분류 성능 평가: ROC (Receiver Operating Characteristic) 및 AUC (Area Under the Curve)
Artificial Intelligence
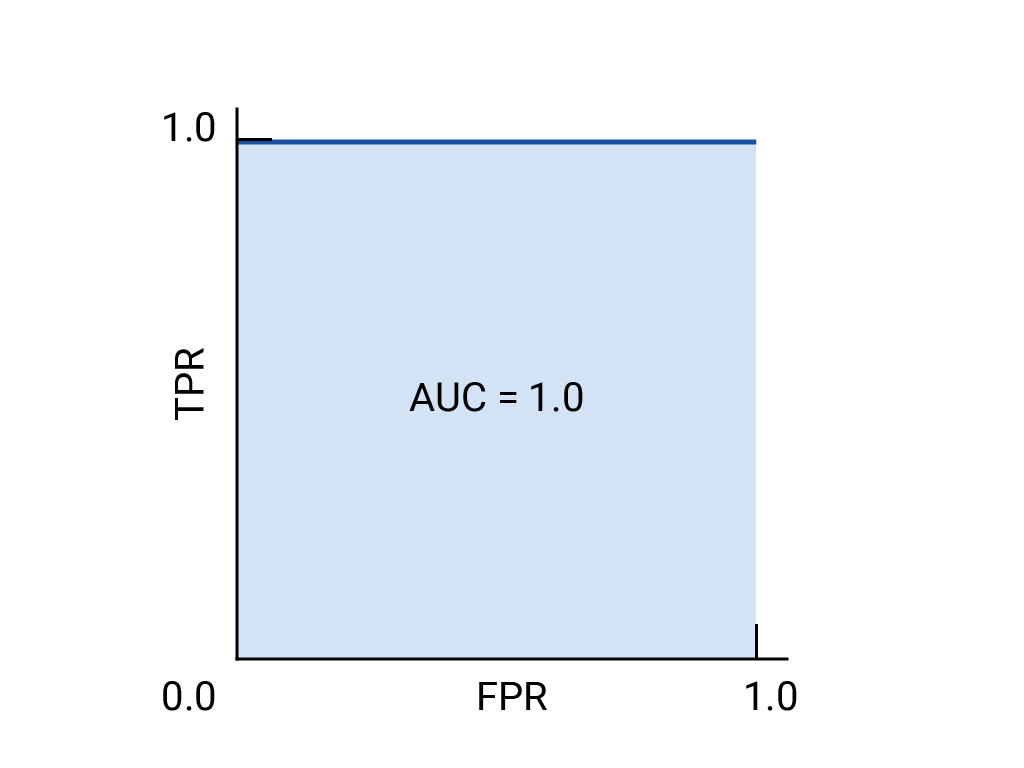
1. ROC 곡선 (Receiver Operating Characteristic Curve)
-
ROC 곡선은 모든 임계값(threshold)에서의 모델 성능을 시각적으로 표현한 그래프입니다.
-
x축은 거짓 양성률(FPR, False Positive Rate),
-
y축은 참 양성률(TPR, True Positive Rate) 을 나타냅니다.
-
-
배경
- “Receiver Operating Characteristic”이라는 용어는
제2차 세계대전 당시 레이더 감지 실험에서 유래했습니다.
- “Receiver Operating Characteristic”이라는 용어는
-
특징
-
완벽한 모델은 (0,1) 지점에 가까운 궤적을 가집니다.
-
무작위 추측 모델은 (0,0)에서 (1,1)까지의 대각선을 따릅니다.
-
2. AUC (Area Under the Curve)
-
ROC 곡선 아래 면적을 의미하며, 임의로 선택된 양성 예시가 음성 예시보다 더 높은 점수를 받을 확률을 나타냅니다.
-
해석 기준
-
AUC = 1.0 → 완벽한 모델
-
AUC = 0.5 → 무작위 추측과 동일
-
AUC < 0.5 → 무작위보다 나쁜 모델 (예측 반전 필요)
-
-
예시
-
스팸 분류기의 경우
-
AUC = 1.0 → 모든 스팸 이메일을 정확히 높은 확률로 예측
-
AUC = 0.5 → 동전 던지기 수준
-
AUC = 0.3 → 오히려 반대로 예측 (스팸을 정상으로, 정상 메일을 스팸으로)
-
-
3. PR 곡선 (Precision-Recall Curve)
-
언제 사용하나
- 데이터 불균형(예: 양성 클래스가 매우 적음) 상황에서 정밀도(Precision) 와 재현율(Recall) 관계를 시각화하는 것이 더 유용합니다.
-
축 구성:
-
x축: 재현율(Recall)
-
y축: 정밀도(Precision)
-
4. 모델 비교 및 임계값 선택
-
AUC 활용
-
데이터의 클래스 비율이 균형적일 때, AUC가 더 큰 모델이 더 좋은 모델입니다.
-
예
-
모델 A → AUC = 0.65
-
모델 B → AUC = 0.93
⇒ B 모델이 더 우수
-
-
-
ROC 곡선의 해석
- (0,1)에 가까운 지점이 가장 좋은 성능을 보입니다.
-
임계값 선택 기준
-
거짓 양성(FP) 의 비용이 크면 → FPR이 낮은 지점(A)
-
거짓 음성(FN) 의 비용이 크면 → TPR이 높은 지점(C)
-
균형을 중시할 경우 → 중간 지점(B)
-
5. 연습 예시
| 모델 | AUC | 성능 판단 |
|---|---|---|
| ROC가 (0,0)→(1,1)로 매끄럽게 상승 | 0.77 | 가장 좋은 모델 |
| 지그재그 형태 | 0.623 | 중간 수준 |
| 오른쪽으로 갔다가 위로 꺾임 | 0.31 | 무작위보다 나쁨 |
| 거의 대각선 | 0.508 | 무작위와 유사 |
→ AUC가 0.5 미만이면, 예측 결과를 반전시키면 성능이 향상될 수 있습니다.
6. 실제 예시: 스팸 분류기
-
상황:
“포지티브 = 스팸”, “네거티브 = 정상 메일”→ 비즈니스상 중요한 메일이 스팸함으로 가는 것(FN)이 더 큰 손실.
-
해석
- 이 경우 거짓 음성(FN) 을 최소화해야 하므로 TPR이 높은 점 C 쪽의 임계값이 더 바람직합니다.
정리 요약
| 구분 | 의미 | 이상적 값 |
|---|---|---|
| TPR (재현율) | 실제 양성을 잘 맞춘 비율 | 1.0 |
| FPR | 실제 음성을 잘못 양성으로 판단한 비율 | 0.0 |
| AUC | ROC 곡선 아래 면적 | 1.0 |
| 좋은 모델의 특징 | (0,1)에 가까운 ROC 곡선 | 높을수록 좋음 |
