머신러닝 w/ 파이썬
1.의사결정 나무를 이용한 Iris 데이터 분류하기 (1)

Iris는 프랑스의 국화로 Veriscolor, Virginica, Setosa 3 종류로 나눌 수 있다. 꽃잎 (petal), 꽃받침(speal)의 길이와 넓이를 이용해 3개의 품종을 구분할 수 있다. R과 Python의 많은 라이브러리가 머신러닝 연습 데이터세트로
2.의사결정 나무를 이용한 Iris 데이터 분류하기 (2)

1편https://velog.io/@bryant\_/Iris-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EA%B5%AC%EB%B6%84%ED%95%98%EA%B8%B0지난 번에 학습한 의사결정나무 모델의 결정 경계를 직접 시각화해 보았다.위 그림에서
3.와인 분류하기
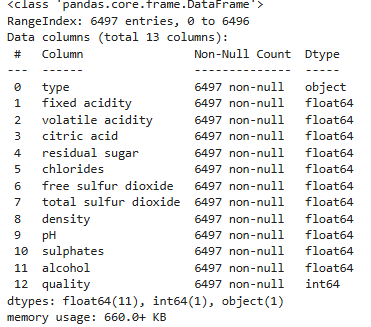
이번 코드의 경우 시간 간격을 두고 작업하여 변수명, 코드작성방법이 일정하지 않을 수 있다. 너그러이 바라봐주시길 바라며 추후 기회가 된다면 업데이트하도록 하겠다.데이터셋은 와인의 성분과 quality 점수를 제공한다. 이를 이용해 와인 type을 예측하는 모델과 qu
4.모델 평가
분류 모델의 평가분류 모델은 다음과 같은 항목을 이용해 평가한다.정확도 (Accuracy)오차행렬 (Confusion Matrix)정밀도 (Precision)재현율 (Recall)F1 ScoreROC AUC위의 오차행렬 (Confusion Matrix)을 이용해 정확도
5.파이프라인

Jupyter Notebook을 사용하면 데이터 전처리, 하이퍼 파리미터 튜닝 등 여러 반복을 진행하다보면 혼란을 야기할 수 있다.Sklearn에는 Pipeline을 이용해 여러 단계 (전처리 -> 학습 -> 예측)을 하나의 객체로 묶을 수 있다. 코드와 노트의 일관성
6.Logistic Regression
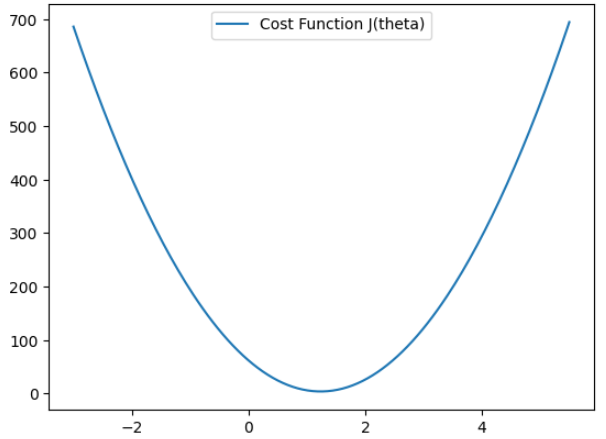
로지스틱 회귀는 독립 변수들을 사용해 사건이 발생할 확률을 예측하는, 분류용 통계·머신러닝 모델이다.비용함수모델이 얼마나 잘 예측하고 있는지를 수치로 표현하는 기준데이터 전체를 보고, 예측값과 실제값의 차이를 하나의 숫자로 요약한 것가설함수 (Hypothesis)를 아
7.Cross Validation & Hyper Parameter

과적합모델이 학습 데이터에만 과도하게 최적화된 현상. 일반화된 데이터에서 모델의 예측 성능이 떨어짐Holdout데이터를 학습용, 테스트용 두 가지로 나누는 것여전히 과적합의 가능성이 있음K-fold Cross Validation전체 데이터셋을 랜덤하게 섞은 후 K개의
8.Ensemble
머신러닝에서 여러 개의 모델을 결합하여 하나의 최종 예측을 만드는 기법을 말한다.앙상블을 사용하는 이유단일 모델은 데이터의 일부 패턴만 잘 잡을 수 있다.여러 모델의 예측을 종합해 Overfitting을 줄이고 새로운 데이터에 대한 예측을 더 안정적으로 할 수 있다.모
9.Principal Component Analysis(PCA)
차원 축소 (dimensionality reduction)과 변수 추출(feature extraction) 기법데이터의 분산을 최대한 보존하면서 서로 직교하는 새 축을 찾아 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법변수를 축소함으로써 과적
10.K-Means Clustering

비지도 학습(Unsupervised Learning) 기법레이블(정답)이 없는 데이터를 비슷한 것끼리 그룹으로 묶는 알고리즘목표는 각 데이터 x_i와 그것이 속한 클러스터의 중심 c_j 사이의 거리(보토 유클리드 거리)의 제곱합을 최소화하는 것동작 원리1\. K개의