NVIDIA V100(Volta)와 H100(Hopper) GPU는 모두 데이터센터·AI·HPC(고성능 컴퓨팅)용이지만, 세대 차이가 크고 성능·아키텍처·지원 기능에서 큰 차이가 있습니다.
1. 기본 사양 비교
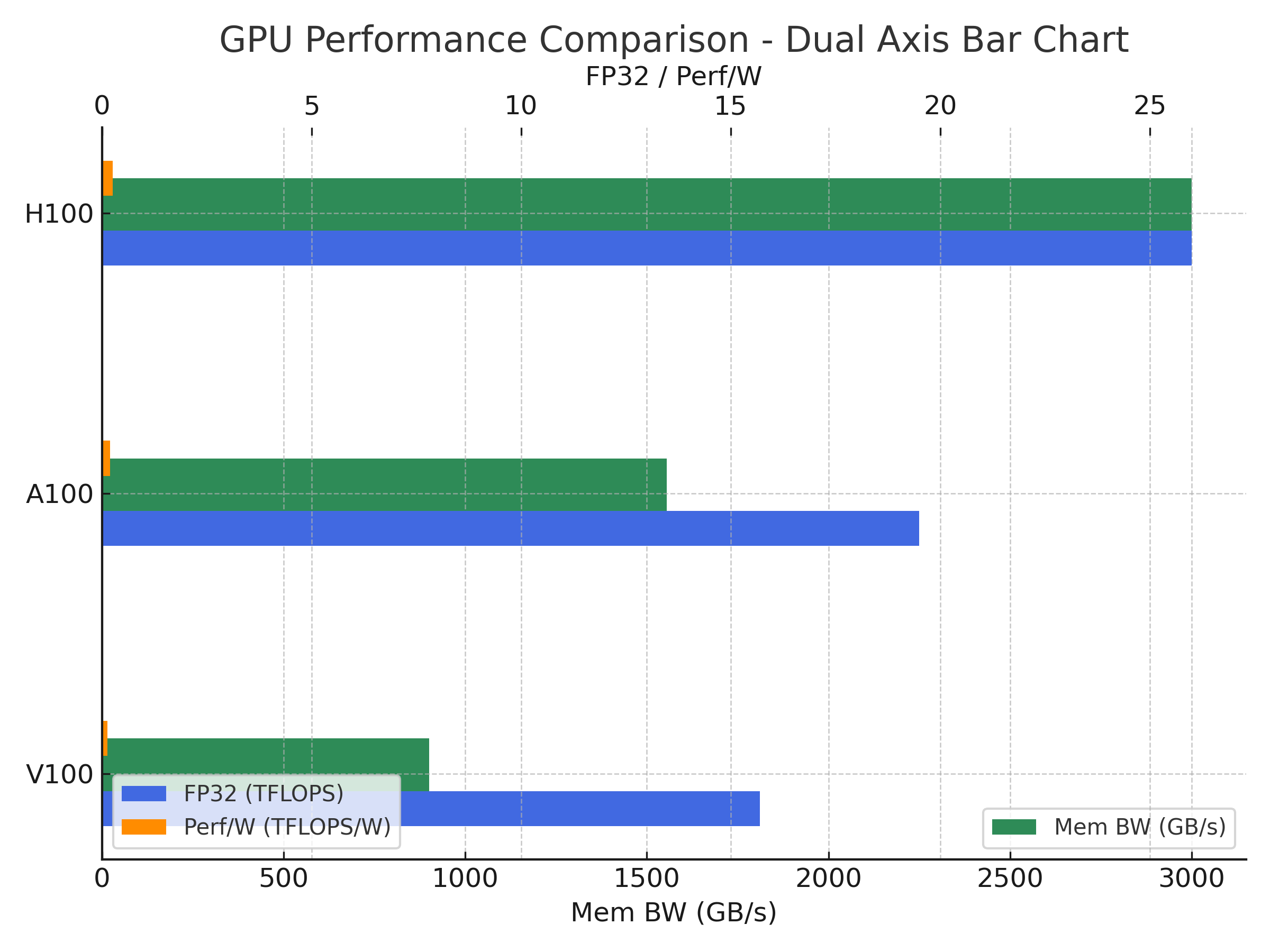
| 항목 | V100 (Volta) | H100 (Hopper) |
|---|---|---|
| 출시 시기 | 2017년 | 2022년 |
| 아키텍처 | Volta | Hopper |
| 제조 공정 | 12nm | 4nm (TSMC) |
| CUDA 코어 | 5,120 | 14,592 |
| Tensor 코어 세대 | 1세대 | 4세대 |
| 메모리 | 16GB / 32GB HBM2 | 80GB HBM3 |
| 메모리 대역폭 | ~900 GB/s | ~3,000 GB/s |
| FP32 성능 | ~15 TFLOPS | ~60 TFLOPS |
| FP16 성능 | ~125 TFLOPS (Tensor Core) | ~1,000 TFLOPS (Tensor Core) |
| NVLink 대역폭 | 300 GB/s | 900 GB/s |
| 주요 특징 | Mixed Precision 지원, 초기 Tensor Core 도입 | Transformer Engine, FP8 지원, 더 높은 에너지 효율 |
2. 실무 활용 관점 비교
AI 학습(Training)
-
V100: 대규모 모델 학습 가능하지만, 최신 대형 모델(예: GPT-3 이상)에서는 속도·메모리 한계가 있음.
-
H100: FP8/FP16 혼합 정밀도와 Transformer Engine 덕분에 대형 언어모델(LLM) 학습 속도가 크게 향상. 동일 모델을 더 적은 GPU로 학습 가능.
추론(Inference)
-
V100: 추론 성능은 준수하지만, 최신 모델의 실시간 서비스에는 병목 발생 가능.
-
H100: FP8 추론 최적화로 지연(latency) 감소, 대규모 동시 요청 처리에 유리.
HPC(과학 계산)
-
V100: FP64 성능이 강점, 기존 HPC 코드와 호환성 높음.
-
H100: FP64 성능도 향상, NVLink/NVSwitch로 대규모 클러스터 확장 용이.
3. 장단점 요약
-
예산 제한 + 중형 모델 학습/추론 → V100
(예: BERT, ResNet, 중형 Transformer) -
최신 대형 모델 학습 + 추론 성능 극대화 → H100
(예: GPT-3, LLaMA, 대규모 Vision Transformer) -
HPC 연구 + AI 혼합 워크로드 → H100 권장, 단 예산 고려.
클라우드(AWS, GCP, Azure)에서 H100 인스턴스를 단기 임대해 벤치마크 후, ROI(투자 대비 효과)를 계산하는 것이 안전합니다.
- 예: AWS EC2
p4d(A100) →p5(H100)로 전환 테스트.
V100
V100 장점
-
안정성 검증 완료, 다양한 프레임워크에서 최적화 지원.
-
중고·클라우드에서 저렴하게 사용 가능.
-
기존 CUDA/HPC 코드 호환성 높음.
V100 단점
-
메모리 용량·대역폭 한계.
-
최신 AI 모델 학습 속도 부족.
H100
H100 장점
-
최신 아키텍처, FP8 지원으로 AI 학습·추론 속도 대폭 향상.
-
메모리 대역폭 3배 이상, 대형 모델 처리에 유리.
-
NVLink 4세대 지원으로 멀티 GPU 확장성 우수.
H100 단점
-
초기 도입 비용 매우 높음.
-
일부 구형 프레임워크·라이브러리에서 최적화 미흡 가능.
Glossary
| 용어 | 정의 | 활용 맥락 | 주의사항 |
|---|---|---|---|
| V100 (Volta) | NVIDIA의 2017년 출시 데이터센터 GPU, Volta 아키텍처 기반. | AI 학습·추론, HPC 계산, 클라우드 GPU 인스턴스에서 사용. | 최신 대형 모델 학습에는 메모리·속도 한계. |
| H100 (Hopper) | NVIDIA의 2022년 출시 데이터센터 GPU, Hopper 아키텍처 기반. | 대형 AI 모델 학습·추론, HPC, FP8 지원. | 초기 도입 비용 높음, 일부 구형 코드 최적화 필요. |
| CUDA Core | NVIDIA GPU의 기본 연산 유닛. 병렬 연산 처리. | 행렬 연산, 벡터 연산, 그래픽·AI 연산. | 코어 수가 많을수록 병렬 처리 성능 향상. |
| Tensor Core | AI 연산(행렬 곱셈) 최적화 전용 유닛. | 딥러닝 학습·추론 속도 향상. | 세대별 지원 정밀도(FP16, FP8 등) 차이 있음. |
| FP32 (Single Precision) | 32비트 부동소수점 연산. | 일반적인 과학 계산, 그래픽 처리. | AI 학습에서는 속도·메모리 효율 낮음. |
| FP16 (Half Precision) | 16비트 부동소수점 연산. | AI 학습·추론에서 메모리 절약, 속도 향상. | 정밀도 손실 가능, Mixed Precision 권장. |
| FP8 | 8비트 부동소수점 연산. | H100에서 지원, 대형 모델 추론·학습 속도 극대화. | 정밀도 손실 가능, 모델·데이터에 따라 성능 차이. |
| HBM2 / HBM3 | High Bandwidth Memory, 고대역폭 메모리. | 대규모 데이터 처리, AI·HPC에서 메모리 병목 완화. | 세대별 대역폭·용량 차이 큼. |
| 메모리 대역폭 (Memory Bandwidth) | GPU가 메모리에서 데이터를 읽고 쓰는 속도. | 대규모 행렬 연산, 데이터 로딩 속도에 영향. | 대역폭이 낮으면 연산 유닛이 놀게 됨(병목). |
| NVLink | NVIDIA GPU 간 고속 연결 인터페이스. | 멀티 GPU 학습·추론, HPC 클러스터. | 세대별 속도 차이, NVSwitch와 함께 사용 가능. |
| Transformer Engine | H100에 탑재된 AI 연산 최적화 엔진. | Transformer 기반 모델(BERT, GPT 등) 학습·추론 가속. | FP8/FP16 혼합 정밀도 활용 필요. |
| HPC (High Performance Computing) | 대규모 병렬 연산을 통한 과학·공학 계산. | 시뮬레이션, 유전체 분석, 기후 모델링. | GPU·CPU·네트워크 모두 병목 없이 구성해야 함. |
| Mixed Precision Training | FP16과 FP32를 혼합해 학습하는 기법. | 속도·메모리 효율 향상, 정밀도 유지. | 자동 혼합 정밀도(AMP) 기능 활용 권장. |
| Inference (추론) | 학습된 모델로 예측을 수행하는 과정. | AI 서비스, 실시간 응답 시스템. | 지연(latency) 최소화가 중요. |
| Training (학습) | 모델이 데이터로부터 패턴을 학습하는 과정. | AI 모델 개발, 성능 개선. | 대규모 모델은 GPU 메모리·연산 성능 필수. |
[참고] TSMC가 등장한 이유
-
TSMC(Taiwan Semiconductor Manufacturing Company)는 세계 최대 파운드리(반도체 위탁 생산) 기업입니다.
-
NVIDIA는 자체적으로 반도체를 생산하지 않고, 설계만 하고 제조는 TSMC 같은 파운드리에 맡깁니다.
-
H100 GPU는 TSMC의 4nm(N4) 공정으로 제조됩니다.
-
반면, V100 GPU는 TSMC의 12nm 공정으로 제조되었습니다.
"TSMC"를 표기한 이유는 H100의 제조 공정이 TSMC에서 이루어졌기 때문입니다.
제조 공정이 중요한 이유 (실무 관점)
-
공정 미세화(예: 12nm → 4nm)는 같은 면적에 더 많은 트랜지스터를 집적할 수 있게 해줍니다.
-
결과적으로
-
성능 향상 (더 많은 연산 유닛 탑재 가능)
-
전력 효율 개선 (와트당 성능 증가)
-
발열 감소 (동일 성능 대비 발열 적음)
-
-
H100이 V100 대비 CUDA 코어 수, 메모리 대역폭, Tensor Core 성능이 크게 향상된 이유 중 하나가 바로 이 제조 공정 차이입니다.
NVIDIA 주요 GPU 제조 공정 변화
| 세대 | 대표 GPU | 제조사 | 공정 |
|---|---|---|---|
| Volta (2017) | V100 | TSMC | 12nm |
| Ampere (2020) | A100 | TSMC | 7nm |
| Hopper (2022) | H100 | TSMC | 4nm |
정리
-
TSMC를 표기한 건 단순한 브랜드 언급이 아니라, GPU 성능·전력 효율·발열 특성에 직접적인 영향을 주는 제조 공정 정보를 명시하기 위함입니다.
-
실무에서 GPU를 선택할 때, 이 제조 공정 차이는 성능 대비 전력비용(TCO) 계산에 중요한 요소가 됩니다.
