분류 모델의 평가
분류 모델은 다음과 같은 항목을 이용해 평가한다.
- 정확도 (Accuracy)
- 오차행렬 (Confusion Matrix)
- 정밀도 (Precision)
- 재현율 (Recall)
- F1 Score
- ROC AUC
오차행렬, 정밀도(Accuracy), 정밀도(Precision), 재현율(Recall),
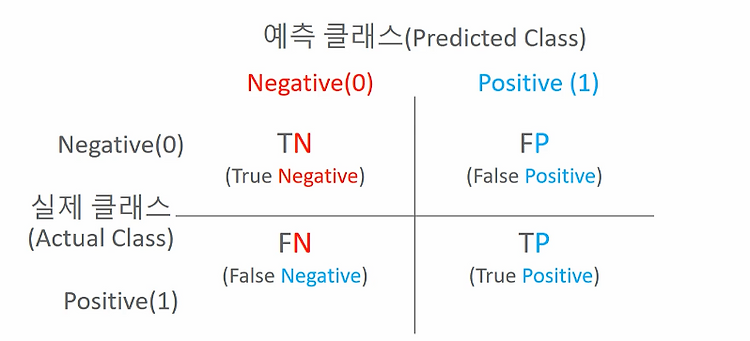
위의 오차행렬 (Confusion Matrix)을 이용해 정확도, 정밀도, 재현율 세 가지를 계산한다. 오차 행렬은 4가지 결과를 해석할 수 있다. 뒤의 알파벳은 예측값이고 앞의 알파벳이 그 값이 맞았는지를 나타낸다.
- TP: Positive라고 예측했고 맞춘 경우
- FN: 실제 Positive인데 Negative로 예측
- TN: Negative라고 예측했고 맞춘 경우
- FP: 실제 Negative인데 Postive로 예측한 경우
Accuracy(정확도)
- 정확도: 전체 데이터 중 알맞게 예측한 비율
Precision
- Precision 양성이라고 예측한 것 중에서 실제 양성의 비율
- 실제 음성인 데이터를 양성이라고 판단하면 안되는 경우 중요하다. (예: 스팸메일)
스팸 메일이 아닌 메일을 스팸메일 분류(양성)함에 넣으면 안된다. 양성일땐 확실히 양성이어야한다.
Recall (재현율)
- 참인 데이터 중 참이라고 예측한 것
- 보통 1이 중요한 상황 (예: 암환자 판별)
암일가능성이 있는 환자를 암이 아니라고 판단하면 안되다. 우선 의심되는 환자를 T로 분류하고 정밀검사를 진행야한다. Positive를 놓치지 말아야한다.
Threshold
이진 분류
- 모델은 각 샘플에 대해 Positive일 출력한다.
- 보통 0.5를 threshold를 사용하며 상황에 맞게 이를 조정한다.
- 예: threshold > 0.7을 positive로 조정. 나머지는 negative.
다중 클래스
- 모델은 각 클래스별 확률 분포를 출력한다.
- 일반적으로 가장 확률이 큰 클래스를 예측값으로 선택한다.
- 하지만 확률이 낮으면 정확도가 낮은 예측이 될 수 있으므로 threshold를 추가할 수 있다.
- 예: {Class A: 0.4, Class B: 0.35, Class C: 0.25}, threshold = 0.5 -> 어떤 클래스도 확실하지 않는다고 판단
F-1 Score
- Recall과 PRecision의 조화평균 (harmonic mean)
- Recall과 PRecision이 어느 한쪽으로 치우치지 않고 둘다 높은 값을 가질수록 F-1 Score는 높은 값을 가진다.
- Precision과 Recall이 모두 클 때 F1도 커짐.
- 둘 중 하나라도 0에 가까우면 F1은 낮아짐. (조화평균이기 때문에 균형을 중시).
- 단순 평균(산술평균)보다 한쪽이 낮으면 더 크게 페널티를 줌.
ROC Curve (Receiver Operating Curve), AUC (Area Under the ROC Curve)
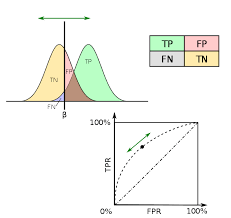
ROC Curve
- Threshold를 1 - 0으로 변화시키면서, 각 threshold별 (FPR,TPR) 좌표를 연결한 곡선
- x축: FPR(False Positive Rate) 위양성률
- y축: TPR(True Positive Rate, 재현율)
- Treshold = 1 -> 전부 음성으로 예측 (0,0)
- Treshold = 0 -> 전부 양성으로 예측 (1,1)
- 직선에 가까울수록 모델 성능이 떨어지는 것으로 판단
AUC
- ROC 커브 아래의 면적
- 1.0 = 완벽한 분류, 0.5 = 랜덤추측, 0.5 - 0.1 = 모델이 어느정도 양성을 구분
- 모델의 성능을 하나의 수치로 요약함
ROC 커브를 그린 후 재현율(Recall, TPR)과 위양성률(FPR)이 어떻게 변하는지 확인 후 이에 맞는 Treshold를 선정한다.
Python 실습
import pandas as pd
df = pd.read_csv("/kaggle/input/wine-quality-data-set-red-white-wine/wine-quality-white-and-red.csv")
df['color'] = df['type'].replace({'red':0,'white':1})
df['taste'] = [1 if i > 5 else 0 for i in df['quality']]
df.tail()
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 데이터 분리
X = df.drop(['type','taste', 'quality'], axis = 1)
y = df['taste']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 23, stratify = y)
#모델 학습
clf = DecisionTreeClassifier(max_depth = 2, random_state = 23)
clf.fit(X_train, y_train)# 모델에 훈련용, 테스트용 데이터를 넣어 예측하고 정확도를 산출
y_pred_tr = clf.predict(X_train)
y_pred_ts = clf.predict(X_test)
accuracy_score(y_train, y_pred_tr), accuracy_score(y_test, y_pred_ts)
# 결과: (0.735039445834135, 0.7215384615384616)from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve
# 지표
print("Acc", accuracy_score(y_test, y_pred_ts))
print("recall_score", recall_score(y_test, y_pred_ts))
print("precision_score", precision_score(y_test, y_pred_ts))
print("roc_auc_score", roc_auc_score(y_test, y_pred_ts))
print("f1_score", f1_score(y_test, y_pred_ts))clf.predict_proba(X_train)
import matplotlib.pyplot as plt
# 1 (white)에 대한 probability만 가져온다.
pred_proba = clf.predict_proba(X_test)[:, 1]
fpr, tpr, threshold = roc_curve(y_test, pred_proba)
pd.DataFrame({'threshold':threshold,'fpr':fpr,'tpr':tpr})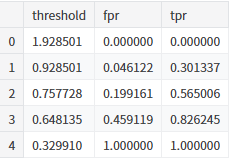
# 시각화
plt.figure(figsize=(10,8))
plt.plot([0,1],[0,1],'r')
plt.plot(fpr,tpr)
plt.grid()
plt.show()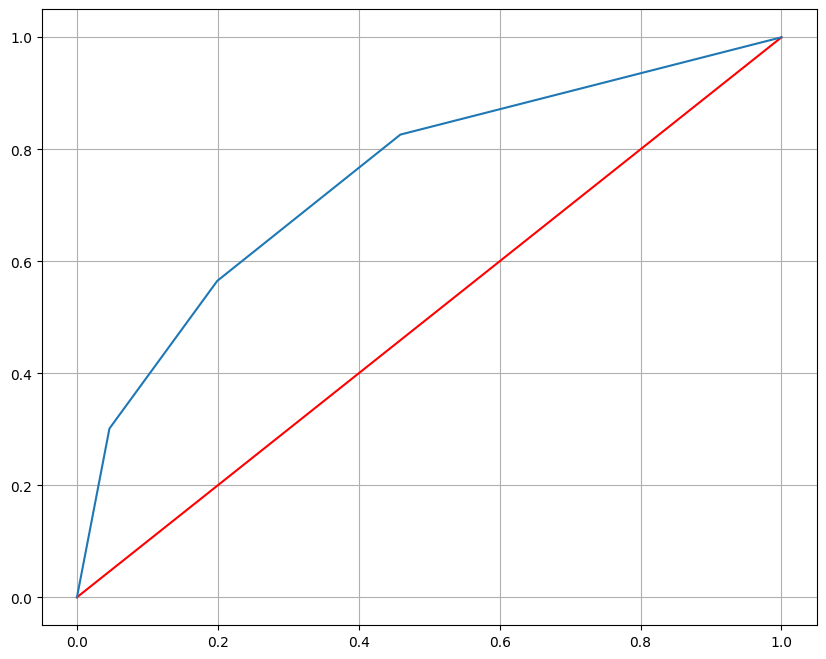

Data analysis, statistics