1. 학습 키워드
- 데이터프레임 핸들링
- transpose, pivot table, melt, stack, unstack
2. 학습 내용
0. Wide Format, Long Format
wide format: 측정값을 모두 한 행에 표시. 열 이름으로 그 측정값의 의미를 나타냄
long format: 긴 형식. 하나의 관찰값이 하나의 행에 위치
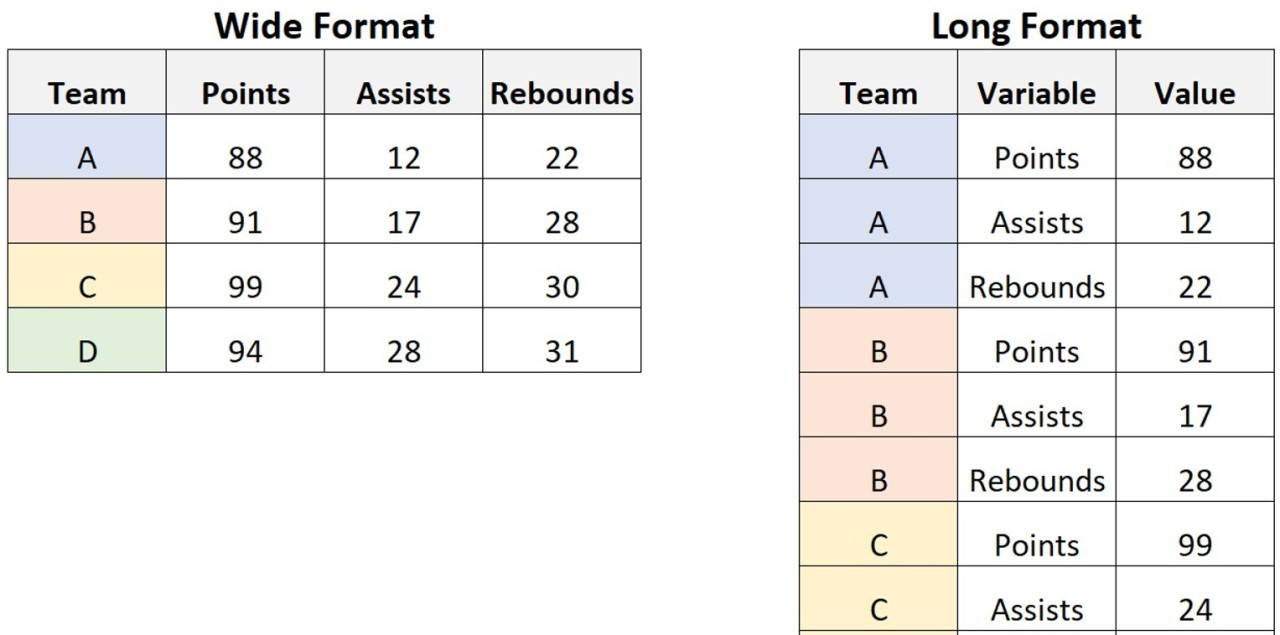
1. Transpose
- 행렬 전환
데이터프레임.T
2. Pivot Table
pd.pivot_table(데이터프레임명, index=컬럼명, columns=컬럼명, values=컬럼명, aggfunc=연산방식)
- index: 인덱스(축) 으로 사용될 열
- columns: 열로 사용될 열
- values: 값으로 사용될 열
- aggfunc: 연산 방식
필수 파라미터: columns를 제외한 데이터프레임명, index, values, aggfunc
3. melt
- 피벗 형태의 테이블을 기존 형태로 다시 변형해줌.(wide format -> long format)
- ID로 지정한 컬럼을 기준으로 여러개의 컬럼을 variable 컬럼에 쌓고 ID와 variable에 해당하는 값을 value 컬럼에 넣어줌.
- 위에서 아래로 쌓는 방식
- 필수 파라미터: id_vars
데이터프레임명.melt(id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
- id_vars : 기준이 될 열( 그대로 유지할 열 )
- value_vars : 기준열에 대한 하위 카테고리를 나열할 열을 선택( 병합할 열 )
- var_name : 카테고리들이 나열된 열의 이름 설정( 병합 후 표현할 열 이름 )
- value_name : 카테고리들의 값이 나열될 열의 이름 설정( 기본값: value )
- col_level : multi index의 경우 melt를 수행할 레벨을 설정
- ignore_index : 인덱스를 1,2,3, ... , n으로 설정할지 여부. 디폴트값은 True로 1,2,3, ... , n으로 설정됨
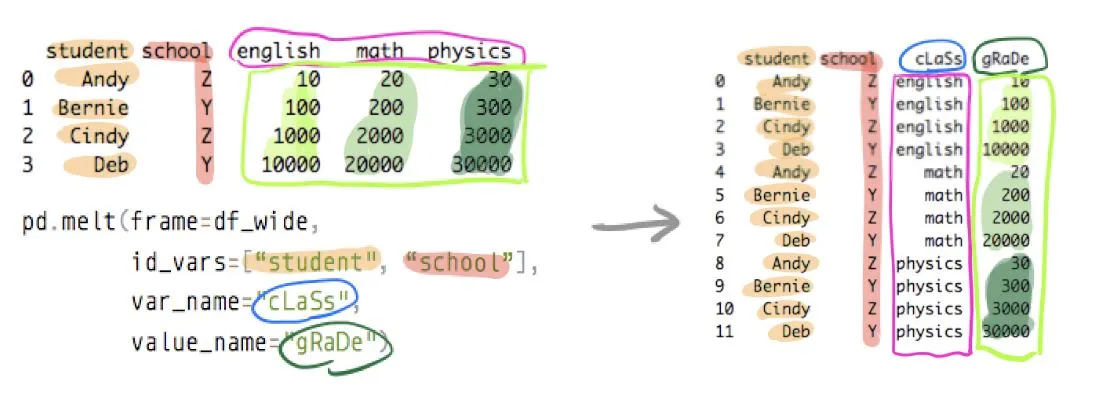
실습
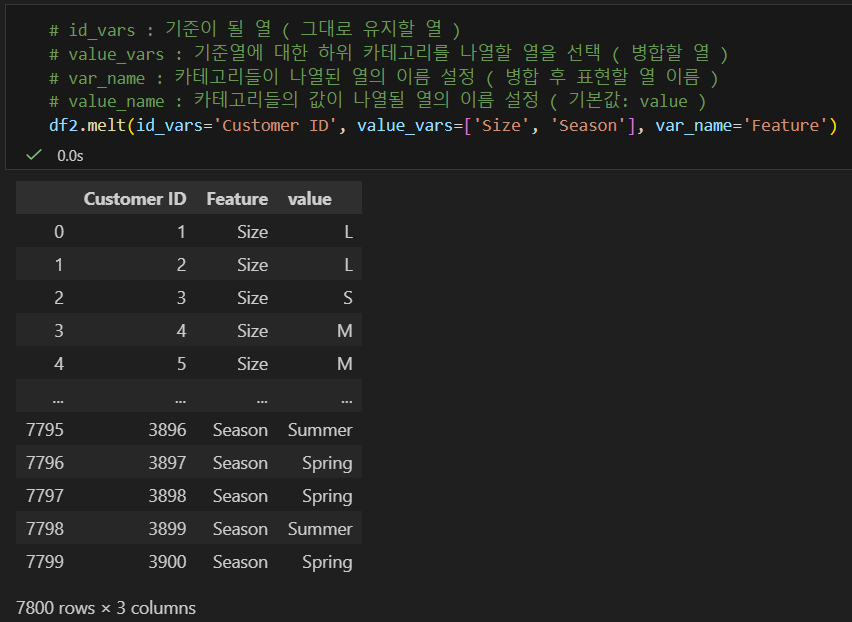
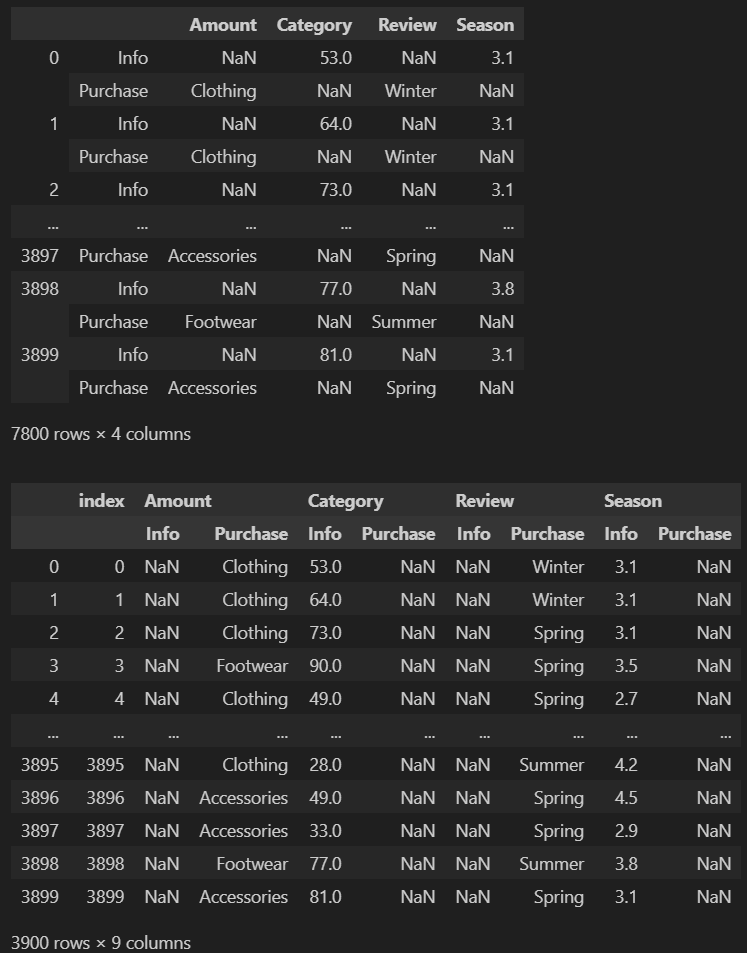
4. stack
- 컬럼을 인덱스로 이동
(melt는 컬럼을 long 형태로 변환해주지만 stack은 인덱스로 보낸다) - 내가 이해하기로는 stack 이니까 컬럼을 아래로 나열하는(쌓는)방식 이라고 생각하면 될 듯.
- 멀티 인덱스 처리 가능
데이터프레임명.stack(level=-1, dropna=True)
- level: stack을 수행할 인덱스 레벨을 지정.
- dropna: 스택을 수행한 결과에서 결측값을 제거할지 여부를 지정. 기본값은 True로, 결측값을 제거함.
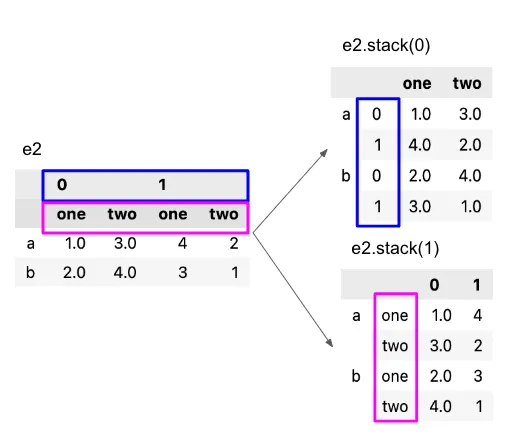
추가 팁) - 멀티 인덱스 강제로 만들기
pd.MultiIndex.from_tuples([('Purchase', 'Amount'), ('Purchase', 'Review'),
('Info', 'Category'), ('Info', 'Season')])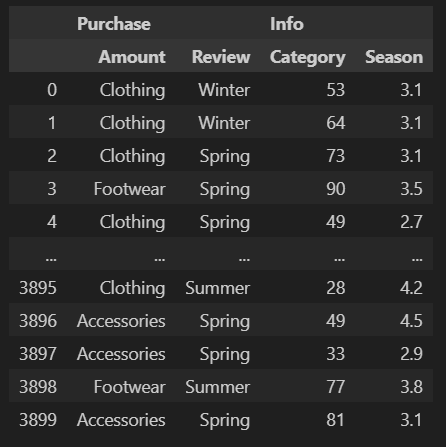
5. unstack
- 인덱스를 컬럼으로 변환
- 세로로 나열된 인덱스를 가로 컬럼으로 나열(스택을 푼다)한다고 생각하면 될 듯.
- 멀티 인덱스 처리 가능
데이터프레임명.unstack(level=-1, fill_value=None)
- level: unstack을 수행할 인덱스 레벨을 지정.
- fill_value: unstack을 수행한 결과에서 결측값을 채울 값을 지정. 기본값은 None으로, 결측값을 그대로 둠
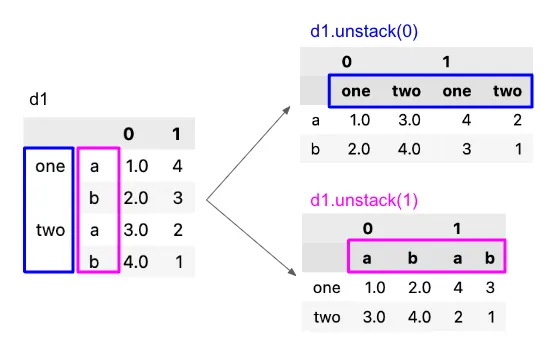

df_stacked_0과 df_unstacked_0 결과.
여기에서는 인덱스가 2개여서 unstack(1)로해도 unstack(-1)과 결과는 같음.
3. 배운점
- melt, stack, unstack에 대해서 알게 됐다. melt와 stack은 모두 가로로 길게 되어있는 컬럼을 세로로 배치해 길게 보는 방법이다. 차이점은 melt는 기존 컬럼들은 하나의 세로로 긴 컬럼으로 쌓지만 stack은 인덱스로 보낸다는 차이점이 있다.
