조사 배경
- 고기능 챗봇 서비스에 대한 관심
- 덕분에 맨날 서버 터져서 나만의 작은 소중한 챗지피티가 갖고 싶었음
- 기업들의 자체 고기능 챗봇 서비스 보유의 움직임
Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs
LLAMA와 ALPACA
what is LLaMA?
- 기존의 대규모 언어모델(LLM)의 문제를 해결하기 위해서 만든 공공 데이터로만 만든 7B~65B 사이즈의 기초 언어 모델입니다.
만들어진 배경
- LLM들 대부분이 접근 불가능하고 독점적인 데이터로 학습되어 편향과 독성(toxicity)를 가질 수 있음(open-source화의 목적도 존재하는 것 같음)

- LLM은 적은 자원을 가진 머신이나 적은 자원을 쓰도록 세팅 된 환경에서는 배포 불가
- LLM은 모델 자체의 복잡성과 크기로 인해 특정 다운스트림 태스크에 대해 파인튜닝하기 까다로웠음
사용 데이터
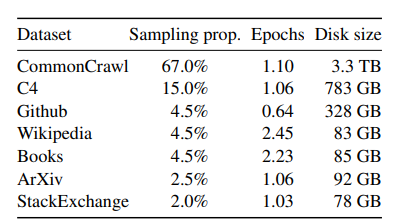
- CommanCrawl
- 연구 목적으로 크롤링이 허용된 웹 페이지의 코퍼스(2017 - 2020). 데이터 수집 파이프라인으로 CCNet-pipeline 사용
- C4
- CommanCrawl 데이터셋에서 전처리된 데이터셋(CCNet-pipeline과의 차별점은 퀄리티 필터링)
아키텍쳐
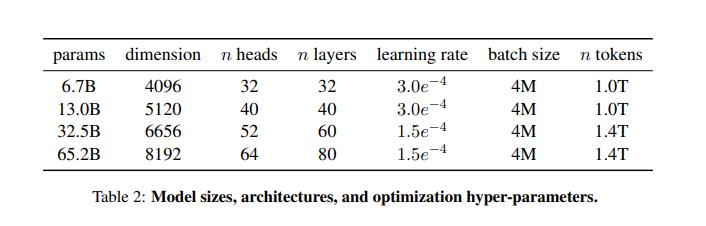
- tokeninzer - BPE tokenizer 사용
- 모델 - Transformer 아키텍쳐를 베이스로 하여 만들었고, 후에 제안 된 더 나은 모델들을 참고하여 만들어졌다. 모델에서 주요하게 다른 특이점은 다음과 같다
- pre-normalization [GPT3]
학습의 안정성을 위해 트랜스포머의 하위 레이어의 인풋마다 노말라이제이션을 걸어주었다. - SwiGLU activation function [PaLM]
ReLU 함수를 SwiGLU함수로 바꾸어주었다. - Rotary Embeddings [GPTNeo]
Absolute Positional Embedding을 Rotary Positional Embedding으로 바꾸어주었다.
- pre-normalization [GPT3]
Instruction Finetuning
- https://arxiv.org/abs/2210.11416 에서 제안된 기법
- 다운스트림 태스크에 맞추어 파인튜닝 하는 것은 무조건 적으로 성능을 보장하지 않는다. 그리고 비용도 많이 깨진다.
- 하지만, 인스트럭션을 넣어주게 되면 실제 다운스트림 태스크에서도 우수한 성능을 보이는 것을 알 수 있었다.
- 인스트럭션이란?
- , “The movie review ‘best RomCom since Pretty Woman’ is _” 처럼 문장을 주고 빈 칸을 “positive” 혹은 “negative” 로 채워라.
- 너무 비슷한 데이터셋을 사용하게 되면 퍼포먼스에 영향을 끼치기 때문에 태스크 별로 클러스트를 만들어 데이터셋을 분류하였다.
What is Alpaca?
- 현재 사용되는 Instruction-folllowing 모델의 경우 잘못된 정보를 생성하거나 사회적 고정관념을 전파하며, 유해한 언어를 생성하는 등의 문제가 있음.
- 알파카는 Meta의 LLaMA 7B 모델을 파인튜닝한 것
사용 데이터
- Instruction Finetuning
- 아의 예시는 GPT를 통해 stanford-alpaca의 self-instruction 데이터셋을 생성 시켰을 때의 분포를 시각화한 예시임.
HOW TO?
- 리소스가 적은 자원으로 학습을 시키는 것이 가능한가?
- 모델 자체의 크기가 LLAMA 모델의 논문에서도 언급되었다시피 싱글 GPU 환경에서 파인튜닝이 가능함
- 추가로 더 효율적인 학습을 위해 PEFT-LORA 를 적용하여 학습을 시킬 예정
What is PEFT
- Parameter-Efficient Fine-Tuning
- 동기 - 과연 드는 비용 대비 효율적인가??
- 전체 파라미터를 업데이트를 시키지 않고 일부만 업데이트 시켜도 성능에 있어서 나쁜 결과를 받아오지 않았음.
- 종류
- LoRA
- Prefix Tuning
- Prompt Tuning
- P-Tuning
LORA(LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)
- 거대 모델들을 파인튜닝 시키기 위해서는 모델의 파리미터 전체를 가지고 와서 조정해야했다.
- 문제를 해결하기 위한 기존의 방안은 일부 매개변수만 조정하거나 새로운 작업에 대해 외부 모듈을 학습하여 각 작업에 대해 저장하고 로드하는 것 등이 있다.
⇒ 이 경우 추론 시간 지연이나 실제 모델의 깊이보다 더 깊어지는 등의 문제를 야기했다.
LoRA의 구조
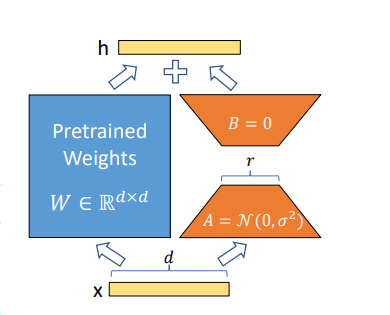
LoRA의 표현식
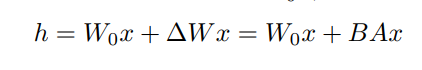
- - pre-trained 된 모델의 학습 파라미터
- - input
- - LoRA에 의해 삽입된 파라미터
- - rank decomposition matrix
FINETUNE
- 밑에는 stanford에서 LLaMA를 파인튜닝 시켰을 시에 사용했던 하이퍼 파라미터 인자 값들
| Hyperparameter | LLaMA-7B | LLaMA-13B |
|---|---|---|
| Batch size | 128 | 128 |
| Learning rate | 2e-5 | 1e-5 |
| Epochs | 3 | 5 |
| Max length | 512 | 512 |
| Weight decay | 0 | 0 |
Reference
- ALPACA
- PEFT
Parameter-Efficient Fine-Tuning using 🤗 PEFT
- LoRA
[2021 Microsoft ] LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- KoAlpaca + LoRA
Alpaca LoRA 파인튜닝 - 나만의 데이터로 학습시키기 Colab 가능
- Custom Dataset
How to make a custom dataset like Alpaca7B
- Instruction Fine-tuning
Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning

파이썬과 함께라면 두렵지 않아