Pytorch 한국 사용자 모임: https://pytorch.kr/
https://www.nvidia.com/ko-kr/glossary/pytorch/
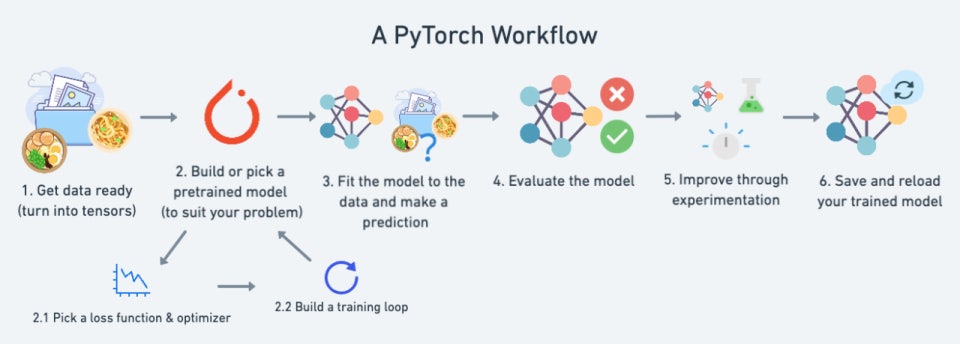
1. PyTorch란
-
PyTorch는 Meta(Facebook) AI Research팀이 개발한 딥러닝 프레임워크로, 동적 계산 그래프(Dynamic Computational Graph) 기반의 신경망 구현이 특징입니다.
- 즉, 코드를 실행하면서 실시간으로 그래프를 구성하고 계산하므로, TensorFlow(1.x)의 정적 그래프 방식보다 디버깅과 실험이 훨씬 직관적입니다.
2. 핵심 구조
| 구성 요소 | 역할 | 비유 |
|---|---|---|
| Tensor | 수치 데이터를 담는 기본 단위 (Numpy의 ndarray 유사) | 행렬 / 벡터 |
| Autograd | 자동 미분 기능 (역전파 자동 계산) | 수학 노트 대신 계산해주는 조교 |
| nn.Module | 신경망 계층 및 모델 정의용 클래스 | 블록 조립식 모형 |
| Optimizer | 가중치 업데이트 담당 (SGD, Adam 등) | 학습 방향 조정기 |
| DataLoader / Dataset | 배치 단위 데이터 공급 및 전처리 | 학습용 데이터 공급 시스템 |
3. 동작 원리 (학습 루프 흐름)
-
데이터 불러오기
Dataset과DataLoader로 미니배치 구성
GPU로 텐서 이동(.to(device))
-
순전파 (Forward pass)
- 입력을 모델에 통과시켜 예측값 계산
-
손실 계산 (Loss calculation)
nn.CrossEntropyLoss등으로 실제값과 예측값 비교
-
역전파 (Backward pass)
loss.backward()호출 시 autograd가 모든 파라미터의 gradient 계산
-
가중치 업데이트
optimizer.step()으로 weight 조정
-
기울기 초기화
optimizer.zero_grad()로 gradient 누적 방지
4. 주요 구성 요소 세부 설명
1) Tensor
-
GPU 가속 가능 (
torch.device('cuda')) -
예시
x = torch.tensor([[1, 2], [3, 4]], dtype=torch.float32, device='cuda')
2) Autograd
-
자동으로 gradient(기울기) 계산
-
requires_grad=True를 설정한 텐서만 추적됨x = torch.ones(2, 2, requires_grad=True) y = x + 2 z = y * y * 3 out = z.mean() out.backward() # d(out)/dx 계산 print(x.grad)
3) nn.Module
-
모든 신경망은
nn.Module을 상속 -
파라미터를 자동으로 등록하고 GPU 전송, 저장, 로드 등을 일괄 관리
import torch.nn as nn class SimpleNN(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(784, 128) self.relu = nn.ReLU() self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.relu(self.fc1(x)) return self.fc2(x)
4) Optimizer
-
예:
torch.optim.Adam,torch.optim.SGDoptimizer = torch.optim.Adam(model.parameters(), lr=0.001) optimizer.zero_grad() loss.backward() optimizer.step()
5) Dataset & DataLoader
-
torch.utils.data.Dataset→ 데이터 정의 -
DataLoader→ 배치 단위 반복자(iterator)from torch.utils.data import DataLoader, TensorDataset dataset = TensorDataset(X, y) dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
5. 예시 코드 (MNIST 분류)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 1) 데이터 전처리 파이프라인 정의
# - ToTensor(): PIL 이미지를 [0,1] 범위의 float32 Tensor로 변환 (C×H×W 형태)
# - Normalize((0.5,), (0.5,)): 평균 0.5, 표준편차 0.5로 정규화 -> [-1, 1] 범위로 스케일링
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 2) 학습 데이터셋 구성
# - root: 데이터 저장 위치
# - train=True: 학습용 split
# - download=True: 없으면 자동 다운로드
# - transform: 위에서 정의한 전처리 적용
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
# 3) DataLoader: 미니배치 단위로 순회하기 위한 반복자
# - batch_size=64: 한 번에 64장 처리
# - shuffle=True: 각 epoch마다 데이터 순서 섞기(일반화 성능 향상)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# 4) 모델 정의
# - nn.Module을 상속하는 클래스로 네트워크 구조를 선언
# - "init에서 레이어를 선언"하고, "forward에서 데이터 흐름을 정의"한다는 점이 핵심
class Net(nn.Module):
def __init__(self):
super().__init__() # 부모 클래스 초기화: 내부적으로 파라미터 등록 등 nn.Module 기반 기능 활성화
# (a) 완전연결(Linear) 계층 선언
# 입력 차원: 28*28=784 (MNIST 한 장을 펼친 벡터 길이)
# 은닉층1 차원: 128
self.fc1 = nn.Linear(28*28, 128)
# (b) 은닉층2: 128 -> 64
self.fc2 = nn.Linear(128, 64)
# (c) 출력층: 64 -> 10 (클래스 수=10)
# CrossEntropyLoss를 사용할 것이므로 최종 활성함수(softmax)는 쓰지 않는다.
# CrossEntropyLoss가 내부에서 LogSoftmax + NLLLoss를 결합해서 처리함
self.fc3 = nn.Linear(64, 10)
# (선택) 활성함수는 nn.ReLU() 모듈로 만들어 멤버로 들고가도 되고,
# 아래 forward처럼 torch.relu 함수형으로 호출해도 무방하다.
# self.relu = nn.ReLU()
# forward: 입력 텐서 x가 레이어를 거쳐 출력으로 변환되는 "연산 그래프(데이터 흐름)" 정의
# - 여기서 호출되는 연산들은 autograd가 추적하여, backward 시 gradient 계산에 사용됨
def forward(self, x):
# (1) 입력 크기 변환: [B, 1, 28, 28] -> [B, 784]
# - view는 텐서의 모양만 바꾸며, 실제 메모리 복사는 하지 않음(가능한 경우)
# - -1은 batch 크기를 자동 유추하라는 의미
x = x.view(-1, 28*28)
# (2) 은닉층1 연산 + ReLU 활성화
# - 비선형성을 부여하여 모델이 복잡한 함수를 근사할 수 있게 함
x = torch.relu(self.fc1(x))
# (3) 은닉층2 연산 + ReLU 활성화
x = torch.relu(self.fc2(x))
# (4) 출력층 연산: [B, 10] 로짓(logits)
# - softmax를 여기서 적용하지 않는 이유:
# CrossEntropyLoss가 logits를 입력으로 받아 내부에서 안정적으로 처리
return self.fc3(x)
# 5) 모델 인스턴스화
# - 이 시점에 nn.Module이 파라미터(가중치/편향)를 내부적으로 보유하게 됨
model = Net()
# 6) 손실 함수(=목표 함수)와 최적화 알고리즘(옵티마이저) 설정
# - CrossEntropyLoss: 다중 클래스 분류용 표준 선택 (logits 입력)
# - Adam: 적응형 학습률을 사용하는 옵티마이저 (초기 실험에 무난)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# (선택) GPU 사용 예시:
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# model.to(device)
# 7) 학습 루프
# - epoch: 전체 데이터셋을 몇 번 반복 학습할지
# - 각 미니배치에 대해: 순전파 -> 손실 계산 -> 기울기 초기화 -> 역전파 -> 파라미터 갱신
for epoch in range(5):
for images, labels in trainloader:
# (GPU 사용 시)
# images = images.to(device)
# labels = labels.to(device)
# (1) 순전파: 현재 파라미터로 예측값 계산
outputs = model(images)
# (2) 손실 계산: 예측(outputs) vs 정답(labels)
loss = criterion(outputs, labels)
# (3) 이전 배치의 기울기 초기화 (누적 방지)
optimizer.zero_grad()
# (4) 역전파: 오차를 각 파라미터로 전파하여 gradient 계산
loss.backward()
# (5) 파라미터 갱신: optimizer가 각 파라미터 w ← w - lr * dw 적용
optimizer.step()
# epoch 종료 시점의 손실 출력(모니터링용)
print(f"Epoch {epoch+1} Loss: {loss.item():.4f}")
6. PyTorch의 장점 요약
| 항목 | 설명 |
|---|---|
| 동적 계산 그래프 | 실행 시점에서 그래프 구성 → 유연한 실험 가능 |
| 직관적 디버깅 | Python 코드처럼 한 줄씩 실행 & 중단점 설정 가능 |
| GPU 연산 통합 | cuda() 한 줄로 GPU 사용 |
| 풍부한 생태계 | torchvision, torchaudio, torchtext, torch-geometric 등 |
| ONNX/Lightning 호환 | 다양한 프레임워크로 확장 용이 |

Hi!