[AI&ML_Eng : 개념 공부.] : 빅데이터(Big Data) – 빅데이터, 정의, 특징, 활용 사례.

▽ [AI&ML_Eng : 개념 공부.] : 빅데이터(Big Data) – 빅데이터, 정의, 특징, 활용 사례.
목 차
0. 데이터가 필요한 이유.
1. 빅데이터란??
2. 빅데이터의 다양한 정의
3. 빅데이터라고 부를 수 있는 크기는?
4. 정형 데이터
5. 비정형 데이터
6. 빅데이터 등장 배경
7. 빅데이터의 양면성
8. 빅데이터의 특징.

0. 📊 데이터가 필요한 이유.
A. 데이터의 본질.
- 데이터(Data)는 단순한 기록이나 숫자가 아니라, "의미 있는 정보를 만들어낼 수 있는 원재료".
- 데이터는 그대로 두면 단순한 사실의 나열일 뿐이지만,
이를 분석 및 해석하면 "새로운 지식, 패턴, 통찰력(insight)"으로 변환. - 이러한 이유로 데이터는 4차 산업혁명 시대를 이끄는 핵심 자원.
🔑 핵심: "데이터 → 정보 → 지식 → 지능"의 전환 과정이 인류 발전의 원동력.
B. 데이터사이언스 & AI 관점에서의 의미.
데이터는 이제 AI 모델의 학습 원재료이자, 비즈니스 인사이트를 발견하는 도구.
-
AI 엔지니어: 머신러닝/딥러닝 모델을 학습시키려면, 대량의 품질 좋은 데이터셋이 필요
-
데이터사이언티스트: 데이터 전처리, 탐색적 데이터 분석(EDA), 모델링, 시각화를 통해 비즈니스 문제 해결에 직접 기여
즉, 데이터는 단순히 저장되는 것이 아니라, 현실 문제를 해결하는 의사결정의 핵심 자원으로 기능.
1. 빅데이터란??
직관적 의미.
-
빅데이터라는 용어는 단순한 "대용량 데이터"를 넘어,
"기존의 데이터 처리 방식으로는 다루기 힘든 복잡한 데이터 집합"을 의미.- 기존의 데이터 처리방법으로는 감당하기 힘들 정도로 방대한 분량의 데이터
- 데이터 하나하나가 모여 의미와 가치가 있는 단위로 묶인 데이터 덩어리
- “빅데이터 프로세싱(Big data processing)”을 포함하여 일컫는 말
- 대용량 데이터가 뭉친 형태를 일컫는 말
2. 빅데이터의 다양한 정의
위키피디아
데이터 베이스 등 기존의 데이터 처리 응용 소프트웨어(data-processing application software)로는 수집 · 저장 · 분석 · 처리하기 어려울 정도로 방대한 양의 데이터를 의미
국가정보화전략위원회
대용량 데이터를 활용, 분석하여 가치있는 정보를 추출하고, 생성된 지식을 바탕으로 능동적으로 대응하거나 변화를 예측하기 위한 정보화 기술
삼성경제연구소
기존의 관리 및 분석 체계로는 감당할 수 없을 정도의 거대한 데이터의 집합
맥킨지(Mckinsey)
기존 시스템의 데이터 수집, 저장, 관리, 분석 역량을 넘어서는 데이터셋(Dataset, 1개 단위로 취급하는 데이터의 집합) 규모로 빅데이터의 분량 기준은 산업 분야에 따라 상대적이며 앞으로도 계속 변화될 것
"기존의 데이터베이스 관리 도구, 관리 시스템의 능력을 넘어 대량의 정형, 비정형 데이터 세트, 이를 포함한 데이터로 부터 분석하여 의미있는 가치를 추출하고 결과를 분석하는 기술".
전통적 데이터 처리와의 차이.
-
전통 방식: RDBMS(관계형 데이터베이스, SQL 기반) → 정형 데이터(표 형태)에 적합
-
빅데이터 시대: 정형 + 비정형 데이터(이미지, 음성, 로그 등)를 동시에 다루어야 함 → 기존 방식만으로는 한계 발생
분산 컴퓨팅(Distibuted Computing) 기반의 새로운 접근 방식이 필요.
AI & 데이터사이언스에서의 빅데이터 의미.
빅데이터는 단순 저장이 아니라, AI 학습과 데이터 분석의 연료 역할을 수행.
-
AI 엔지니어 관점: 머신러닝/딥러닝 모델은 학습을 위해 대량의 데이터가 필요.
→ 빅데이터 없이는 AI 발전이 불가능 -
데이터사이언티스트 관점: 빅데이터에서 패턴을 찾아내고, 의사결정에 필요한 인사이트를 제공.
→ 기업 경쟁력 강화
3. 빅데이터라고 부를 수 있는 크기는?
“얼마부터 빅데이터일까?”
-
많은 사람들이 “도대체 몇 GB부터가 빅데이터인가?”라는 궁금증을 가집니다.
예를 들어, 스마트폰 사진 1장의 용량이 약 3MB라고 하면,-
1,000장의 사진 = 약 3GB
-
영화 한 편(HD 기준) = 약 2GB~4GB
-
-
이 정도라면 여전히 개인 기기에서 관리할 수 있는 수준입니다.
-
즉, 이런 데이터는 “많다”라고는 할 수 있지만, 빅데이터라 부르기는 어렵습니다.
빅데이터의 절대적 기준
일반적으로 학계·업계에서는 수십 테라바이트(TB)에서 페타바이트(PB) 단위 이상을 다루는 경우를 빅데이터라고 부름.
-
1TB (테라바이트) = 1,000GB
-
1PB (페타바이트) = 1,000TB = 100GB 스마트폰 10,000대 분량
-
1EB (엑사바이트) = 1,000PB
-
1ZB (제타바이트) = 1,000EB
👉 1PB 이상부터는 개인이 상상하기 어려운 수준이며, 기업이나 연구기관 단위에서 다루는 데이터 크기
빅데이터 = 크기만의 문제가 아니다.
빅데이터를 크기(Volume)로만 정의하면 오해가 생기게 됨.
왜냐하면 빅데이터의 본질은 “5V 특성”에 있기 때문.
-
Volume (규모): TB~PB~EB 단위의 데이터
-
Velocity (속도): 초당 수십만 건 이상 발생하는 데이터 스트림
-
Variety (다양성): 정형·비정형·반정형 데이터 혼합
-
Veracity (정확성): 불완전한 데이터, 노이즈 문제
-
Value (가치): 데이터 자체보다 이를 통해 얻는 인사이트
👉 따라서 빅데이터는 크기+속도+다양성까지 고려한 개념이라고 이해해야 함.
4. 정형 데이터 (Structured Data)
정형 데이터는 일정한 규칙과 구조(스키마) 를 가진 데이터로, 행(row)과 열(column) 형태로 정리된 것이 특징.
- 일반적으로 수치 만으로 파악이 쉬운 데이터들.
- 즉 데이터베이스나 엑셀과 같은 '표 형태'에 잘 들어맞습니다.
정형 데이터의 특징.
-
고정된 스키마
: 데이터의 형식과 구조가 미리 정의되어 있어 예측 가능하고 일관성이 있음. -
행과 열 구조
: 스프레드시트나 데이터베이스 테이블처럼 행과 열로 구성되며,
각 열은 특정 속성(ex: 이름,나이,가격)을 나타냄. -
데이터의 유형.
: 각 열은 날짜, 텍스트, 숫자 등 특정 데이터 유형을 가져야 하며,
다른 유형의 데이터가 입력되면 오류로 간주됨. -
쉬운 접근 및 분석.
: SQL과 같은 언어를 통해 데이터를 쉽게 검색하고 조작할 수 있으며,
머신러닝 알고리즘으로 이해하고 분석하기 편함.
정형 데이터의 예시.
-
관계형 데이터베이스(RDB)
: 고객 정보, 재고 관리, 판매 거래 기록 등 고정된 테이블 구조로 저장되는 데이터. -
스프레드시트 데이터
: 마이크로소프트 엑셀이나 구글 시트 등에서 볼 수 있는 행과 열로 이루어진 데이터. -
CSV (Comma-Separated Values) 데이터
: 쉼표로 데이터가 구조화된 파일
📌 정형 데이터는 “정답이 딱 떨어지는 질문”에 강합니다.
예: “20대 고객은 몇 명인가?” “지난 달 매출은 얼마인가?”
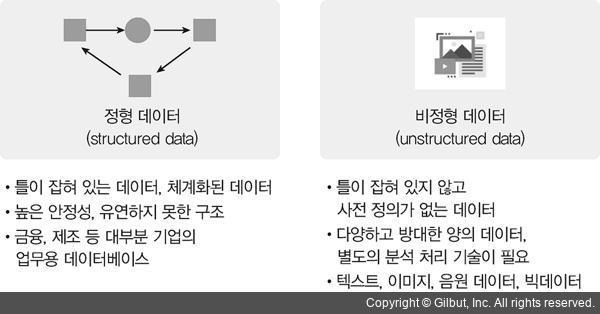
5. 비정형 데이터 (Unstructured Data)
비정형 데이터는 "정해진 규칙(스키마)이 없기 때문에" 표 형태로 정리하기 어려운 데이터.
- 정해진 규칙이 없어서 값의 의미를 쉽게 파악하기 힘든 데이터들.
- 그 안에 담긴 의미를 파악하려면 추가적인 {분석, 전처리, 모델링}이 필요.
비정형 데이터의 특징.
-
정의된 구조 없음.
: 특정 모델이나 스키마에 맞지 않고, 일관된 형식이나 규칙을 따르지 않음. -
다양한 형태.
: 텍스트, 이미지, 오디오, 비디오 등 인간이 생성하는 형태의 데이터를 주로 포함. -
방대한 양.
: 기업에서 생성되는 데이터의 대부분을 차지하며, 분석을 통해 가치 있는 정보를 발견 가능. -
분석의 어려움.
: 고정된 구조가 없으므로, 내용을 분석하기 위해 별도의 텍스트 마이닝이나 데이터 전처리 과정을 거쳐야 함.
-
저장은 쉽지만(파일 형태), 분석은 복잡.
-
자연어 처리(NLP), 컴퓨터 비전(CV), 음성인식 등 AI 기술이 필요.
비정형 데이터의 예시.
-
텍스트 데이터.
: 이메일, 소셜 미디어 대화, 보고서, 문서 등등. -
멀티미디어 데이터
: 디지털 사진, 동영상, 오디오 파일 등
-
로그 및 센서 데이터
: 서버 로그, IOT 장비의 센서 데이터 등
-
웹 트래픽 데이터
: 웹사이트 방문자의 행동 패턴 분석 데이터 등.
📌 비정형 데이터는 “정답이 딱 정해져 있지 않은 문제”에 강합니다.
예: “리뷰에서 고객 감정은 긍정일까 부정일까?” “X-ray 이미지를 보고 질환이 있는가?”
++. 반정형 데이터 (Semi-structured Data)
정형과 비정형의 중간 형태로, 완전한 스키마는 없지만 '일정한 구조나 태그'를 가지고 있음.
반정형 데이터의 특징.
-
일정한 구조적 요소 포함.
: 데이터 안에 태그나 메타데이터와 같은 구조적 요소가 있어서
데이터의 의미를 파악하고 분석하는데 도움을 준다.
-
유연한 구조
: 정형 데이터처럼 고정된 테이블 형식을 따르지 않으며,
스미카가 변경될 수 있어서 확장성이 유연.
-
데이터와 구조 정보 동반.
: 데이터의 구조 정보를 데이터와 함께 젲공하는 파일 형식으로,
이 구조 정보를 통해 정형 데이터로 변환하기도 한다. -
정형처럼 일부 필드를 쉽게 추출 가능
-
동시에 비정형처럼 유연한 데이터 표현 가능
-
NoSQL(MongoDB, Elasticsearch 등)에 적합.
반정형 데이터의 예시.
-
XML (Extensible Markup Language)
: 데이터의 구조를 태그로 명시하는 마크업 언어로, 데이터의 계층적 구조를 잘 표현 -
JSON (JavaScript Object Notation)
:경량의 데이터 교환 형식으로, 주로 웹 애플리케이션에서 사용되며 가독성이 높음. -
HTML (Hypertext Markup Language)
:웹 페이지의 구조를 정의하는 마크업 언어로, 태그를 통해 텍스트, 이미지 등의 콘텐츠를 구조화. -
이메일
: 발신자, 수신자, 제목 등 일정한 구조를 가지지만, 본문의 내용은 비정형적인 텍스트로 구성 가능.
★ 데이터 사이언스 & AI 관점에서의 의미.
-
정형 데이터 : 통계 분석, 시각화, 머신러닝 회귀 & 분류 모델 등에 적합.
- SQL & 통계적 분석이 강점.
-
비정형 데이터 : 딥러닝 기반 AI 모델(NLP,CV,ASR 등)의 핵심 데이터.
- Ai * 딥러닝 모델링이 필수.
-
반정형 데이터 : 실시간 로그 분석, 검색 엔진, 추천 시스템에서 자주 활용.
- 정형 + 비정형의 다리 역할.
👉 실제 AI 프로젝트에서는 세 가지 데이터가 혼합되는 경우가 많음.
6. 빅데이터 등장 배경
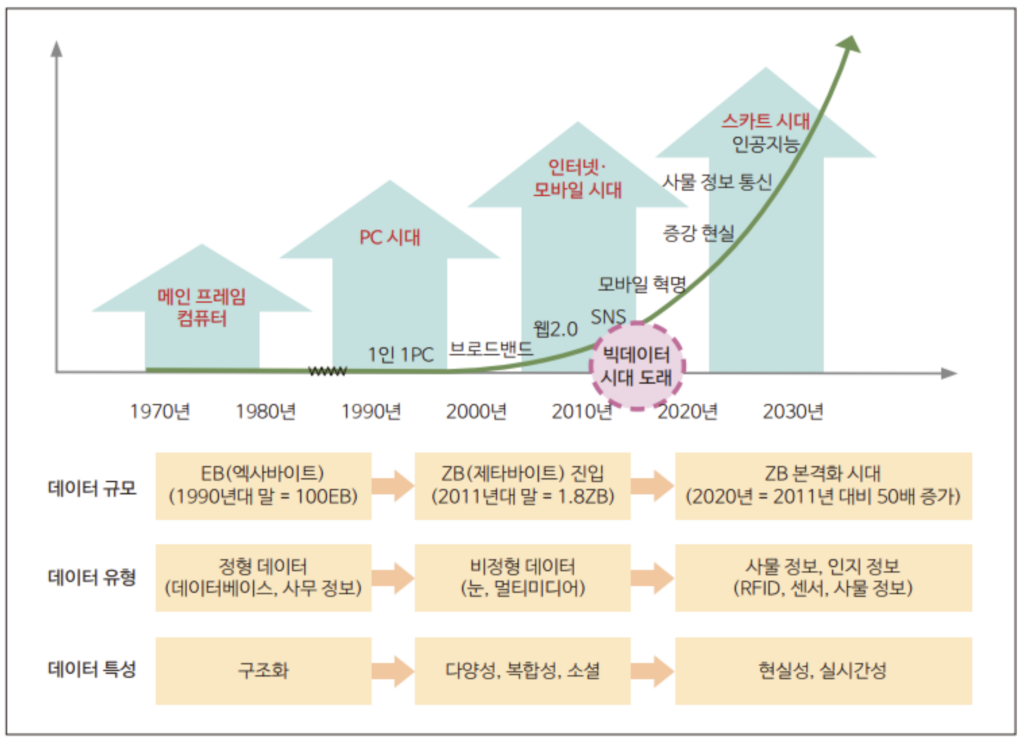
인터넷의 확장과 정보 홍수.
- 1990년대 이후 인터넷이 전 세계로 확산되면서 우리는 “정보화 시대(Information Age)”에 진입.
- 웹사이트, 이메일, 온라인 쇼핑몰에서 발생하는 데이터가 폭발적으로 늘어나면서,
사회적으로는 “정보 홍수(Information Flood)”라는 표현이 등장.
👉 이 시기 데이터는 주로 정형 데이터(거래 기록, 사용자 등록 정보 등)에 가까웠지만,
동시에 이미지, 문서, 로그와 같은 비정형 데이터도 서서히 늘어나기 시작
스마트폰의 등장과 모바일 혁명.
-
2007년 아이폰을 시작으로 스마트폰이 보급되면서 데이터의 양과 종류는 기하급수적으로 증가.
-
언제 어디서나 인터넷 접속 가능
-
사진·동영상·위치 정보(GPS) 등 새로운 데이터 생성
-
앱(App)과 SNS의 폭발적 성장 → 사용자 행동 로그, 메시지, 멀티미디어 데이터 생산
-
👉 모바일의 확산은 빅데이터 시대를 앞당긴 촉매제 역할을 수행.
기술적 요인 : 저장과 처리 비용의 감소.
빅데이터 발전의 또 다른 큰 요인은 하드웨어와 소프트웨어 기술의 발전.
-
저장 비용의 급격한 하락.
-
HDD/SSD 가격 인하
-
메모리(RAM) 성능 향상
-
-
클라우드 컴퓨팅의 확산
- AWS, Google Cloud, Azure → 데이터 저장/처리 서비스 대중화
-
분산 파일 시스템 개발
-
Google File System(GFS)
-
Hadoop Distributed File System(HDFS)
-
-
병렬/분산 처리 기술 발전.
- MapReduce, Spark 같은 빅데이터 프레임워크
👉 이제 데이터는 쉽고 저렴하게 저장·처리·분석 가능.
사회적 요인 : 디지털 서비스의 확산.
-
SNS: 트위터, 페이스북, 인스타그램 → 방대한 텍스트·이미지·동영상
-
실시간 서비스: 검색엔진, 온라인 게임, 금융 거래 → 초당 수십만 건의 데이터 발생
-
IoT 기기 확산: 센서, 웨어러블, 스마트홈 → 실시간 스트리밍 데이터
👉 결과적으로 디지털 정보량은 매년 기하급수적(Exponential) 으로 증가.
기존 데이터 처리 방식의 한계.
전통적인 RDBMS(Relational Database)는 테라(TB) 단위 이상의 데이터 세트를 다루는 데 한계가 존재.
- 문제점.
- 수직적 확장(Scale-up)한계 -> 서버 성능 무한 증설 불가.
- 비정형 데이터 처리 어려움(SQL 기반 구조화 데이터에 최적화)
- 실시간 데이터 처리 지원 부족.
👉 이로 인해 “기존의 데이터 저장·관리·분석 방식은 한계에 도달했다”는 인식이 확산되었고, 새로운 패러다임(빅데이터)이 필요해짐.
7. 빅데이터의 양면성
긍정적 측면: 빅데이터가 제공하는 가치.
빅데이터는 정치·사회·경제·과학기술 등 다양한 분야에서 새로운 기회와 가능성을 제공
-
정치/사회: 선거 예측, 여론 분석, 범죄 예방(예측 치안 시스템)
-
경제/비즈니스: 고객 행동 분석, 맞춤형 마케팅, 공급망 최적화
-
과학/기술: 유전체 분석, 신약 개발, 기후 변화 예측, 스마트시티 구축
-
일상 생활: 개인화 추천(넷플릭스, 유튜브), 실시간 교통 안내, 헬스케어 모니터링
👉 빅데이터는 사회와 인류 발전을 가속화하는 핵심 자원
부정적 측면: 프라이버시와 보안 문제.
그러나 빅데이터는 수많은 개인 정보의 집합이기도 함.
-
사생활 침해
-
위치 데이터, SNS 활동, 검색 기록이 개인의 행동 패턴을 드러냄
-
동의 없이 수집/활용될 경우 “감시 사회”로 이어질 위험
-
-
보안 취약성
-
데이터 유출 → 대규모 개인정보 노출 사고 발생 가능
-
한 번 유출되면 사실상 회수 불가
-
-
데이터 윤리 문제
- 데이터 편향(Bias)이 차별을 강화할 수 있음 (예: AI 채용 시스템에서 특정 집단 차별)
👉 빅데이터 = 현명한 도구(빅데이터) vs 감시 도구(빅브라더) 라는 이중성
AI 엔지니어 & 데이터사이언스 관점에서의 책임.
-
데이터 수집 단계 → 개인 동의(Consent)와 데이터 최소화 원칙 준수
-
데이터 저장 단계 → 암호화, 접근 권한 관리, 익명화 처리 적용
-
데이터 분석 단계 → 편향(Bias) 탐지와 제거 노력
-
데이터 활용 단계 → 투명한 알고리즘 설명 가능성(Explainability) 확보
👉 기술 역량과 더불어 윤리적 판단 능력이 필수 역량
8. 빅데이터의 특징.
3V: 빅데이터의 기본 특징.
① 규모 (Volume)
- 기술과 ICT 발전으로 디지털 정보량이 기하급수적으로 증가.
- 2020년 기준, 전 세계 데이터 총량은 제타바이트(ZB) 규모에 진입.
- ex) 유툽에 매분 업로드되는 동영상은 500시간 이상.
👉 핵심: 빅데이터는 TB, PB, EB 단위의 방대한 규모를 다룸
② 다양성 (Variety)
-
과거: 주로 정형 데이터(숫자, 표) 위주
-
현재: 텍스트, 이미지, 음성, 동영상, 센서 로그 등 비정형 데이터가 압도적
-
예: 의료 영상(X-ray, MRI), SNS 댓글, IoT 센서 데이터
👉 핵심: 데이터 유형이 다양할수록 분석 기법도 달라져야 함 (SQL → NLP, CV, IoT 분석 등)
③ 속도 (Velocity)
-
IoT, 모바일, SNS 확산으로 실시간 데이터 생성·이동 증가
-
초당 수백만 건의 이벤트가 발생하는 경우 흔함
-
예: 금융 거래(실시간 사기 탐지), 자율주행 차량 센서 데이터(실시간 반응 필요)
👉 핵심: 데이터는 단순히 크기만 중요한 게 아니라, 얼마나 빠르게 생성·처리할 수 있는가가 관건
5V: 확장된 빅데이터 특징.
3V에서 발전해, 정확성(Veracity)과 가치(Value)가 추가된 5V 모델.
④ 정확성 (Veracity).
-
방대한 데이터가 늘어날수록 노이즈, 오류, 불완전성 문제 발생
-
“쓰레기 데이터(Garbage In) → 쓰레기 아웃(Garbage Out)” 위험
-
예: 잘못된 센서 값, 편향된 데이터 → AI 모델 성능 저하
👉 핵심: 데이터 품질 관리가 분석 정확도를 결정.
⑤ 가치 (Value).
-
빅데이터의 최종 목적은 단순한 저장이 아니라 가치 창출
-
분석을 통해 새로운 인사이트를 제공하고, 현실 문제 해결에 기여해야 함
-
예:
-
기업 → 고객 맞춤형 마케팅, 공급망 최적화
-
의료 → 질병 조기 진단, 신약 개발
-
정부 → 도시 교통 최적화, 범죄 예방
-
👉 핵심: 데이터는 활용해서 가치로 전환될 때 비로소 의미가 있음
