[논문 리뷰] TIVA-KG: A Multimodal Knowledge Graph with Text, Image, Video and Audio (ACM MM 2023)
Paper Review
Text, Image, Video, Audio 총 4개의 modality를 포함하는 지식 그래프를 제시하고 4개 modality에 대한 Quadruple Embedding Baseline (QEB) 모델을 제시하여 Uni-modal KG보다 multi-modal KG가 가지는 이점을 증명함
1. Introduction
기존의 선행 Multi-Modal Knowledge Graph (MMKG)는 동시에 최대 2개 Modality만 커버하고 주로 text, image modality 간의 관계를 표현한다. 또한 단순히 여러 entity간의 관계로만 지식그래프를 구축하는 방식으로는 Multimodal Knowledge를 표현하는데에 한계가 존재한다.
따라서 본 연구에서는 아래와 같은 contribution을 가진다.
- Text, Image, Video, Audio modality를 동시에 포함하는 첫 General KG인 TIVA-KG를 제안함.
- TIVA-KG는 Multimodal data간의 관계를 triplet 형태로 구축하여 (Triplet grounding) 더 풍성한 knowledge representation을 제공한다.
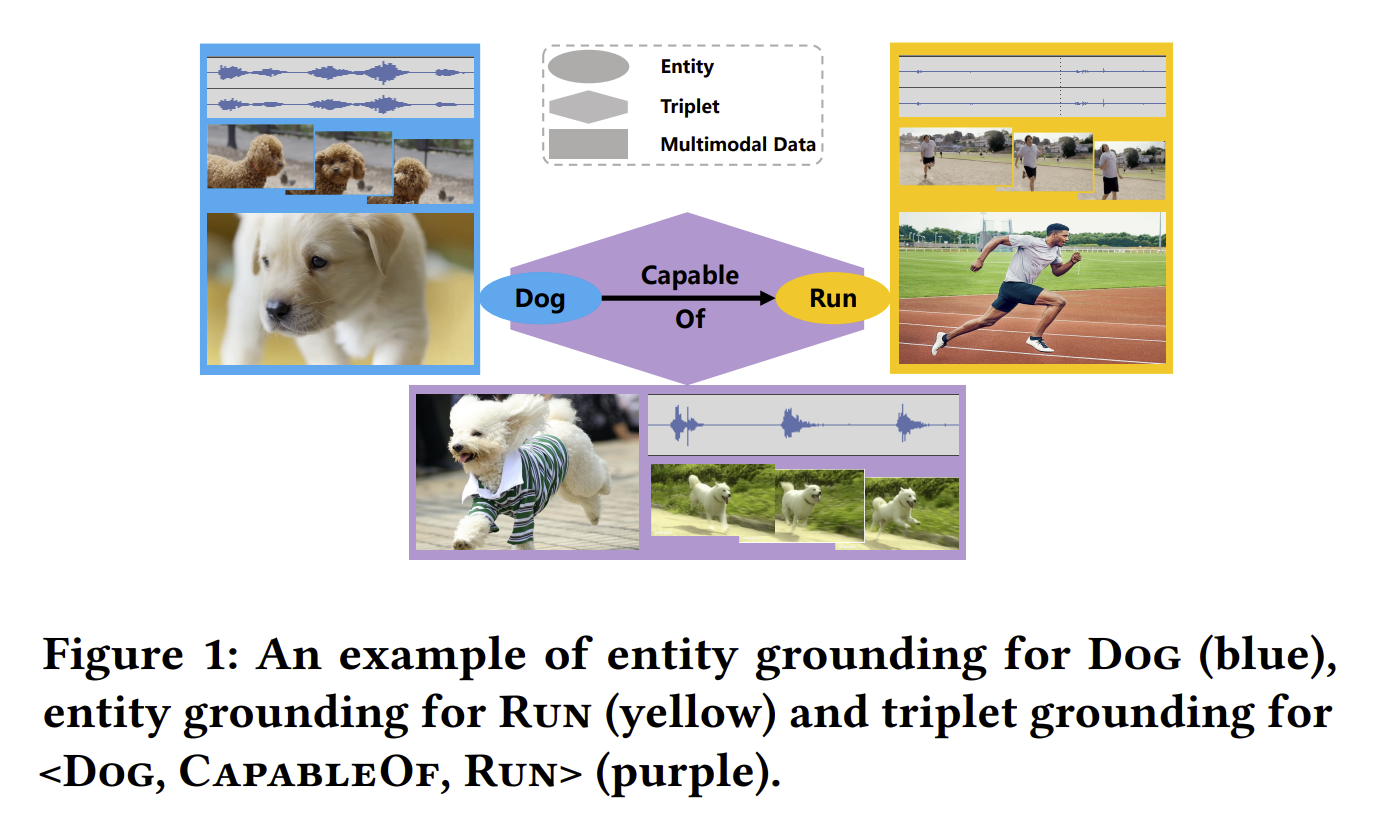
- {Dog; Capable of; Run} 의 triplet 형태의 symbolic knowledge 에서 각 entity (Head, Relation, Tail)에 audio, image, video를 매칭시켜 MMKG를 구축함.
- 각 modal data에 대한 독립적인 entity를 구성하는 것 보다 더 효율적인 방법.
- Baseline Node embedding인 Quadruple Embedding Baseline(QEB)를 고안하여 link prediction task에서 TIVA-KG가 가지는 이점을 증명한다.
2. TIVA-KG 구축방법
TIVA-KG는 동물, 사회 관계, 지리학과 같은 보편적인 지식(general knowledge)을 multimodal data로 표현한다. TIVA-KG의 구축방법, Statistics, 저장방법을 이어서 설명한다.
Source
TIVA-KG는 ConceptNet의 Sub-Graph를 기반으로 구축된다. ConceptNet은 open, multi-lingual knowledge graph로 ontology 전문가, crowd-sourcing등을 통해 수작업으로 생성된 자연어 기반 지식 그래프이다. 따라서 TIVA-KG는 ConceptNet이 가지는 고품질의 구조적, textual 정보를 상속받아 사용한다는 이점을 가진다.
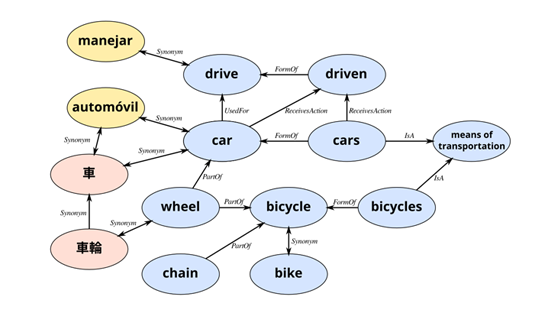
추가로 TIVA-KG를 위해 특별하게 제작된 Web crawler (저자들이 만든, 코드 공개는 되어있지 않음) 을 사용하여 Text description을 바탕으로 Google, Freesound에서 multimodal data를 수집한다. 수집된 정보는 search engine을 통해 rank되며, 가장 높은 rank의 data들만 TIVA-KG 구축에 사용하였다.
Ontology (Knowledge Representation)
TIVA-KG가 ConceptNet의 구조를 상속받기 때문에 image, video, audio modality에 대한 knowledge를
<entity, relation, entity> 형태로 표현한다. [예시: 남자는 (entity1)는 좋아한다 (relation) 여자를 (entity2)]
Multimodal Information 수집 방법
Multimodal Graph 선행 연구인 Richpedia의 경우 multimodal data를 표현할 때 각자 다른 노드와 그에 해당하는 relation을 사용한다. 예를 들어 ImageOF나 ImageSimilarity와 같은 Relation을 사용하여 image와 image 사이 혹은 image, text사이의 관계를 표현하게 되는 것인데 이는 multimodal triplet을 구축할 때 제한을 줄 수 있는 KG 설계 방법이다.
따라서 multimodal 정보로 구성된 triplet을 구축하기 위해 multimodal 정보를 한 entity에 대한 attribute로 추가하고, entity간의 관계인 triplet ontology에도 multimodal 정보를 triplet attribute로 추가한다.
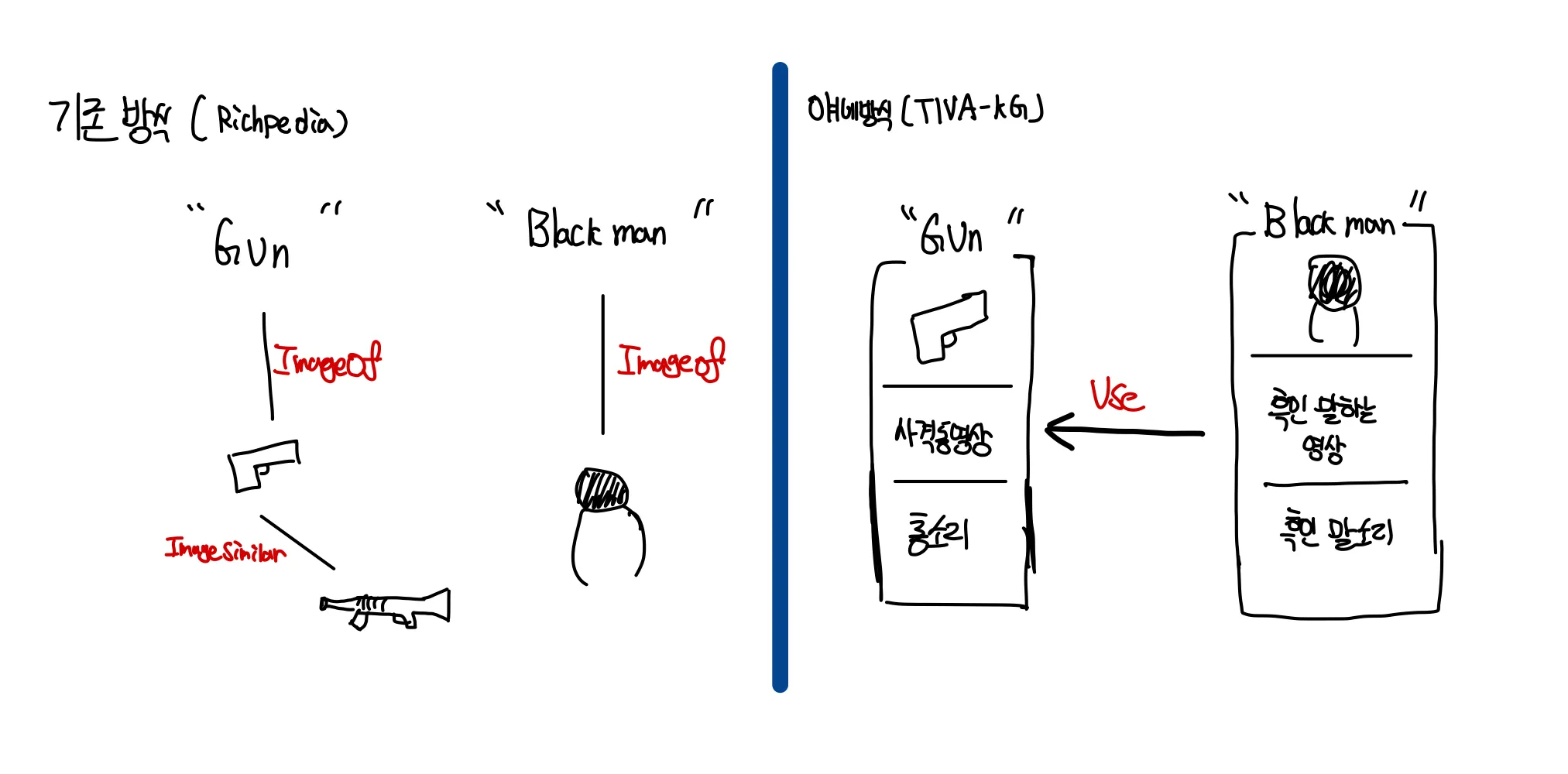
- 기존 방식은 개념 사이의 관계를 표현하는데 한계가 있지만 각 entity의 attribution에 multimodal data를 넣어주면 개념과 개념 사이의 지식관계를 표현하기에 용이하다.
Statistics
TIVA-KG는 4403,580개의 entity와 1,382,358개의 triplet들로 이루어져 있고 한 entity로부터 다른 entity까지의 이동이 보장된다.
Construction
- ConceptNet Filtering 규칙:
- ConceptNet에서 영어로만 구성된 triplet 사용
- ConceptNet에서 relation weight가 1보다 큰 relation만 사용
- 애매한 semantic meaning을 가진 relation을 제거 (예시: related to)
“CAT” 노드에서 BFS를 수행하여 새로운 이웃이 없을 때 까지 탐색된 노드들을 graph topology로 두었다.
한 entity 혹은 triplet에 대해 저자들이 정한 규칙들을 기반으로 Ontology triplet을 자연어 description으로 변환하고 이를 검색어로 하여 multimodal data를 crawling 하였다. 동영상의 경우 구글 검색시 gif 이미지를 찾도록 하여 수집하였다.
규칙 예시:
{Ontology triplet} → 자연어 description
{head : A, relation : HasA, tail : B} → A has B
{head : A, relation : PartOF | HasProperty | AtLocation | Cause, tail : B} → A B
저작권 이슈 및 효율적인 저장을 위해 수집된 raw multimodal 데이터들을 feature로 인코딩하여 vector형태로 저장하였다. 각 modality에 해당하는 pre-trained encoder와 embedding 차원은 아래와 같다.
| Modality | Feature Extractor | Embedding Shape | 비고 |
|---|---|---|---|
| Text | ConceptNet Numberbatch | N/A | - |
| Image | ResNet-101 | 2048 | - |
| Audio | VGGish | (x, 128) | x는 오디오 길이에 따라 달라짐 |
| Video-frame | HCRN (ResNet-101) | (8, 16, 2048) | pixel feature |
| Video-motion | HCRN (ResNext-101) | (8, 2048) | motion feature |
- video의 경우 처음에 16개 frame을 포함한 8개 clip으로 sampling후 128개 frame들은 ResNet에, 8개 clip은 ResNext에 fed되어 feature를 뽑아낸다.
Storing
각각의 entity(text, image, audio, video)와 triplet 에 고유한 ID를 부여하고, 이들을 각각 다른 json dictionary로 파싱하여 저장하였다 (entity dict [entities.json ]& triplet dict [ relations.json ]).
entity dict에는 ID로 indexing되어 있으며, 각 entity에는 multimodal attribute와 연결된 triplet과의 ID가 저장되어 있다. 여기서의 multimodal attribute는 raw multimodal data로 URL 형식으로 저장되어 있다.
Latent feature는 HDF5 파일에 저장되어 있으며 Raw 데이터와 같은 URL을 공유한다.
- 예시 코드
import h5py
# latent 파일
f = h5py.File('all.hdf5', 'r')
# entity는 json 파일 파싱하여 접근 가능
# 고양이 entity의 0번째 image attribute 불러오기
i = entities['cat']['image'][0]
# image attirubte의 latent feature 접근방법
print(f[i['@id']])
>> <HDF5 group "/m/en/cat/a/wikt/en_4/image/0" (1 members)>
i = entities['cat']['image'][0]
print(f[i['@id']]['feature'])
>> <HDF5 dataset "feature": shape (2048,), type "<f4">
# Torch tensor나 numpy array로 바로 변환 가능3. Quadruple Embedding Baseline (QEB)
TIVA-KG의 품질을 MMKG에 대한 link prediction task 성능을 기준으로 평가하였다. Link prediction은 주어진 graph에서 entity사이의 관계을 예측하는 task로 이를 위해서는 entity와 relation을 low-dimension의 embedding으로 representation하는 방법을 학습하는 embedding 기법이 필요하다.
그 후 link prediction을 위해, 주어진 관계(h, r, t)의 적합성을 판단하는 scoring function 를 설계하여 예측한 Relation r이 h, t를 타당하게 연결해 주도록 학습한다.
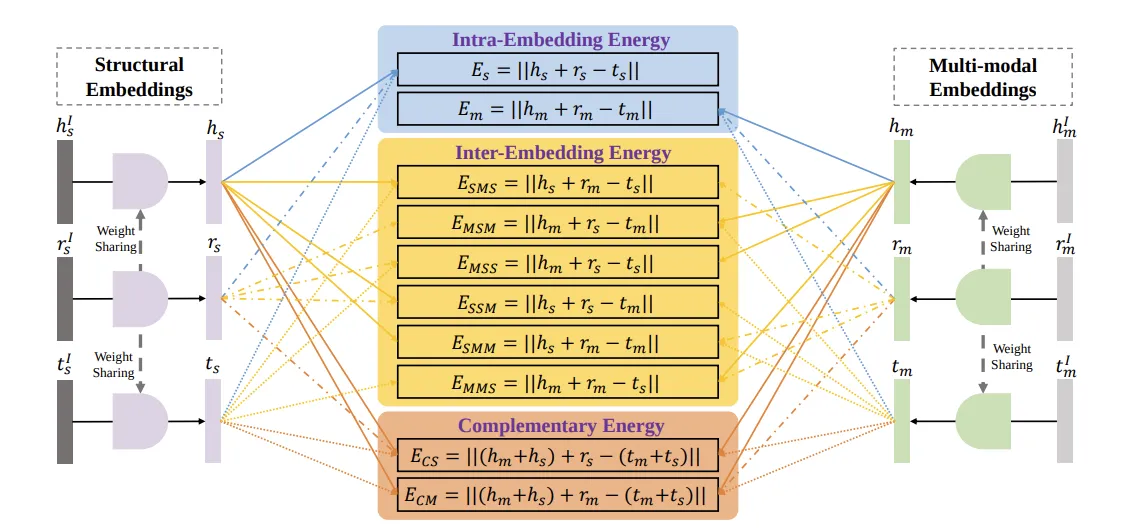
본 연구에서 제안하는 QEB는 entity와 relation을 위한 2개의 embedding을 정의한다.
- Structure Embedding () → () :
TransE의 출력인 () MLP를 통과시켜 common latent space로 projection 한다. - Multi-modal Embedding () → () :
, 으로 head, tail은 같은 modality지만 relation은 다른 modality이다. 이 역시 MLP를 통과시켜 structure embedding과 동일한 common latent space로 projection 한다.
같은 common space로 투영된 두 embedding 사이의 교차 energy function들을 정의하고, 아래와 같이 이를 모두 합한 것을 triplet에 대한 total energy function으로 정의한다.
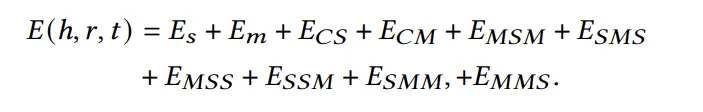
Energy function in Unsupervised-Learning:
Data manifold에서 작은 energy를 부여하도록 X를 잘 모델링 하는 것이 목표
Embedding model은 Positive sample인 와 의 energy를 최소화 하고 negative sample인 와 의 에너지를 최대화 하도록 margin-based ranking loss를 사용하여 최적화 한다.
-r 은 reversed relation을 뜻하고, ‘은 not을 의미함.
h, r, t: 나는 (H) 사랑해 (r) 너를 (t)라는 지식에 대한 임베딩이 있을 때
”나는 너를 사랑해” & “너는 사랑받아 나에게” 지식을 모델링 하도록 하고,
”나는 사랑해 너말고” & “너는 사랑받아 나말고” 지식은 지양하도록 학습함.
4. Experiments
TIVA-KG의 퀄리티 평가를 위한 Task는 앞서 언급하였듯이 link prediction 으로 고정하였다.
Triplet 관점에서 link prediction은 head, relation을 입력하면 tail을 예측하거나, relation, tail을 입력하면 head 를 입력하는 Task이다.
TransE, DistMult, TransD와 같은 Unimodal link prediction 모델들의 경우 TIVA-KG의 structure embedding과 multimodal embedding을 concat하여 하나의 embedding으로 합쳐 예측하도록 하였다.
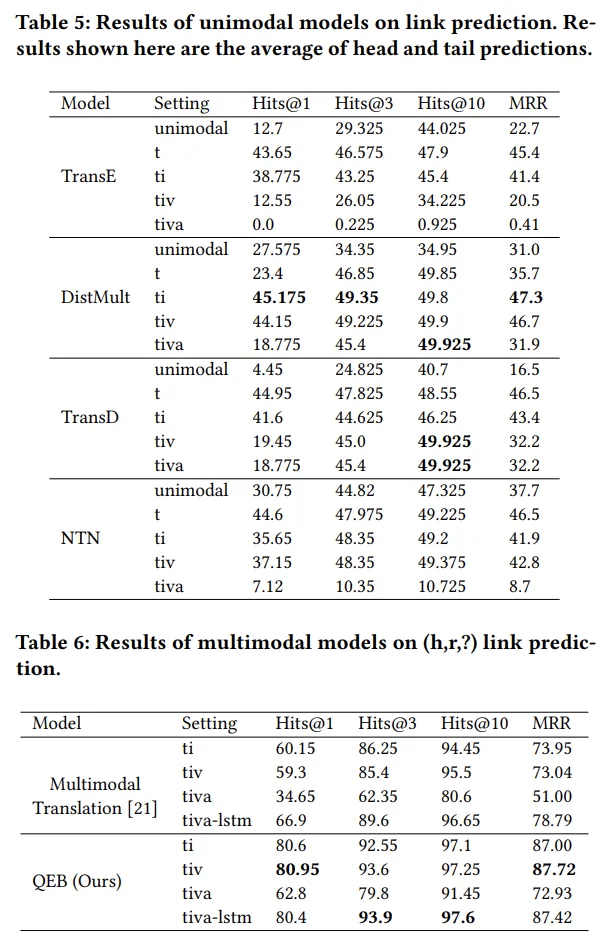
위 실험결과를 보면 QEB가 다른 multimodal translation보다 더 좋은 성능을 보여줄 뿐만 아니라 uni-modal link prediction model에서도 multimodal knowledge graph가 link prediction에 더 좋은 성능을 보여줌을 확인할 수 있다.
즉 multi-modal knowledge가 추가된 지식 그래프가 더 풍성하고 다채로운 지식을 제공한다는 것을 위 결과들을 통해 반증한 것이다.
5. 활용방안
Knowledge Graph 구축 코드는 없고, 가공이 완료된 지식그래프 데이터셋과 QEB 실험 코드만 제공함.
