

📚 DataFrame의 다양한 함수
df = pd.read_csv('/파일경로/auto-mpg.csv', header=None)
df.columns = ['mpg', 'cylinder', 'displacement', 'horsepower', 'weight',
'acceleration', 'model_year', 'origin', 'name']
display(df)
auto-mpg.csv 파일을 사용하여 다양한 함수를 알아보자.
head()
display(df.head())
DataFrame의 상위 5개의 row를 가져와서 DataFrame으로 생성한다. 이때 인자로 숫자를 사용할 수도 있다.
tail
display(df.tail())
DataFrame의 하위 5개의 row를 가져와서 DataFrame으로 생성한다. 이때 인자로 숫자를 사용할 수도 있다.
shape
print(df.shape) # (398, 9)DataFrame의 shape을 return한다.
info()
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 398 entries, 0 to 397
# Data columns (total 9 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 mpg 398 non-null float64
# 1 cylinder 398 non-null int64
# 2 displacement 398 non-null float64
# 3 horsepower 398 non-null object
# 4 weight 398 non-null float64
# 5 acceleration 398 non-null float64
# 6 model_year 398 non-null int64
# 7 origin 398 non-null int64
# 8 name 398 non-null object
# dtypes: float64(4), int64(3), object(2)
# memory usage: 28.1+ KBDataFrame의 기본정보를 모두 출력해준다.
count()
print(df.count())
# mpg 398
# cylinder 398
# displacement 398
# horsepower 398
# weight 398
# acceleration 398
# model_year 398
# origin 398
# name 398
# dtype: int64DataFrame이 가지고 있는 각 열의 데이터의 개수를 Series로 return한다. 이때 count()는 유효한 값만 counting하며, NaN은 counting하지 않는다.
value_count()
print(df['origin'].value_counts())
# origin
# 1 249
# 3 79
# 2 70
# Name: count, dtype: int64Series가 가지고 있는 함수이다. unique한 value가 몇개 있는지 알려주며, dropna를 인자로 사용해 NaN의 포함 여부를 명시할 수 있다.
unique()
print(df['model_year'].unique())
# [70 71 72 73 74 75 76 77 78 79 80 81 82]Series가 가지고 있는 함수이다. 중복을 제거해준다.
isin()
print(df['origin'].isin([1, 2]))
# 0 True
# 1 True
# 2 True
# 3 True
# 4 True
# ...
# 393 True
# 394 True
# 395 True
# 396 True
# 397 True
# Name: origin, Length: 398, dtype: bool어떤 값이 내가 정한 값들 안에 들어 있으면 True를 return하고 그렇지 않으면 False를 return한다. Boolean indexing에 많이 사용된다.
# 제조국이 미국, EU가 아닌 차량의 mpg와 origin, name을 추출
display(df.loc[~df['origin'].isin([1, 2]), ['mpg', 'origin', 'name']])isin()을 이용한 Boolean indexing 예시.
DataFrame의 기술통계(Descriptive Statistics)를 위한 함수
data = np.array([[2, np.nan], [7, -3], [np.nan, np.nan], [1, -2]])
df = pd.DataFrame(data, columns=['one', 'two'], index=['A', 'B', 'C', 'D'])
display(df)
print(df.sum()) # df.sum(axis=0, skipna=True) -> Series로 리턴
# one 10.0
# two -5.0
# dtype: float64
print(df.sum(skipna=False)) # NaN은 값이 없기 때문에 (값을 알 수 없기 때문에) sum하면 그 값도 알 수 없다.
# one NaN
# two NaN
# dtype: float64
print(df.sum(axis=1))
# A 2.0
# B 4.0
# C 0.0
# D -1.0
# dtype: float64
# 특정 행, 열에 대한 합
print(df['two'].sum()) # 열, -5.0
print(df.loc['B'].sum()) # 행, 4.0
# 평균을 구할 때는 mean(), NaN은 연산에서 아예 포함 X
print(df.mean())
# one 3.333333
# two -2.500000
# dtype: float64
# NaN 결측값 처리('one' 컬럼의 평균을 이용하여)
df['one'] = df['one'].fillna(value=df['one'].mean())
display(df)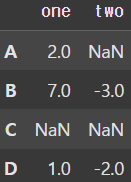 | 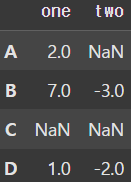 |
|---|
DataFrame에는 다양한 기술통계(Descriptive Statistics)를 위한 함수들이 있다. (sum(), mean(), max(), min(), count(), std(), ...) NumPy는 axis를 사용하지 않으면 전체 ndarray를 대상으로 함수를 적용하는 반면, Pandas는 axis를 사용하지 않으면 기본 axis=0 (row 방향)을 기준으로 한다.
merge()
data1 = {
'학번' : [1, 2, 3, 4],
'이름' : ['홍길동', '신사임당', '강감찬', '이순신'],
'학년' : [1, 3, 2, 4]
}
data2 = {
'학번' : [1, 2, 4, 5],
'학과' : ['철학', '국어국문', '기계', '컴퓨터'],
'학점' : [3.1, 2.5, 1.6, 4.5]
}
result1 = pd.merge(df1, df2, on='학번', how='inner')
result2 = pd.merge(df1, df2, on='학번', how='outer')
result3 = pd.merge(df1, df2, on='학번', how='left')
display(result1, result2, result3)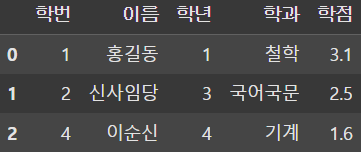 | 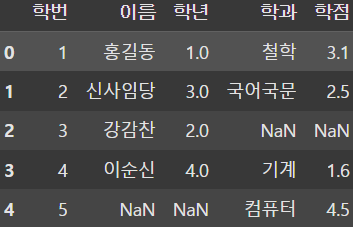 | 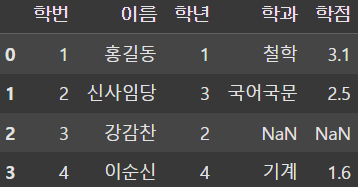 |
|---|
merge() 함수를 이용하여 SQL의 JOIN 절처럼 DataFrame을 결합할 수 있다.
data1 = {
'학번' : [1, 2, 3, 4],
'이름' : ['홍길동', '신사임당', '강감찬', '이순신'],
'학년' : [1, 3, 2, 4]
}
data2 = {
'학생학번' : [1, 2, 4, 5],
'학과' : ['철학', '국어국문', '기계', '컴퓨터'],
'학점' : [3.1, 2.5, 1.6, 4.5]
}
result = pd.merge(df1, df2, left_on='학번', right_on='학생학번')
display(result)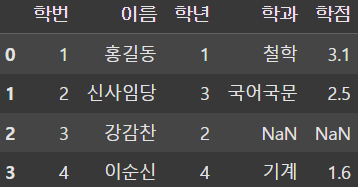
컬럼명이 다른 경우에 left와 right 각각 기준이 되는 key 값을 지정해주면 된다.
data1 = {
'학번' : [1, 2, 3, 4],
'이름' : ['홍길동', '신사임당', '강감찬', '이순신'],
'학년' : [1, 3, 2, 4]
}
data2 = {
'학과' : ['철학', '국어국문', '기계', '컴퓨터'],
'학점' : [3.1, 2.5, 1.6, 4.5]
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2, index=[1, 2, 4, 5])
result = pd.merge(df1, df2, left_on='학번', right_index=True, how='inner')
display(result)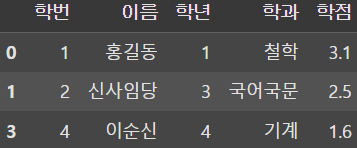
또한 left의 특정 컬럼값과 right의 숫자 index를 기준으로 결합하고 싶다면 right_index 인자를 전달하여 결합할 수 있다.
📚 DataFrame 함수 Mapping
import numpy as np
import pandas as pd
import seaborn as sns
# Raw data Loading
titanic = sns.load_dataset('titanic')
display(titanic.head())
# 모든 행에 대해 age, fare 컬럼만 추출한다.
df = titanic.loc[:, ['age', 'fare']]
display(df.head()) | 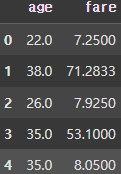 |
|---|
titanic 데이터 셋을 사용해서 DataFrame 함수 Mapping에 대해서 알아보자.
Series 원소에 함수 Mapping
# 사용자 정의 함수를 생성한다.
def add_10(n):
return n + 10
def add_two_obj(a, b):
return a + b
s1 = df['age'].apply(add_10)
display(s1.head())
s2 = df['age'].apply(add_two_obj, b=100)
display(s2.head())
s3 = df['age'].apply(lambda x : x + 30)
display(s3.head()) |  |  |
|---|
이처럼 apply() 함수를 사용하여 Series의 원소에 함수를 Mapping할 수 있다.
- 인자를 하나만 받는 함수 -> apply(func)
- 인자를 여러개 받는 함수 -> apply(func, ...)
- 람다 함수 -> apply(lambda x : x + n)
DataFrame 각 원소에 함수 매핑
# MinMaxScaling
def min_max(s):
return (s - s.min()) / (s.max() - s.min())
result = df.apply(min_max, axis=0)
display(result.head())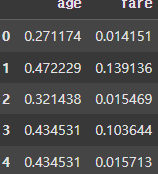
이처럼 DataFrame 각각의 원소에도 함수를 Mapping 할 수 있다.
DataFrame의 열과 행에 함수 Mapping
def min_max(s):
return (s - s.min()) / (s.max() - s.min())
result = df.apply(min_max, axis=0)
display(result.head())
result = df.apply(min_max, axis=1)
display(result.head())
def add_two_obj(a,b):
return a + b
df['add'] = df.apply(lambda x: add_two_obj(x['age'], x['fare']), axis=1)
display(df.head())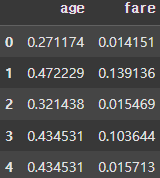 |  | 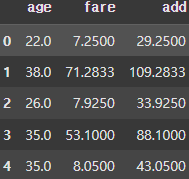 |
|---|
Series에 함수를 Mapping하는 것처럼 apply() 함수를 이용하면서 axis로 기준을 정해 열과 행을 기준으로 함수를 Mapping 할 수도 있다.
📚 DataFrame Grouping
Grouping?
복잡한 데이터를 어떤 기준에 따라 여러그룹으로 나눠 관찰하는 것도 좋은 방법이다. 이처럼 특정 기준을 적용하여 몇 개의 그룹으로 분할하여 처리하는 것을 Grouping이라고 한다.
import numpy as np
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
# 필요한 몇개의 컬럼만 추출하여 사용한다.
df = titanic.loc[:, ['age', 'sex', 'class', 'fare', 'survived']]
display(df.head())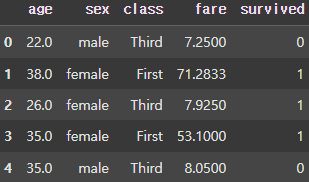
이번에도 titanic 데이터 셋을 사용하여 Grouping에 대해 알아보자.
1개의 열을 기준으로 Grouping
grouped = df.groupby('class')
print(grouped) # 그룹 객체가 생성되요!
print()
for (key, group) in grouped:
display(group)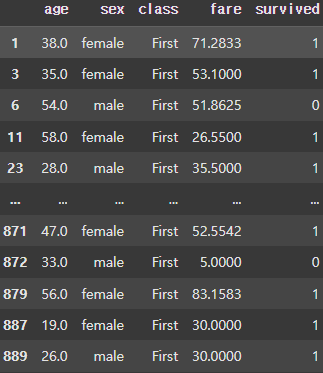 | 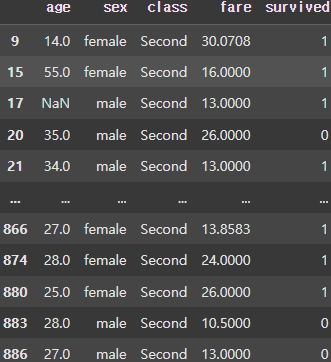 | 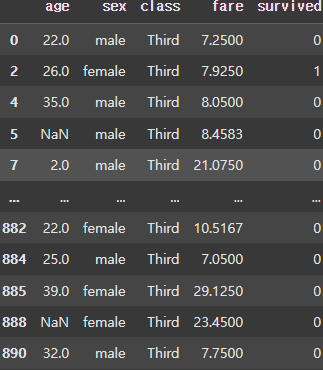 |
|---|
class 컬럼에 대해 Grouping하면 First, Second, Third에따라 Group이 나눠지는 것을 볼 수 있다.
group3 = grouped.get_group('Third')
display(group3.head())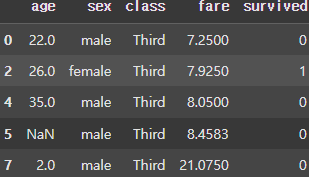
이때 생성된 Group을 get_group() 함수를 사용하여 가져올 수 있다.
여러개의 열을 기준으로 Grouping
grouped = df.groupby(['class', 'sex'])
# class 3개 * sex 2개 = group 6개
for key, group in grouped:
display(group.head())
group3 = grouped.get_group(('Third', 'female'))
display(group3.head())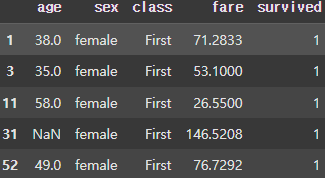 | 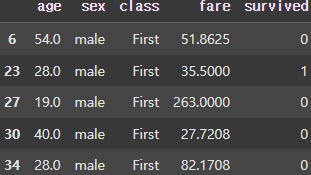 |  |
|---|---|---|
 |  |  |
class(3개), sex(2개)의 컬럼을 기준으로 Grouping을 진행하게 되면 총 6개의 Group이 생성되는 것을 볼 수 있다.
grouped = df.groupby('class')
result = grouped.mean()
display(result)
display(grouped.survived.mean(), grouped.fare.mean())
display(grouped.fare.sum())
print(grouped.fare.sum().max()) # 18177.4125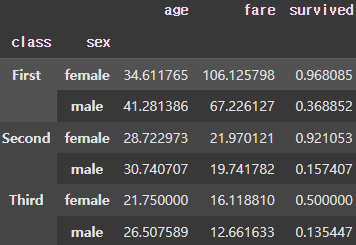 | 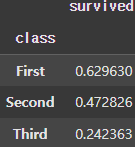 | 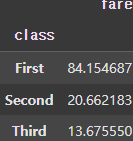 | 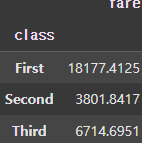 |
|---|
또한, 이처럼 각 Group에 다양한 집계함수를 사용할 수도 있다. 이때 Group의 컬럼을 선택하여 집계함수를 적용할 수도 있다.
Group 객체 Filtering
grouped_filter = grouped.filter(lambda x: len(x) >= 300 )
display(grouped_filter.head())
group_filter = grouped.filter(lambda x : x.age.mean() < 30)
display(group_filter)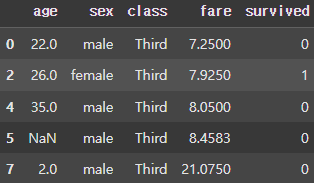 | 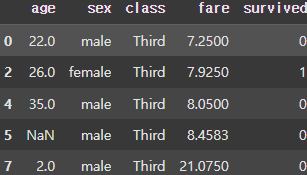 |
|---|
filter() 함수를 사용해 Group을 생성한 후 Group에 대해 조건을 설정해 설정된 조건을 만족하는 Group만 따로 추출할 수도 있다.
