StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
0. Abstract
다양한 도메인에서 고해상도의 사실적인 이미지를 생산할 수 있는 StyleGAN의 능력에 힘입어, StyleGAN의 latent space를 이용하여 gerenated & real image를 manipulate하는 방법에 대한 연구가 최근 집중되고 있다.
하지만 기존의 manipulation 방법들은 많은 실험을 요구하거나, 원하는 manipulation을 위한 annotated된 image 등의 manual한 노력이 필요하였다.
본 논문에서는 Contrastive Language-Image Pre-training(CLIP) 모델을 사용하여 StyleGAN image manipulation을 위한 text-based interface를 제시한다.
총 3가지의 방법을 제시하는데, (1) Latent vector를 update하기 위한 optimization 기법과, (2) Encoder network의 일종인 latent mapper, (3) global direction을 찾는 기법을 제시한다.
1. Introduction
GAN의 등장으로 image 합성 기술은 눈부신 발전을 이루고 있고, 발전된 형태의 GAN인 StyleGAN의 latent space에서는 semantic한 image manipulation을 가능하게 하는 disentanglement한 특성을 가진다.
- entangle: 각 특징들이 서로 얽혀있어서 구분이 안되는 상태
- disentangle: 특징들이 잘 분리되어 있는 상태
현존하는 image manipulation을 위한 기법들은 미리 정해진 semantic direction으로만 가능하여 사용자의 창의력과 상상력을 제한한다. 새로운 direction으로 manipulate를 원한다면, manual한 노력이나 양질의 annotated data가 필수적이다. 본 논문에서는 이러한 수동적인 작업이 필요 없는, 텍스트에의해 직관적으로 image control이 가능하도록 StyleGAN과 CLIP모델을 활용하여 text에 기반한 image를 변형시키는 interface를 개발했고, StyleGAN과 CLIP을 결합하는 3가지 기술, Latent optimization, Latent mapper, Global direction을 소개한다.
2. Related Work
Vision and Language
BERT의 성공 이후, Vision and Language(VL) method는 joint representation을 학습하기 위해 transformer를 사용한다. Text와 Image를 pair로 학습시킨 CLIP은 multi-modal embedding space를 학습하는데, 대량의 데이터에 의해 학습이 되었기 때문에 image-text간 관계를 잘 나타낸다.
아래는 이미 개발된 Text-guided image generation/manipulation 모델들이다.
- Text-guided Image generation:
Conditional GAN, AttnGAN - Text-guided image manipulation:
ManiGAN, DALL・E, TediGAN
Latent Space Image Manipulation
StyleGAN의 latent space를 통하여 의미있는 image manipulation이 가능하기 때문에 많은 연구들이 pre-trained generator의 latent space를 이용하는 방법에 대해 탐구하였다.
연구된 방법은 크게 두 갈래이다. image annotation을 사용하여 의미있는 latent path를 찾는 방법과, 감독 없이 의미있는 direction을 찾고, 각 direction에 대한 수동적인 annotation을 요구하는 방법이다.
본 논문에서 제시하는 3가지 방법은 manipulation이 text input으로부터 직접적으로 파생되고, pre-trained model CLIP에 대해서만 지도학습이 이루어 진다.
3. StyleCLIP Text-Driven Manipulation
본 논문에서 StyleGAN과 CLIP을 결합하여 text-driven image manipulation을 수행하는 3가지 방법 Latent optimization, Local Mapper, Global Direction을 제시한다.
Latent optimization은 StyleGAN의 space를 CLIP space에서 계산된 loss를 줄이는 방향으로 optimization하는 방법이다. 입력되는 값 마다 optimization을 진행하기 때문에 하나의 manipulation을 수행하기 위하여 오랜 시간이 걸리며, 다루기 힘들다는 단점이 있다.
Local Mapper는 mapping network가 latent space에서 manipulation을 추론하도록 훈련하는 방식이다. 훈련에는 몇시간이 소요되지만 하나의 text prompt에 대해 한번만 학습하면 되는 장점이 있다. 하지만 공간의 시작점에 따라 manipulation step의 방향이 달라지는 단점이 있다. 또한 manipulation step이 에서 이루어지기 때문에 disentangled하게 visual effect를 주는 것이 어렵다.
Global Direction은 주어진 text prompt를 global mapping direction으로 변환한다. global direction은 StyleGAN의 style space s에서 계산되며 disentangled한 visual manipulation이 가능하다.
4. Latent Optimization
첫번째로 제시되는 Latent Optimization은 직접적으로 latent vector를 optimization하는 방식이다. 아래의 Optimization을 푸는 것으로 이 문제를 표현할 수 있다. 는 e4e encoder에서 얻게되며, StyleGAN은 에 해당하는 이미지를 생성한다.
G는 pretrained된 StyleGAN generator이고, 은 CLIP embedding의 2개 argument 사이의 Cosine 유사도 즉 CLIP Loss이다. 입력 이미지와의 유사도는 latent 공간의 distance와 identity loss 로 조절되는데 는 아래와 같다.
가 만들어낸 이미지 와 가 만들어낸 이미지 의 identity loss이며 두 이미지를 유사하게 하는 방향으로 optimization이 이루어 진다. Gradient descent 방식을 사용하여 200-300 iter만큼 optimization을 진행한다. 와 는 조절 가능한 파라미터로 이미지의 identity를 크게 변경하고 싶으면 를 낮은 값으로 setting한다.
5. Latent Mapper
Latent optimization은 (source image, text prompt) pair마다 optimization을 수행해야 하고, 하나의 이미지를 조정하는데 최적화를 계속 시행해줘야 하기 때문에 시간이 많이 걸린다는 단점이 있다. 더 효율적인 방법으로 Mappint network를 훈련하는 방법이 있다.
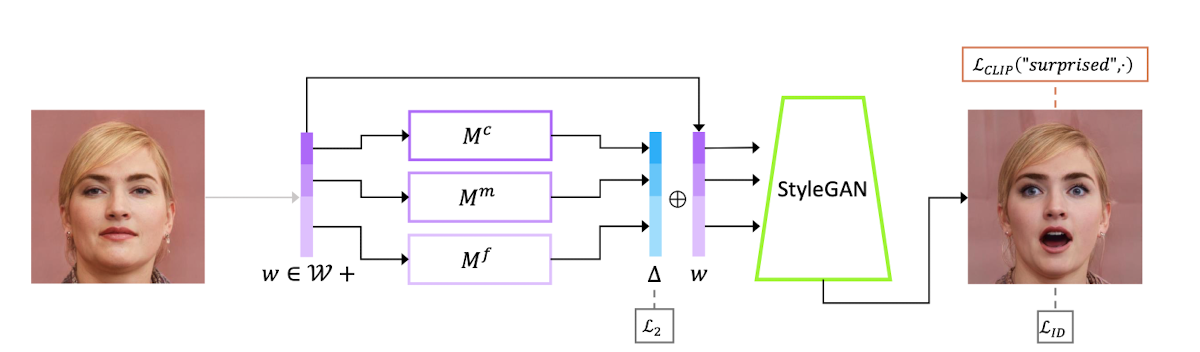
Latent mapper는 Text prompt에 대한 mapping network을 학습한다. Mapper는 세가지 다른 정보에 해당하는 FC layer ()로 구성되며 각각 Course, Medium, Fine style을 의미한다. 이러한 mapping network의 구조는 기존 StyleGAN의 mapping network와 동일하지만 더 적은 layer (8→4)를 가진다. Mapping network에 가 입력되면 즉,를 출력하게 되며, 와 합해져 StyleGAN의 입력으로 들어간다. 생성된 이미지는 주어진 text와 cosine 유사도 검사를 통해 유사도를 확인한다. Loss function은 아래와 같다.
Optimization은 를 산출하는 Latent mapper에 수행된다. 은 CLIP loss로, 원본 이미지의 latent space에서 만큼 변형된 이미지인 와 주어진 Text가 CLIP에서 유사한지 확인한다.
두번째 항인 L2 loss는 가 너무 커지는 것을 막고, 마지막 항인 identity loss는 원본 이미지와 만들어낸 이미지가 너무 달라지는 것을 방지한다.
Text prompt를 통해 Identity를 유지하면서 여러가지 속성을 한번에 바꿀 수 있다는 것을 확인했다.
6. Global Directions
Latent mapper는 빠른 inference time을 보이지만, 가끔 disentangled하지 않기 때문에 manipulation에 실패하는 경우가 있다. 또한 서로 다른 의미를 지닌 text가 유사한 manipulation으로 이끄는 경우도 발생한다.
따라서 마지막으로 이 논문에서는 주어진 text prompt와 manipulation을 유사하게 만들기 위해 text prompt를 StyleGAN의 style space S 안에 있는 global direction으로 mapping하는 방법을 제시한다.
기본적인 아이디어는 CLIP text encoder를 사용하여 를 구하고 style space S의 vector와 mapping하여 구하고 입력 이미지에 독립적인 다른 attiribute를 해치지 않는 수정된 image를 획득하는 것이다. 위 식에서 는 변형의 세기를 뜻한다. 남은 일은 를 찾는 일이다.
먼저 CLIP의 joint embedding space에서 prompt engineering을 사용하여 를 찾는다.
대응되는 는 잘 훈련된 CLIP 공간에서, image manifold와 text manifold 에서의 semantic change direction이 rough하게 collinear하다는 것을 가정했을 때 image manifold에서의 이미지 변화량 와 또한 collinear하기 때문에 이미지 변화량 로 를 구할 수 있고 을 StyleGAN의 입력으로 하여 원하는 조작된 이미지를 획득할 수 있다.
From natural language to
Prompt engineering을 이용하여 를 찾아낸다. 같은 의미를 지니는 여러 문장을 text encoder에 넣은 후 그 embedding을 평균내는 방법이다. Zero-shot ImageNet 분류 문제를 예로 들면, 80개의 문장 template의 embedding을 평균하여 구하고 이 과정은 분류 성능을 향상시킨다.
text manifold 공간 안에서도 더 안정적인 direction을 얻기 위해 위 방법을 사용한다.
Channelwise relevance
잘 훈련된 CLIP 공간에서 와 가 colinear함을 가정할 수 있고, 로부터 를 구성한다.
먼저 기존 의 특정 채널 c에 값을 더하거나 빼서 style code를 생성한다.
기존 s로부터 생성된 image와 교란된 s로부터 생성된 이미지의 CLIP embedding space에서의 차이를 라고 정의할 때, 찾고자 하는 는 와 관계성을 계산하여 관련성이 없는 채널은 zero-vector로, 높은 채널은 로 정의한다. 는 disentanglement threshold로 원본 이미지와의 관련성을 제시한다.

위 그림에서 볼 수 있듯이, amplitude 값이 커질 수록 변형의 강도가 강해지고, 값이 높으면 원본 이미지와의 유사성을 유지하는 모습을 확인할 수 있다.
7. Comparisons and Evaluations

Latent optimization method를 제외한 Latent mapper와 global direction method를 TediGAN과 비교하였다. manipulation시 복잡하지만 구체적인 속성으로 “Trump”를, 덜 복잡하지만 덜 구제척인 속성으로는 “Mohawk”(모히칸 머리), 간단하고 흔한 속성으로는 “without wrinkles”(주름이 없는)을 text prompt로 하였다. 실험 결과 Latent mapper가 복잡한 속성에 더 적합하고, global direction은 더 간단하거나 더 일반적인 속성에 만족스러운 결과를 보였다.
8. Limitations
- 제시된 방법들이 Pretrained StyleGAN과 CLIP에 의존적이기 때문에, pretrained generator의 domain에서 벗어난 이미지를 manipulate할 수 없다.
- CLIP 공간에서도 이미지로 채워지지 않은 공간 영역에 mapping되는 text prompt는 의도한대로 manipulation 잘 수행할 수 없다.
- 어떤 image data에 급격한 변화를 주는 manipulation은 성공하는 경우도 있지만 실패하는 경우도 있다.
