1. 학습 키워드
- 머신러닝
- 통계 세션 메모
2. 학습 내용
머신러닝
머신러닝
- AI를 실현하기 위한 방법중 하나. 데이터로 부터 특징이나 규칙을 찾아내서 학습하는 것
ex) 스팸 메일에 특정 단어나 형태가 자주 등장하는 공통점(패턴)이 있을 수 있는데 이를 자동으로 스팸으로 분류
딥러닝
- 인공 신경함으로 이루어져있음.
머신러닝 활용 예시
제조업
- 예측 유지 보수(장비 고장 시점 예측)
- 품질 관리(이미지 분석, 센서 데이터 분석으로 불량 여부 판별)
- 생산공정 최적화
- 수요 예측
- 에너지 효율 최적화
마케팅
- 고객 세분화(비슷한 취향, 행동을 하는 사람들 끼리 그룹을 나누는 것)
- 추천 시스템
- 마케팅 캠페인 성과 예측
- 고객 생애가치(LTV) 예측: 얼마나 많은 수익을 가져다 줄지 예상
금융
- 과거 금융 기록, 소득, 직장, 대안데이터(신용 평가를 위한 데이터 like 구매이력, sns 등)를 바탕으로 신용평가. 돈을 잘 갚을 수 있는지를 점수로 매기는 과정
- 위험 관리(손실 위험을 계산하고 미리 대비)
- 자동으로 주식 매매, 투자 종목 추천
챗봇, 보험 업무 고도화 등
머신러닝 vs 기존 통계 분석
통계분석: 왜? 라는 질문에 집중
머신러닝: 얼마나 잘?에 집중(정확도, 재현율)
머신러닝 종류
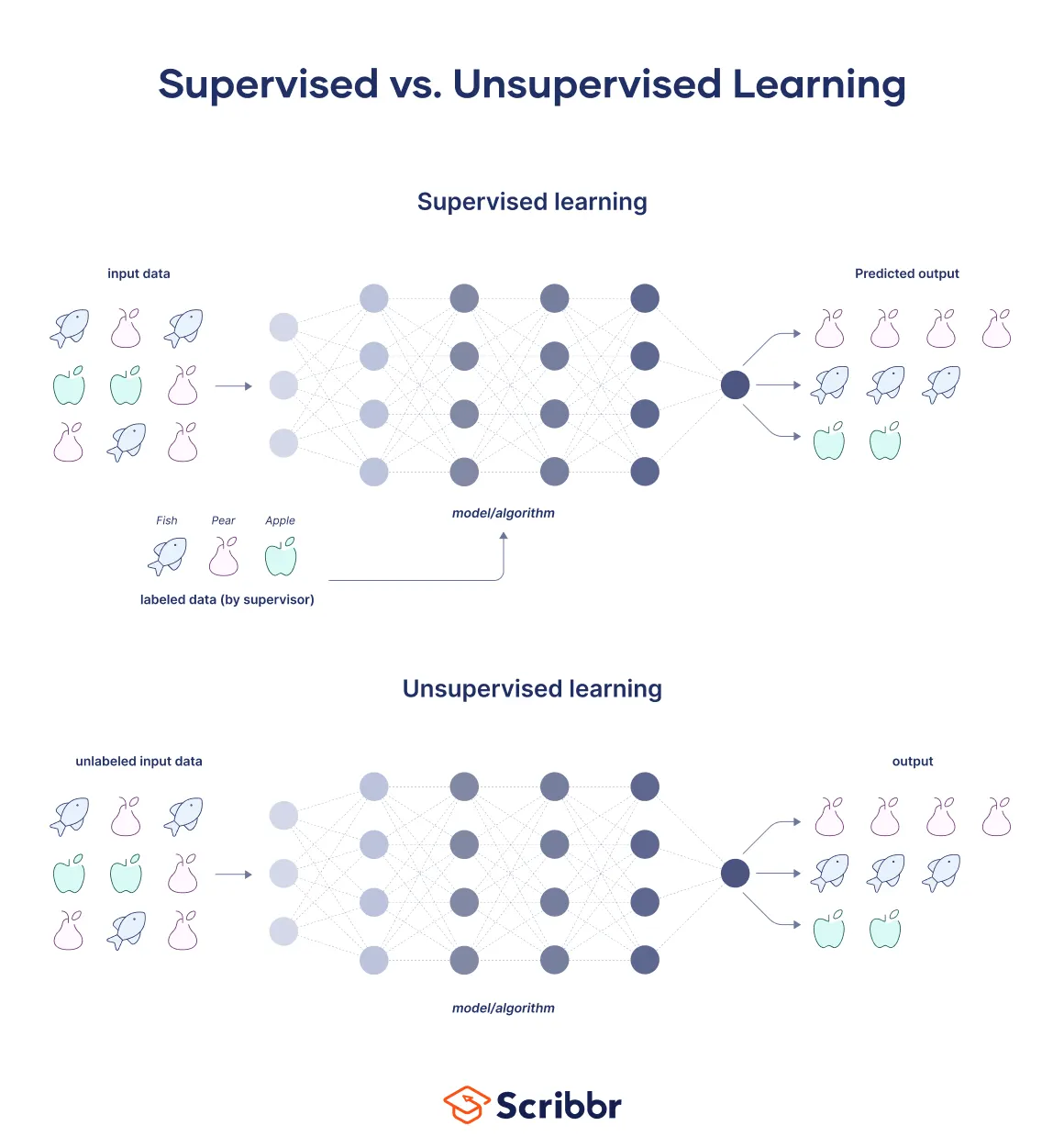
1) 지도학습
: 정답값이 있는 데이터를 학습
- 분류: 어느 그룹에 속하는 지를 결정(스팸 메일 분류, 대출 상환 가능 여부 분류)
- 회귀: 숫자로 된 결과를 예측(주택 가격 예측, 주가 예측)
2) 비지도학습
: 레이블 없이 데이터 패턴을 스스로 찾음
- 군집화: 성향이 비슷한 사람이나 사물을 자동으로 묶어내는 기법(군집 분석, 문서 토픽 분석)
- 차원 축소: 데이터의 특징이 너무 많아서 복잡한 데이터를 핵심 정보만 남기고 압축하는 기법. 변수 선택과는 다르다. 변수 선택는 일부 변수만 선택하는 것.
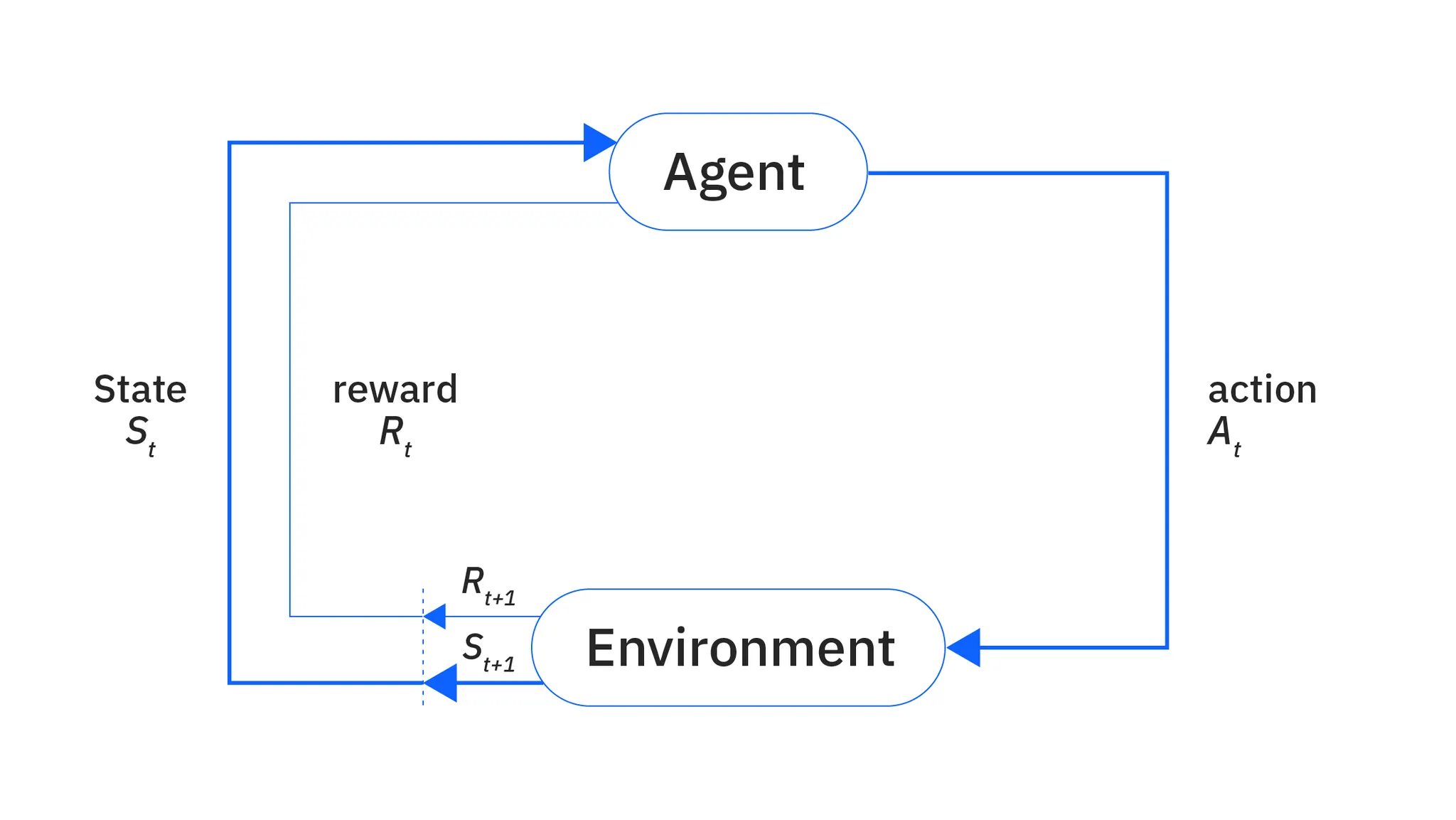
3) 강화학습
: 리워드가 높아지는 방향으로 행동하도록 함. 초기에 구조만 잘 설정해놓으면 됨. 에이전트가 환경과 상호작용하며 보상을 최대화하도록 학습.
- 에이전트란? 학습을 수행하는 주인공. 게임으로 치면 플레이어, 로봇으로 치면 로봇 자체가 에이전트
- 환경이란? 에이전트가 움직이고 상호작용 하는 무대
- 보상이란? 에이전트가 잘했을 때 얻는 점수나 잘못했을 때 받는 벌점 같은 개념
머신러닝 모델링 프로세스
-
데이터 수집(웹 크롤링, 센서 측정, 설문 조사, DB 추출 등)
-
전처리
- 결측치 처리
- 이상치 처리
- 스케일링(각각 다른 단위를 쓰는 데이터를 비슷한 수준으로 맞춤)
- 트리기반 모델은 스케일링을 안해줘도 됨.
- 범주형 변환(글자로 된 정보를 숫자로 바꿔주는 과정)
- 원-핫 인코딩(빨강=(1,0,0), 파랑=(0,1,0))
- 레이블 인코딩(숫자에 순위 의미가 생겨버릴 수 있어 주의 필요)
- 모델링
- 지도학습: 분류, 회귀
- 비지도학습: 클러스터링, 차원 축소(K-Means, PCA 등)
- 성능 평가
- 분류: Accuracy, Precision, Recall, F1-score 등
- 회귀: MAE, RMSE, R^2 등
- 비지도(군집): 실루엣 계수 등
- 배포
주로 백엔드 엔지니어의 영역
윤리적 이슈 & 데이터 편향
- 데이터가 편향되지 않는 것이 중요하다. 데이터를 분석할 때 편향되지 않았는지 확인을 해야함.
통계 세션 메모
확정된 사실을 말하는 것이 아니라 가장 가능성 높은 것을 추론 하는 것
기술통계
현재의 데이터를 요약하고 설명하는 통계
- 중심 경향치: 평균, 중앙값, 최빈값(카테고리 같은 범주형 데이터)
평균을 구하기 전에 데이터 분포를 확인해봐라 - 흩어짐 정도: 히스토그램, 분산, 표준편차
분한을 확인할 수 있는 시각화: 박스플랏, 바이올플랏 등
추론통계
일부 데이터(표본)을 바탕으로 전체 모집단을 추정(예측)하거나 어떤 주장이 맞는지 검정하는 통계
- 기술 통계는 있는 데이터를 요약하고 추론 통계는 없는 모집단을 예측한다.
- 우리가 뽑은 평균이 모집단의 평균과 얼마나 비슷할까?
- 확률로 불확실 성을 다루는 통계
연속형 확률분포
- 구간을 나누고 해당 구간 안에서 확률 밀도 함수에서의 면적의 넓이가 확률을 나타낸다
조건부 확률
동시확률분포
- 독립: 2개의 확률변수에 대한 동시확률분포. 한쪽이 어떤 값을 취하든지 다른 한쪽의 발생 확률은 변하지 않는다.
조건부확률
- 어떤 정보가 주어졌을 때 다른 사건이 일어날 확률
- 추론통계에서 전부다 조건부 확률이다.
추론통계
추정
- 모집단의 평균, 비율 등은 알 수 없기에 '표본'을 통해 '추정'
- 이때 범위를 정하기 위해 표본평균의 분포가 정규분포를 따른다는 전제를 사용
가설검정
- 어떤 주장이 우연인지, 아니면 통계적으로 의미 있는지를 검정하는 과정
- p-value 사용함.
표본 데이터가 정규분포가 아닌데도 모집단을 정규분포라고 가정할 수 있는가?
- 표본의 크기가 충분히 클 때 가능(대수의 법칙, 중심극한정리)
- 단, 표본이 크면 모집단이 정규이다가 아니라 표본이 정규가 아니어도 정규모델을 사용해도 된다에 가까움
** 중심극한정리: 모집단의 분포가 어떻게 생겼든 상관없이, 표본을 여러번 뽑아서 각 표본의 평균을 계산하면 그 평균은 정규분포의 형태를 이룬다.
정규화
- Z(표준점수) = (값-평균)/표준편차
- Z=1 -> 평균에서 1시그마(표준편차) 떨어져 있다는 의미. 1%라는 의미가 아니다.
3. 배운점
- 머신러닝은 데이터로 부터 특정 규칙이나 패턴을 찾아내 학습하는 방법이다. 정확도나 재현율에 조금 더 중점을 두며 얼마나 잘 예측하는 지가 중요하다.
- 추론 통계를 사용하는 이유는 표본을 통해 모집단을 추정하기 위함이다. 또한 어떤 주장이 우연인지 통계적으로 의미있는지 판단하기 위해 사용함.
