

📚 DataFrame 생성
일반적으로 사용하는 데이터 파일의 형식
1. CSV 파일 (.csv) - Comma Seperated Value
홍길동, 20, 서울, 김길동, 30, 부산, 최길동, 50, 인천
- 장점 : 부가적인 데이터가 적게 들어가고, 상대적으로 사이즈가 큰 데이터를 표현하기에 적합하다.
- 단점 : 데이터를 해석하거나 사용하는데 어려움이 있고, 유지보수가 어렵다.
2. XML 파일 (.xml) - Extended Markup Language
<person> <name>홍길동</name><age>20</age><address>서울</address> </person> <person> <name>김길동</name><age>30</age><address>부산</address> </person>
- 장점 : 사용하기가 아주 쉽고, 데이터 표현을 쉽게 할 수 있다.
- 단점 : 사이즈가 너무 커진다.
3. JSON 파일 (.json) - JavaScript Object Notation
{person : {'name' : '홍길동', 'age' : 20, 'address' : '서울'}}
Dictionary를 이용한 DataFrame 생성
data = {
'name': ['홍길동', '신사임당', '강감찬', '이순신'],
'year': [2020, 2021, 2020, 2023],
'grade': [3.1, 4.0, 1.2, 2.5]
}
# Series를 만들때는 key값이 지정 index로 사용.
# DataFrame을 만들때는 key값이 컬럼명으로 사용.
s = pd.Series(data)
print(s)
# name [홍길동, 신사임당, 강감찬, 이순신]
# year [2020, 2021, 2020, 2023]
# grade [3.1, 4.0, 1.2, 2.5]
# dtype: object
df = pd.DataFrame(data)
print(df)
# name year grade
# 0 홍길동 2020 3.1
# 1 신사임당 2021 4.0
# 2 강감찬 2020 1.2
# 3 이순신 2023 2.5
display(df)
# 기억해야 하는 속성(기본 속성)
print(df.shape) # (4, 3)
print(df.size) # 12
print(df.ndim) # 2
print(df.values)
# [['홍길동' 2020 3.1]
# ['신사임당' 2021 4.0]
# ['강감찬' 2020 1.2]
# ['이순신' 2023 2.5]]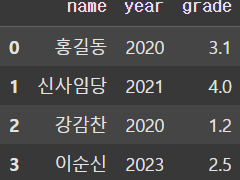
이처럼 Python의 Dictionary를 사용하여 생성할 수 있으며, display() 함수를 이용해 보기 좋게 출력할 수도 있다. 또한 DataFrame도 마찬가지로 여러가지 기본 속성을 가지고 있다.
CSV 파일을 이용한 DataFrame 생성
df = pd.read_csv('/파일경로/movies.csv')
display(df)
Pandas에서 제공하는 read_csv() 함수를 이용하여 간단하게 CSV 파일을 가져올 수도 있다.
Open API를 호출하여 DataFrame 생성
# 영화진흥위원회의 Open API를 사용하였다.
# https://www.kobis.or.kr/kobisopenapi/homepg/apiservice/searchServiceInfo.do
import numpy as np
import pandas as pd
import json
import urllib
key = '부여받은 key 값'
targetDt = '20250101'
movie_url = f'http://kobis.or.kr/kobisopenapi/webservice/rest/boxoffice/searchDailyBoxOfficeList.json?key={key}&targetDt={targetDt}'
# load_page는 respoense 객체
# 이 객체안에 결과데이터와 헤더정보같은 것들이 들어가있다.
load_page = urllib.request.urlopen(movie_url)
# 객체화 시켜서 사용한다.
json_page = json.loads(load_page.read())
print(type(json_page)) # <class 'dict'>
print(json_page) # {'boxOfficeResult': {'boxofficeType': '일별 박스오피스', ...
title = json_page['boxOfficeResult']['dailyBoxOfficeList'][0]['movieNm']
print(title) # 하얼빈
name = []
open_date = []
audience = []
for i in range(10):
name.append(json_page['boxOfficeResult']['dailyBoxOfficeList'][i]["movieNm"])
open_date.append(json_page['boxOfficeResult']['dailyBoxOfficeList'][i]["openDt"])
audience.append(json_page['boxOfficeResult']['dailyBoxOfficeList'][i]["audiAcc"])
data = {
'제목' : name,
'개봉일' : open_date,
'누적 관람객 수' : audience
}
df = pd.DataFrame(data)
display(df)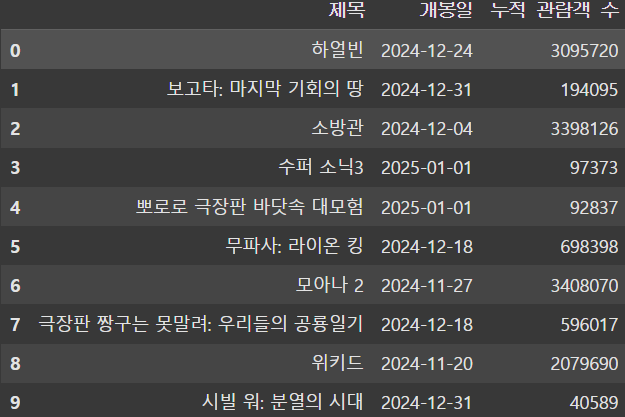
웹에서 Open API를 이용하여 JSON 파일을 읽어 DataFrame을 생성할 수 도 있다. 과정이 조금 복잡할 수 있는데, 이는 제공하는 Open API 마다 사용하는 key 값이 다르기 때문이다.
- 우선 사용할 Open API의 key값을 부여받아야 한다. 이후, 부여받은 key값으로 url을 호출하여 response 객체에 저장한다.
- json.loads() 함수를 이용하여 읽어들인 데이터를 Dictionary 형태로 변환시킨다.
- JSON 파일의 필요한 데이터를 key를 사용하여 key값 따른 value를 list에 저장한다.
- list에 저장한 데이터를 사용하여 새로운 Dictionary를 생성하고 이를 사용하여 DataFrame을 생성한다.
Database를 사용하여 DataFrame 생성
DBMS (DataBase Management System)
데이터를 사용하기 위한 프로그램의 집합
# Database는 MySQL을 사용하였다.
from sqlalchemy import create_engine, text
import numpy as np
import pandas as pd
# sqlalchemy engine을 생성
# 접속할 수 있는 engine을 생성한 후 connect()를 이용해서 Database에 접속한다.
engine = create_engine('mysql+pymysql://root:비밀번호@localhost:3306/library?charset=utf8mb4')
engine.connect()
# 데이터 추출을 위한 SQL
search_keyword = '파이썬' # 책 제목에 대한 키워드 검색
# LIKE 절 뒤에 keyword는 임시로 지정한다.
sql = 'SELECT bisbn, btitle, bauthor, bprice FROM books WHERE btitle LIKE :keyword'
with engine.connect() as connection:
result = connection.execute(text(sql), {'keyword' : f'%{search_keyword}%'})
df = pd.DataFrame(result.fetchall())
display(df)이처럼 sqlalchemy 라이브러리를 사용하여 Database에 접속해 DataFrame을 생성할 수도 있다.
- 우선 sqlalchemy engine을 생성하여 connect() 함수를 통해 Database에 접속한다.
- 내가 얻고자하는 데이터를 위한 SQL 구문을 작성하고 excute() 함수를 통해 데이터를 추출한다.
📚 DataFrame 조작
컬럼 추출하기
data = {
'이름' : ['홍길동', '신사임당', '강감찬', '이순신', '정약용'],
'학과' : ['컴퓨터', '국어국문', '기계', '철학', '물리'],
'학년' : [1, 2, 4, 3, 2],
'학점' : [1.5, 4.3, 2.4, 3.5, 4.4]
}
df = pd.DataFrame(data, columns=['학과', '이름', '학점', '학년', '등급'], index=['one', 'two', 'three', 'four', 'five'])
display(df)
print(df['이름'])
# one 홍길동
# two 신사임당
# three 강감찬
# four 이순신
# five 정약용
# Name: 이름, dtype: object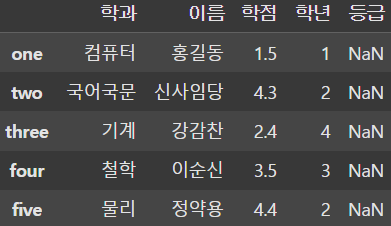
DataFrame은 여러개의 Series가 모여서 생성된 것이다. 각각의 Series는 컬럼으로 표현되며, DataFrame의 컬럼명으로 indexing을 하면 해당 컬럼의 데이터를 Series로 return한다. 이때 컬럼을 DataFrame에서 추출하면 View로 return된다.
display(df[['학과', '이름', '학년']]) # Fancy indexing
# display(df['학과':'학점']) error
이처럼 Fancy indexing을 통해 두개 이상의 컬럼을 추출하는 것도 가능하다. 그러나 slicing을 통한 추출은 불가능하다.
특정 컬럼값 수정하기
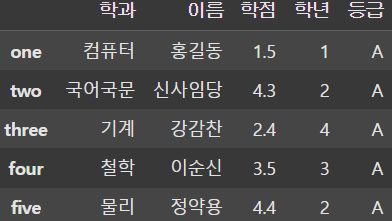
df['등급'] = 'A' # Broadcasting을 이용한 값 수정
display(df)
df['등급'] = ['A', 'B', 'C', 'D', 'A']
df['등급'] = np.array(['A', 'B', 'C', 'D', 'A'])
df['등급'] = pd.Series(['A', 'B', 'C', 'D', 'A'],
index=['one', 'two', 'three', 'four', 'five'])
display(df)
 |  |
|---|
이처럼 Broadcasting, list, ndarray, Series로 다양하게 컬럼의 값을 수정할 수도 있다.
컬럼 추가하기
df['나이'] = [22, 23, 20, 26, 29]
display(df)
df['나이'] = pd.Series([22, 23, 26, 29],
index=['one', 'two', 'four', 'five'])
display(df)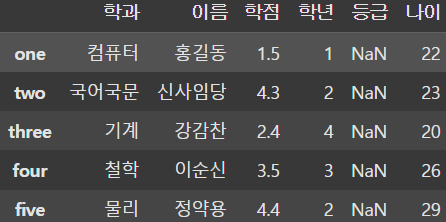 | 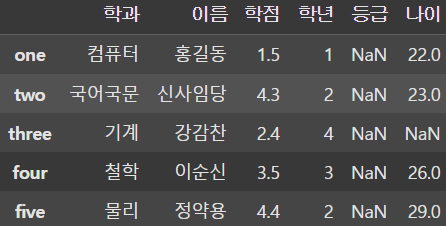 |
|---|
기존의 DataFrame에 없는 컬럼을 추가하려면 새로운 컬럼의 값을 assign하면 된다. 단, 데이터의 개수는 맞춰줘야 하며 모르는 데이터가 있다면 Series를 생성해서 추가해준다.
df['장학여부'] = df['학점'] >= 4.0
display(df)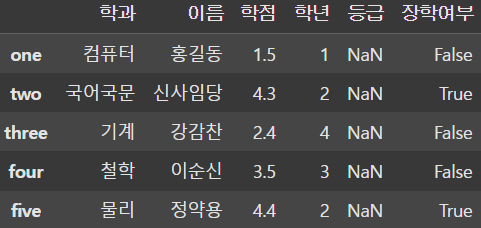
보통 이처럼 연산을 통한 새로운 컬럼을 생성하는 작업을 많이 활용한다.
컬럼 삭제하기
new_df = df.drop('등급', axis=1, inplace=False)
display(new_df)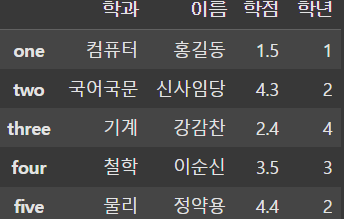
drop() 함수를 사용하여 필요없는 열을 삭제할 수도 있다. 이때 axis는 ndarray와 다르게 1로 지정해야 행 방향으로 삭제할 수 있다.
row indexing
# print(df['one']) error
print(df.loc['one'])
# 학과 컴퓨터
# 이름 홍길동
# 학점 1.5
# 학년 1
# 등급 NaN
# Name: one, dtype: object
# loc를 이용하면 slicing도 가능하다.
display(df.loc['one':'three'])
display(df.loc['three':])
# display(df.loc['three':-1]) error (지정 index와 숫자 index 혼용 불가)
display(df.loc[['one', 'three']]) # Fancy indexing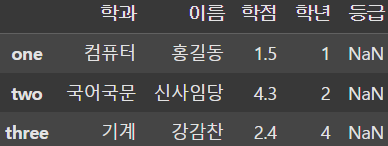 | 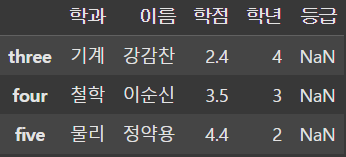 | 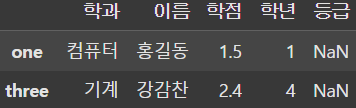 |
|---|
loc를 사용해 행을 추출할 수도 있다. 또한 loc는 컬럼 indexing과는 다르게 slicing을 사용할 수 있으며 Fancy indexing도 사용가능하다.
display(df.iloc[0])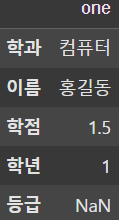
숫자 index를 사용할 경우 iloc를 사용해야한다.
display(df.loc['one':'three', '이름'])
display(df.loc['one':'three', '이름':'학년'])
display(df.loc['one':'three', ['이름', '학년']]) | 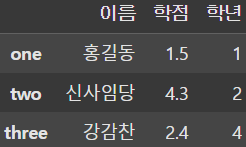 | 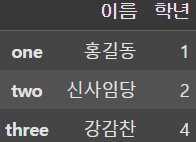 |
|---|
또한 loc는 행뿐만 아니라 열**도 추출할 수 있다.
# 학점이 3.0을 초과하는 학생의 이름과 학과를 DataFrame으로 출력
display(df.loc[df['학점'] > 3.0, ['이름', '학과']])
print()
# 이름이 신사임당인 사람을 찾아서 이름과 학점을 DataFrame으로 출력
display(df.loc[df['이름'] == '신사임당', ['이름', '학점']])
print()
# 학점이 2.0 초과 4.0 미만인 사람을 찾아서 학과와 이름을 DataFrame으로 출력
display(df.loc[(2.0 < df['학점']) & (df['학점'] < 4.0), ['학과', '이름']])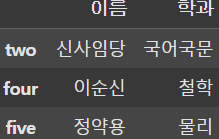 | 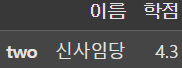 | 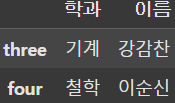 |
|---|
물론 가장 많이 사용하는 기능 중 하나는 Boolean indexing이다.
행 추가, 삭제하기
df.loc['six'] = ['체육', '김연아', 4.5, 3, np.nan]
display(df)
new_df = df.drop('three', axis=0, inplace=False)
display(new_df) |  |
|---|
행을 추가할 때도 loc를 사용하여 새로운 행의 값을 assign해주면 된다. 삭제할 때는 drop() 함수를 이용하는데, 이때 axis의 값은 0으로 지정해주어야 한다.
