임베딩 모델(Embedding Model)
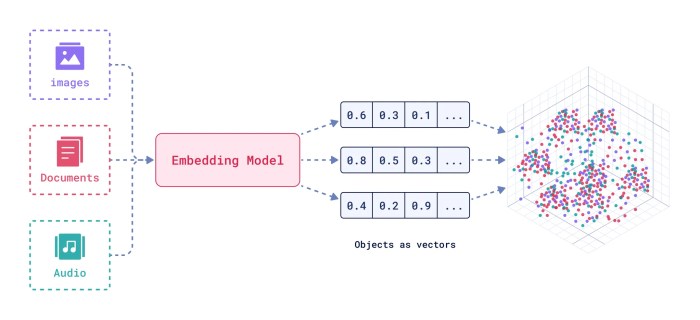
1. 임베딩이란?
-
사람이 쓰는 텍스트(단어, 문장, 문서 등)를 컴퓨터가 이해할 수 있는 숫자 벡터(고차원 숫자 배열)로 변환하는 것.
- 이 숫자 벡터가 바로 “임베딩(embedding)”입니다.
2. 왜 임베딩이 필요할까?
-
컴퓨터 입장에서는 ‘강아지’, ‘고양이’라는 글자만 보고 두 단어의 “의미적 유사성”을 알 수 없음.
- 하지만 임베딩 벡터로 표현하면 의미가 비슷한 단어, 문장, 문서의 벡터끼리 “가까운 숫자”로 자동 변환됨.
-
그래서 검색, 추천, 유사도 계산, 벡터DB 등 “텍스트의 의미 비교·검색”이 가능해짐!
3. 임베딩 모델이란?
-
이 변환 작업(텍스트→벡터)을 수백/수천만 문장의 패턴을 학습한 딥러닝 모델이 자동으로 처리!
-
대표적인 임베딩 모델은
-
OpenAI의 text-embedding-ada-002
-
BERT, Word2Vec, Sentence Transformers 등
-
4. 실제 예시
"오픈AI는 인공지능 회사다."
→ [0.323, -1.042, 2.19, ...] ← 이런 768개 등 숫자 배열이 됨"구글은 IT 대기업이다."
→ [0.322, -1.041, 2.21, ...] ← 가까운 값(비슷한 의미)
5. 어디에 쓰일까?
-
① 벡터DB: 입력 문장과 벡터DB 내 수천~수백만 문서 '거리' 비교
-
② 검색/챗봇: 질문과 답변, 유사 사례 연결
-
③ 추천·필터링: 의미 적합한 문서, 이미지, 상품 추천
-
④ LLM context retrieval: RAG(Retrieval-Augmented Generation) 구조 기반의 정보 검색
6. 정리
| 용어 | 의미/설명 |
|---|---|
| 임베딩(embedding) | 텍스트를 의미 벡터로 변환한 수치형 표현 |
| 임베딩 모델 | 이 변환을 자동으로 해주는 딥러닝 모델 |
| 벡터DB | 벡터로 저장된 대용량 데이터베이스, 유사 검색 |
| 대표 예시 | OpenAIEmbeddings(), BERT, FastText 등 |
임베딩 모델이란 “텍스트의 의미를 숫자 배열로 바꿔주는 딥러닝 변환기!”
이 덕분에 컴퓨터가 텍스트의 의미까지 비교하고 검색, 추천, 유사도를 쉽게 다룰 수 있습니다.
코드에서 해당 부분
- 이미지 속 코드에서 임베딩 모델(embedding model)은
바로 OpenAIEmbeddings()입니다.
embedding = OpenAIEmbeddings()
vector_db = Chroma.from_texts(
glossaries,
embedding,
metadatas=metadatas
)임베딩 모델이란?
-
임베딩 모델(embedding model)은 텍스트(주로 단어, 문장, 문서)를 고차원 실수 벡터(=숫자 배열) 형태로 변환해주는 인공지능 모델입니다.
-
이렇게 변환해야 컴퓨터(특히 벡터 DB, 검색, 머신러닝, 유사도 계산)에서 텍스트 의미·유사성을 수학적으로 빠르게 판단할 수 있습니다.
OpenAIEmbeddings()의 의미
-
LangChain(및 Chroma 등 벡터 DB)이 지원하는 임베딩 모델 중
최신/대표적인 것이 바로 OpenAI에서 제공하는 문장 임베딩 API(OpenAIEmbeddings) 입니다.- ("text-embedding-ada-002" 등 모델 사용)
-
glossary.txt에 들어있는 전문 용어나 설명을 OpenAIEmbeddings 모델로 변환(임베딩)해서 Chroma vector DB에 저장하고,
→ 이후 입력 문장도 동일 임베딩 모델로 변환해서 벡터DB에서 유사도 비교
결론
| 항목 | 코드에서 구체적 역할 |
|---|---|
| 임베딩 모델 | OpenAIEmbeddings() |
| 목적 | 텍스트(용어, 설명, 사용자 입력 등)를 벡터로 변환 |
| 활용 위치 | Chroma 벡터DB에 용어집 저장/유사 검색 시 동일하게 사용 |
| 대표적 모델 | OpenAI의 text-embedding-ada-002 등 |
-
임베딩 모델은 텍스트 ➔ 벡터(숫자) 변환기
-
이미지 코드에서는 OpenAIEmbeddings()가 그 역할 담당
-
입력 문장과 glossary 용어 모두 같은 임베딩 모델로 벡터화 → 유사도 검색 가능!
