https://developer.nvidia.com/ko-kr/blog/nvidia-hopper-architecture-in-depth/
1. H100
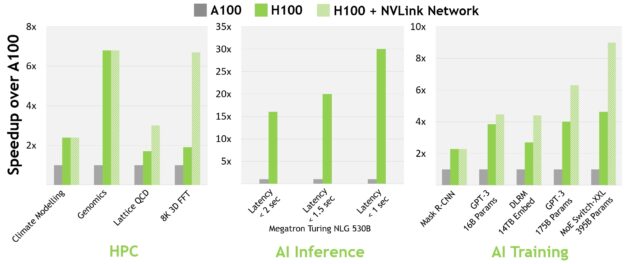
| 구분 | 주요 개선점 | 실무 활용 효과 |
|---|---|---|
| 연산 성능 | A100 대비 최대 6배 성능 향상 (FP8 도입, SM 증가, 클럭 향상) | 대규모 AI 모델 학습·추론 시간 단축, HPC 시뮬레이션 속도 향상 |
| 메모리 | HBM3(3TB/s) + 50MB L2 캐시 | 대규모 데이터셋 처리 시 메모리 병목 감소 |
| 트랜스포머 엔진 | FP8/FP16 혼합 정밀도 자동 관리 | LLM·NLP 모델 학습·추론 최적화 |
| NVLink 4세대 | GPU 간 900GB/s 대역폭, 최대 256 GPU 연결 | 멀티 GPU 클러스터 확장성 극대화 |
| MIG 2세대 | 인스턴스당 3배 컴퓨팅, 2배 메모리 대역폭 | 멀티 테넌트 환경에서 QoS 보장 |
| 비동기 실행 | Tensor Memory Accelerator, DSMEM, 트랜잭션 장벽 | 데이터 이동과 연산 중첩 → GPU 활용률 극대화 |
2. 실무 적용 시나리오
1) AI 모델 학습·추론
-
대형 언어 모델(LLM): GPT-3, MT-NLG 등 수십~수백억 파라미터 모델 학습 시간 단축
-
컴퓨터 비전: 대규모 이미지·영상 데이터 처리 속도 향상
-
추천 시스템: DLRM, MoE 모델에서 배치 크기 확장 가능
Tip: FP8 혼합 정밀도 사용 시 메모리 절감 + 처리량 증가
→ NVIDIA Transformer Engine API와 함께 사용
2) HPC(High Performance Computing)
-
유전체학: 스미스-워터맨 알고리즘 DPX 명령어로 최대 7배 가속
-
기후 모델링·유체역학: NVLink 네트워크로 노드 간 통신 병목 제거
-
금융 시뮬레이션: FP64 연산 성능 3배 향상
Tip: DSMEM(Distributed Shared Memory)로 SM 간 데이터 교환 시 글로벌 메모리 접근 최소화
3) 데이터센터·클라우드 서비스
-
MIG 2세대: GPU를 최대 7개 인스턴스로 분할, 각 인스턴스 독립 성능 모니터링 가능
-
컨피덴셜 컴퓨팅: TEE 기반 보안 환경에서 AI/HPC 실행
-
SR-IOV + NVLink: 멀티 VM 환경에서 GPU 간 직접 메모리 접근
Tip: 클라우드 제공 시 GPU 자원 할당 정책에 MIG 활용 → SLA 보장
3. 장점 vs 주의사항
| 장점 | 주의사항 |
|---|---|
| AI·HPC 모두에서 세대별 최대 성능 향상 | FP8 사용 시 일부 모델에서 정밀도 손실 가능 → 사전 검증 필요 |
| NVLink 네트워크로 대규모 GPU 확장 가능 | NVLink 네트워크 구성·주소 관리 복잡 → 초기 설계 중요 |
| 비동기 실행으로 GPU 활용률 극대화 | TMA·트랜잭션 장벽 API 학습 필요 |
| MIG로 멀티 테넌트 지원 | 인스턴스 간 자원 경합 방지 정책 필요 |
4. 도입·구현 체크리스트
-
워크로드 분석: FP8/FP16/FP32 중 어떤 정밀도가 적합한지 결정
-
클러스터 설계: NVLink 네트워크 vs InfiniBand 선택
-
메모리 최적화: DSMEM, L2 캐시 활용 패턴 설계
-
보안 요구사항: 컨피덴셜 컴퓨팅 필요 여부 확인
-
소프트웨어 스택: CUDA 12.x 이상, NCCL, cuBLAS, cuDNN 최신 버전 적용
부동소수점(Floating Point) 정밀도 활용 종합 가이드
1. 정밀도 높을 때의 특징
| 항목 | 장점 | 단점 |
|---|---|---|
| 정확도 | 계산 결과 오차 감소, 과학·금융 분야에서 필수 | AI·ML에서는 데이터 노이즈로 인해 과도한 정확도가 의미 없을 수 있음 |
| 연산 안정성 | 수치 오차 누적 방지 | 연산 속도 저하, GPU 병렬 처리 효율 감소 |
| 데이터 표현 범위 | 매우 큰/작은 값 표현 가능 | 메모리 사용량 증가, 전력 소비 증가 |
2. 정밀도별 특성 (H100 기준)
| 형식 | 비트 수 | 처리량(TFLOPS) | 메모리 사용량 | 주 사용 분야 |
|---|---|---|---|---|
| FP64 | 64 | 30 | 매우 큼 | 과학 계산, 금융 시뮬레이션 |
| FP32 | 32 | 60 | 큼 | HPC, 일부 AI |
| FP16/BF16 | 16 | 1000 (Tensor) | 중간 | AI 학습·추론 |
| FP8 | 8 | 2000 (Tensor) | 작음 | 대형 언어 모델, 추론 최적화 |
3. 실무에서 발생하는 문제점 (정밀도 높을 때)
-
속도 저하: FP64는 FP16 대비 연산 속도가 수십 배 느림
-
메모리 부족: 비트 수가 많아 데이터 크기 증가 → 배치 크기 축소
-
전력·비용 증가: 데이터센터 운영비 상승, 발열 증가
-
GPU 활용률 저하: Tensor 코어는 낮은 정밀도에서 최대 성능 발휘
4. 최적화 전략
-
혼합 정밀도(Mixed Precision)
-
FP8 + FP16 조합 → 속도·메모리 최적화, 정확도 유지
-
NVIDIA Transformer Engine, AMP(Automatic Mixed Precision) 활용
-
-
워크로드별 정밀도 매핑
-
HPC: 핵심 계산만 FP64, 나머지는 FP32/FP16
-
AI: 학습 초기 FP16, 추론 시 FP8
-
-
자동 튜닝
- 프레임워크에서 제공하는 자동 정밀도 선택 기능 사용 (PyTorch AMP, TensorFlow mixed_precision)
5. 의사결정 표 (워크로드별 추천 정밀도)
| 워크로드 | 추천 정밀도 | 이유 |
|---|---|---|
| 대형 언어 모델 학습 | FP16/BF16 | 속도·메모리 절약, 정확도 유지 |
| 대형 언어 모델 추론 | FP8 | 처리량 극대화, 메모리 절감 |
| 과학 시뮬레이션 | FP64 (핵심 계산), FP32 (보조 계산) | 수치 안정성 확보, 성능 최적화 |
| 이미지·영상 AI | FP16 | GPU Tensor 코어 최대 활용 |
| 추천 시스템 | FP8/FP16 혼합 | 대규모 배치 처리 최적화 |
-
정밀도 높음 → 정확도↑ / 속도↓ / 메모리↑ / 전력↑
-
정밀도 낮음 → 속도↑ / 메모리↓ / 전력↓ / 정확도↓
-
실무 최적화 핵심: 필요한 만큼만 정밀도를 쓰고, 혼합 정밀도 전략으로 성능·비용·정확도 균형 맞추기
5. 예시: FP8 트랜스포머 엔진 활용 코드 스니펫
#include <cuda_fp8.h>
#include <transformer_engine.h>
// FP8 Tensor 변환 예시
void run_fp8_transformer(te::Tensor &input, te::Tensor &output) {
te::TransformerEngine engine;
engine.set_precision(te::Precision::FP8);
engine.forward(input, output);
}활용 포인트: FP8 변환은 엔진이 자동으로 스케일링 → 메모리 절감 + 속도 향상
결론
-
NVIDIA H100은 AI·HPC·클라우드 데이터센터 모두에서 성능·확장성·보안을 동시에 강화한 GPU입니다.
-
특히 FP8 + 트랜스포머 엔진 + NVLink 네트워크 조합은 대규모 모델과 엑사스케일 HPC 환경에서 ROI를 극대화할 수 있습니다.
