https://www.nb-data.com/p/comparing-model-ensembling-bagging
1. Ensemble Learning 이란?
-
여러 개의 약한(Weak) 모델을 결합해 강한(Strong) 모델 을 만드는 방법
-
목표
-
예측 성능 향상
-
과적합 감소
-
불확실성 감소
-
비유
- 한 사람이 판단하는 것보다 여러 전문가의 의견을 모아서 결론 내리는 방식
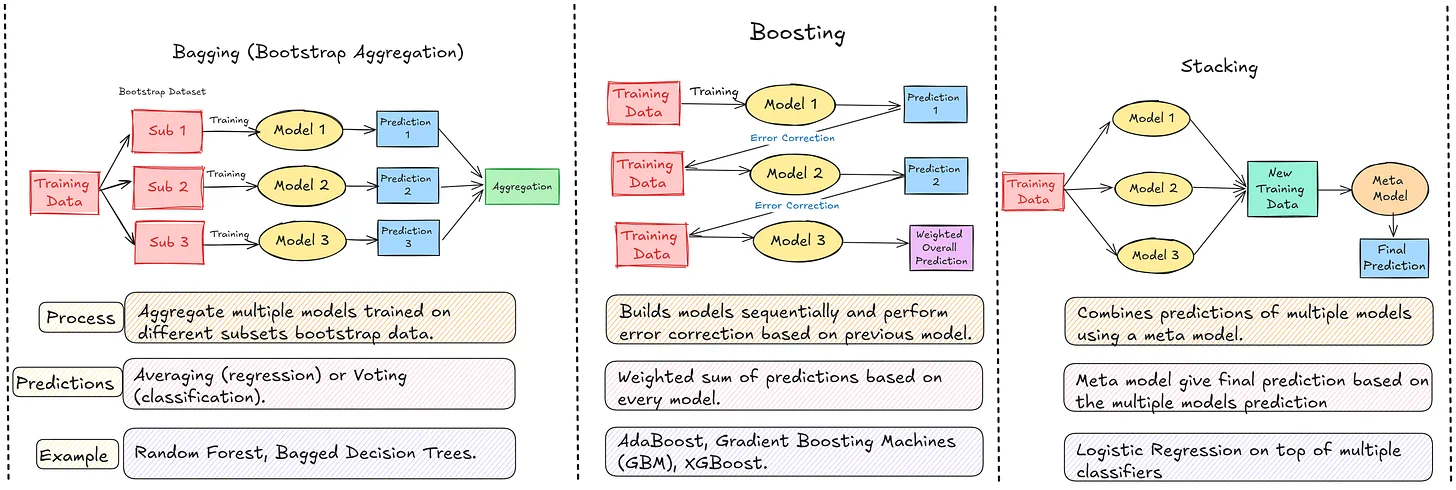
2. Bagging (Bootstrap Aggregating)
-
데이터에 Bootstrap(중복 허용 샘플링) 을 적용하여 서로 다른 학습 데이터 생성
-
여러 모델을 독립적으로 병렬 학습
-
최종 출력은 다수결(분류) / 평균(회귀) 로 결정
대표 모델
- Random Forest
구조 예시
-
원본 데이터 → 여러 Bootstrap 샘플 생성
-
각각의 샘플 → 여러 모델 개별 학습
-
최종 결과 → 투표 / 평균
비유
- 문제집을 여러 버전으로 바꿔가며 풀어 전체 감을 잡는 방식
장점
-
모델 변동성(variance) 감소 → 예측이 안정적
-
과적합에 강함
-
데이터가 달라져도 성능이 크게 흔들리지 않음
단점
- 모델의 근본적인 한계(편향 bias)는 개선되지 않음
(약한 모델 여럿이면 그대로 약함)
3. Boosting
-
모델을 순차적으로 학습
-
이전 모델이 틀린 데이터에 가중치(weight) 를 높여 다음 모델이 보완
-
반복적으로 성능을 강화하는 구조
대표 모델
-
AdaBoost
-
XGBoost
-
LightGBM
-
CatBoost
구조 예시
-
Model₁ 학습 → 오답 데이터 강조
-
Model₂ 학습 → 남은 오답 더 강조
-
Model₃ … 반복
-
최종 결과 = 모든 모델의 가중 합
비유
- 시험에서 틀린 문제만 오답노트로 집중 복습하는 방식
장점
-
매우 높은 성능 가능
-
복잡한 데이터 패턴을 정교하게 학습
단점
-
잘못 튜닝하면 과적합 위험 높음
-
하이퍼파라미터 설정 난이도 ↑
-
학습 시간/자원 소모 ↑
4. Stacking
- 서로 다른 종류의 모델들의 결과를 이용해 메타 모델(meta-model) 이 최종 예측을 결정하는 방식
구조 예시
-
Level-0 (Base Models)
-
Logistic Regression
-
Random Forest
-
SVM
-
XGBoost
-
-
Level-1 (Meta Model)
- Logistic Regression (또는 다른 모델 가능)
-
데이터 흐름
- 원본 데이터 → Base Models 예측값 → Meta Model → 최종 출력
비유
- 여러 전문가의 의견을 듣고, 가장 중심에 있는 최종 의사결정자가 종합하여 판단하는 구조
장점
-
서로 다른 모델의 장점을 결합하여 성능 극대화 가능
-
단일 모델 대비 일반화 성능이 우수
단점
-
구조와 구현이 복잡
-
Base 모델 선택 + 데이터 분할 방식 + Meta 모델 선택이 중요
-
튜닝 비용 ↑
5. 비교 요약
| 방법 | 핵심 개념 | 학습 방식 | 대표 모델 | 장점 | 단점 |
|---|---|---|---|---|---|
| Bagging | 여러 샘플로 여러 모델 학습 | 병렬 | Random Forest | 안정적, 과적합 감소 | Bias 개선 어려움 |
| Boosting | 이전 오류 보완 반복 | 순차 | XGBoost, LightGBM | 높은 성능 | 과적합·튜닝 난이도 ↑ |
| Stacking | 다양한 모델 출력 통합 | 병렬 + 메타 | LR + RF + XGB 조합 | 최종 성능 최고 | 설계 복잡 |
6. 상황별 선택 기준
| 상황 | 추천 앙상블 방식 |
|---|---|
| 데이터 노이즈 많고 일반화가 중요 | Bagging (Random Forest) |
| 최고 성능이 최우선 | Boosting (XGBoost / LightGBM) |
| 여러 모델의 장점을 종합하고 싶음 | Stacking |
