데이터 취업 스쿨 스터디 노트 -(57) Logistic Regression 및 실습 + threshold 임의 수정
제로베이스 데이터 스쿨(Data Science & Analytics)
Logistic Regression
- 회귀용도로 사용하는 것이 아니라 분류를 하기 위해 사용함.
- 로지스틱 회귀 분석을 통해 하나의 이진(0,1)종속 변수와 여러 독립 변수 간의 다변수 회귀 관계를 조사할 수 있다.
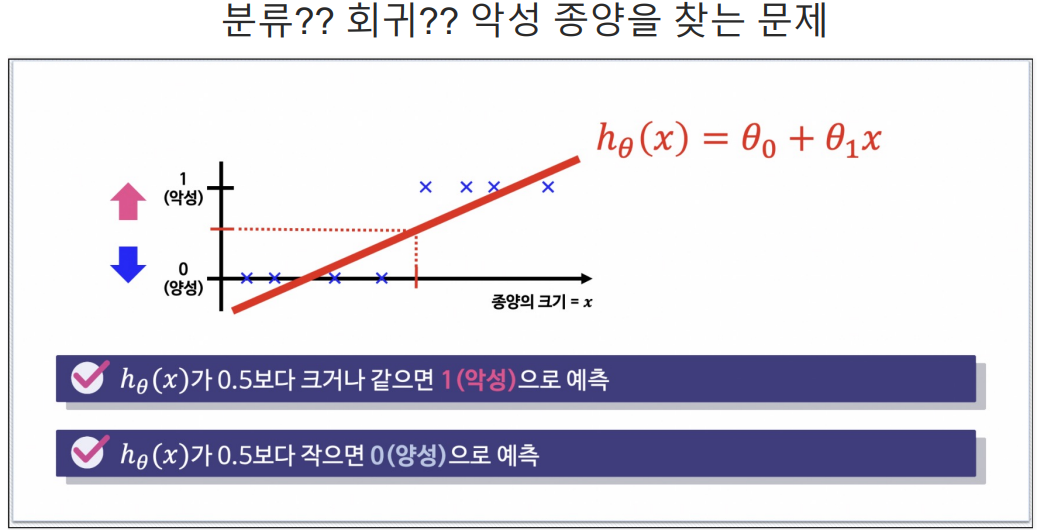
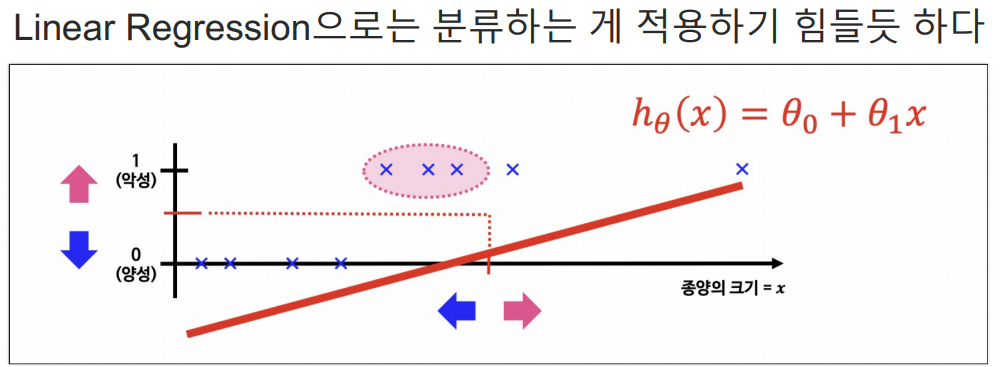
여기에는 선형회귀를 사용하기 어려움.
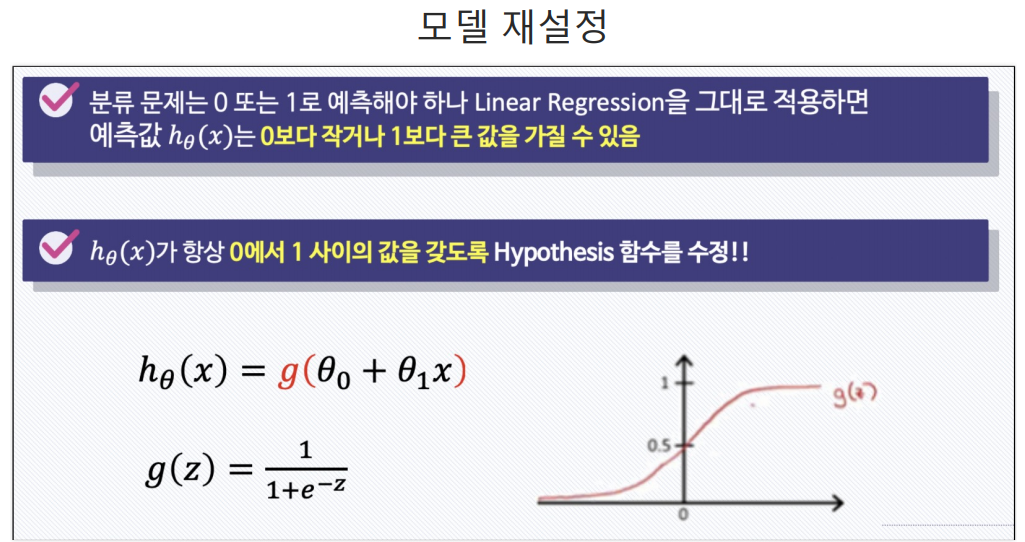
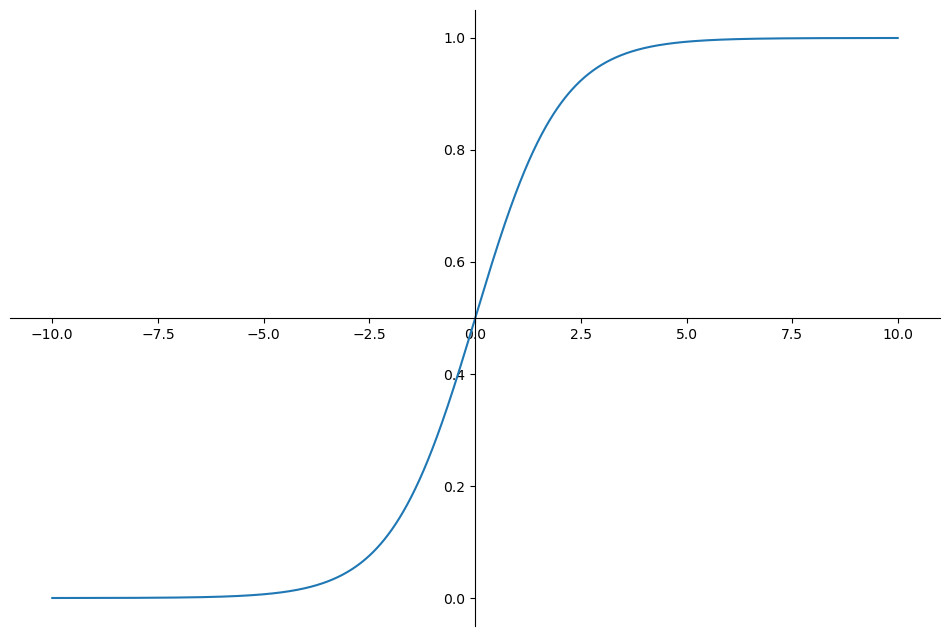
0과 1사이의 값을 갖는 시그모이드에다가 직선을 넣는 것임.
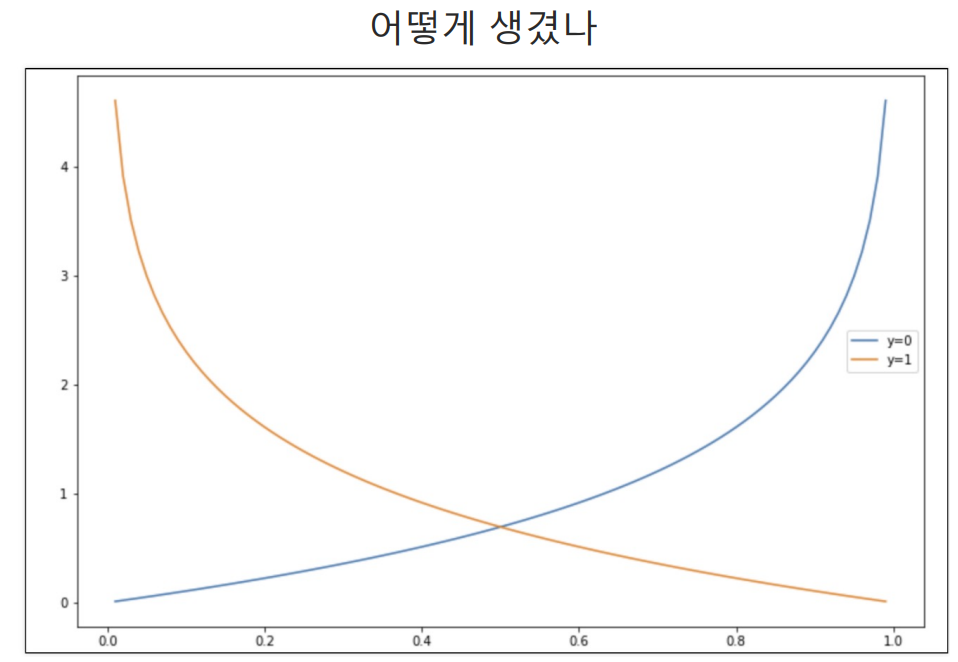
sigmoid 그래프

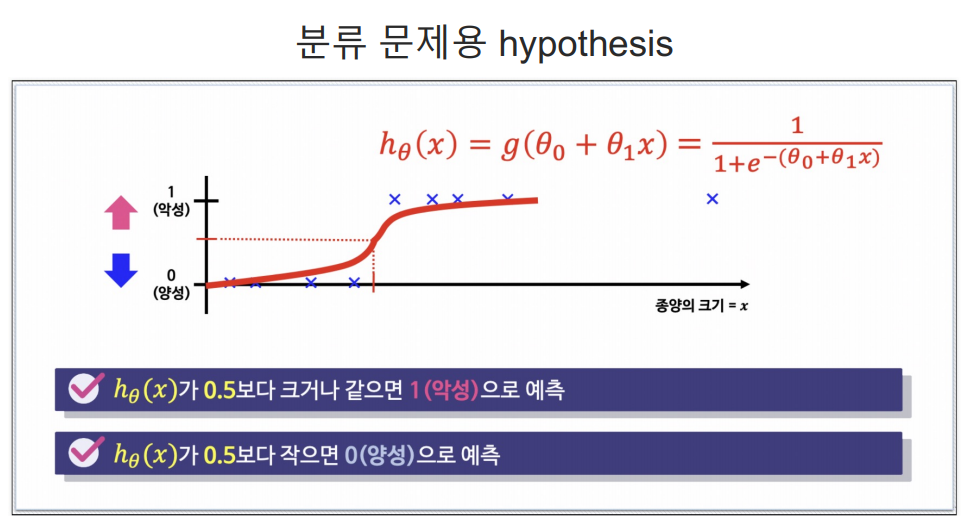
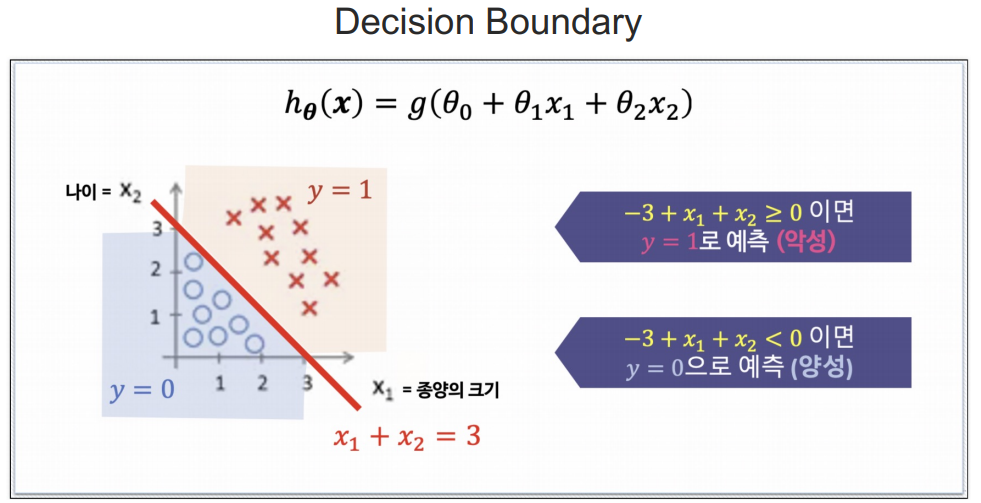
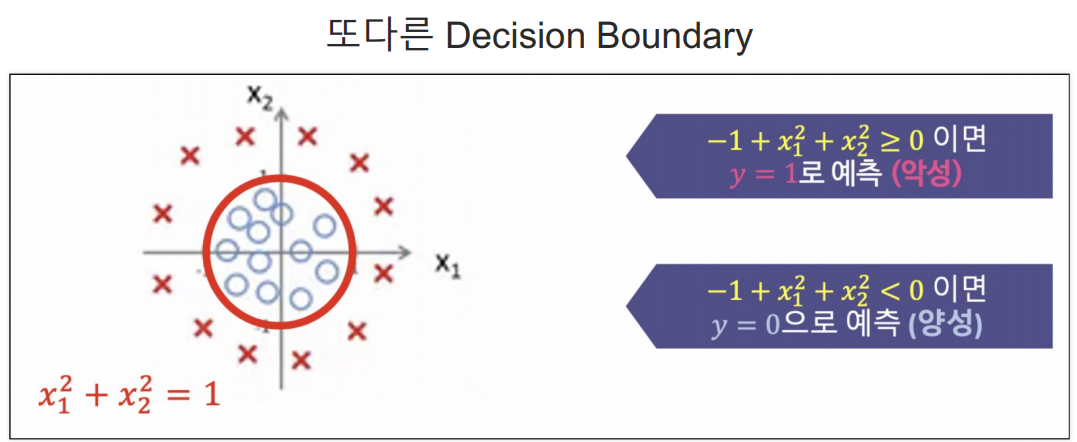
참고) 결정경계
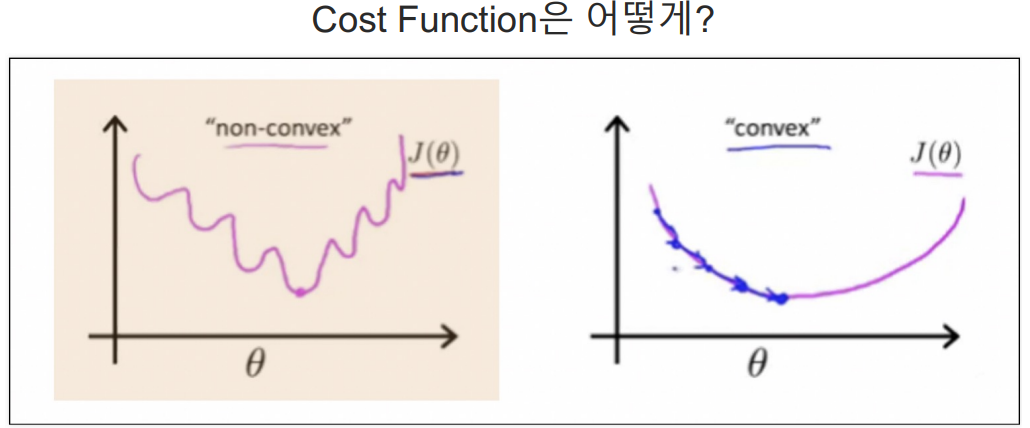
cost function
Logistic Regression에서 cost function은 선형에서 구했던 방식으로 하면 너무 복잡하다.


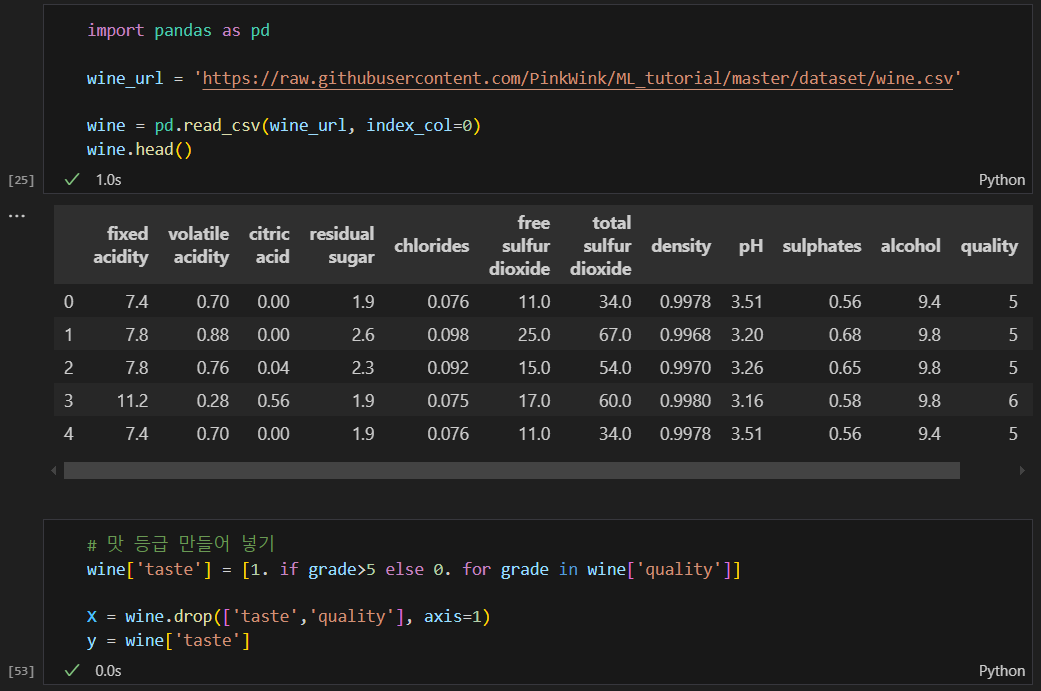
실습
데이터 받아오고 맛 등급 만들어 넣기
데이터 분리

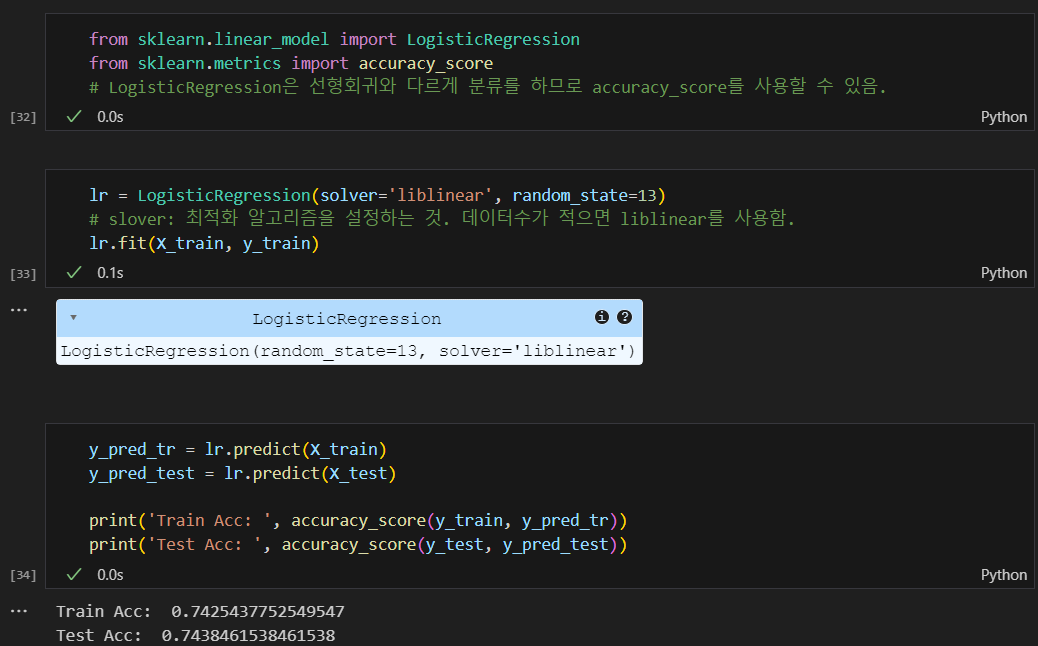
로지스틱 회귀 테스트
정확성까지 파악
스케일러까지 적용해서 파이프라인 구축
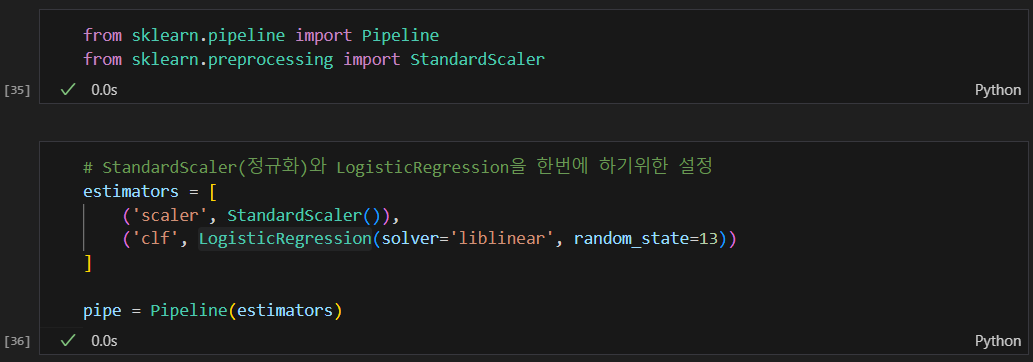
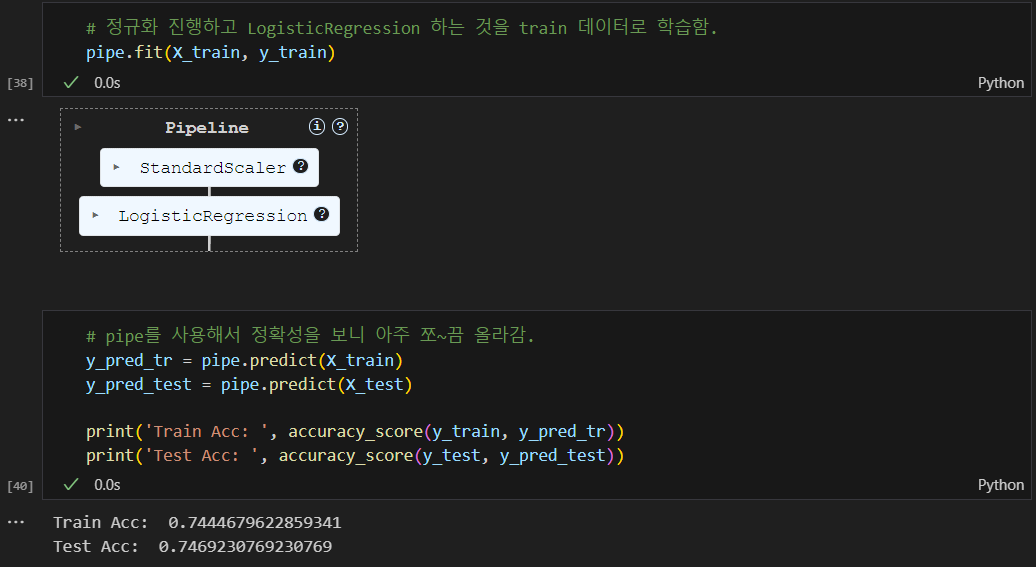
스케일러(정규화) 진행하고 하니 정확도가 조금 상승하긴함.
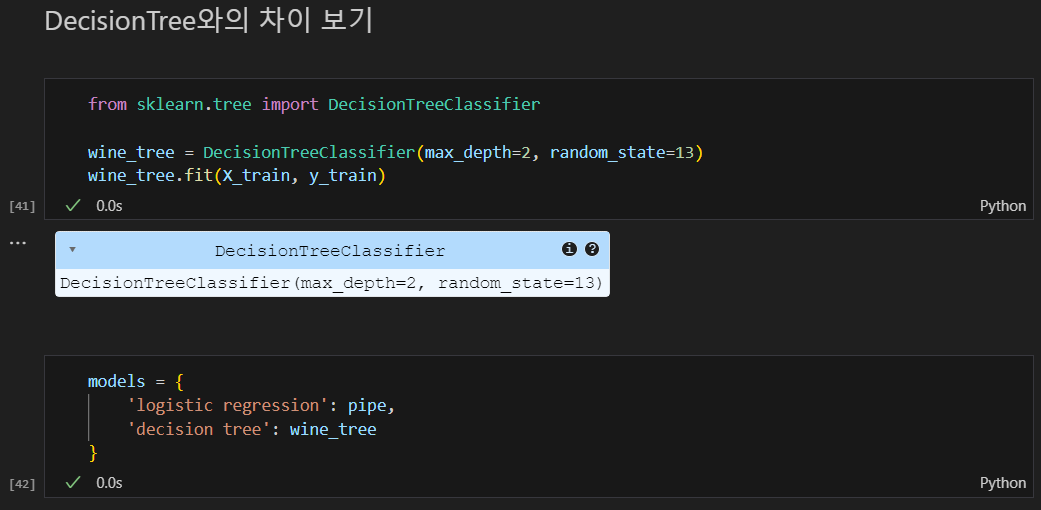
Decision Tree와의 차이를 보기 위해 결정나무 학습 및 두가지 모델로 분류
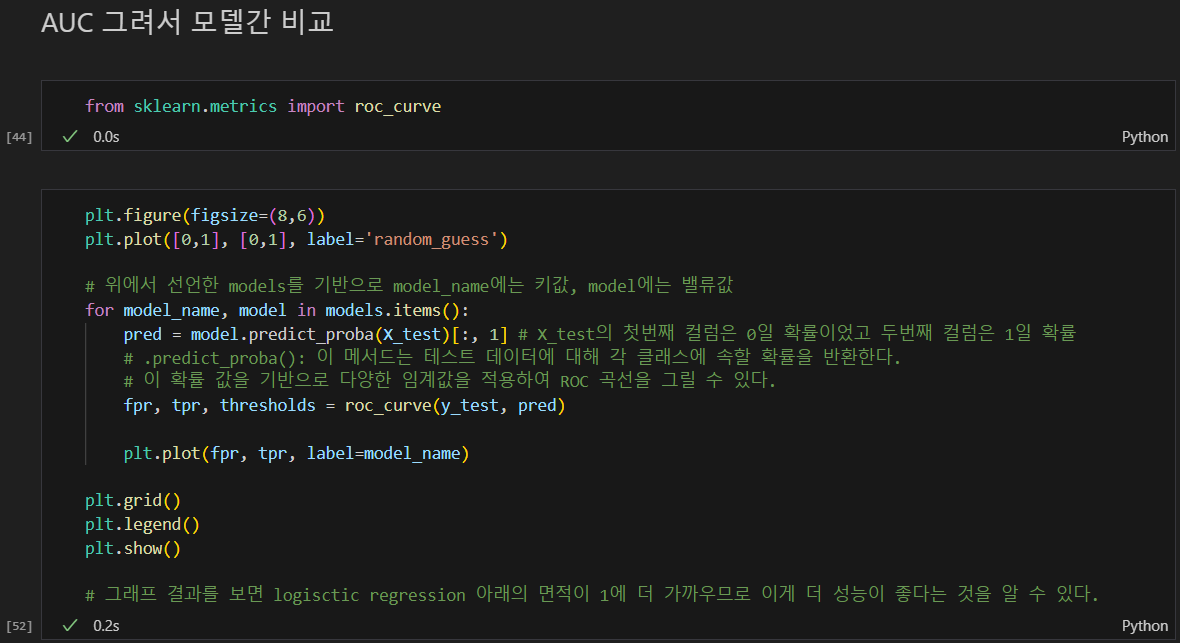
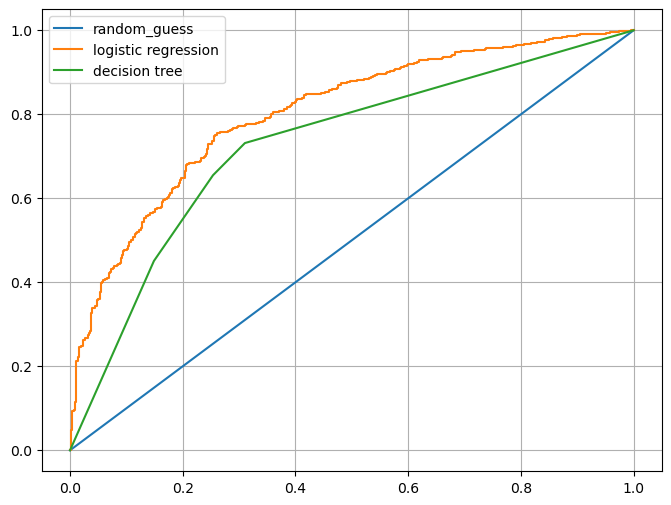
AUC 그려서 모델간 비교
- .predict_proba(): 이 메서드는 테스트 데이터에 대해 각 클래스에 속할 확률을 반환한다. 이 확률 값을 기반으로 다양한 임계값을 적용하여 ROC 곡선을 그릴 수 있다. predict()은 ROC 곡선에 사용 못함. 0과 1의 결과만 나옴.
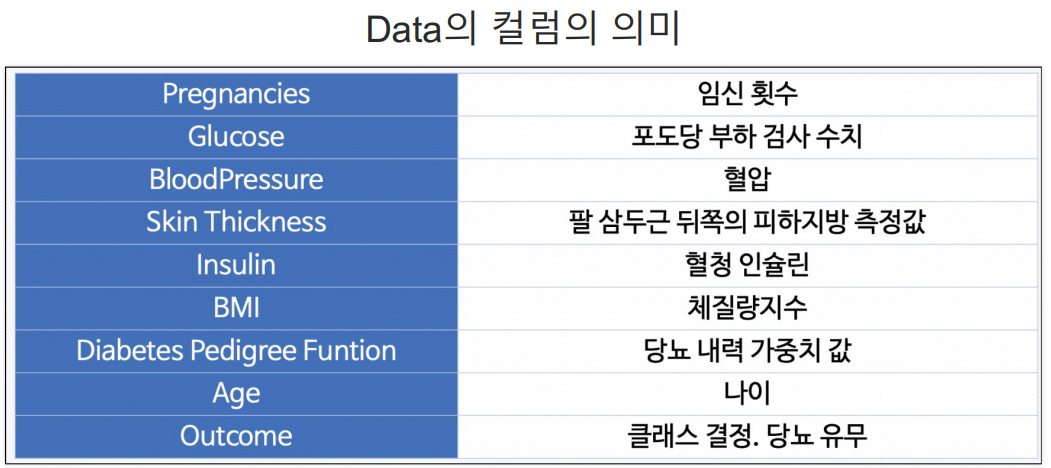
PIMA 인디언 당뇨병 문제
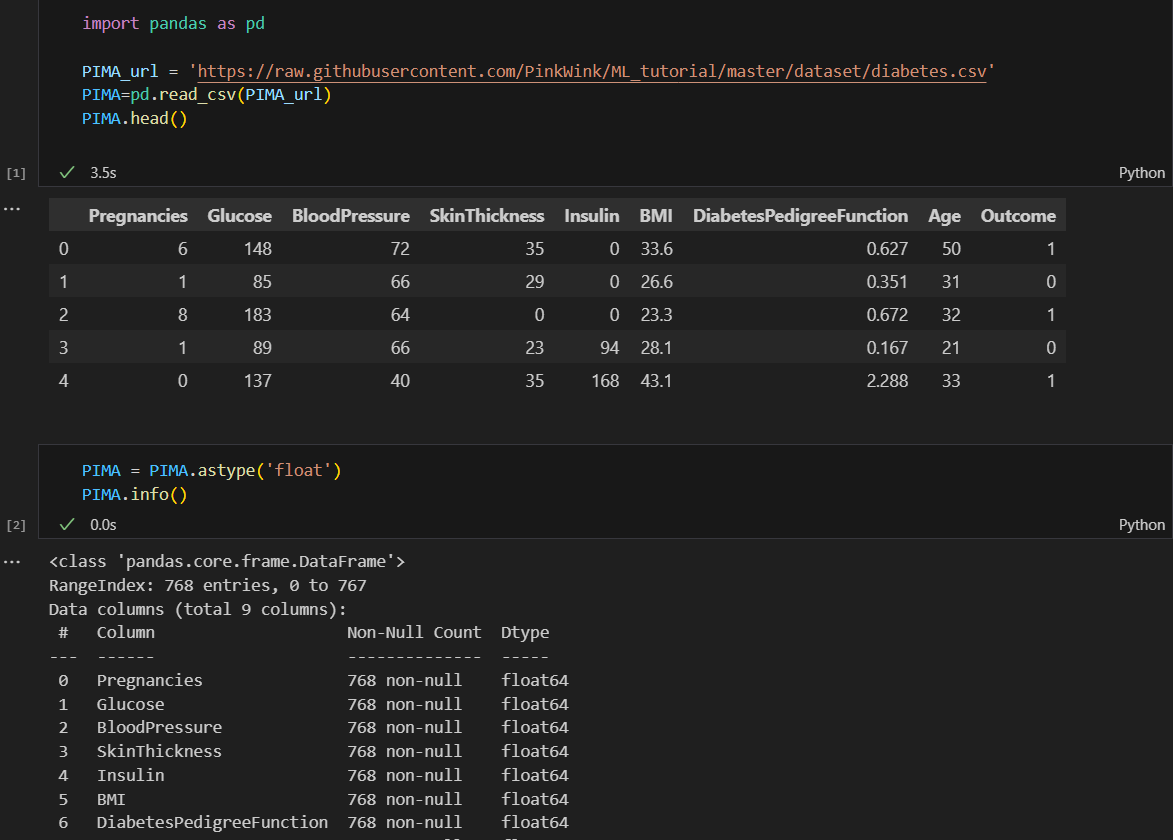
데이터 읽기 및 float으로 변환
Outcome과 다른 요소들의 상관관계 파악

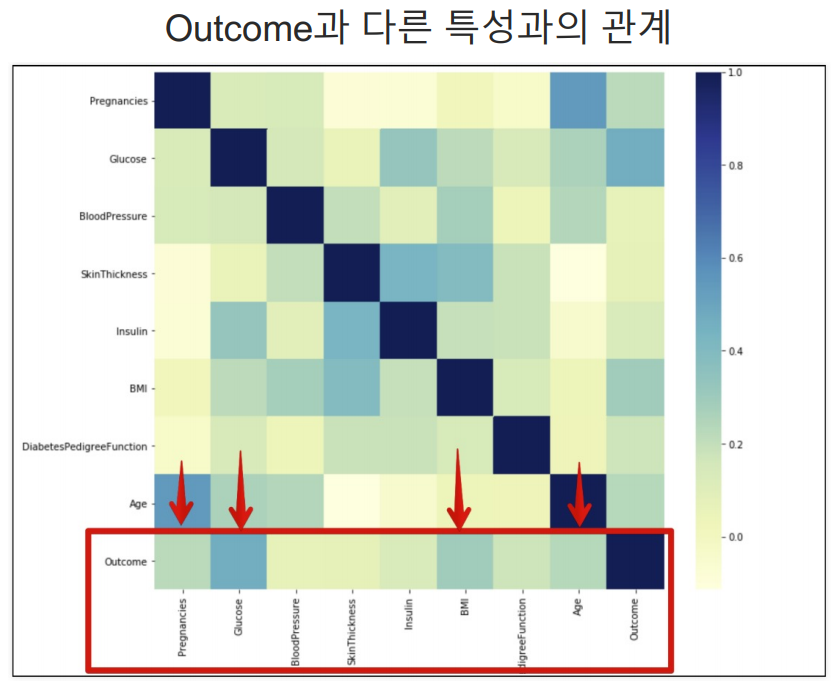
문제가 있는 데이터 확인
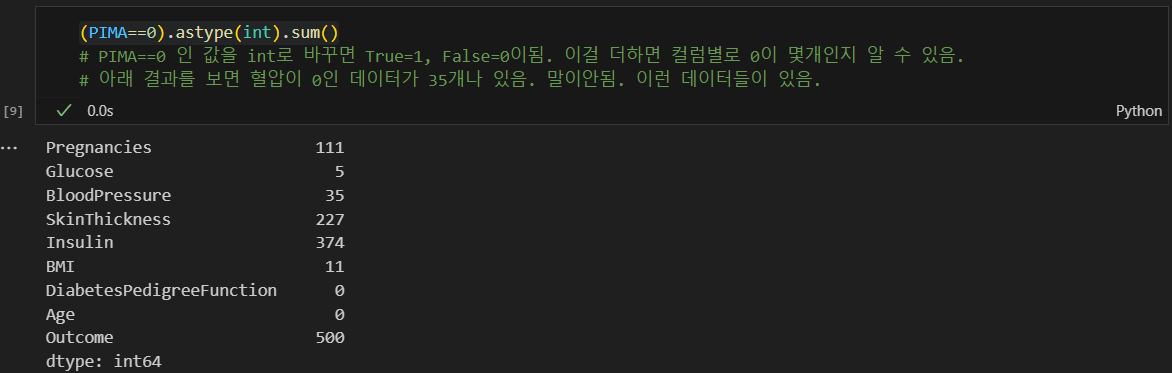
문제가 있는 데이터들은 임의로 각 열의 평균값으로 넣어줌
데이터 나누기
파이프라인 만들고
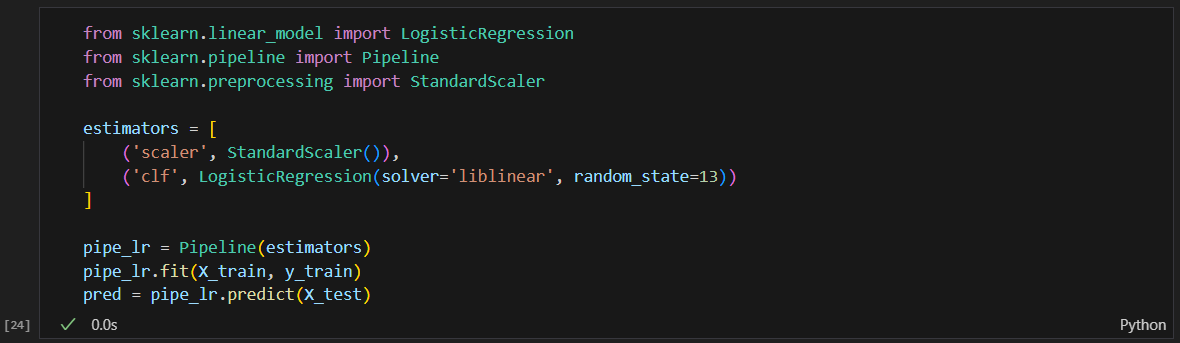
몇몇 수치 확인
상대적 의미를 가질 수 없어서 이 수치 자체를 평가할수는 없다.
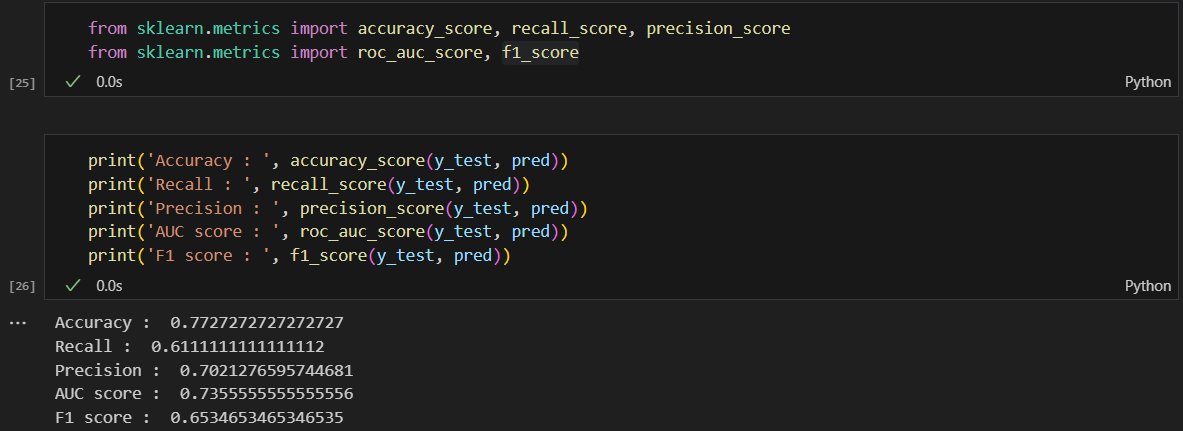
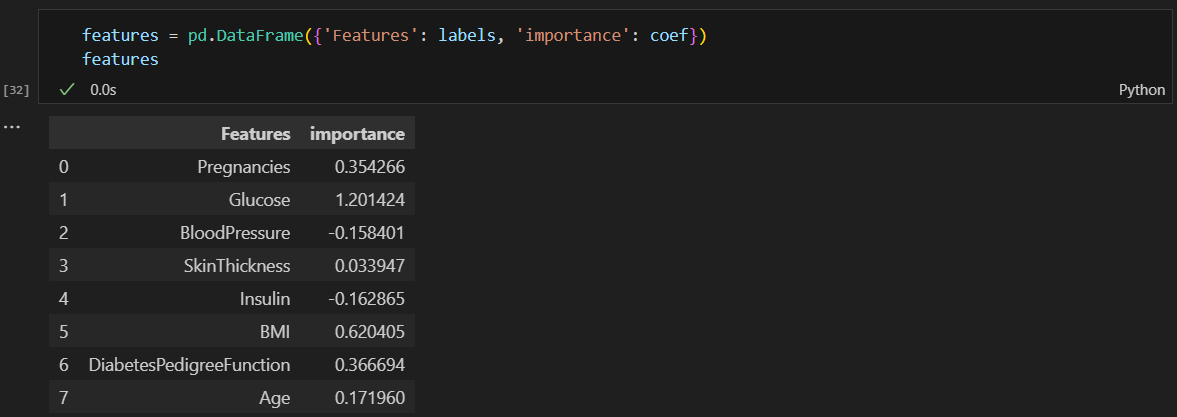
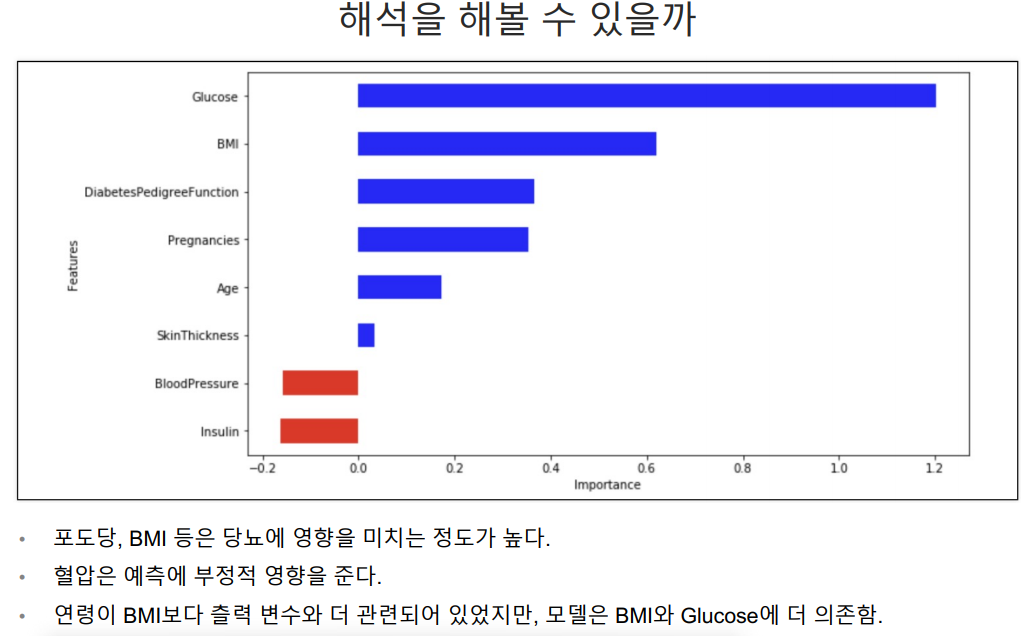
다변수 방적식의 각 계수값 확인
계수값을 보는 이유는 각 요소들이 얼만큼의 영향을 주는지 보기 위해.
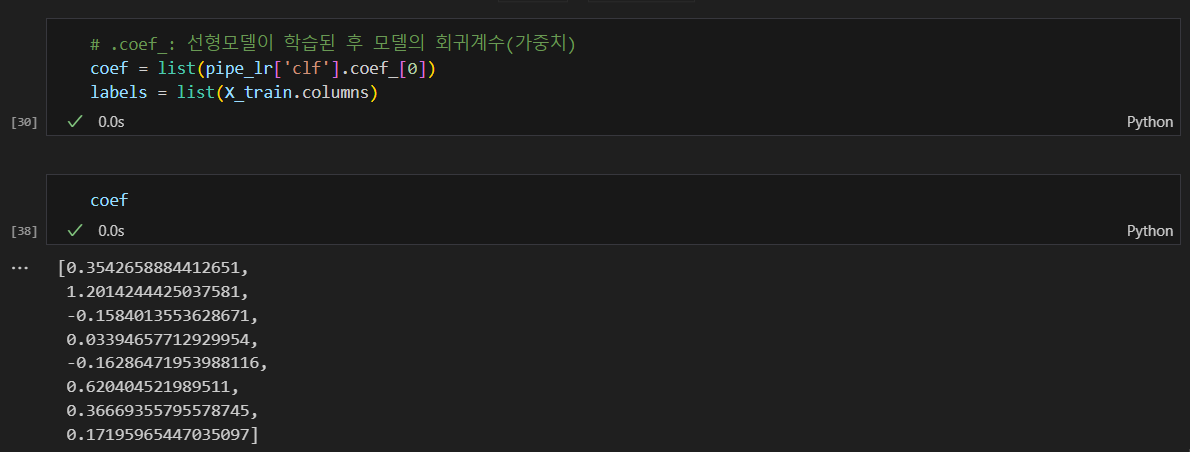
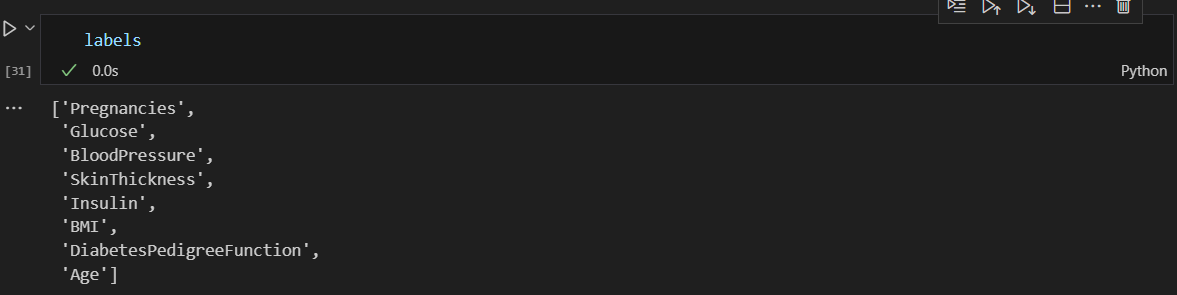
데이터 프레임으로 만들고 정렬
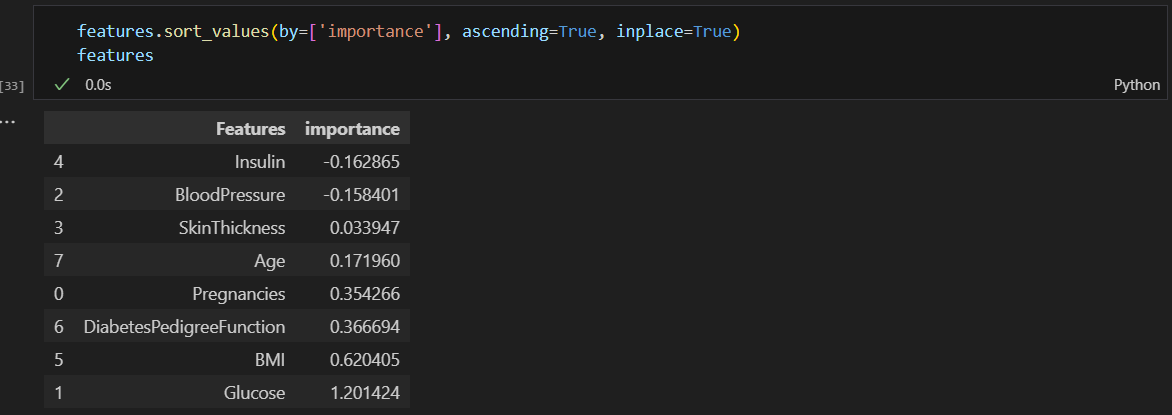
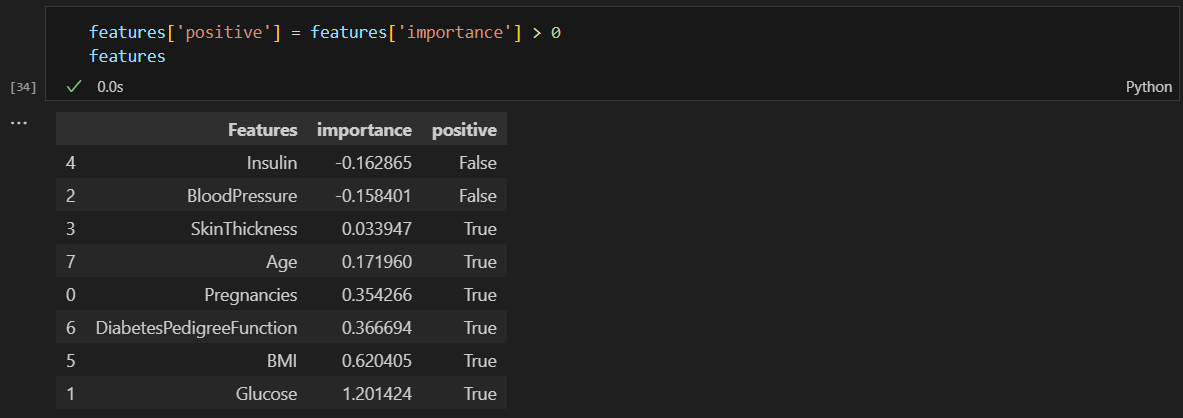
그래프 그릴시 색 구분을 위해 컬럼 추가
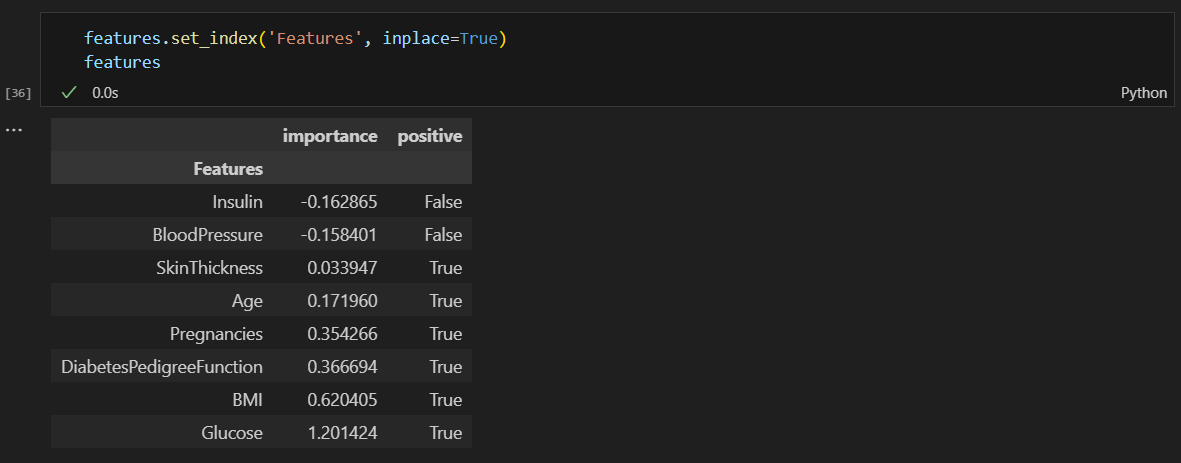
그래프 그리기

임의로 threshold를 수정해서 결과를 바꾸기(좋은 방법은 아니어서 거의 사용하지 않음)
와인데터이 가져오고 데이터 분리
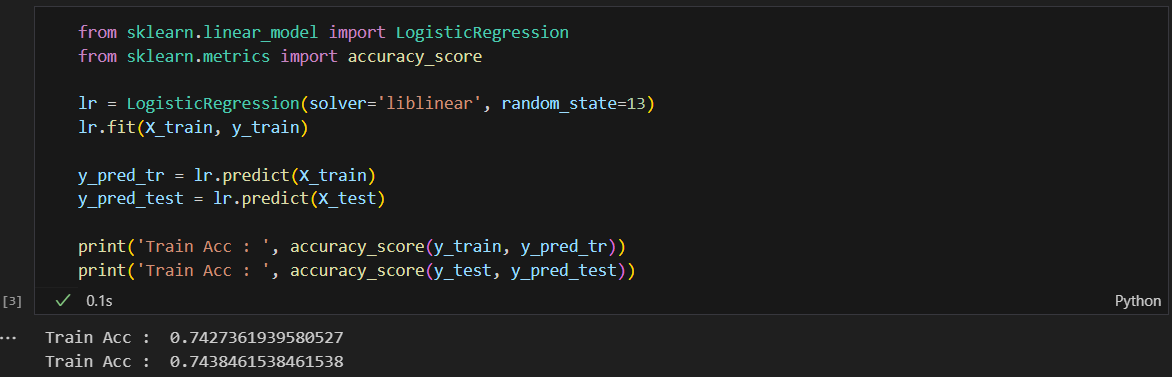
로지스틱 회귀 적용
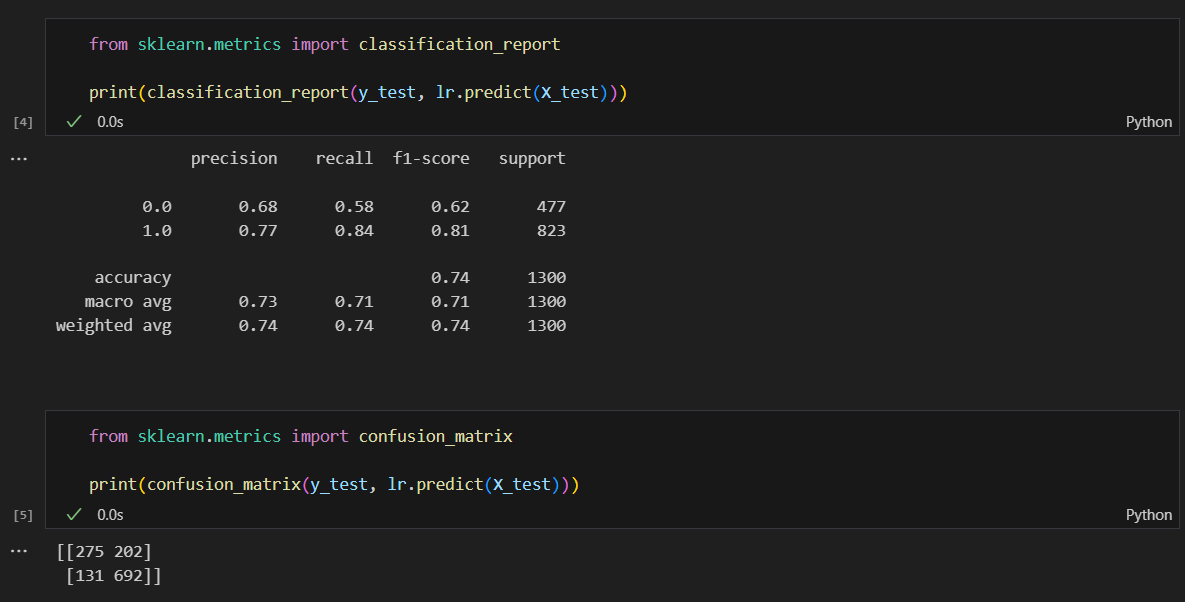
classification_report, confusion_matrix
그래프 그리기
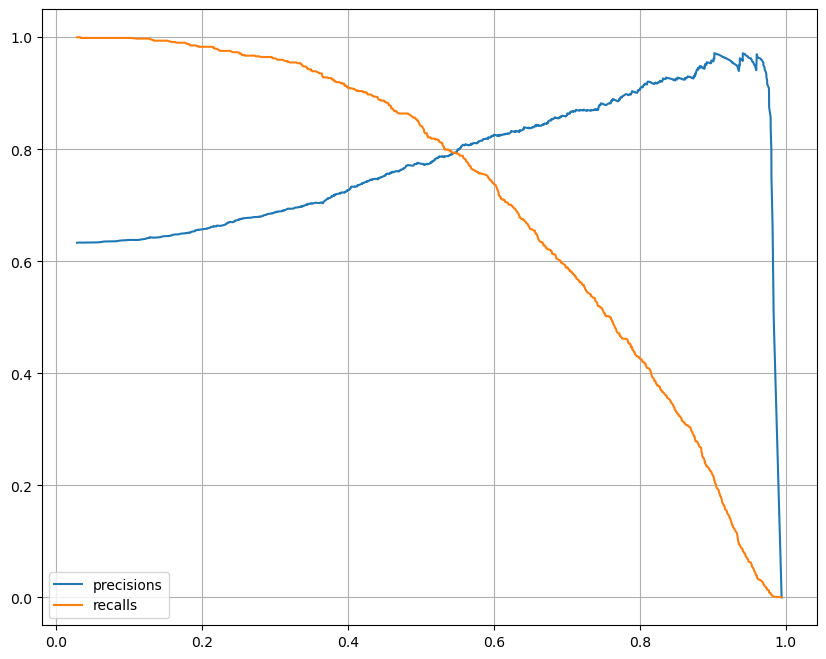
precision_recall_curve
threshold = 0.5일때 예측값은
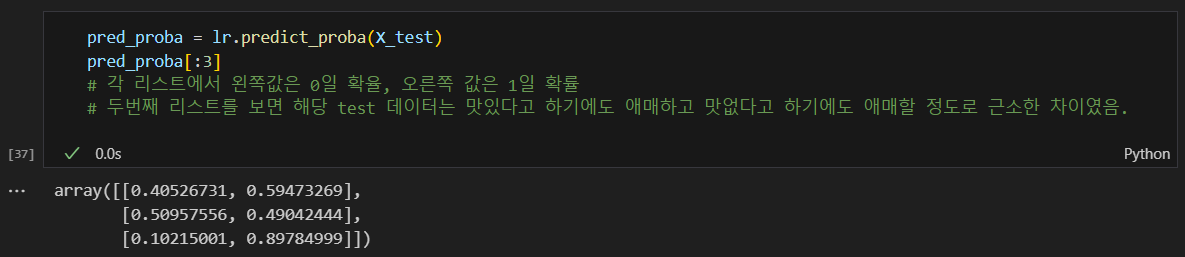
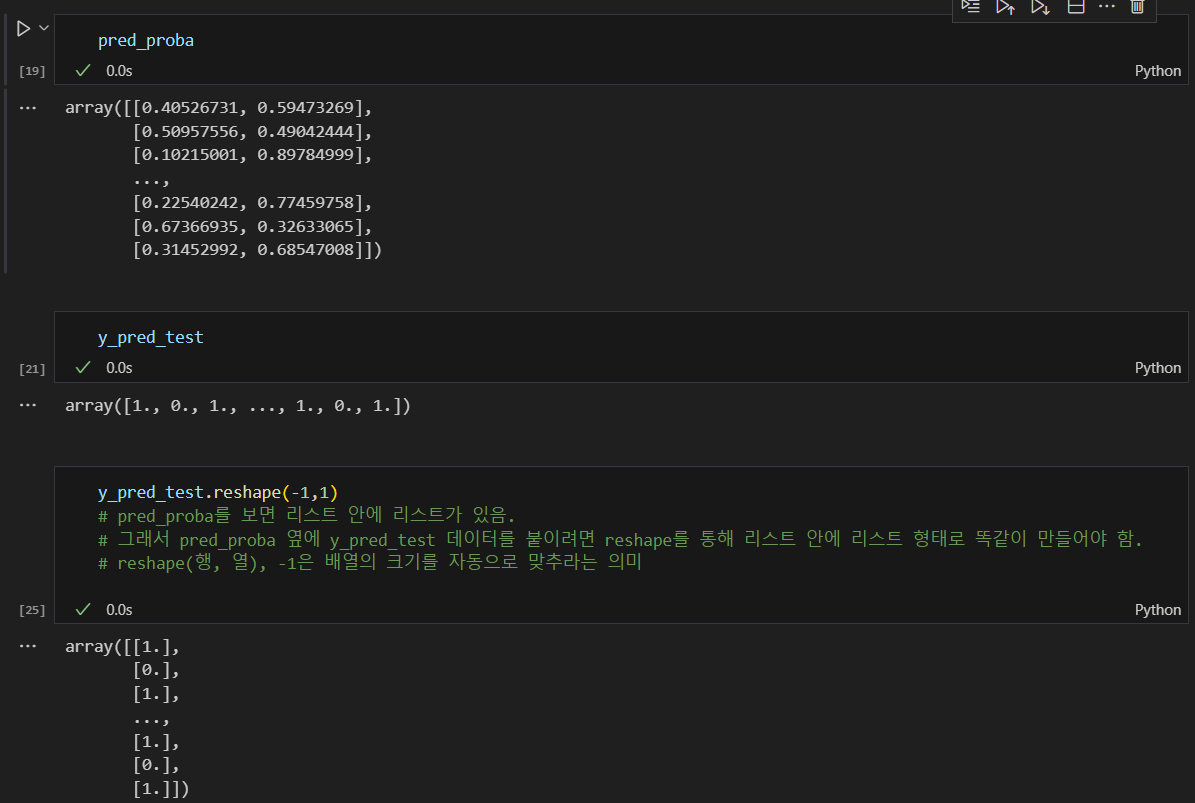
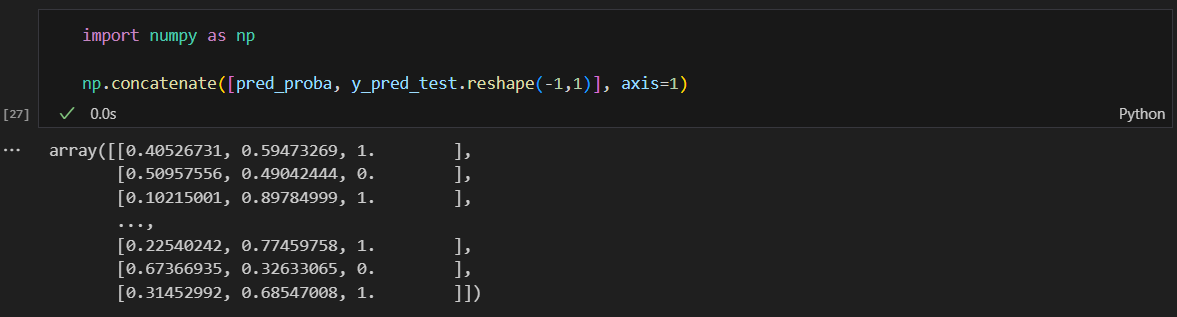
맛없다: 0, 맛있다:1 의 결과값을 각각의 확률 옆에 붙여보기
reshape(행, 열) 사용
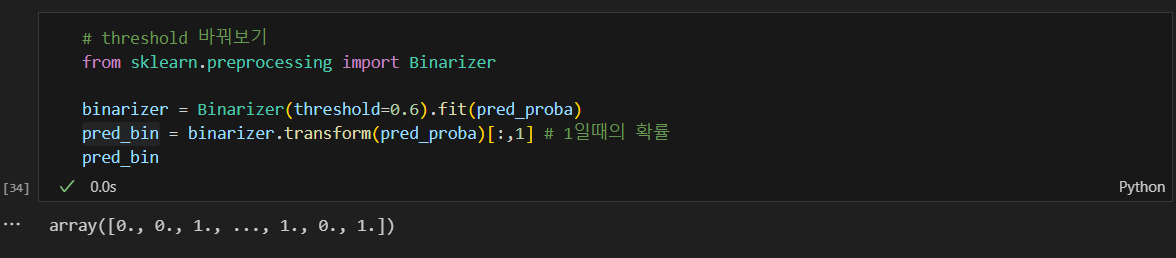
threshold = 0.6으로 바꾼 후 결과값 비교해보기
위에가 threshold=0.5, 아래가 0.6
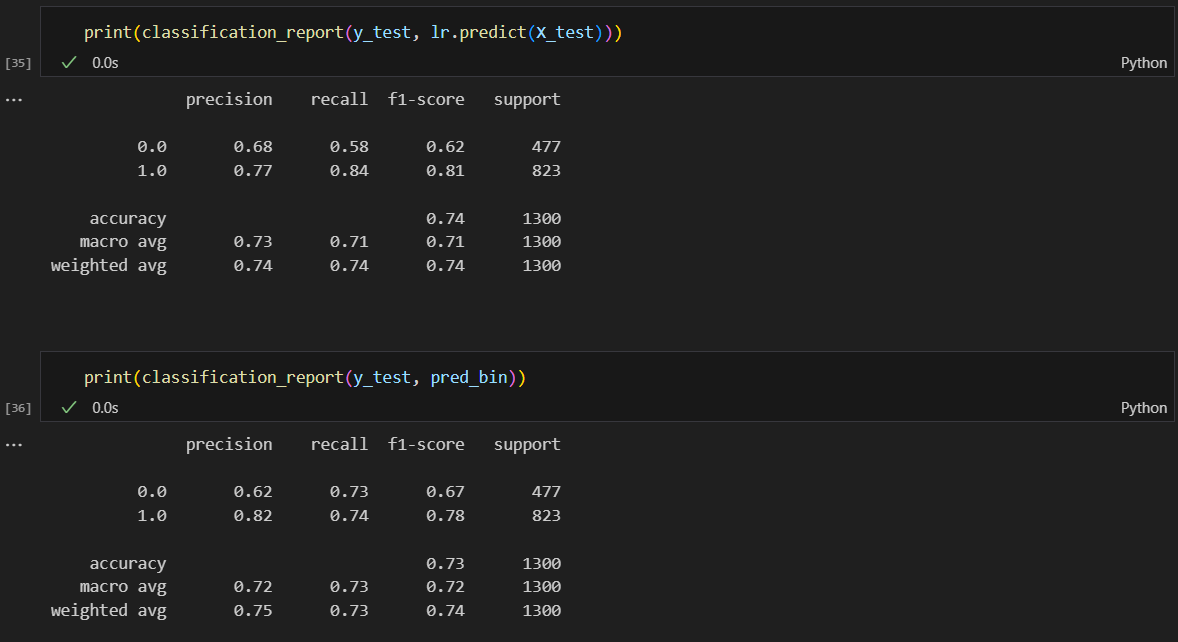
다시 말하지만 이렇게 임의로 threshold를 바꾸는 방법은 좋은 방법은 아님.
