-
지금 코드에서는 “영어” 같은 단어만 입력하면, 그대로 번역(즉 ‘English’)이라는 결과를 주는데 의도하신 건 아마 만약 사용자가 “영어,” “일본어” 등 언어만 입력하면 최근 번역했던 문장·답(혹은 질문)을 해당 언어로 다시 번역
-
또, glossary.txt의 전문용어 자동 참고와 실제 번역 수행이 "동시에" 자연스럽게 작동해 “대치(단순 교체)”만 되지 않고 전체 문맥에서 올바른 용어 반영 및 실제 문장 번역이 “영리하게” 이뤄지도록 개선
현상 원인
-
지금 번역 체인은 단어 대치가 목적이 아님에도, '영어' 입력시: ‘영어’만 번역됨 → 'English'
- glossary.txt 용어들은 참고용 context로 프롬프트에 전달만 되고, 실제 문장 전체 맥락·문법까지 자연스럽게 번역하는 것은 OpenAI LLM이 처리하게 설계됨
-
하지만 직전 입력/답변을 기억해 '다시 번역'하는 구조는 직접 구현이 필요 (langchain의 체인 메모리만으로는 LCEL 파이프라인 방식에서 바로 불가)
"동시에 처리" 구현에 중요한 포인트
- 직전 번역/입력 기억
→ 언어만 입력 시 직전 텍스트를 다시 번역 - glossary.txt의 연관 용어 검색
→ 입력 텍스트 기준으로 가장 적합한 용어 여러 개 도출
→ 프롬프트 컨텍스트에 자동 삽입 - "대치만 되는 현상"
→ 번역은 LLM이 전체 문장 context와 glossary를 동시에 보고 자연어 번역하게 설계
→ 단어 치환 수준이 아니라 “올바른 번역+용어 일치”가 LLM 학습에 기반하여 이루어짐
개선된 코드 구조 예시
import os
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
def build_glossary_vector_db(filepath="glossary.txt"):
with open(filepath, "r", encoding="utf-8") as f:
lines = f.readlines()
glossaries = []
metadatas = []
for line in lines:
if ":" in line:
term, explanation = line.strip().split(":", 1)
glossaries.append(f"{term.strip()}: {explanation.strip()}")
metadatas.append({"term": term.strip()})
embedding = OpenAIEmbeddings()
vector_db = Chroma.from_texts(glossaries, embedding, metadatas=metadatas)
return vector_db
def create_translation_chain():
prompt_template = ChatPromptTemplate.from_messages([
('system', """너는 전문 번역가야. 주어진 한국어 문장을 자연스럽게 {language}로 번역해.
아래 '참고 용어'가 있으면 반드시 정확하게 반영해.
참고 용어: {glossary_context}
"""),
('user', '{text}'),
])
model = ChatOpenAI(temperature=0.3)
parser = StrOutputParser()
chain = prompt_template | model | parser
return chain
def is_language_name(text):
language_keywords = ["영어", "일본어", "중국어", "프랑스어", "독일어", "스페인어"]
return text.strip() in language_keywords
def main():
print("== LangChain 똑똑 번역기(glossary+재번역)==")
vector_db = build_glossary_vector_db("glossary.txt")
translation_chain = create_translation_chain()
last_text = None # 직전 번역된(혹은 입력된) 문장 보관
last_language = None # 직전 번역 요구 언어 기억
while True:
text = input("\n번역할 한국어 문장을 입력하세요 (종료:'exit'): ")
if text.lower().strip() == "exit":
break
# 만약 '영어', '일본어' 처럼 언어명만 입력하면
# 직전 입력문(most recent)을 그 언어로 번역하도록 자동 대체
if is_language_name(text):
if last_text:
language = text
text = last_text
print(f"[자동 감지] 바로 이전 텍스트를 {language}로 다시 번역합니다.")
else:
print("이전 번역할 문장이 없습니다.")
continue
else:
language = input("어떤 언어로 번역할까요? (예: 영어, 일본어, 중국어 등): ")
last_text = text # (새로운 번역문 요청 시 원본을 저장)
last_language = language
# glossary 자동 context 추출
similar_docs = vector_db.similarity_search(text, k=3)
glossary_context = "\n".join([doc.page_content for doc in similar_docs]) if similar_docs else "없음"
try:
result = translation_chain.invoke({
"language": language,
"text": text,
"glossary_context": glossary_context
})
print(f"\n번역 결과:\n{result}")
except Exception as e:
print("오류:", e)
if __name__ == "__main__":
main()- 언어만 치면(예: “중국어” 입력)
→ 방금 입력한 텍스트를 해당 언어로 재번역 (스마트 재번역) - glossary.txt의 용어가 입력에 자연스레 녹아 들어감
→ 예전처럼 단순 “대치”가 아니라 뜻이 맞는 번역 생성 - 오타/직전 입력 없음 등도 안내문구 출력
실행 결과
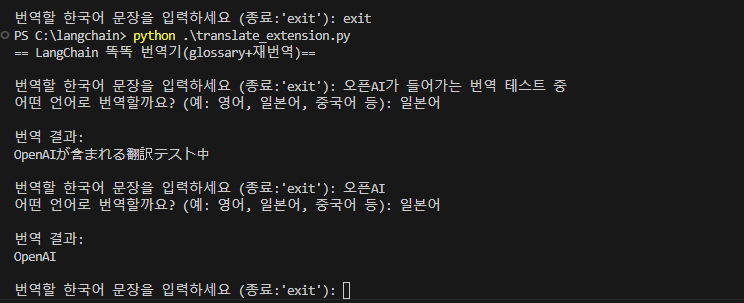
PS C:\langchain> python .\translate_extension.py
== LangChain 똑똑 번역기(glossary+재번역)==
번역할 한국어 문장을 입력하세요 (종료:'exit'): 오픈AI가 들어가는 번역 테스트 중
어떤 언어로 번역할까요? (예: 영어, 일본어, 중국어 등): 일본어
번역 결과:
OpenAIが含まれる翻訳テスト中
번역할 한국어 문장을 입력하세요 (종료:'exit'): 오픈AI
어떤 언어로 번역할까요? (예: 영어, 일본어, 중국어 등): 일본어
번역 결과:
OpenAI
번역할 한국어 문장을 입력하세요 (종료:'exit'):
추가 팁
-
여러 언어명 추가 원할 때
language_keywords를 확장하면 됨 -
필요시, last_translation(직전 결과)도 함께 저장해서
“이전 번역 결과를 다시다시…” 기능도 구현 가능
결론
“대치만 되는 문제”는 LLM의 프롬프트 활용/직전 입력 관리에 따라 극복할 수 있습니다.
위 예시처럼 “자동 재번역 + glossary 동시 컨텍스트 추출”이 실전 번역기 앱에서 가장 자연스럽고 사용자입장에서 편리합니다.

Hi!