Paper Review
1.[논문 리뷰] CLIP
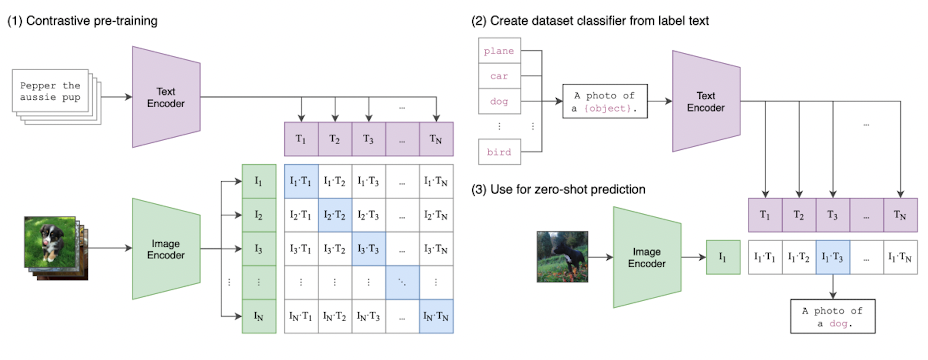
computer vision system은 정해진 범주의 객체를 가지고 학습을 진행하는 것이 일반적이지만 이러한 학습 방법은 모델의 일반성을 떨어뜨릴 뿐더러, 새로운 class의 data를 모델 추가적으로 명시해야한다는 문제점이 존재한다.이러한 문제를 해결하고자, 본
2.[논문 리뷰] StyleCLIP
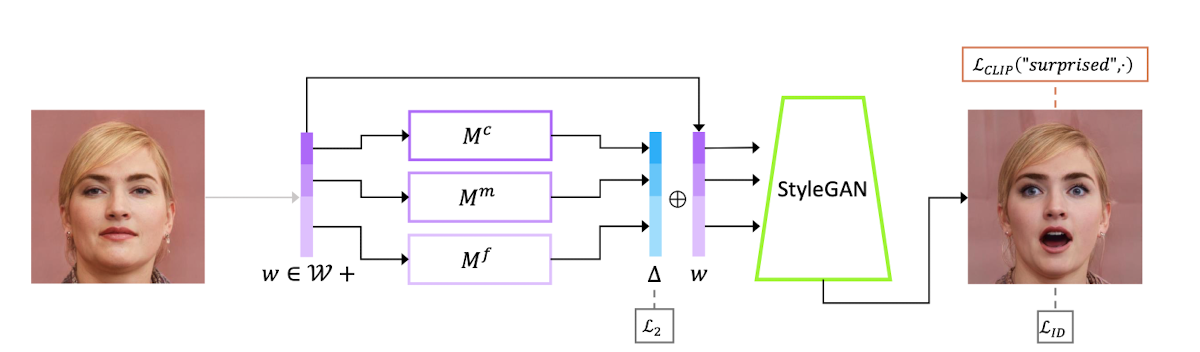
다양한 도메인에서 고해상도의 사실적인 이미지를 생산할 수 있는 StyleGAN의 능력에 힘입어, StyleGAN의 latent space를 이용하여 gerenated & real image를 manipulate하는 방법에 대한 연구가 최근 집중되고 있다.하지만 기존의
3.[논문 리뷰] Sound-Guided Semantic Image Manipulation
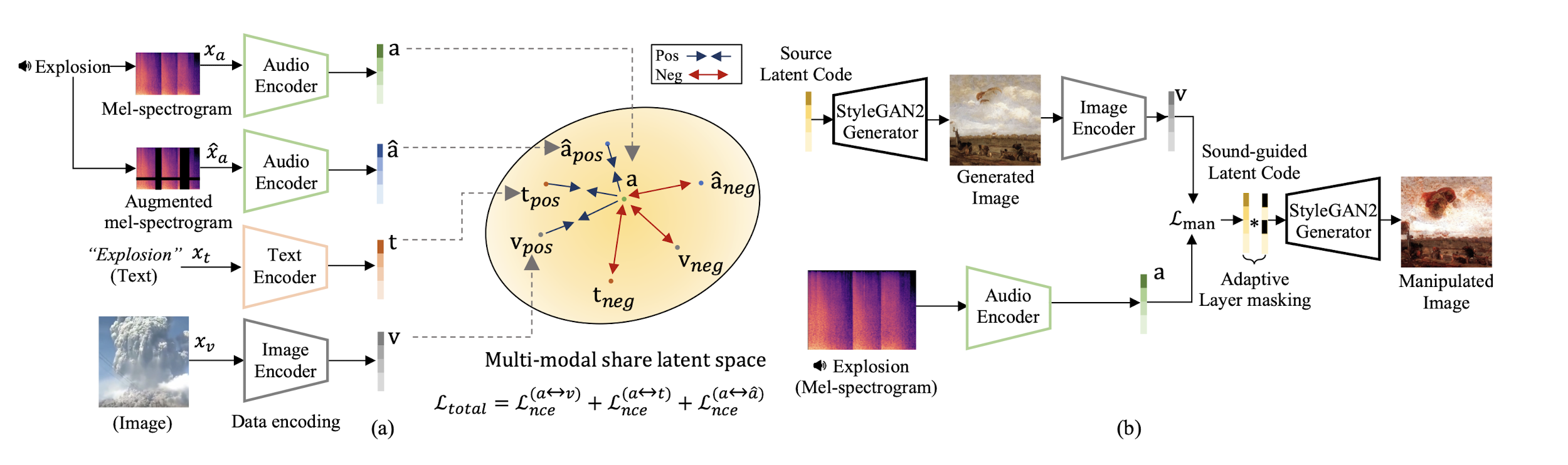
최근 generative model관련 연구의 성공은 multi-modal embedding space를 사용하여 text 정보를 바탕으로 image를 manipulate할 수 있음을 보여주었지만, 다른 Source를 사용한 manipulation은 쉽지 않은 작업이다
4.[논문 리뷰] Sound-guided Semantic Video Generation
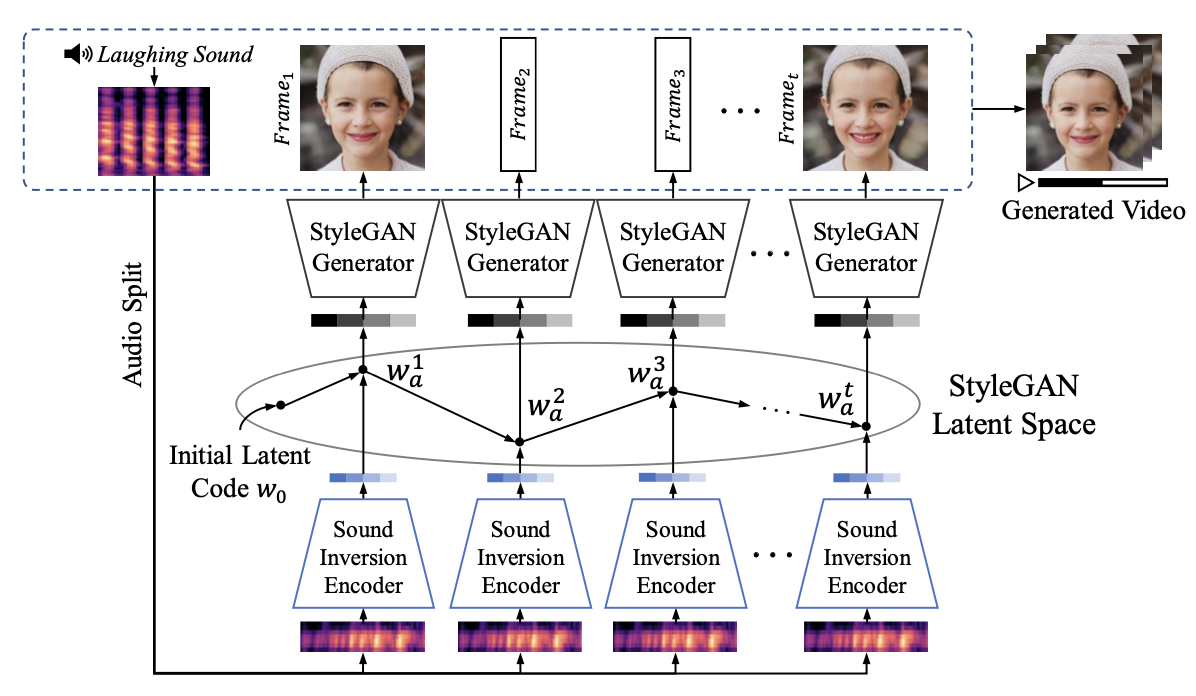
Multimodal (sound-image-text) embedding space를 사용하여 사실적인 Video를 생성하는 framework를 제시하고, 새로운 고해상도 풍경 video dataset (audio-visual pair)를 제세한다.기존의 Video 생성
5.[논문 리뷰] Soundini
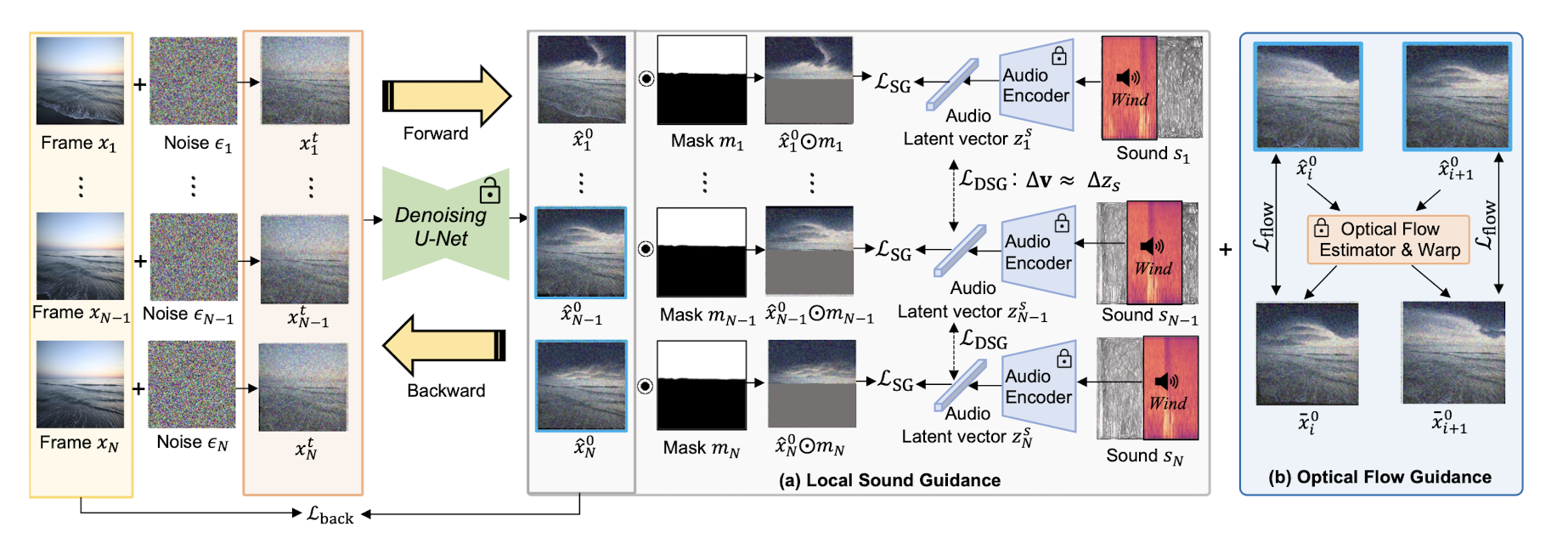
zero-shot setting에서 Video의 특정 영역에 sound-guided visual effect를 더하는 method.Proposed method:Video decomposition-based:영상에서 특정 object와 background represen
6.[논문 리뷰] DDPM
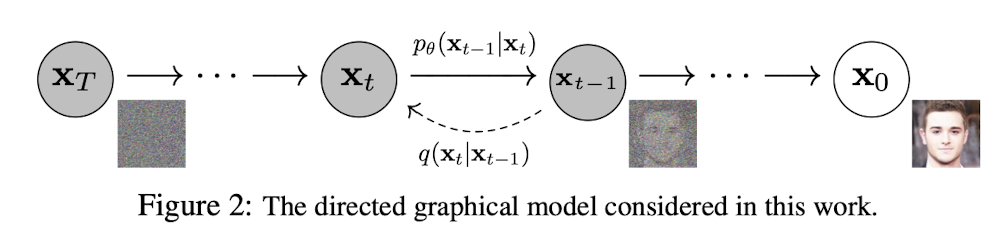
Diffusion Probabilistic model과 denoising score matching을 연결하여 Image 생성 모델 제시기존의 생성모델로 제시 되었던 GAN과는 다르게 energy-based modeling과 score matching의 발전은 더 높은
7.[논문 리뷰] GaussianEditor: Swift and Controllable 3D editing with Gaussian Splatting (CVPR 2024)

Gaussian semantic tracing, Hierachical Gaussian Splatting (HGS)을 통해 editing을 위한 3DGS Fine-tuning시 기존에 존재하던 gaussian들을 효과적으로 control하는 기법 제안.
8.[논문 리뷰] TIVA-KG: A Multimodal Knowledge Graph with Text, Image, Video and Audio (ACM MM 2023)
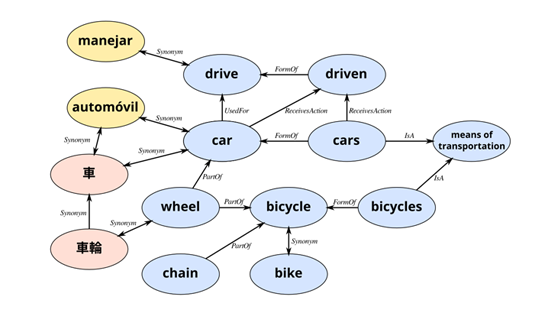
Text, Image, Video, Audio 총 4개의 modality를 포함하는 지식 그래프를 제시하고 4개 modality에 대한 Quadruple Embedding Baseline (QEB) 모델을 제시
9.[논문 리뷰] Open-Vocabulary Semantic Segmentation with Mask-adaptive CLIP (CVPR 2023)
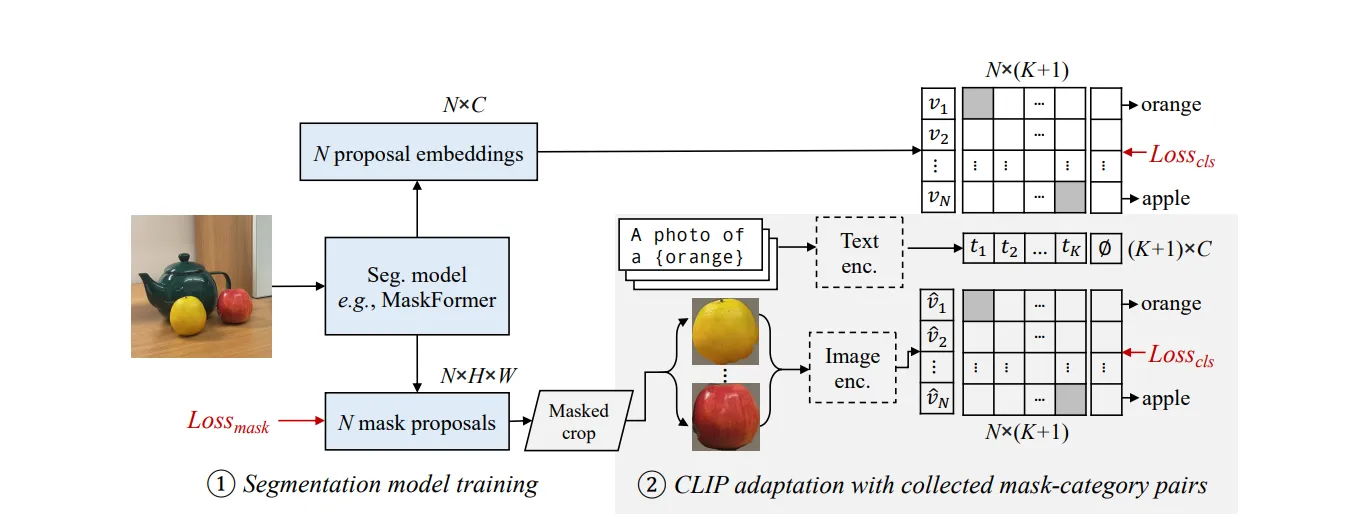
two-stage open-vocab semantic segmentation task에서 COCO-Caption을 활용한 CLIP fine-tuning을 통한 모델 OV-Seg 제시
10.[논문 리뷰] Deformable Neural Radiance Fields using RGB and Event Cameras (ICCV 2023)
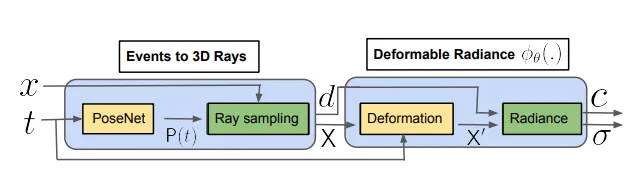
빠르게 움직이는 deformable한 object에 대해, 정교한 3D recon을 수행하기 위해서 Event Stream을 고려하는 Dynamic NeRF network 제안최근 NeRF의 발전으로 3D Scene을 implicit하게 represent하여 여러 Vi
11.[논문 리뷰] How Far Are We from Intelligent Visual Deductive Reasoning? (ICLR 2024 AGI Workshop)
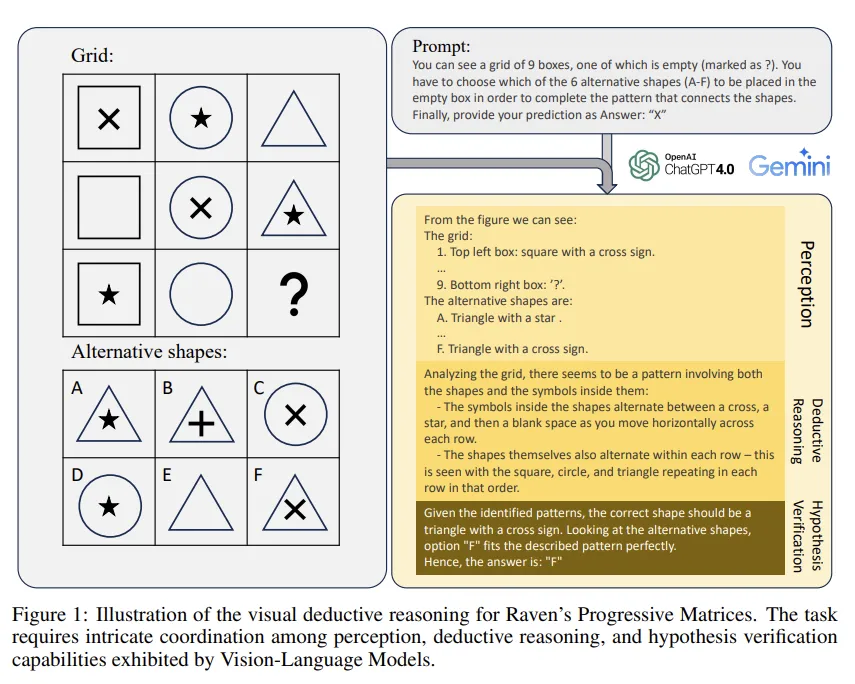
Raven’s Progressive Matrices(RPMs) task를 SOTA Vision-Language Models (VLMs) 해결해 보도록 하여 VLM이 visual clues에만 의존하는 reasoning에는 취약하다는 blindspot(약점)을 찾아냄.