
📖 05장. 머신 러닝의 기본 요소
🗝️ 핵심내용
- 머신 러닝의 근본 문제인 일반화와 최적화 사이의 긴장 관계 이해하기
- 머신 러닝 모델의 평가 방법
- 훈련 성능 향상을 위한 모범 사례
- 일반화 성능 향상을 위한 모범 사례
📑 훈련 성능 향상하기
최적적합 모델을 찾으려면 먼저 과대적합되어야 한다. 경계가 어디인지 미리 알 수 없기 때문에 넘어가 보아야만 알 수 있기 때문이다.
이 단계에선 일반적으로 세가지 문제가 발생한다.
훈련이 되지 않는다.: 시간이 지나도 훈련 손실 감소 X훈련은 잘 시작되었지만 모델이 의미있는 일반화를 달성하지 못한다.: 상식 수준의 기준점 X- 시간에 따라 훈련, 검증 손실이 감소하고 기준점을 넘을 수 있지만 과대적합되지 않는다. (여전히 과소적합)
경사 하강법의 핵심 파라미터 튜닝하기
가끔 훈련이 시작되지 않거나 너무 일찍 중단되는 경우가 발생한다. (손실이 멈춰있다.) 그러나 문제에 아무런 의미가 없더라도 훈련 데이터를 외우는 것만으로도 무언가를 훈련할 수 있기 때문에 이런 문제는 항상 극복할 수 있다.
일반적으로 이런 상황의 경우 경사 하강법 과정에 대한 설정에 문제가 있는데, 이는 옵티마이저 선택, 모델의 가중치 초깃값 분포, 학습률, 배치 크기와 같은 파라미터 설정을 말한다.
이때는 보통 나머지 파라미터는 고정하고 학습률과 배치 크기를 튜닝하는 것으로 충분하다.
학습률을 낮추거나 높인다.: 너무 높은 학습률은 최적적합을 크게 뛰어넘는 업데이트가 일어날 수 있고, 너무 낮은 학습률은 훈련을 너무 느리게 만들 수 있다.배치 크기를 증가시킨다.: 배치 샘플을 더 늘리면 유익하고 잡음이 적은 (분산이 적은) 그레이디언트가 만들어진다.
구조에 대한 더 나은 가정하기
모델은 훈련되지만 모종의 이유에서인지 검증 지표가 전혀 나아지지 않는다. 즉, 모델은 훈련되지만 일반화되지 않는다. 이는 아마도 맞닥뜨릴 수 있는 최악의 상황일 것이다. 이는 접근 방식에 문제가 있다는 것인데 다음과 같은 해결 방법이 있다.
- 단순하게 입력 데이터에 타깃 예측을 위한 정보가 충분하지 않을 수 있다.
- 현재 사용하는 모델의 종류가 문제에 적합하지 않을 수 있다.
모델 용량 늘리기
모델이 훈련되고 검증 지표가 향상되며 최소한 어느 정도 일반화 능력을 달성하였다면, 모델을 과대적합시킬 차례이다.
이는 매우 작은 모델로 훈련시킬 경우, 검증 손실이 정점에 도달하여 역전되지 않고 멈춰 있거나 매우 느리게 좋아진다. 이는 과대적합되지 못하고 있다는 의미인데, 다른 말로 모델의 표현 능력 (representational power)이 부족하다고 할 수 있다.
우리는 항상 과대적합이 가능하다는 것을 기억해야 한다. 이러한 경우 모델의 용량을 늘려, 더 많은 정보를 저장할 수 있는 모델을 만들어 과대적합시킬 수 있다. 모델의 용량을 늘리는 방법은 다음과 같다.
- 층을 추가한다.
- 층 크기를 늘린다.
- 현재 문제에 더 적합한 종류의 층 (구조에 대해 더 나은 가정)을 사용한다.
📑 일반화 성능 향상하기
결론부터 얘기하면 신경망에서 일반화 성능을 향상하고 과대적합을 방지하기 위해 사용되는 방법은 다음과 같다.
- 훈련데이터를 더 모으거나 더 나은 데이터를 모은다.
- 더 나은 특성을 개발한다.
- 네트워크의 용량을 감소시킨다.
- 가중치 규제를 추가한다.
- 드롭아웃을 추가한다.
이제 위 방법을 하나씩 알아보자.
데이터셋 큐레이션
딥러닝은 일종의 곡선을 맞추는 작업이다. 데이터를 사용하여 샘플 사이를 부드럽게 보간할 수 있다면 일반화 성능을 가진 딥러닝 모델을 훈련할 수 있을 것이다.
따라서 적절한 데이터셋으로 작업하고 있는지 확인하는 것이 매우 중요하고, 데이터 수집에 노력과 시간은 투자하는 것이 모델 개발에 동일한 노력과 시간을 투자하는 것보다 항상 더 나은 결과를 가져올 수 있다.
- 데이터가 충분한지 확인한다. 이따금 불가능해 보이는 문제도 대용량의 데이터셋으로 해결되는 경우가 있다.
- 레이블 할당 에러를 최소화하고, 이상치를 확인하고, 레이블을 교정한다.
- 데이터를 정제하고 결측치를 처리한다.
- 많은 특성 중 유용한 특성을 골라내기 위해 특성 선택을 수행한다.
특성 공학
특성 공학(feature engineering)은 모델에 데이터를 주입하기 전 알고리즘이 더 잘 수행되도록 하드코딩된 변환을 적용하는 것이다.
에를 들면, 시계 이미지를 입력으로 받고 그에 따른 시간을 출력하는 모델을 만든다고 가정해보자.
이미지의 원본 픽셀을 입력으로 사용한다.: 이를 해결하기 위해 합성곱 신경망이 필요할 뿐더러 훈련을 위해 많은 컴퓨팅 자원이 필요할 것이다.각 바늘 끝의 좌표를 입력으로 사용한다: 간단한 파이썬 스크립트를 사용하여 바늘 끝의 좌표를 입력하여도 좌표와 적절한 시각의 관계를 학습할 수 있다.좌표를 바꾸어 바늘의 각도를 입력으로 사용한다: 이 단계까지 적용한다면 사실 문제가 너무 쉬어져 머신 러닝이 필요없는 단계에 이른다.
위와 같은 예시는 특성 공학의 핵심을 잘 설명해주고 있다. 따라서 좋은 특성은 같은 문제를 적은 자원을 이용하여 더 쉽게 해결할 수 있게 하고 더 적은 데이터로도 문제를 풀 수 있게 한다.
조기 종료 사용하기
이 전에 우리는 최상의 검증 점수를 내는 에포크 횟수를 찾기 위해 모델을 끝까지 학습 시킨 후 검증 손실이 최소가 되는 지점을 찾아 최적의 에포크 횟수를 찾는 작업을 수행했었다.
그러나 이는 기본이지만 중복 작업이며 비효율적인 많은 비용을 수반하는데, 이 대신 각 에포크가 끝날 때마다 모델을 저장하고 최상의 에포크를 찾을 후 저장된 모델을 재사용할 수 있는 EarlyStopping 콜백(callback)을 사용하여 처리할 수 있다.
모델 규제하기
규제(regularization) 기법은 훈련 데이터에 완벽하게 맞추려는 모델의 능력을 적극적으로 방해하는 일련의 모범 사례이다. 모델이 훈련 세트에 덜 특화되고 모델을 더 간단하고 평범하게, 곡선을 더 부드럽게 만들어준다.
다양한 규제 방법들을 IMDB 영화 분류 모델에 적용하여 성능을 확인해보자.
# 원본 모델
import numpy as np
import keras
from tensorflow.keras.datasets import imdb
from tensorflow.keras import layers
(train_data, train_labels), _ = imdb.load_data(num_words=10000)
def vecterize_sequences(sequences, dimensions=10000):
results = np.zeros((len(sequences), dimensions))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
train_data = vecterize_sequences(train_data)
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history_original = model.fit(train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)1. 네트워크 용량 조절하기
너무 작은 모델은 과대적합되지 않는다는 것은 이미 이전에 배웠다. 이는 모델의 기억 용량이 훈련 데이터를 학습하기에 충분하지 않다는 의미이다. (여기서 기억 용량은 층의 수와 층에 있는 유닛 개수로 결정되는 학습 가능한 파라미터 개수를 의미한다.)
그렇다면 모델의 기억 용량이 매우 크다면 어떻게 될까? 이때는 순식간에 훈련 데이터를 단순히 외워버려 훈련 데이터에만 특화된 모델이 만들어질 것이다.
따라서 우리는 너무 많은 용량과 충분하지 않은 용량 사이에서의 절충점을 찾아야한다. 이는 보통 적은 수의 층과 파라미터로 시작하여, 검증 손실이 감소되기 시작할 때까지 층이나 유닛 개수를 늘려본다.
먼저 원본 모델보다 작은 모델을 학습시키고 두 모델의 검증 손실을 비교해보자.
# 작은 용량의 모델
model = keras.Sequential([
layers.Dense(4, activation='relu'),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history_smaller_model = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)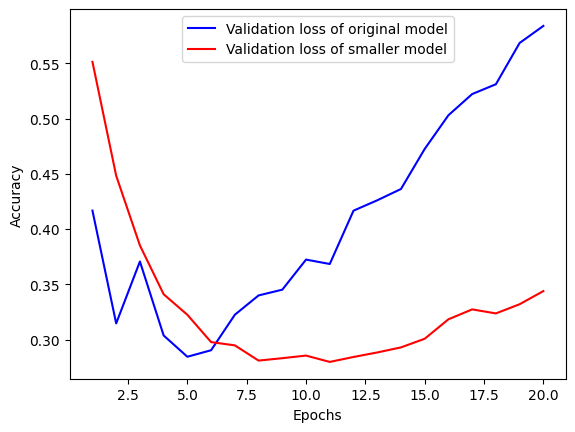
위 그래프에서 볼 수 있듯이, 더 작은 모델이 기존 모델보다 나중에 과대적합되기 시작했으며, 과대적합이 시작되었을 때 더 천천히 성능이 감소하는 것을 볼 수 있다.
이번엔 원본 모델보다 큰 모델을 학습시키도 두 모델의 검증 손실을 비교해보자.
# 큰 용량의 모델
model = keras.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history_larger_model = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)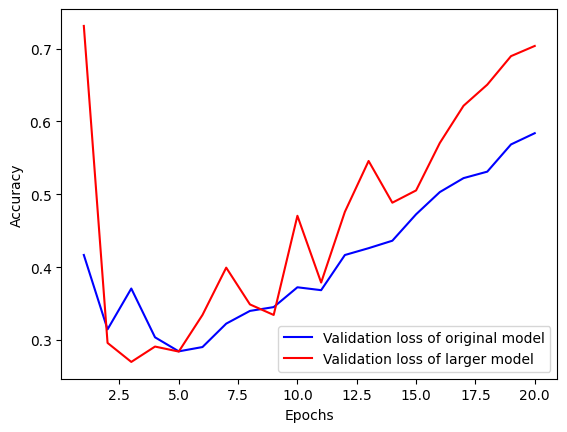
용량이 큰 모델은 거의 첫번째 에포크 이후부터 바로 과대적합이 시작되고, 과대적합이 진행될 수록 손실이 매우 불안정한 모습을 볼 수 있다.
2. 가중치 규제 추가
계속해서 나오는 얘기지만 간단한 모델일수록 복잡한 모델보다 덜 과대적합될 가능성이 높다는 것을 기억하자. 이번에 얘기하는 간단한 모델을 용량이 작은 모델이 아닌 가중치가 작은 모델이다.
모델의 복잡도에 제한을 두어 가중치가 작은 값을 가지도록 강제할 수 있는데, 크게 두가지 방법이 있다.
L1 규제: 가중치의 절댓값에 비례하는 비용이 추가된다.L2 규제: 가중치의 제곱에 비례하는 비용이 추가된다.
이러한 가중치 규제는 일반적으로 작은 딥러닝 모델에서 사용되며, 대규모 딥러닝 모델에는 큰 영향을 미치지 않는다.
L2 규제를 추가하여 원본 모델과 검증 손실을 비교해보자.
# 모델에 L2 가중치 추가하기
from tensorflow.keras import regularizers
model = keras.Sequential([
layers.Dense(16,
kernel_regularizer=regularizers.l2(0.002),
activation='relu'),
layers.Dense(16,
kernel_regularizer=regularizers.l2(0.002),
activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history_l2_reg = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)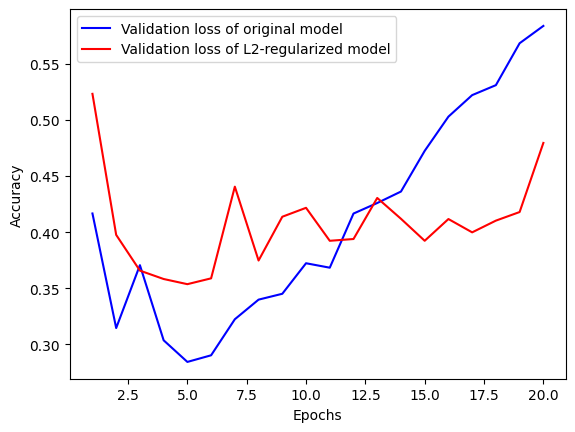
위 코드에서 l2(0.002)는 가중치 행렬의 모든 원소를 제곱하고 0.002를 곱해 모델의 전체 손실에 더해진다는 의미이다. 이 페널티(penalty) 항은 훈련될 때만 추가된다.
이를 미루어보아 그래프를 확인해보면, 손실이 전체적으로 조금 높지만, 훨씬 과대적합에 잘 견디는 모습을 볼 수 있다.
L2 규제 이외에도 다음과 같이 규제를 추가할 수 있다.
# 케라스에서 사용할 수 있는 가중치 규제
from tensorflow.keras import regularizers
regularizers.l1(0.001)
regularizers.l1_l2(l1=0.001, l2=0.001)3. 드롭아웃 추가
드롭아웃(dropout)은 가중치 규제와 달리 대용량 모델에도 많이 사용되며, 가장 효과적이고 널리 사용되는 방법이다.
드롭아웃은 만약 어떤 층이 훈련 과정에서 [0.1, 0.2, 0.3, 0.4, 0.5] 벡터를 출력한다고 했을 때, 드롭아웃을 적용하면 드롭아웃 비율에 따라 벡터의 일부를 0으로 바꾼다. 만약 비율을 0.4로 적용했다면 [0.1, 0, 0, 0.4, 0.5] 와같이 비율에 따라 0으로 바뀌게 된다.
이는 층의 출력값에 노이즈를 추가하여 중요하지 않은 우연한 패턴을 깨뜨리는 것이 핵심이다.
그렇다면 이번엔 드롭아웃 층을 추가하여 원본 모델과 검증 손실을 비교해보자.
# IMDB 모델에 드롭아웃 추가하기
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dropout(0.5),
layers.Dense(16, activation='relu'),
layers.Dropout(0.5),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history_dropout = model.fit(train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)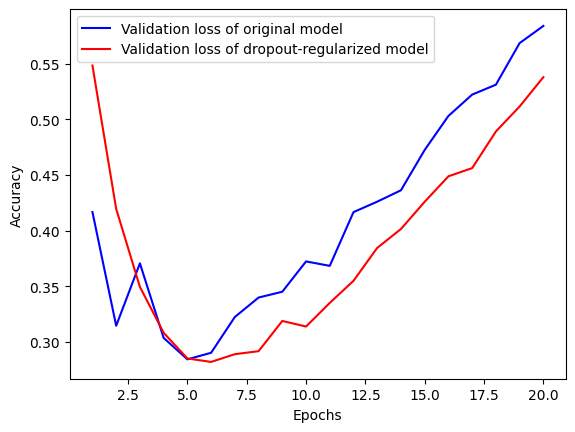
원본 모델보다 훨씬 덜 과대적합되고, L2 규제보다 더 낮은 검증 손실을 달성한 것을 볼 수 있다.
🔗 출처
https://www.gilbut.co.kr/book/view?bookcode=BN003496
