https://medium.com/@enerzai/onnx-%EB%84%88-%EB%88%84%EA%B5%AC%EC%95%BC-who-are-you-5c1435b997e2
1. ONNX란?
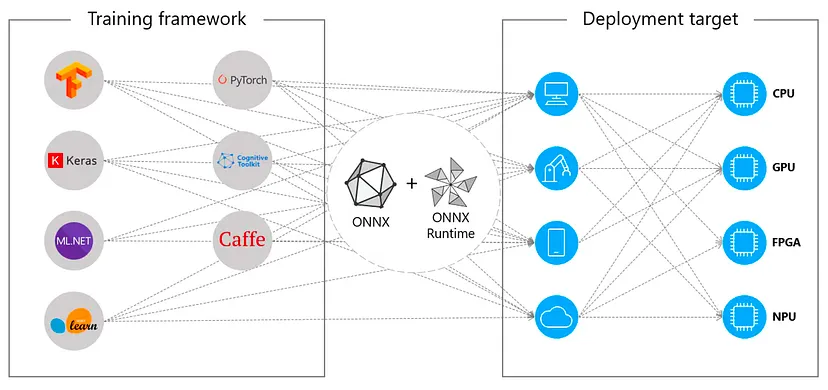
-
ONNX(Open Neural Network Exchange)는 서로 다른 머신러닝(ML) 프레임워크에서 개발된 모델을 표준 포맷으로 변환하여 호환성을 제공하는 오픈소스 프로젝트입니다.
-
Meta와 Microsoft가 주도했고, 현재는 Intel, NVIDIA 등 다양한 HW/SW 기업이 참여하고 있습니다.
핵심 목적
-
프레임워크 간 모델 호환 (PyTorch → TensorFlow → Caffe 등)
-
다양한 하드웨어에서 실행 가능 (CPU, GPU, NPU, FPGA 등)
-
표준화된 생태계 구축 (Model Zoo, Runtime, Converter 등)
2. 실무 활용 시 장점
| 장점 | 설명 | 예시 |
|---|---|---|
| 프레임워크 독립성 | 모델을 특정 프레임워크에 종속시키지 않고 배포 가능 | PyTorch에서 학습 → ONNX 변환 → TensorRT로 추론 |
| 다양한 하드웨어 지원 | Intel OpenVINO, NVIDIA TensorRT, Qualcomm QNN 등과 연동 | 엣지 디바이스에서 최적화된 추론 |
| 모델 최적화 기능 | 그래프 최적화, Constant Folding, Node Fusion 등 | 추론 속도 20~30% 향상 |
| Model Zoo 제공 | 사전 학습된 모델을 바로 활용 가능 | ResNet, BERT, YOLO 등 ONNX 포맷 다운로드 후 배포 |
3. 실무 적용 예시
1) 모델 변환
import torch
import torch.onnx
# PyTorch 모델 정의
model = MyModel()
model.load_state_dict(torch.load("model.pth"))
model.eval()
# ONNX로 변환
torch.onnx.export(
model,
torch.randn(1, 3, 224, 224), # 입력 샘플
"model.onnx",
export_params=True,
opset_version=13,
do_constant_folding=True
)활용: 변환된 model.onnx를 TensorRT, OpenVINO, Windows ML 등에서 바로 사용 가능.
2) ONNX Runtime 추론
import onnxruntime as ort
import numpy as np
# 세션 생성
session = ort.InferenceSession("model.onnx")
# 입력 데이터 준비
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32)
# 추론 실행
outputs = session.run(None, {"input": input_data})
print(outputs)활용: 서버, 데스크톱, 엣지 디바이스에서 동일한 코드로 추론 가능.
4. 주의사항
-
Opset Version 호환성
-
변환 시
opset_version을 명시하지 않으면 일부 연산이 호환되지 않을 수 있음. -
예: PyTorch 최신 버전 → ONNX 변환 시 특정 Conv 연산이 누락.
-
-
정확도 저하
-
Resize, Interpolation 등 연산 구현 차이로 인해 결과가 미세하게 달라질 수 있음.
-
특히 이미지 처리 모델에서 주의 필요.
-
-
지원하지 않는 Layer
-
변환 시 Unsupported Layer가 있으면 변환 실패.
-
해결: Custom Layer 구현 또는 변환 전 모델 구조 변경.
-
-
모델 크기
-
임베디드 환경에서는 ONNX Runtime 크기(약 250MB)가 부담될 수 있음.
-
해결: 경량화된 EP(Execution Provider) 사용.
-
5. ONNX와 NNEF 비교 (간단 요약)
| 항목 | ONNX | NNEF |
|---|---|---|
| 그래프 방식 | 정적 그래프(Protobuf) | 절차적 구문(동적 그래프) |
| 데이터 타입 | 다양한 비트 폭 지원 | 단순 타입 중심 |
| 파일 구조 | 단일 Protobuf 파일 | 구조/데이터 분리 |
| 생태계 | 풍부한 툴과 지원 | 제한적 |
6. ONNX 기반 최적화 툴
-
ONNX Runtime: 범용 추론 엔진, 다양한 하드웨어 EP 지원
-
Olive (Microsoft): 하드웨어 인식 모델 최적화 솔루션
-
Optimium: MLIR 기반 커스텀 최적화, 속도 향상, Custom Layer 지원
7. 실무 적용 전략
-
모델 개발 단계
- PyTorch/TensorFlow에서 학습 후 ONNX로 변환
-
배포 단계
- 대상 하드웨어에 맞는 EP 선택 (TensorRT, OpenVINO 등)
-
최적화 단계
- 그래프 최적화, Quantization, Model Partitioning 적용
-
검증 단계
- 원본 모델과 ONNX 모델의 출력 비교 (정확도 검증)
-
운영 단계
- ONNX Runtime 또는 경량화된 추론 엔진으로 서비스 운영
