
1. Model Selection
1.1 Cross Validation
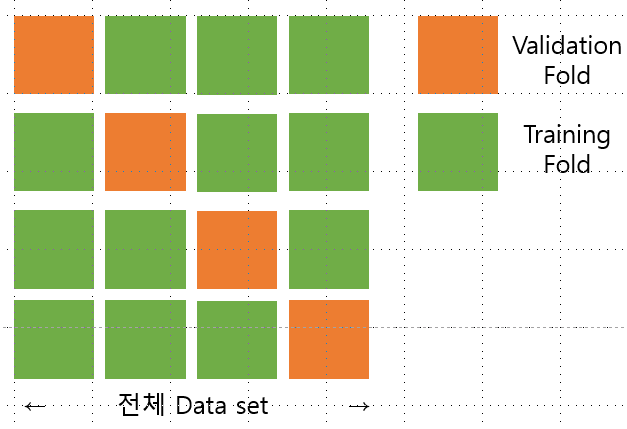
위의 그림처럼 전제 Data set을 Validation(검증)/Training(훈련)용으로 나눈다. 초록색 데이터로 훈련을 시키고 나면은 주황색 데이터로 훈련한 모델을 검증한다. 이걸 K번 한다(K는 Validation Fold의 수 = 전체 쪼갠 Block의 수!)
1.1.1 왜 하는 걸까?
- 데이터의 크기가 작은 경우. 이를 어느정도 해결해줄 수 있다.
- 서로 다른 Machine Learning 모델을 비교해주고, 얼마나 성능을 낼 수 있을지에 대해 추측해볼 수 있다.
- 여러 번의 검증 결과를 종합해서 일반화를 할 때의 성능을 확인할 수 있다.
만약, 운이 너무너무 좋아서, 우연의 일치로 딱 한번 검증을 했을 때 결과가 좋게 나왔다. 이거를 바로 Test에 사용하고, 실제 업무에 사용해도 좋을까?(뭔가 그러면 안될것 같다는 느낌이....)
실제에도 좋을 수 있고, 안 좋을 수 있다. 그렇기에 여러 번 교차검증을 하면서 일반화 성능을 확인할 수 있다.
+ 최적화와 일반화의 차이는?
-
최적화(optimization): 파라미터와 하이퍼파라미터를 조정해서 모델의 성능을 높이는 것. 주어진 데이터를 학습시켜 모델이 좋은 성능을 내게 하는 것.
-
일반화(generalization): 새로운 데이터로도 훈련했을 때의 성능을 유지할 수 있는지 확인하는 것. 주어지지 않은 새로운, 다른 데이터로도 좋은 성능을 낼 수 있도록 하는 것.
1.2 최적의 하이퍼파라미터를 구해주는 라이브러리 2가지
-
GridSearchCV: Grid는 격자라는 뜻. 일정한 범위(격자)를 정해주면, 범위 내의 모든 조합을 비교해서 내가 정한 Score를 기준으로 하이퍼파라미터값을 구해준다. 단, '모든' 조합을 비교하기 때문에 느리다. 대신에 정확하다. 범위를 넓게 잡으면? 당연히 오래 걸린다....
-
RandomizedSearchCV: 이름에서도 알 수 있듯이 랜덤으로 확인해본다. Grid와 비교해보면 범위 내에서 Random하게 하이퍼파라미터의 조합을 비교해서 그 값을 구해준다. Grid에 비해 빠르고, 확률적 탐색을 진행해 어느 정도 정확하다고 볼 수 있다. 범위를 넓게 잡으면? Local Minima 문제에 빠져서 최적의 하이퍼파라미터 값을 놓칠 수 있다.
그럼 그렇게 하이퍼파라미터를 뱉어내면은 다시 fit 시켜야하나?
맞다. 근데 pipe에서 수정하는 것이 아니다. 라이브러리 공식 문서를 보면 'refit'의 default=True로 되어있다. 이걸 따로 False로 바꾸지 않는 이상. 훈련한 데이터가 자동으로 재훈련된다고 볼 수 있다.
그렇게 Test를 돌려보니, 결과값이 달라졌다. 👏
+ CrossValidation(CV)와 RandomizedSearchCV의 차이?
둘 다 CV가 들어가서 똑같은 건가 할 수도 있겠지만....
CV는 데이터 셋의 크기가 작을 경우 이로 인해 생기는 문제를 보완해주고, 모델의 일반화를 위해 성능을 검증해보는 것으로 이해하면 좋겠다.
한편, RSCV는 이러한 CV의 개념을 활용해서 최적의 하이퍼파라미터 값을 확인해 보는 것으로 이해하면 된다!
++ Check the list of available parameters with 'estimator.get_params().keys()'
RandomizedSearchCV를 사용하다가, 지속적으로 발생한 문제였다......
sorted(pipe.get_params().keys())을 사용하면 전체 pipe에 있는 파라미터 값들을 보여준다. 이걸 그대로 복붙!! 하면 오류를 줄일 수 있다...
꺼진 불도 다시보자! 가 생각났던 오류...
