Learning Transferable Visual Models From Natural Language Supervision
0. Abstract
computer vision system은 정해진 범주의 객체를 가지고 학습을 진행하는 것이 일반적이지만 이러한 학습 방법은 모델의 일반성을 떨어뜨릴 뿐더러, 새로운 class의 data를 모델 추가적으로 명시해야한다는 문제점이 존재한다.
이러한 문제를 해결하고자, 본 논문에서는 인터넷에서 수집한 400M의 (image, text) pair dataset을 구축하여 caption을 통해 image를 학습하는 pre-training method를 제시한다. pre-training 이후 자연어는 학습된 시각적 개념을 참고하는데 사용되어 downstream task로 zero-shot transfer를 가능하게 한다.
본 논문에서는 30개의 서로다른 computer vision dataset을 가지고 모델의 성능을 평가/비교 하였으며, OCR, action recognition, geo-localization 등 많은 종류의 fine-grained object classification task에도 모델을 적용해보았다. 모델은 대부분의 task로 transfer가 가능하였고, 기존의 모델보다 때때로 더 나은 성능을 보여주었다.
1. Introduction and Motivating Work
raw text로 부터 바로 학습하는 pre-training method는 지난 몇년간 NLP의 발전을 이끌었고, 논문 기준 최신 모델인 GPT-3의 경우 특정한 training data 없이 task에 상관없는 zero-shot transfer가 가능하다. 하지만 computer vision 분야에서는 논문 기준으로 아직 ImageNet과 같은 crowd-labeled dataset으로 pre-trained된 model을 사용하고 있다. 이러한 전통적인 pre-training method 대신, NLP처럼 web text로부터 직접적으로 학습할 수 있는 확장가능한 pre-training method를 개발하기 위해 많은 연구가 이루어졌고 VirTex, ConVIRT와 같은 모델들이 text에서 image-representation을 학습할 수 있는 가능성을 증명하였다.
하지만 앞서 언급된 모델들은 pre-training시 작은 학습 데이터셋 크기의 문제로 다른 SOTA computer vision 모델들 보다 낮은 성능을 보이고 있다. 이 논문에서 제시하는 모델인 CLIP은 대용량의 자연어 지도학습을 통해 데이터셋 크기의 차이를 줄이고 이미지를 학습한다. CLIP은 pre-training과정에서 여러 task를 수행할 수 있도록 학습하고, 계산적으로 효율적이지만 여타 다른 ImageNet model들 보다 더 좋은 성능을 보인다.
2. Approach
Creating a Sufficiently Large Dataset
Computer vision에서 주로 사용되는 MS-COCO, Visual Genome, YFCC100M dataset은 한계를 가지고 있다고 한다. MS-COCO와 Visual Genome의 경우 양질의 crowd-labeled dataset이지만, 데이터셋의 크기가 작으며, YFCC100M의 경우 100M의 이미지를 가지고 있지만 각 이미지의 metadata의 질이 좋지 않고 유용한 데이터셋을 추려내면 데이터셋의 크기가 ImageNet과 비슷해진다.
따라서 본 논문에서는 인터넷을 통하여 400M개의 (image, text) pair 데이터셋을 생성하였다. 최대한 넓은 범위의 이미지를 포용하기 위해 (image, text) pair에서 text는 최소한 하나의 단어라도 미리 정의해논 500,000개의 쿼리에 포함되어 있어야 데이터셋에 포함하였다. 또한 쿼리 당 (image, text) pair가 최대 20,000개까지만 저장되도록 하였고 WebText dataset과 크기가 비슷한 데이터셋을 구축할 수 있었다고 한다. 만들어진 데이터셋을 WIT(WebImageText)라고 지칭하고 있다.
Selecting an Efficient Pre-Training Method
처음의 접근은, VirTex와 유사하게, Image CNN과 text trasformer를 join하여 이미지의 caption을 예측하도록 학습하였지만, 이 방법은 model을 scaling하는데 문제점을 낳았다. 언어 모델의 속도가 매우 낮아지는 것이었다. 따라서 이 논문에서는 한 단어가 아닌 텍스트 전체로 이미지와 짝지어지도록 학습하였다. Bag-of-words 인코딩 방식을 사용하여 더 많은 효율성을 확보하였다.
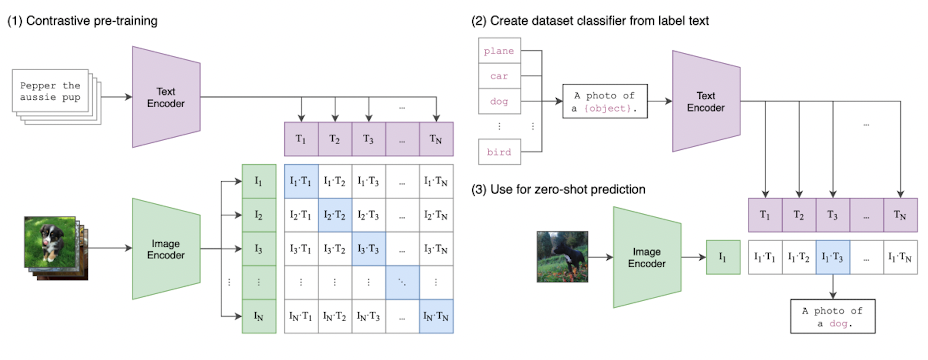
위 figure는 CLIP의 구조를 나타낸 그림으로, (1)에서 볼 수 있듯이 N개의 (image, text)쌍의 배치가 model로 forward할 때 각각의 image와 text는 encoder를 통과하고 embedding과정을 거쳐 각 modality별 N개의 feature representation으로 나타난다.
Image encoder는 ResNet 혹은 Vision Transformer를 사용하고 text encoder는 CBOW 혹은 Text Transformer를 사용한다. 그 후 embedding과정에서 추출된 벡터에 가중치 행렬을 한번 더 곱하고,L2 normalization을 수행하여 각 벡터들을 embedding한다.
그 다음 각 이미지와 텍스트 vector간 내적을 통해 코사인 유사도를 구하고, N개 pair의 코사인 유사도를 최대화 하고, 나머지 N^2 - N개의 코사인 유사도를 최소화하는 방향으로 CLIP 모델은 multi-modal embedding space를 학습하게 된다. 두개의 유사도와 cross entropy loss를 사용하여 loss를 계산하고 optimization을 진행한다.
그림 (2), (3)은 zero-shot prediction을 하는 과정을 보여준다.
먼저 적용하고자 하는 특정 하위 문제(downstream task)의 데이터셋의 label을 text로 변환하고, 이를 text encoder에 통과시켜 텍스트 벡터를 구한다. 구해진 텍스트 벡터와 예측하고 싶은 이미지 벡터간의 유사도를 계산하여 높은 값을 갖는 텍스트를 선택한다.
CLIP은 pre-trained weight를 사용하지 않으며, representation과 contrastive embedding space사이에 non-linear projection을 사용하지도 않았다. 대신에 각 인코더의 representation에서 multi-modal 임베딩 공간으로의 linear projection만을 사용하였다. Text가 대체로 한 문장 단위이기 때문에 text transformation function을 사용하지 않으며 image transformation function도 단순화 하여 사용한다.
Choosing and Scaling a Model
본 논문에서는 Image encoder로 2개의 architecture ResNet과 Vision Transformer를 고려하였고, Text encoder로 CBOW와 8개의 head가 있는 Transformer를 고려하였다. 일반적인 computer vision연구에서는 모델의 width 혹은 depth를 독립되게 증가시키지만, CLIP에서는 width, depth, resolution 모두 추가적인 computing을 할당하였고 text encoder의 경우 width만 조절하였다.
Pre-training
Image Encoder로 ResNet based 모델 5개 ResNet50x4, ResNet50x16, ResNet50x64, ResNet101, EfficientNet을 사용하였고 Vision Transformer로는 ViT-B/32, ViT-B/16, ViT-L/14를 각각 사용한다.
모든 모델은 32epoch 훈련하였고, Adam optimizer를 사용하였다.
ViT-L/14의 경우 더 높은 336 pixel 해상도에서 1 epoch 훈련을 추가하여 성능을 향상시켰다. 이렇게 train된 모델을 ViT-L/14@336px로 칭하며 performance가 가장 좋았다.
3. Experiments & Results
Computer Vision 분야에서 zero-shot은 처음보는 object에 대한 분류를 예측하는 방식을 말하는데, 이 논문에서는 처음보는 dataset에 대한 분류로 그 의미를 확장하였다. 각각의 dataset에 대하여 모든 class들의 이름을 잠재적 text paring의 집합으로 사용하고 CLIP이 점수가 가장 높은 (image, text) pair를 예측한다.
image classification을 위한 zero-shot transfer는 Visual N-Grams 에서 처음 연구되었고, 논문에서 유일하게 zero-shot image classification 성능을 비교할 수 있는 모델이다. 비교 결과 CLIP이 월등히 좋은 성능을 보였고, 가장 좋은 CLIP(ViT-L/14@336px)의 경우 ImageNet으로 학습된 ResNet50 보다 더 좋은 ImageNet 분류 성능을 보였다.
CLIP은 fully supervised learning과 비교하여 경쟁력있는 성능을 보여주고 있고, 물체를 인식하는 task에서는 매우 좋은 성능을 보여주지만, 물체의 개수를 세거나 물체가 얼마나 가까이 있는지를 예측하는 복잡한 task에서는 상대적으로 좋지 못한 성능을 보여준다.
CLIP은 Few-shot method과 기존의 다른 SOTA computer vision 모델들과 비교했을 때 더 나은 결과를 보여준다. 또한 CLIP은 텍스트간의 연관성을 학습하여 task transfering에 더 강력하다는 특징이 있는데 논문에서 제시한 transfer score를 확인하면 다른 모델들 보다 더 높은 것을 볼 수 있다.
CLIP은 distribution shitf에도 ImageNet으로 pre-trained된 모델보다 더 robust한데, 인터넷 상에서 추출한 많은 양의 데이터로 학습을 했기 때문에 데이터의 분포가 크고, 많은 케이스의 이미지를 포함하기 때문에 생긴 결과라고 볼 수 있다.
인터넷 상에서 대규모의 이미지와 캡션을 추출하여 훈련에 사용하였기 때문에, Train data와 test간의 overlap이 생길 수 있어 overlap검사를 하였으나, 전반적인 성능에 영향을 끼치지 않는 정도임을 확인하였다.
4. Limitation
본 논문에서 CLIP의 성능이 ResNet-50과 비교가 많이 되었는데, CLIP이 SOTA의 성능을 보이려면 1000x의 계산량 증가가 필요하다. 따라서 CLIP의 효율적인 계산과 데이터 효율에 대한 연구가 필요하며 새로운 벤치마크 또한 필요하다. 또한 image classifier를 자연어로 명시하는 것은 유동적인 방법이지만, 모든 task가 text로 분명하게 명시될 수 있는 것이 아니기 때문에 어느정도의 한계가 존재한다.
5. Conclusion
CLIP은 crowd-labeled dataset 없이 task-agnostic web-scale pre-training을 vision에 적용하여 zero-shot transfer를 수행한다. 아직 발전의 여지가 남아있다.
