1. Ensemble이란
머신러닝에서 여러 개의 모델을 결합하여 하나의 최종 예측을 만드는 기법을 말한다.
앙상블을 사용하는 이유
- 단일 모델은 데이터의 일부 패턴만 잘 잡을 수 있다.
- 여러 모델의 예측을 종합해 Overfitting을 줄이고 새로운 데이터에 대한 예측을 더 안정적으로 할 수 있다.
- 모델마다 장점이 다르기 때문에 서로의 단점을 보완할 수 있다.
- 모델마다 같은 분류기를 여러 번 사용할 수 있고, 서로 다른 분류기를 사용할 수 있다.
2. Voting
Voting
- 서로 다른 종류의 분류기를 조합해서 최종 예측을 투표로 결정하는 방식이다.
- 서로 다른 모델들이 같은 데이터를 학습하고, 최종 예측은 다수결(Hard Voting) 또는 예측 확률 평균 (Soft Voting)으로 뽑는다.
- Hard Voting: 각 모델의 예측 결과가 [A, B, B]일 때, B를 최종 예측으로 선택
- Soft Voting: 각 모델의 예측이 Class A, B에 대하여 [0.6, 0.4], [0.7, 0.3], [0.4, 0.6]일 때 mean([0.57, 0.43])을 사용해 A를 최종예측으로 선택
3. Ensemble 기법
Bagging (Boostrap Aggregating)
- 같은 분류기 여러 개를 만들어 조합하는 방법
- 데이터 샘픗을 Boostrap(중복 허용 랜덤 샘플링)해서 각각의 모델을 학습시키고, 최종 예측은 다수결 투표로 뽑는다.
- Decision Tree를 사용하는 Random Forest가 대표적인 예이다.
Boosting
- 약한 학습기를 순차적으로 학습시켜 점점 강한 학습기를 만든다.
- 대표 알고리즘으로 AdaBoost, Gradient Boosting, XGBoost, LightGBM, CatBoost가 있다.
- Bias(편향)을 줄이지만 overfitting문제가 있다.
방식:
1. 첫 모델 학습 -> 오답에 가중치 부여
2. 두 번째 모델은 첫 번째가 틀린 샘플을 더 잘 맞추도록 학습
3. 1, 2를 반복하며 마지막에 가중 평균으로 최종 예측
Stacking
- 여러 다른 분류기의 예측 결과를 메타 모델이 다시 학습
방식:
1. 여러 모델 (예: SVM, RandomForest, NN)로 예측 -> 예측 결과 (출력값)를 새로운 특징으로 변환
2. 메타 모델 (보통 로지스틱 회귀 등)이 특징을 학습해서 최종 예측
4. Python 실습 - UCI HAR 데이터셋
데이터 소개
- 허리에 스마트폰을 착용하여 인간의 신체활동 정보에 대한 데이터를 스마튼폰의 주파수로 수집
- WALKING, WAKLING_UPSTARIS, WALKING_DOWNSTAIRS, SITTING, STANDING, LAYING 6가지 동작을 수행함 (Class)
- 70%의 train 데이터와 30%의 test 데이터로 구성
import pandas as pd
train = pd.read_csv("/kaggle/input/human-activity-recognition-with-smartphones/train.csv")
test = pd.read_csv("/kaggle/input/human-activity-recognition-with-smartphones/test.csv")
train.shape
# 결과: (7352, 563)train.head()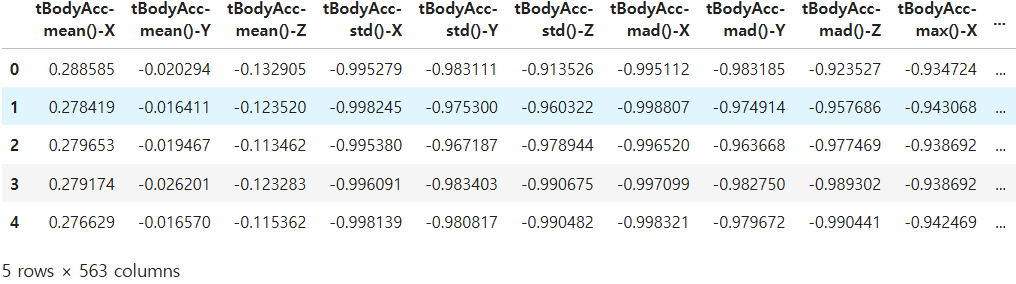
# 563개의 열을 X, y 데이터로 구분
# X 데이터
X_train = train.drop(['Activity', 'subject'], axis = 1)
X_test = test.drop(['Activity', 'subject'], axis = 1)
# y 데이터
y_train = train['Activity']
y_test = test['Activity']
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# 결과: ((7352, 561), (2947, 561), (7352,), (2947,))
```python
y_train.unique()# Label Encoding
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_test = le.fit_transform(y_test)
y_train, y_test
# 결과: (array([2, 2, 2, ..., 5, 5, 5]), array([2, 2, 2, ..., 5, 5, 5]))
# 의사결정나무 모델링
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
clf = DecisionTreeClassifier(max_depth = 4, random_state = 23)
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
accuracy_score(y_test, pred)
# 결과: 0.8096369189005769# 최적의 하이퍼파라미터 찾기 및 교차검증 적용
from sklearn.model_selection import GridSearchCV
params = {'max_depth': [6, 8, 10, 12]}
grid_cv = GridSearchCV(clf,
param_grid = params,
scoring = 'accuracy',
cv = 5,
return_train_score = True
)
grid_cv.fit(X_train, y_train)print(f'best score: {grid_cv.best_score_}')
print(f'best params: {grid_cv.best_params_}')
# 결과
# best score: 0.8512052053996311
# best params: {'max_depth': 8}
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df[['param_max_depth', 'mean_test_score', 'mean_train_score']]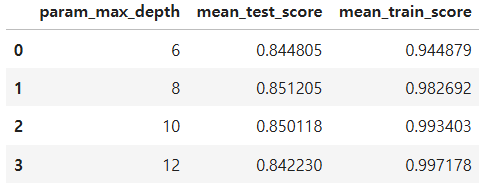
위 결과에서 최적의 max_depth는 8로 나타난다. max_depth 24는 비교적 과적합 한다고 추측할 수 있다.
# 최적의 모델을 활용한 결과 확인
best_clf = grid_cv.best_estimator_
pred = best_clf.predict(X_test)
accuracy_score(y_test, pred)
# 결과: 0.8713946386155412# 랜덤 포레스트 적용
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth': [6,8],
'n_estimators' : [10, 20],
'min_samples_leaf':[8, 12],
'min_samples_split' : [8,12]
}
rf_clf = RandomForestClassifier(random_state=23, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid = params, cv = 2, n_jobs=-1)
grid_cv.fit(X_train, y_train)GridSearchCV에서는 각 Hyperparameter에 대해서 모든 조합을 실행한다. 위 코드에서는 모든 하이퍼파라미터의 조합인 36개의 랜덤포레스트를 생성하게된다.
- n_estimators: 랜덤 포레스트에서 사용할 트리 개수
- min_samples_leaf: 리프 노드에 최소 몇 개의 샘플이 있어야 할지
- min_samples_split: 노드를 분할할 때 최소 몇 개의 샘플이 있어야 할지
- n_jobs = -1: CPU 코어 전체 사용 (병렬 처리)
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df.columns
cols = ['rank_test_score','mean_test_score','param_n_estimators','param_max_depth']
cv_results_df[cols].sort_values(by='rank_test_score').head()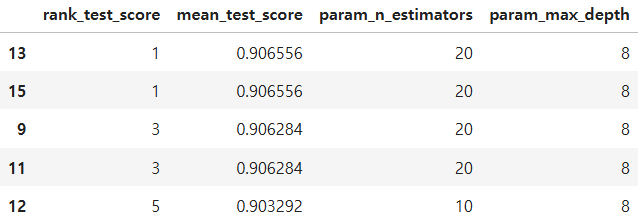
grid_cv.best_params_
grid_cv.best_score_
# 결과: 0.9065560391730141best_rf_clf = grid_cv.best_estimator_
best_rf_clf.fit(X_train, y_train)
pred = best_rf_clf.predict(X_test)
accuracy_score(y_test, pred)
# 결과: 0.9029521547336274원본 데이터에는 561개의 feature가 있는데 모두 사용하게 되면 학습에 오랜 시간이 걸리게 된다. 학습 시간 단축을 위해 feature 개수를 줄여보자.
best_cols_values = best_rf_clf.feature_importances_
best_cols = pd.Series(best_cols_values, index = X_train.columns)
top20 = best_cols.sort_values(ascending=False)[:20]
top20
각 특성들의 중요도가 개별적으로 높지 않다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(8,8))
sns.barplot(x=top20, y=top20.index)
plt.show()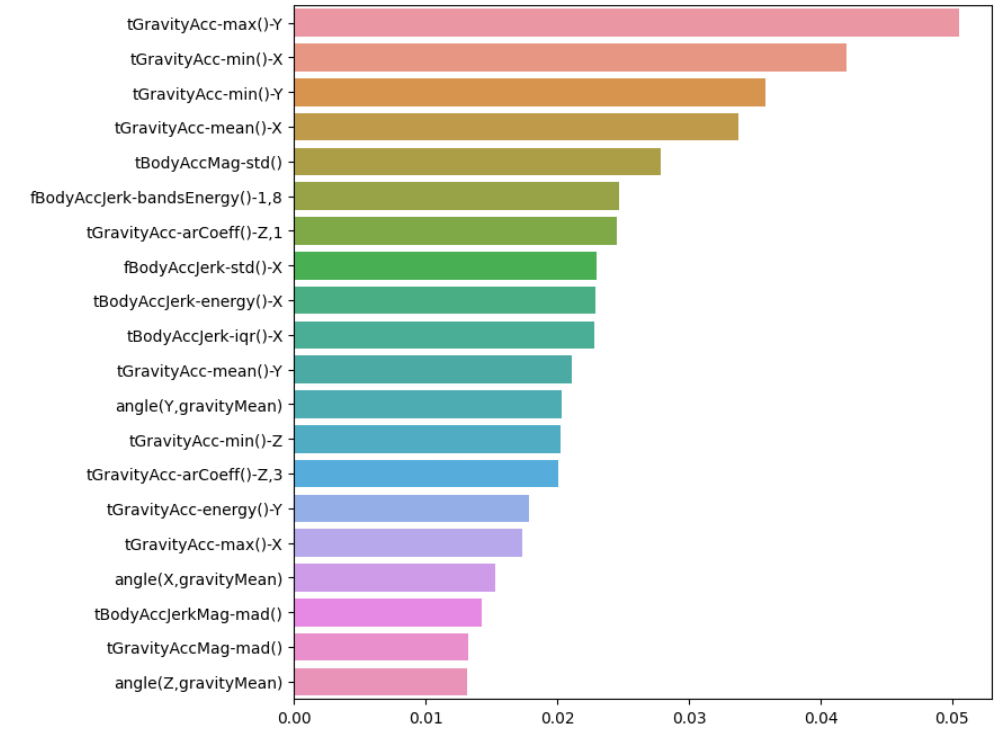
X_train_re = X_train[top20.index]
X_test_re = X_test[top20.index]
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train.reshape(-1,))
pred_re = rf_clf_best_re.predict(X_test_re)
accuracy_score(y_test, pred_re)
# 결과: 0.827960637936885모델의 성능은 저하됐지만 연산 속도가 크게 줄었다.

Data analysis, statistics