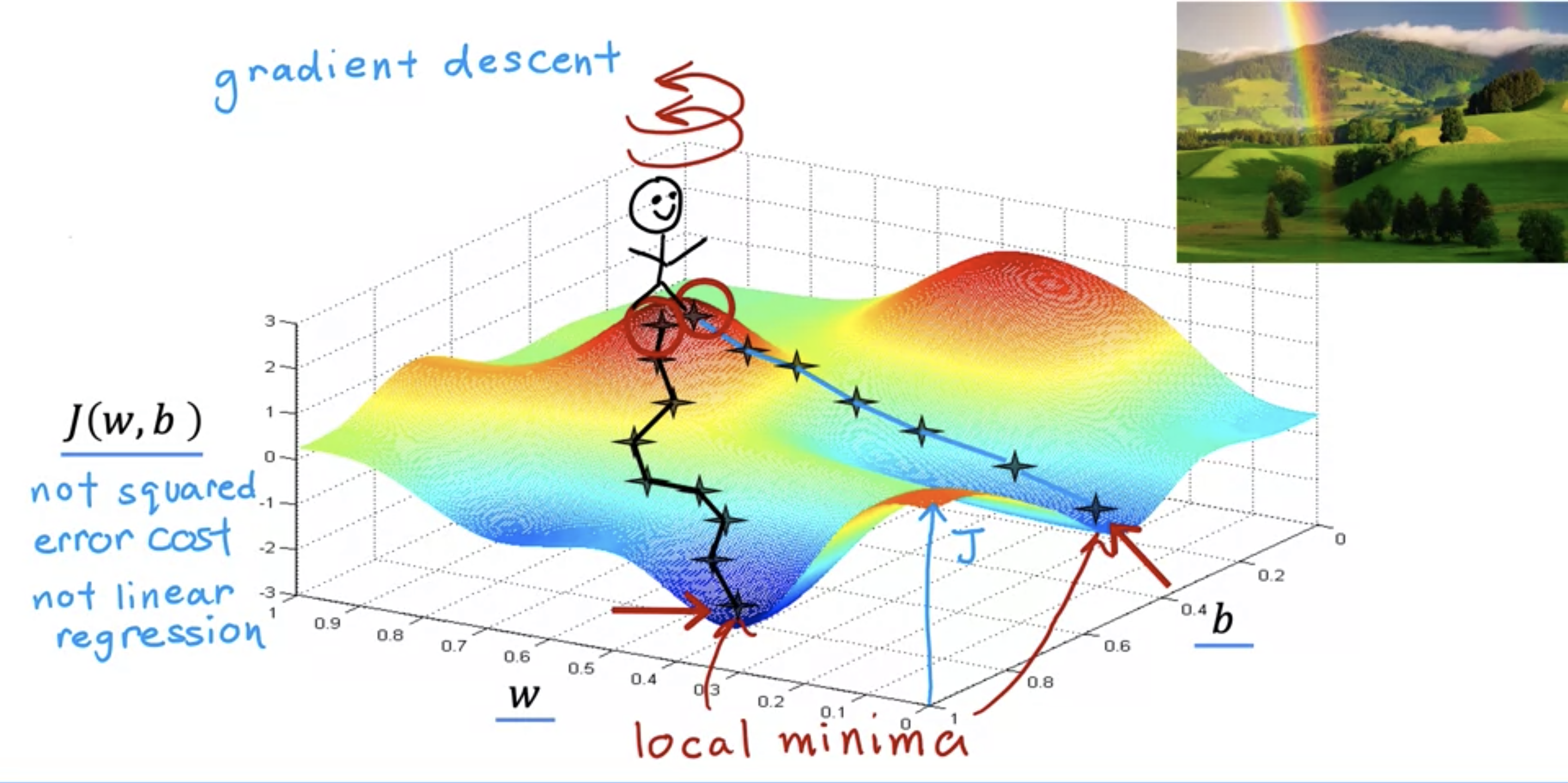
- at a certain w and b value, take a 360 turn to look for the steepest descent.
- following the steepest descent after descent takes to the lowest valleys.
- there could be multiples of valleys: known as local minima.
Gradient Descent Formula

- alpha: learning rate, a number from 0 to 1.
- updates w and b value little by little
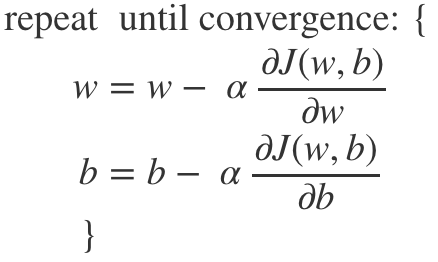
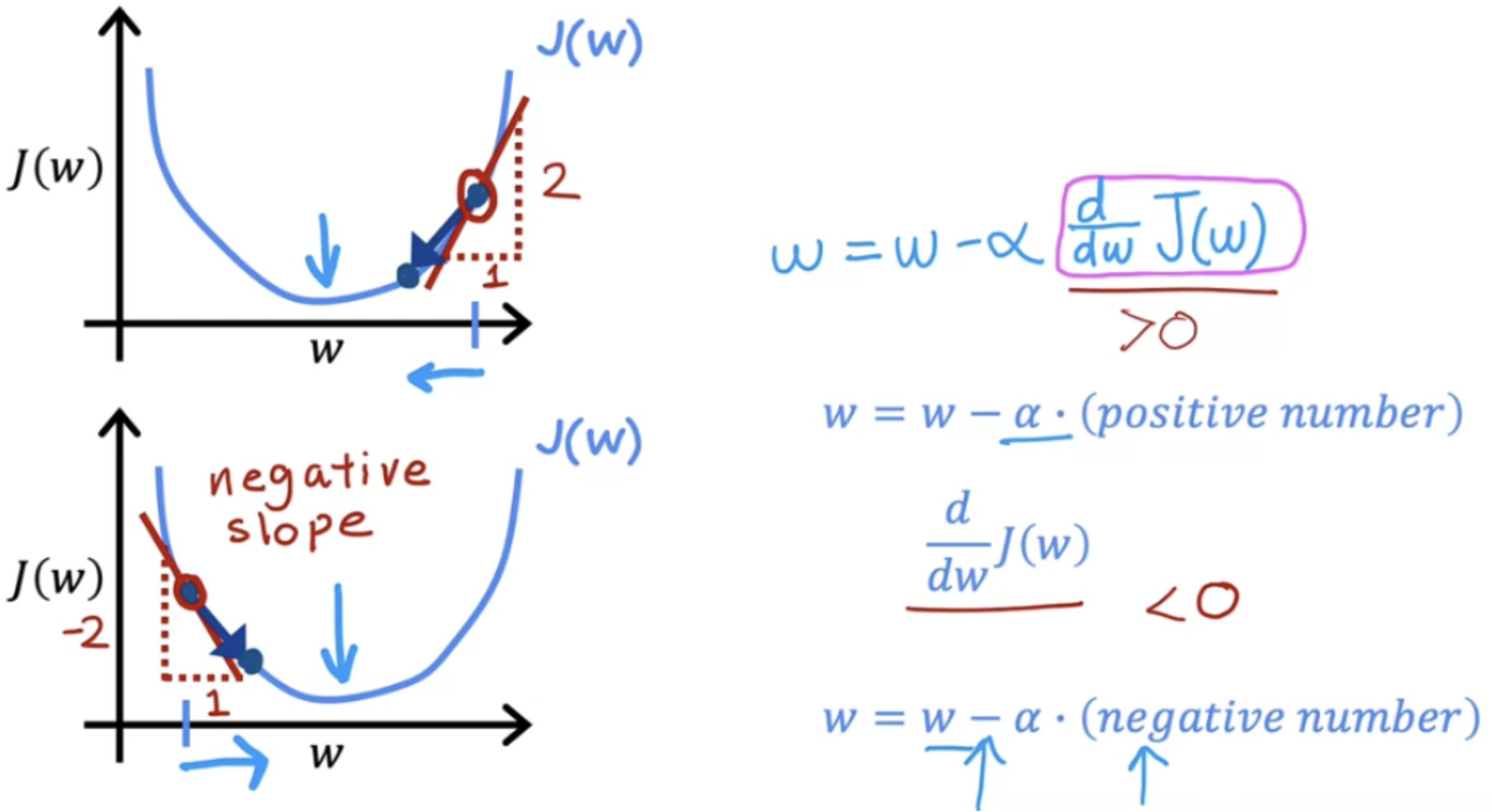
Deriving Linear Regression Cost Function Derivatives
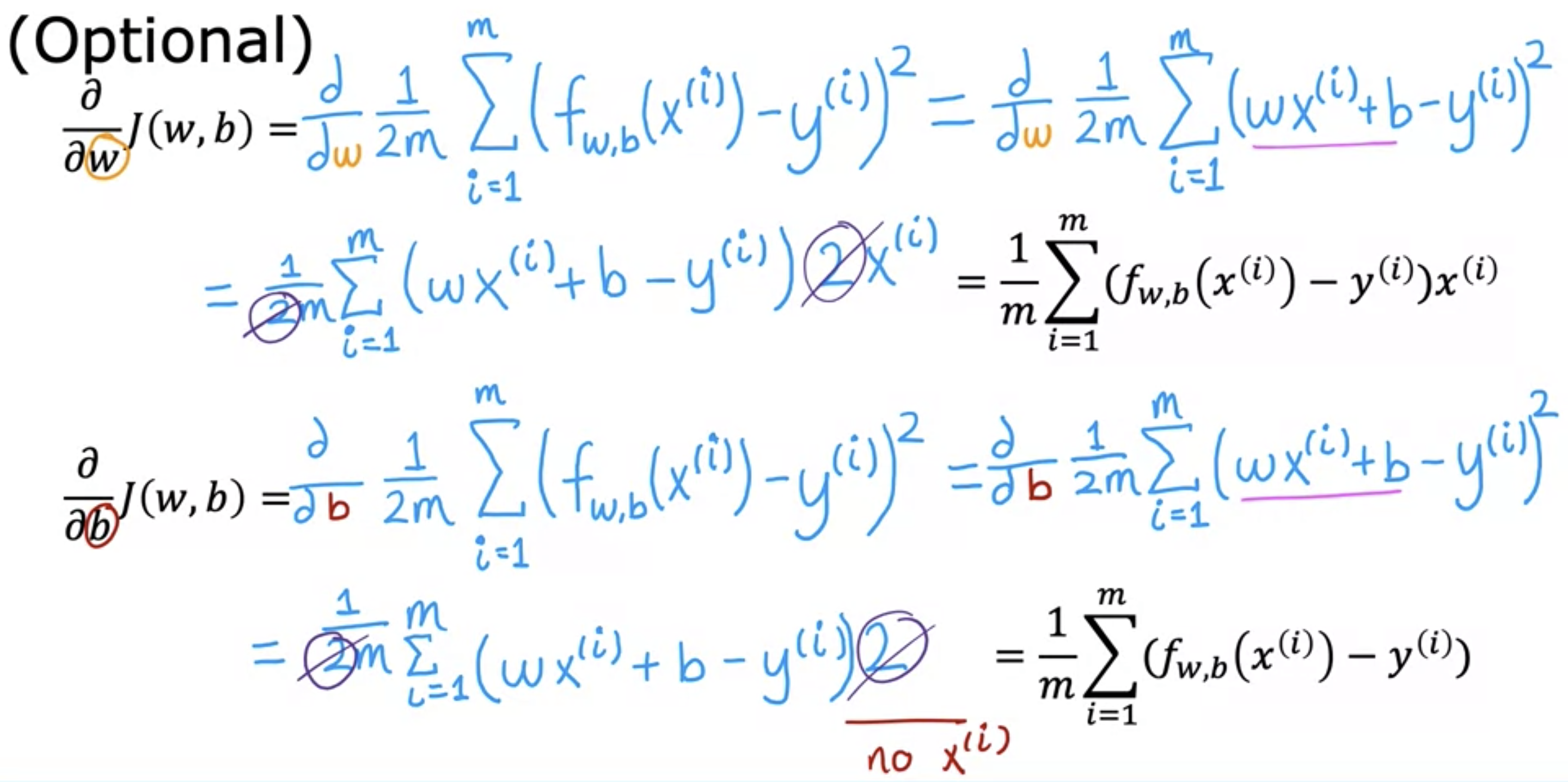
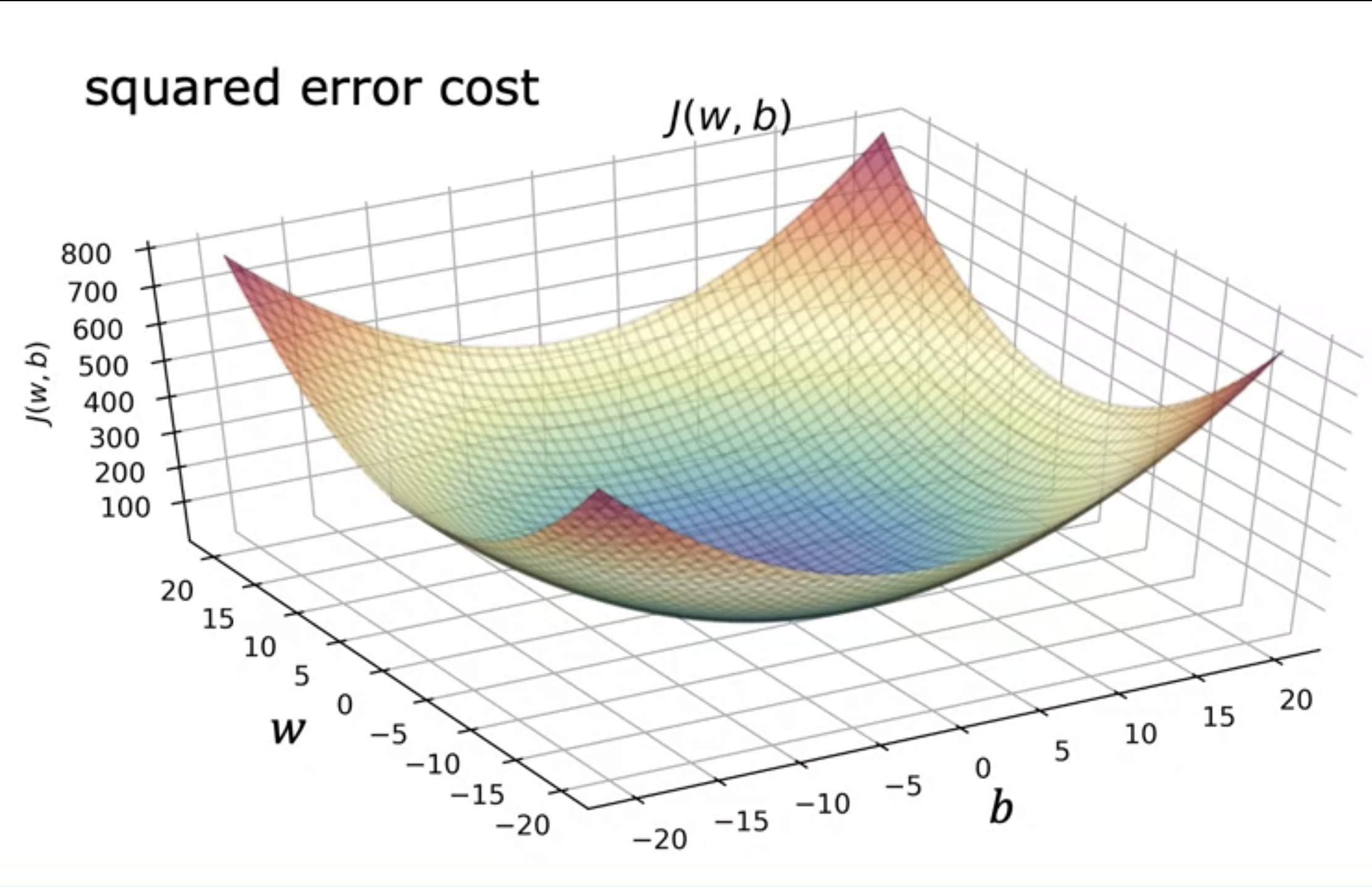
- Squared error cost for linear regression is always a convex function.
- it always has one global minimum.

- Looks at all training examples:
- Each gradient descent step computes J(w,b) value, which is an average of sum of squared errors. This is calcuated by using every training examples by formula.

everything happens for a reason