[논문 리뷰] How Far Are We from Intelligent Visual Deductive Reasoning? (ICLR 2024 AGI Workshop)
Paper Review
Raven’s Progressive Matrices(RPMs) task를 SOTA Vision-Language Models (VLMs) 해결해 보도록 하여 VLM이 visual clues에만 의존하는 reasoning에는 취약하다는 blindspot(약점)을 찾아냄.
1. Introduction
최근 LLM을 기반으로한 여러 VLMs들은 vision-based reasoning, understanding 등의 task에서 좋은 성능을 보였다. 심지어 입력받은 image에 작성되어 있는 Text 정보를 추출하고 이를 기반으로 사고 및 판단도 가능하였다.
본 논문에서는 정교하고 연역적인 추론이 필요한 RPM 문제를 모델에게 해결하도록 하여 VLMs가 가지고 있는 한계에 대해 분석해 보고자 한다.
- RPM: 인간 지능을 평가할 때 사용되는 문제로 주어진 intent에서 pattern을 찾아내고, 이를 바탕으로 여러 선택지 중 하나를 골라 빈칸을 채우는 문제이다.
RPM을 풀기 위해서는 다음과 같은 단계가 필요하다.
RPM 문제 예시
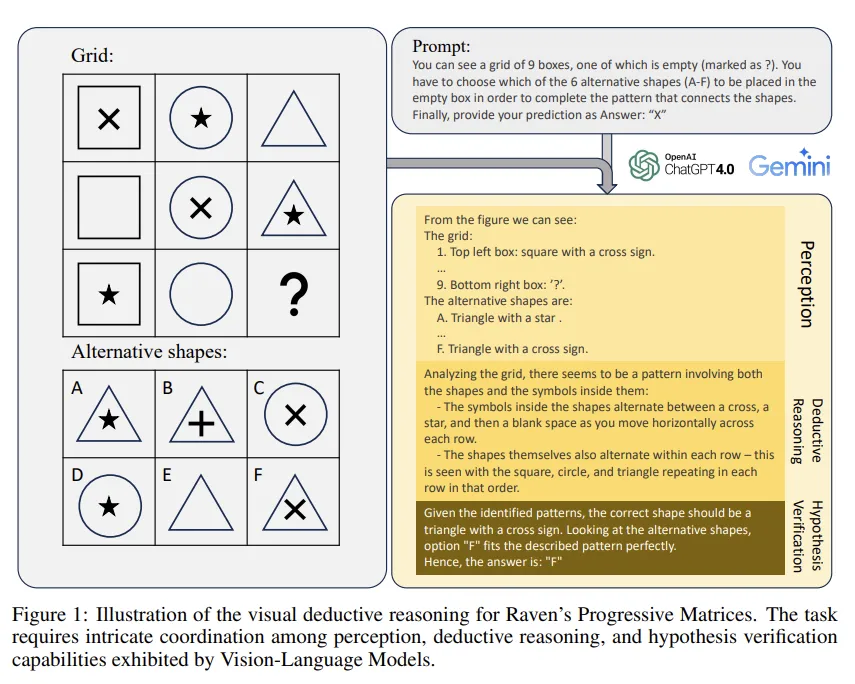
- 선택지를 포함한 주어진 Image들에 대해 총체적인 패턴을 파악해야함.
- 패턴들이 바뀌어가는 과정을 관찰하고 변화하는 규칙이나 트렌드를 파악해야함.
- 파악한 규칙을 바탕으로 주어진 선택지 내에서 사라진 패턴을 찾아야 한다.
기존의 image reasoning task들과는 다르게 RPM은 아래와 같은 challenge를 요구한다.
- 구분, 관계파악, 유추 등의 복잡한 연역적인 판단이 가능해야 한다.
a. 연역적인 판단: 기존의 것을 바탕으로 새로운 명제를 추론하는 것. - 기존의 VQA는 Text description을 바탕으로 모델의 추론 과정에서 가이드를 줄 수 있는 반면, RPM은 가설을 생성하고 확인할 때 오직 visual clue에만 의존한다.
- RPM은 보통 few-shot learning task로 각각의 RPM 문제들이 다른 규칙들을 가지고 있기 때문에 모델에 넓은 범위의 강력한 일반화 능력을 요구한다.
본 논문의 contribution은 아래와 같다.
- RPM문제에 대해 VLMs을 평가하는 Framework 제시함. Mensa IQ test, IntelligenceTest, RAVEN 3개의 dataset을 사용하였으며 VLM이 text-based reasoning에는 뛰어나지만, image-based reasoning에는 좋지 않은 성능을 보였다는 사실을 증명함.
- LLM의 Reasoning 능력을 높이기 위한 prompt engineering 기법들 (in-context learning, self-consistency)이 VLMs에는 큰 효과를 보이지 못하였다.
- VLMs들의 기능을 perception, deductive reasoning, hypothesis verification, 3개로 나누어 어디에서 performance bottleneck이 발생하는지 찾았다.
- RPM 해결에서 VLM이 가지는 issue를 파악 및 평가하고, 다른 style의 prompt가 다른 성능을 보이는 것을 확인하여 잘 짜여진 (Structured) prompt가 성능에 영향을 미친다는 것을 확인하였다.
2. Experiment Setting
Dataset
- Mensa Test (35) + IntelligenceTest Pattern Recognition + RAVEN (140) ⇒ 약 200개 사용.
Model
- 4개 모델:
GPT4-V,Gemini-pro,Qwen-VL-Max,LLaVA-1.5-13B사용 - 같은 질문에 대해 10번씩 물어보고, 정확도와 entropy를 측정
Prompt
단계적으로 지시를 하는 prompt를 제공하여 단계적으로 옳은 답변을 추론하도록 prompt를 설계함


3. Evaluation Results
Evaluation
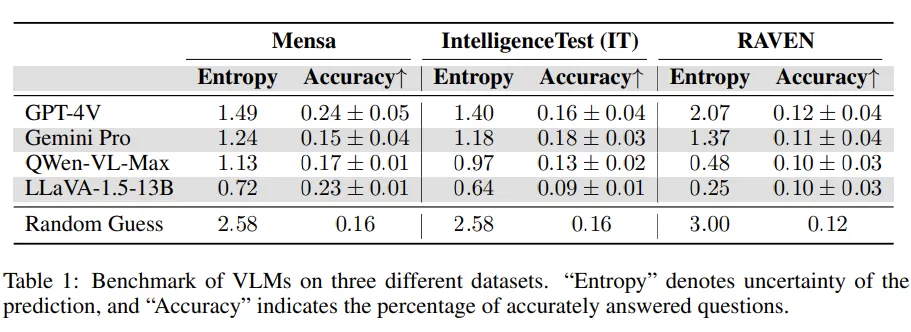 - Entropy : 한 문제에 대해 10개의 choice 집합 C가 있을 때 엔트로피 S는 아래와 같음
- Entropy : 한 문제에 대해 10개의 choice 집합 C가 있을 때 엔트로피 S는 아래와 같음
- 정확도도 10번의 case에 대한 평균을 계산해서 산출
- Random Guessing 과 비슷한 수준
- GPT와 Gemini가 다양한 답변 (diverse answers)을 출력
- QWen과 LLaVA는 더 deterministic 한 답변을 출력
LLM에 사용되는 전략이 VLM에 먹힐까?
- Evaluation 결과
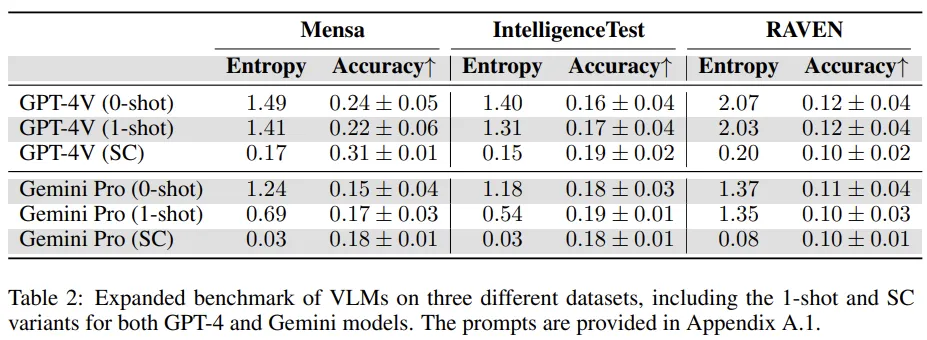
- One-shot : 하나의 prompt 답변 예시를 VLM에 제시

- Self-consistency (SC) :여러 response를 sampling하고, 가장 많은 vote를 받은 정답을 선택 (앙상블 모델 처럼)
→ 효과는 미미했다. 오히려 성능 떨어지는 경우도 발생. - 특이한 점은 One-shot 예시에서 제공한 example을 똑같이 물어봐도 정확도와 비슷한 확률로 정답을 맞춘다는 사실
- 그래서 새로운 실험 설계
- 모델이 one-shot에서 제공받는 문제와 동일한 문제를 풀도록 함.
- 정답도 제공해 주기 때문에 모델은 걍 in-context sample에서 답변을 copy하면 됨.
- 결과는 아래와 같음.
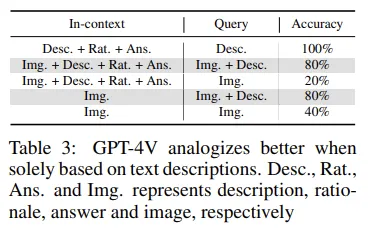
이미지로 예시를 줬을 때 정확도가 떨어지고, text가 들어가면 정확도가 올라가는 것으로 보아, 모델이 그냥 in-context든 query든 이미지 자체를 이해를 잘 못하고 있다는 것을 확인할 수 있었음.
모델이 textual token보다 image token을 더 이해하기 힘들어하며, 텍스트를 더 사용한다는 것을 알 수 있음.
4. What limits the performance of the VLMs?
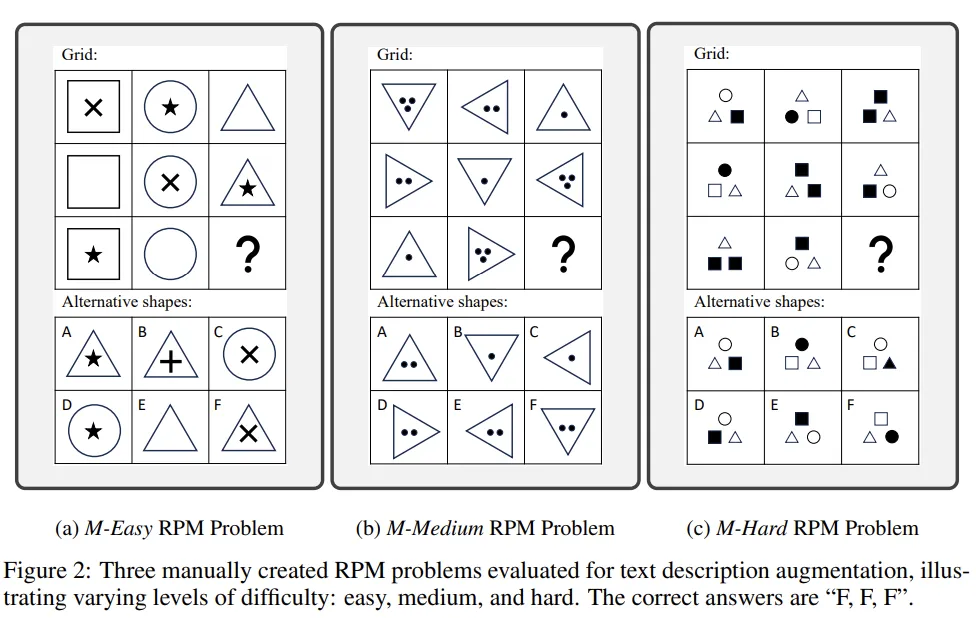
왜 VLM의 성능이 낮은지 파악하기 위해, RPMs을 3개의 난이도로 나누었다.
[M-Easy, M-Medium, M-Hard]
Evaluation 또한 3개의 연속된 단계로 나누었다.
- Perception: 모델이 RPM의 패턴을 잘 이해하고 묘사할 수 있는가?
- Deductive reasoning: 모델이 패턴들 사이의 규칙을 파악할 수 있는가?
- Hypothesis verification: 모델이 사라진 패턴을 예측하기 위한 가설을 잘 세우고, 선택지 중 정답을 잘 고르는가?
Task 인지능력이 어떠냐?
이를 평가하기 위해 VLM이 RPM Figure를 잘 묘사하는지 물어봄. Real-life photo에서 좋은 captioning 성능을 보이는 VLM들이 간단한 패턴 조차 파악을 잘 못하는 것을 발견
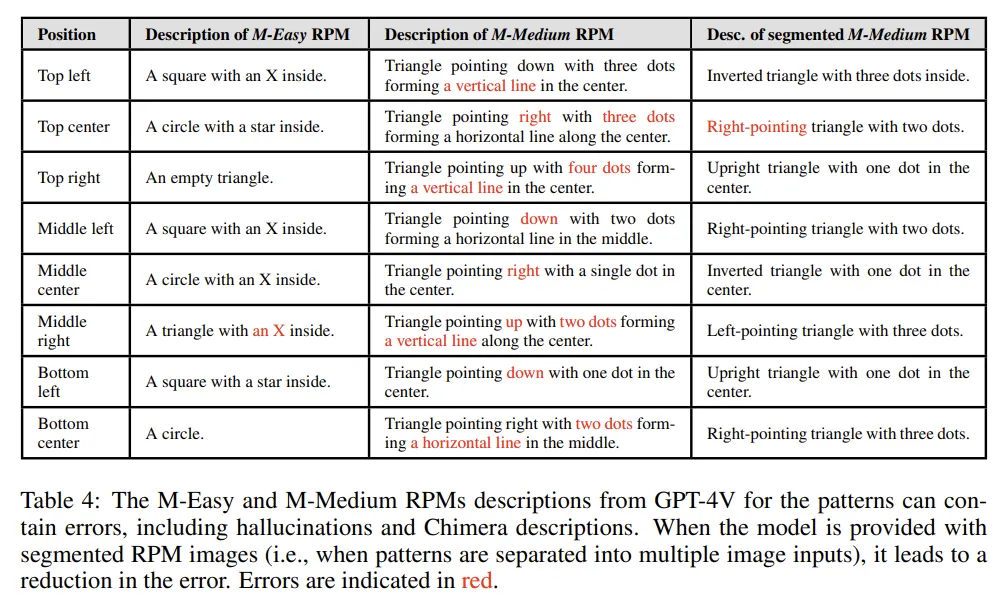
2가지 major 한 error를 발견
- Compounding error: 모델이 이전 pattern 에 대한 description을 복제하는 경우가 많아, 처음 에러가 발생하면 다음 description도 이 에러를 따르는 경향을 보임
- confounding(혼란) error: 패턴들간의 유사성이 혼란을 야기시킴. 모든 패턴들이 다 비슷해 보이기 때문에 구분되는 description을 뽑아내는데 어려움을 겪음.
- 그래서 하나의 이미지에 있던 여러개의 패턴을 Decompose해서 모델에게 넣어주었더니 성능이 올라감.
- 또한 counting해야하는 상황에서 hallucination을 생성하는 경향 보임
VLM이 real-world image를 기반으로 주로 학습되었기 때문에 추상적인 패턴을 파악하는데 어려움을 겪을 수 있을 것이라고 저자들은 판단함.
RPM으로 fine-tuning하면 성능을 올라가겠지만, 본질적인 문제 (Compounding, confounding)는 해결하지 못할 것이라고 예상.
연역적인 추론을 잘 하냐?
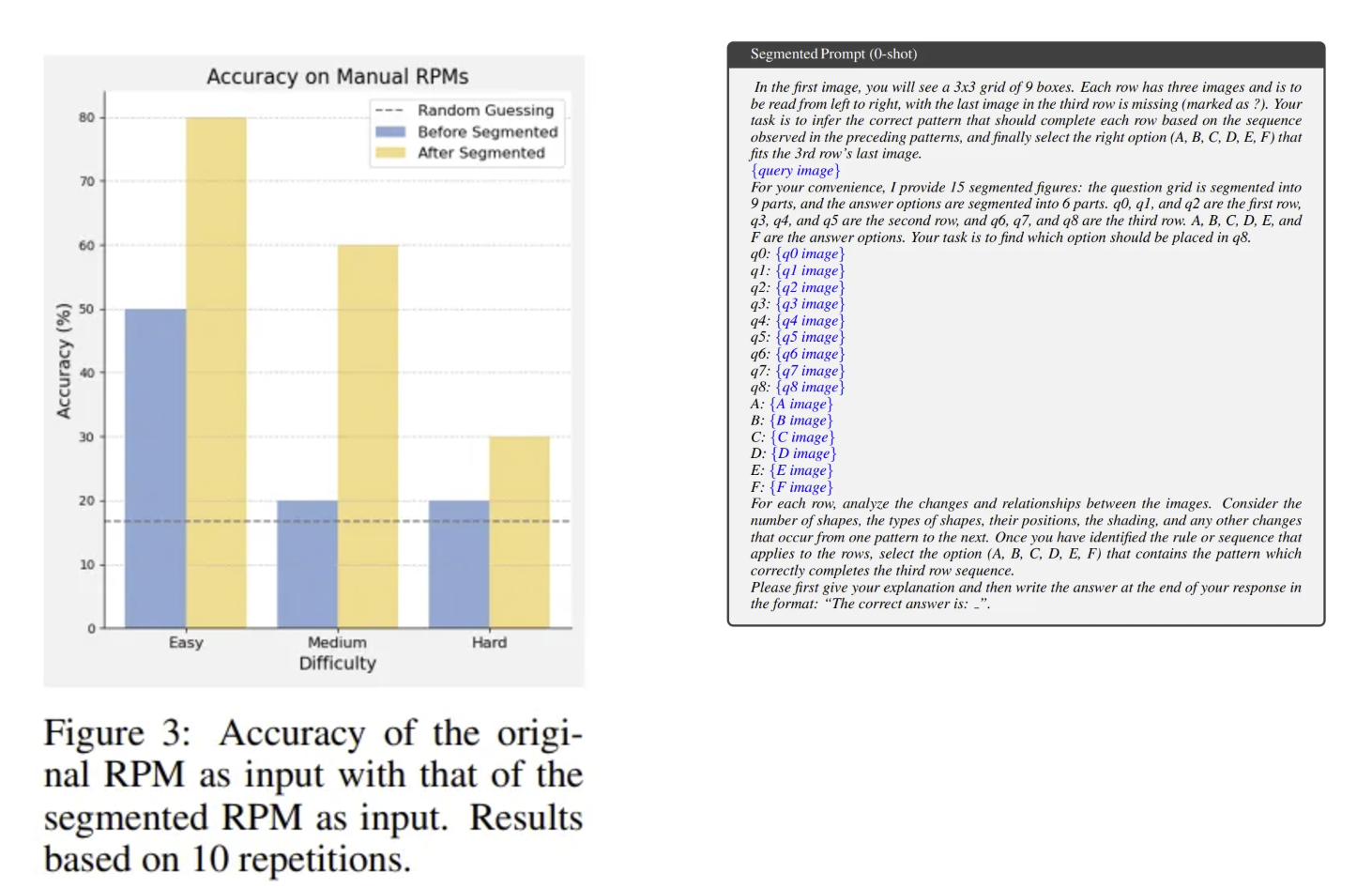
위의 성능평가 지표들은 이미지로부터 바로 답변을 생성하도록 해서, 이미지 안의 문제를 분리하고 사고하기 어려운 구조였음.
그래서 독자들이 context image에 대한 text description을 만들어서 모델에 제공해봄.
위 지표에서 중요한 것은 복잡한 spatial layout이나 relational reasoning이 필요할 때, text 정보 만으로는 추론을 하기에 부족하고 visual 정보가 모델 입장에서 유용하게 사용될 수 있다는 점.
(Hard한 문제에서 visual 이 같이 있는게 성능이 제일 좋고, visual이 빠지면 성능이 엄청 내려감)
또한 모델이 자체적으로 생성한 description도 성능 향상에 도움이 될 수 있음.
(논문에서 noisy description이라고 표현함)
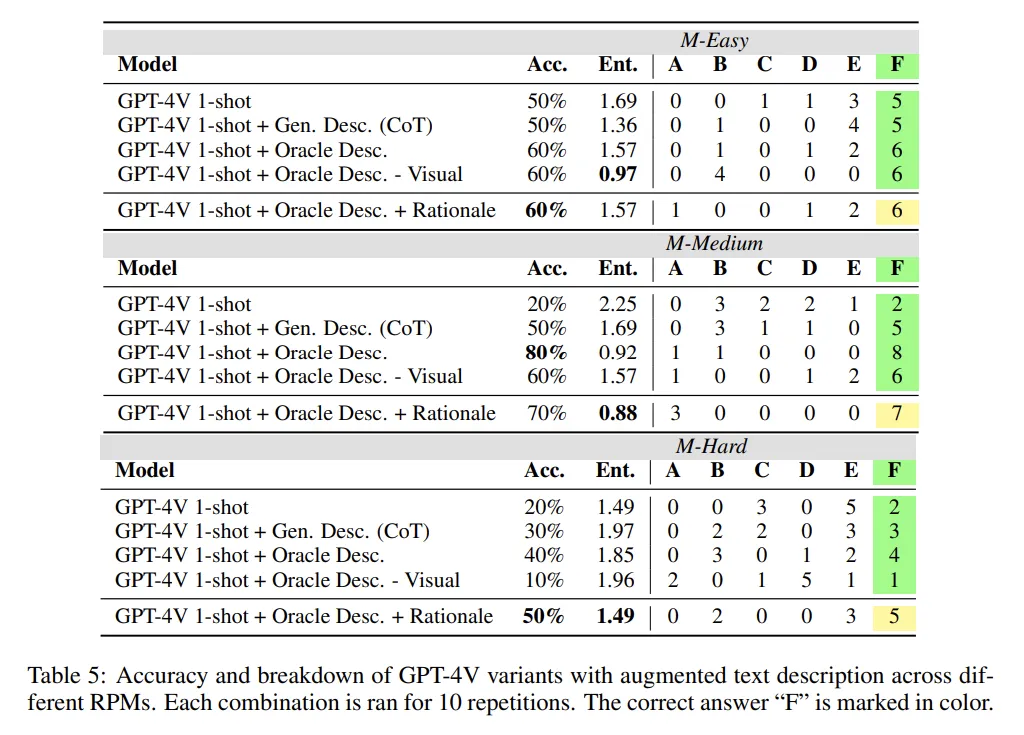
VLM이 가설 증명을 잘 하느냐?
- Rationale: 풀이과정을 제공하고 정답만 추론하도록 유도

일단 rationale을 추가로 제공하는 것이 모델 성능 향상에 큰 도움이 안 됨.
모델에 생성한 정답이 틀리면 대부분 Rationale도 같이 틀림.
모델에서 연역적 추론을 위해 가설을 생성하는 것과 이를 증명하는 사고가 연결되어 있음을 증명.
GPT-4V와 같은 강력한 모델들은 grid만 보고 답변을 우다다다 생성하는 것이 아니라,
선택지에서 정답을 제외하는 것과 같이, 사람처럼 정답 선택지와 grid를 함께 고려하는 사고를 함.
프롬프트의 format이 모델 성능에 영향을 주는가?
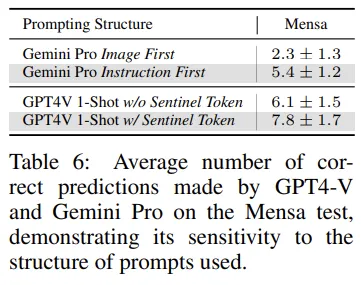
- Gemini에서 이미지를 먼저 주는지, instruction을 먼저 주는지에 따라 성능이 달라짐.
- 멘사 : 문제 35개
- 텍스트와 이미지를 구분지어주는 특정 토큰
[{BEGIN/END}_OF_EXAMPLE]등의 사용이 성능에 영향을 줌. - text only task보다 이러한 multimodal task에서 modality간의 structured format을 제시하는 것이 성능 향상에 좋은 영향을 주더라
Conclusion
-
Perceptual understanding이 performance bottleneck이었다.
-
텍스트를 제공받으면 더 잘하더라.
-
Contrastive learning이나 Reinforcement learning이 visual deductive reasoning 능력에 도움을 줄 수도 있을 것 같다.
