[논문 리뷰] Open-Vocabulary Semantic Segmentation with Mask-adaptive CLIP (CVPR 2023)
Paper Review
two-stage open-vocab semantic segmentation task에서 COCO-Caption을 활용한 CLIP fine-tuning으로 2017년 supervised semantic segmentation 모델의 성능을 능가하는 모델 OV-Seg 제안
1. Introduction
Open-vocabulary semantic segmentation이란 입력되는 image를 단어의 제한없이 자유롭게 입력되는 text-description에 따라 segmentation해 주는 task를 의미한다.
이전의 work들은 대부분 pre-trained된 Vision-Language 모델을 사용하였고 특히 Two-stage approach 방법이 좋은 성능을 보였다.
Two-stage approach: class-agnostic(클래스는 구분 못하는 마스크) 한 seg-mask를 생성하고, 마스트된 이미지를 CLIP을 통과시켜 classification을 진행하는 방식으로 Open-Vocab Seg 수행
Two-stage approach는 두 가지 factor에 따라 성능이 좌지우지 되는데
- 모델이 class-agnostic mask를 얼마나 정확하게 잘 만드느냐
- mask 이미지를 CLIP이 얼마나 잘 classification 하느냐
저자들은 1, 2번 조건을 각각 ‘oracle’로 세팅 (Ground Truth로 세팅)하고, performance bottleneck을 찾았는데 mask image와 CLIP 훈련에 사용된 이미지 사이의 domain gap 때문에 2번이 문제 라는 것을 발견하였다.
따라서 저자들은 CLIP이 mask 이미지를 잘 classification할 수 있도록 Fine-tuning 하였고, open-vocabulary 성능을 높이기 위해 COCO-Caption 데이터셋의 caption들을 사용하여 더 많은 범위의 단어들에 대해 segmentation이 가능하도록 하였다. 본 논문의 Contribution은 아래와 같다.
- pre-trained CLIP이 performance bottleneck 이 발생했다는 것을 발견하고 이를 개선
- mask-category pair dataset을 caption으로부터 수집하여 Open-vocab에 대한 일반화 성능 높임
- mask prompt tuning을 통해 2에서 수집한 데이터를 바탕으로 CLIP을 효과적으로 fine-tuning함
- 좋은 성능 보임
2. Method
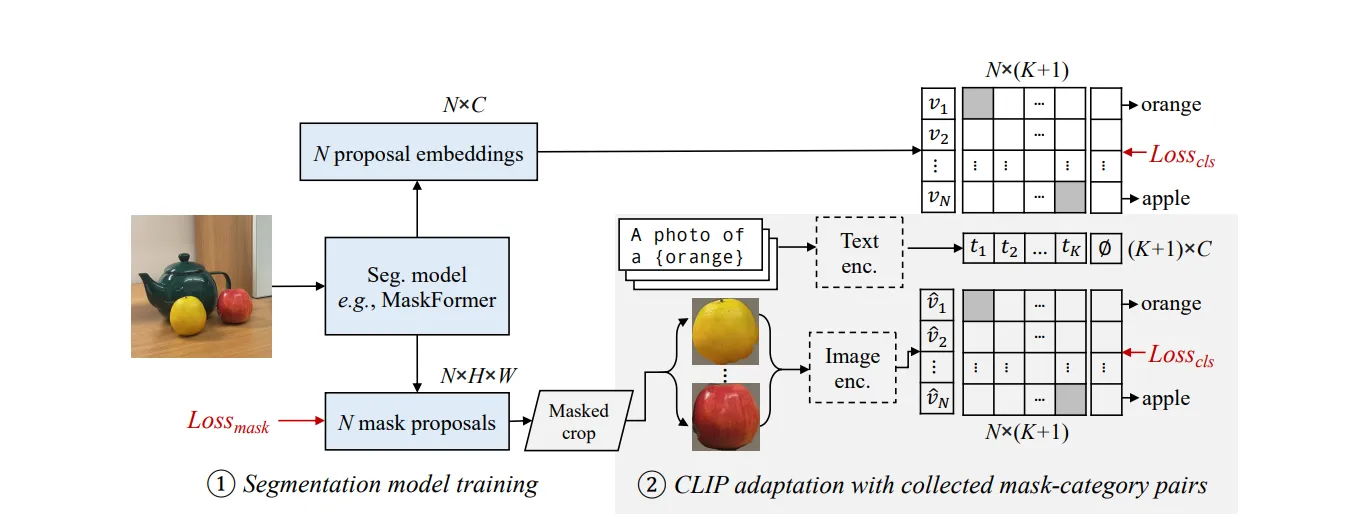
위 그림은 OVSeg 모델의 훈련 과정이다.
N개의 Class-agnostic 마스크를 생성하고 C개의 class를 분류할 수 있는 Segmentation 모델에 MaskFormer를 사용하였다.
- MaskFormer Fine-tuning
저자는 C를 CLIP model의 embedding dimension (512 or 718)로 하여 K개의 카테고리를 분류할 때 (K개의 Text) K개의 Text prompt가 CLIP text encoder를 통과하여 MaskFormer가 예측한 N개의 mask와 text Class 사이의 cosine similarity를 계산하여 pre-trained MaskFormer를 훈련시켰다. 이때 171 class를 가지는 COCO-Stuff dataset으로 MaskFormer를 fine-tune하였다 (K = 171)
사실 이렇게 훈련된 MaskFormer는 class-agnostic한 mask를 생성한다고 보기 힘들다. Object에 대한 정의가 COCO-Stuff dataset의 class에 한정되기 때문에. 예를들어 COCO-Stuff에는 face, hand, body와 같은 class가 없으므로 OVSeg는 사람을 더 미세한 파트로 Segmentation할 수 없다.
본 논문의 한계로 이걸 개선시키는 Open-Vocab 후속 연구들이 나오는 것 같음.
더 많은 class를 segmentation할 수 있도록 (Open-SAM)
- CLIP Image Encoder Fine-tuning
다음으로 mask를 사용하여 Crop된 이미지들에 대해서 입력된 text와 매칭되도록, Crop된 이미지를 CLIP Image encoder의 입력 차원에 맞게 resize하고 CLIP SIM을 측정하여 Loss로 하였다. 이때 CLIP Image Encoder의 성능을 높이기 위해 아래 2가지 기법을 사용했다.
Collecting diverse mask-category pairs from captions
CLIP이 마스크 이미지를 더 잘 인식하도록 하기 위해, 마스크 이미지 ↔ Text description pair 데이터셋으로 CLIP image encoder를 fine-tuning 하였다.
(물론 COCO-Stuff도 훈련에 사용함)
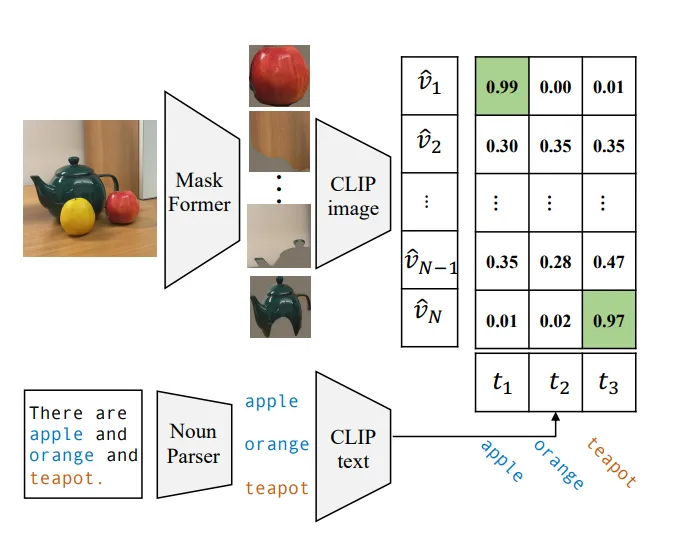
위 그림과 같이 text description에서 명사를 추출하고 추출한 명사와 mask image 사이의 CLIP Similarity가 가장 높은 것을 pair로 하여 Mask-image ↔ Text 데이터셋을 구축하고 이를 CLIP Image Encoder에 추가로 학습시켰다. 이는 COCO-Stuff에 없는 teapot과 같은 text class도 추가로 학습시킬 수 있도록 한 효과를 보였다.
Mask prompt tuning
데이터셋 구축 후 저자들이 한 고민은 Fine-tuning을 어떻게 잘 할까? 였다.
왜냐면 Mask image 특성상 빈 공간들 (0-pixel)이 많은데, 이 부분들이 real-world domain과의 급격한 Distribution 차이를 유발시키는 것이었다. CLIP image encoder는 ViT 기반으로 입력되는 이미지들이 패치로 분할 후 token화 되는데, 빈 공간들이 zero token이 되서 성능 저하를 유발한다.
이를 해결하기 위해 Mask Prompt Tuning 기법을 사용하는데, 이는 아래 그림과 같다.
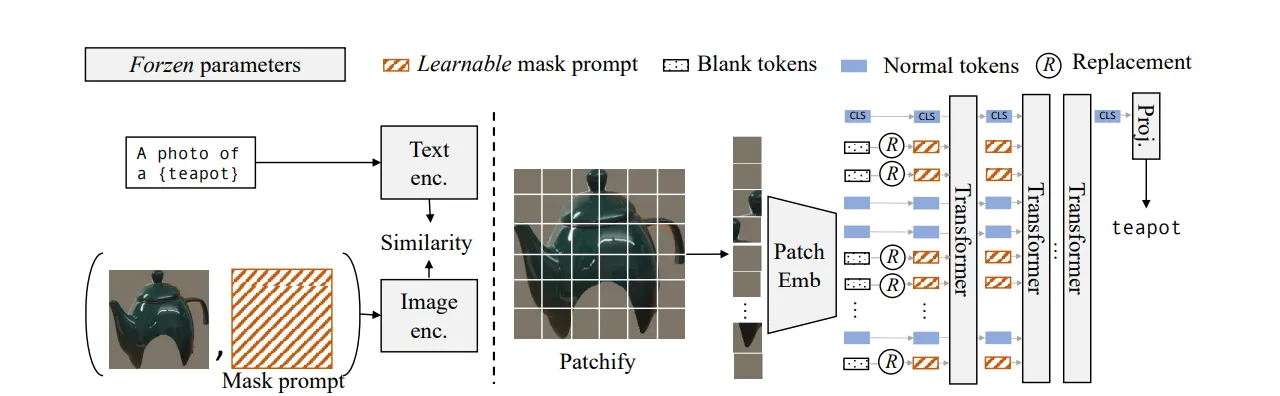
이미지 인코더 입력에 마스킹된 이미지와 압축된 이진 마스크 (Mask prompt)가 함께 입력되는데, Image encoder에서 patch token의 모든 영역이 0 token이면 mask token으로 대체하여 패치 내의 모든 픽셀이 완전히 마스킹된 경우에만 Mask token으로 대체되도록 한다.
전체 모델을 완전히 fine-tuning하는 것이 아닌 이러한 역할을 하도록 하는 Mask Prompt를 학습하는 방식으로 CLIP Image Encoder 가중치는 변경을 주지 않아, CLIP의 Image-prior를 그대로 사용하면서 원하는 기능을 수행하도록 한다.
3. Experiment
- Training Dataset: COCO-Stuff, COCO Captions
- Evaluation Dataset: ADE20K, Pascal VOC, Pascal Context
4. Limitation
- Class label이 많은 Segmentation benchmark 데이터셋에서는 성능이 별로 안 좋아 보임
- 특히 ADE20K와 같은 large scale dataset에서 성능 개선의 여지가 많이 보임
평가
- 성능저하가 발생하는 부분을 찾고, 이를 해결했다는 점에서 좋은 연구 접근 방식인 것 같음. 또한 이런 흐름을 따라서 논문이 작성되어서 읽기 수월했음.
